
Clickbait Word Cloud
TL; DR:ヘッダーとコンテンツの機能に基づいて、テストデータで99.2%のクリックスルー認識を達成しました。 コードはGitHubリポジトリにあります 。
かつて、クリックベイトを明らかにすることに関する記事を書きました 。 その記事は多くの批判と同様に良いレビューを受けました。 サイトのコンテンツを検討する必要があると言う人もいれば、さまざまなソースからより多くの例を要求する人もいれば、深層学習法を試すことを提案する人もいました。
この記事では、これらの問題を解決し、クリックベイト検出を新しいレベルに引き上げようとします。
無料の食べ物情報はありません
自分のFacebookフィードを調べたところ、クリックベイトはタイトルだけで分類できないことがわかりました。 また、コンテンツにも依存します。 サイトのコンテンツがタイトルとよく一致する場合、クリックベイトとして分類しないでください。 しかし、実際のクリックベイトが何であるかを判断することは非常に困難です。
Facebookで実際の例を見てみましょう。
| 1。 |  |
| 2。 |  |
| 3。 |  |
| 4。 |  |
今はどう思いますか? そのうちクリックベイトに分類するものとしないものはどれですか? ソース情報を削除した後、さらに困難になりましたか?
TF-IDFとWord2Vecに基づいた私の以前のモデルは、最初の3つをclickbaitとして分類し、おそらく4つ目も分類します。 ただし、これらの例のうち、クリックベイトは2番目と3番目の2つのみです。 最初の例はCNNによって配布された記事で、4番目はThe New York Timesからのものです。 これらは、トランプが何と言っているかに関係なく、2つの権威あるニュースソースです! :)
Facebook / Googleが見出しのみを考慮する場合、ニュースフィードまたは検索結果で上記のすべての例をブロックします。
そこで、タイトルだけでなく、リンクによって開かれるサイトのコンテンツ、およびこのサイトで目立ついくつかの主要な機能によっても分類することにしました。
データを収集することから始めましょう。
データ収集
今回は、公開されているFacebookページからデータを取得しました。 Max Wulfは、これを行う方法に関する優れた記事を執筆しました。 Pythonスクリプトはこちらから入手できます 。 このスクレーパーを使用すると、サイトで許可なく表示できる公開のFacebookページからデータを抽出できます。
次のページからデータを抽出しました。
- バズフィード
- CNN
- ニューヨークタイムズ
- クリックホール
- StopClickBaitOfficial
- 価値がある
- ウィキニュース
Max WolfeスクレーパーがClickholeページから抽出したデータを見てみましょう。
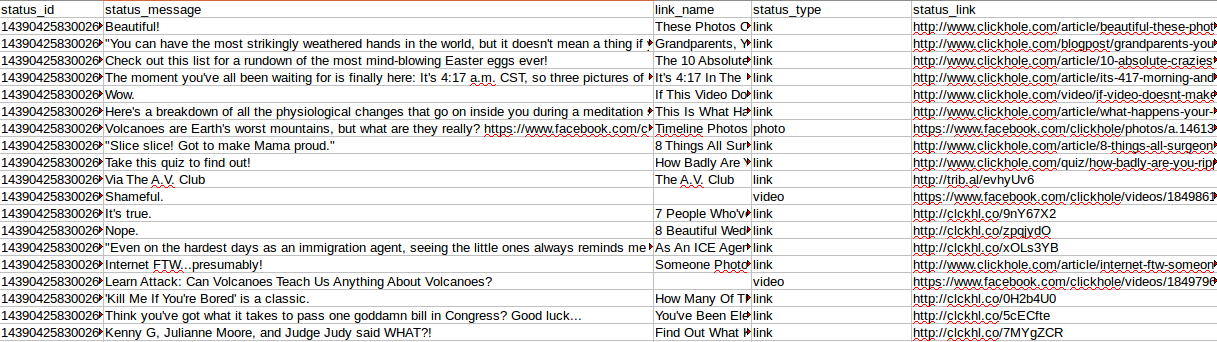
ここで興味深いのは次のフィールドです。
- link_name(公開されたURLヘッダー)
- status_type(リンク、写真、またはビデオがあります)
- status_link(実際のURL)
ステータスstatus_type == linkをフィルタリングしました。テキストコンテンツがある公開URLにのみ興味があるからです。
次に、収集したデータを2つのCSVファイルに結合しました。Buzzfeed、Clickhole、Upworthy、Stopclickbaitofficialはclickbaits.csvに、残りはnon_clickbaits.csvに分類されました。
データ処理と特性生成
データを収集して2つの異なるファイルに保存すると、すべてのリンクのHTMLドキュメントを収集し、すべてのデータをピクルファイルとして保存するときが来ました。 これを行うために、非常に単純なPythonスクリプトを作成しました。

私は非常に厳密にhtmlの抽出に取り組みましたが、何らかの障害が発生した場合、「htmlなし」という応答が返されました。 時間を節約し、データ収集を高速化するために、彼はJoblibで Parallelを使用しました 。 The New York TimesなどのクロールサイトのCookieサポートを有効にする必要があることに注意してください。
私のコンピューターは64 GBのRAMを搭載しているため、すべてをメモリで実行しました。 コードを簡単に変更して、CSVで1行ずつ結果を保存し、多くのメモリを解放できます。
次のステップは、このHTMLデータからタグを生成することでした。
BeautifulSoup4とgoose-extractorを使用してサインを生成しました。
生成されたサインは次のとおりです。
- HTMLサイズ(バイト単位)
- HTMLの長さ
- リンクの総数
- ボタンの総数
- 入力フィールドの総数
- 順序付けられていないリストの総数
- 番号付きリストの総数
- H1タグの総数
- 合計H2タグ
- 見つかったすべてのH1タグのテキストの長さ
- 見つかったすべてのH2タグのテキストの長さ
- 画像の総数
- htmlタグの総数
- 一意のhtmlタグの数
これらの兆候のいくつかを見てみましょう。
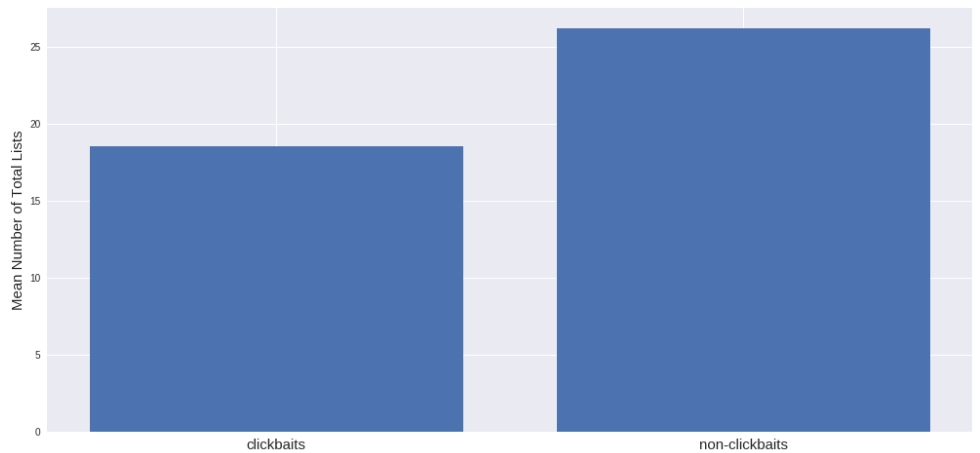
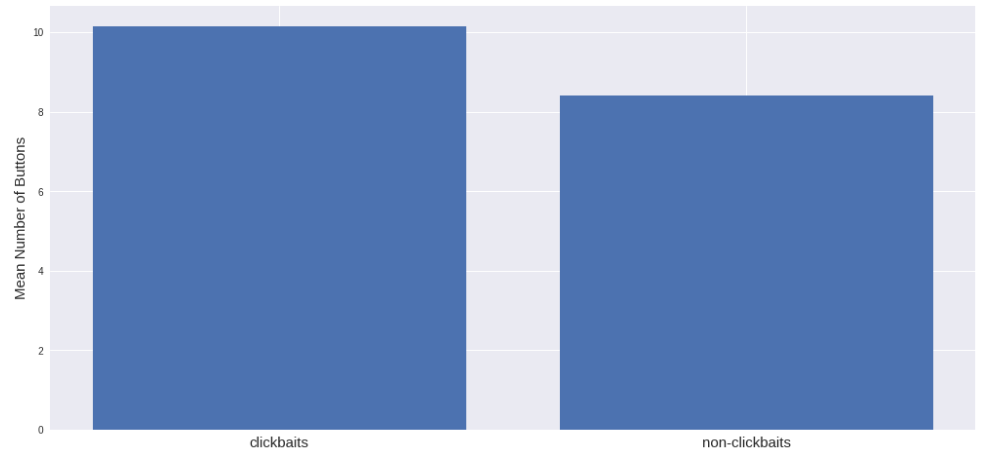
リストの平均数は、clickbaitのあるサイトよりclickbaitのないサイトの方が多いようです。 私はそれが逆になると思ったが、そうでなければデータは納得する。 また、clickbaitを使用するサイトには、より多くのリンクがあることがわかります。
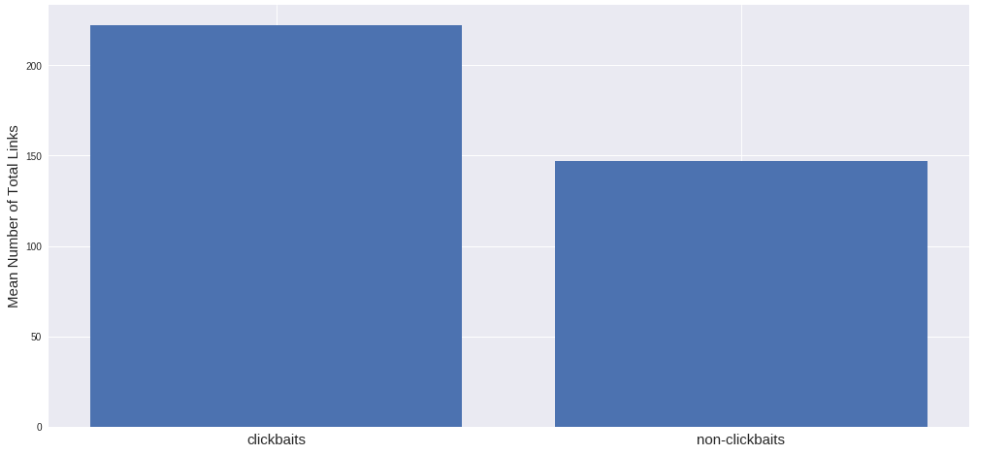
最初は、clickbaitサイトにもっと画像があることを提案しました。 そして、はい、私は正しかったです:
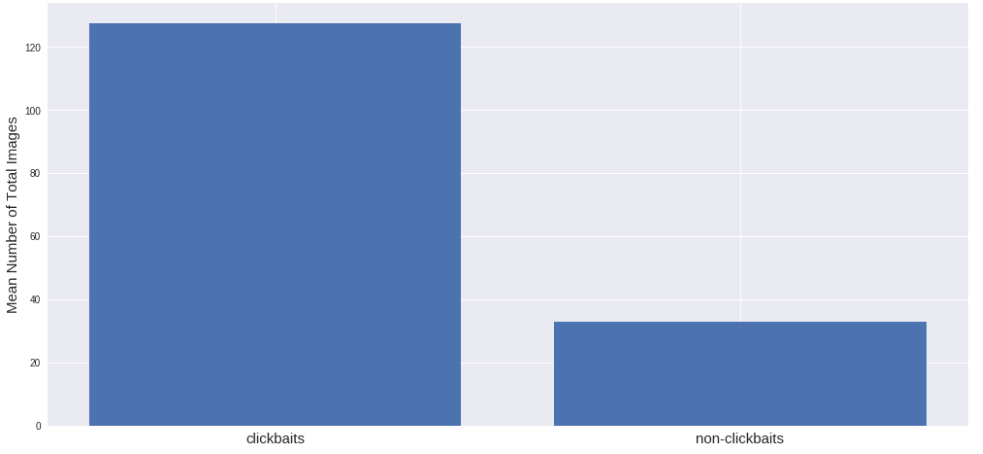
これは彼らが人々を引き付ける方法です。 記事の写真は魚の虫のようなものです:)
ボタンなどのインタラクティブ要素の数はほぼ同じです。
テキストデータを使用する場合、ワードクラウドを作成するのが一般的です:)。
| Clickbait Header Word Cloud |  |
| Clickbait Header Word Cloud |  |
最後に、テキスト属性には次のものが含まれます。
- すべてのテキストH1
- すべてのテキストH2
- メタの説明
もちろん、Webページからより多くのテキスト属性と非テキスト属性を抽出できますが、私は上記のリストに限定しました。 Webページからテキストデータを抽出するこの段階で、再トレーニングを避けるために、対応するWebページのテキストデータからドメイン名も削除しました。
Buzzfeedのテキストには「問題の報告をありがとう」という言葉が含まれていることが多いので、それらも削除しました。 Webページのストップワードの特別なリストも作成しました。

ある瞬間、データは私を満足させ始め、モデルはこのデータで再訓練しないという自信がありました。 その後、クールなディープラーニングモデルの設計を開始しました。 しかし、最初に、最終データを見てください:

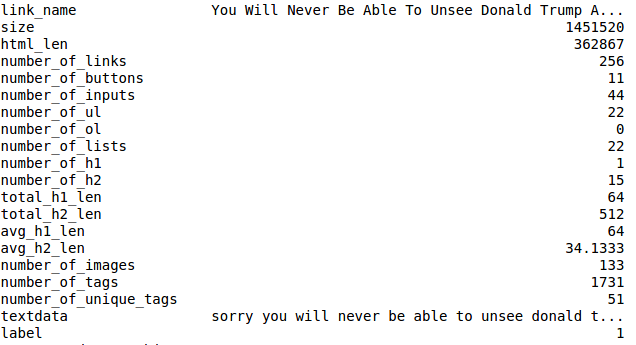
最終的には約50,000個のサンプルになりました。 clickbaitサイトの場合は約25,000、残りのサイトの場合もほぼ同じです。
モデルの作成を始めましょう!
深層学習モデル
深層学習モデルの構築を開始する前に、ラベルバンドルを使用してデータを2つの部分に分割しました(1 = clickbait、0 = non-clickbait)。 これをテストデータと呼び、各サンプルの約2500のサンプルで構成されています。 テストデータはそのままで、モデルの評価にのみ使用されました。 このモデルは、残りの90%のデータ(トレーニング用データ)で構築およびテストされました。
最初に、正のインデックスを固定サイズの密度ベクトルに変換する組み込みレイヤーを備えた単純なLSTMモデルを試しました。 続いて、ドロップアウトとバッチ正規化を伴う2つの高密度レイヤー(高密度)が続きました。

単純なネットワークでは、数期間後の検証セットで0.904の精度が示され、テストセットで0.884の精度が示されます。 私はそれをベンチマークと見なし、パフォーマンスを改善しようとしました。 追加できるコンテンツの兆候がまだあります! おそらくこれにより、検証セットとテストセットの両方の精度が向上します。
次のモデルでは、密層を変更せずにLSTM層を変更せずに、テキストコンテンツ属性を追加し、密層を通過する前にそれらをマージしました。
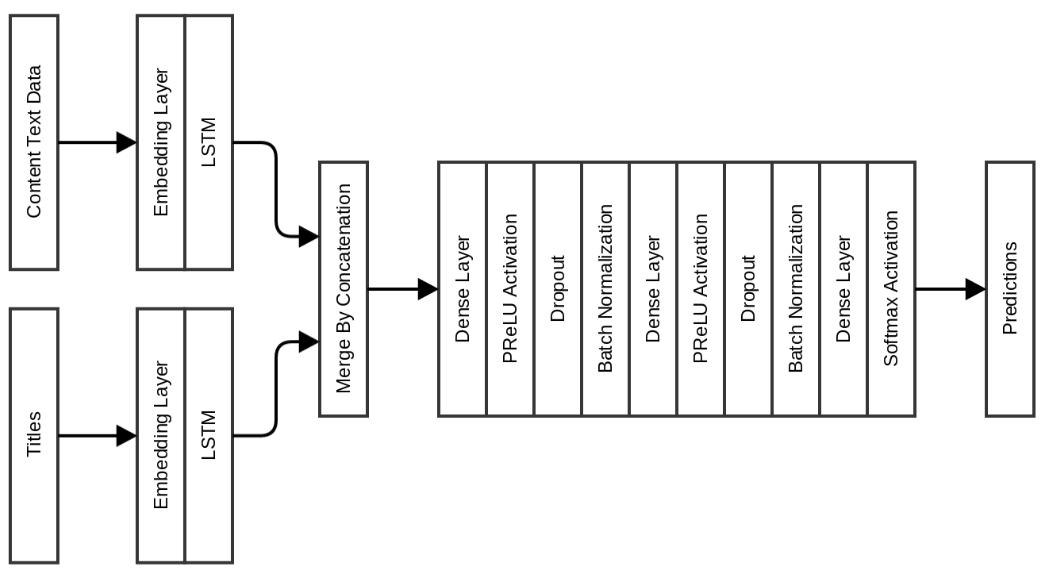
このモデルはベンチマークですぐにパフォーマンスを7%改善しました! 検証の精度は0.975に向上し、テストスイートの精度は0.963に向上しました。 これらのモデルの欠点は、埋め込みを学習する必要があるため、学習に時間がかかることです。 これを克服するために、埋め込みレイヤーの初期化としてGloVeを埋め込む以下のモデルを作成しました。 Common Crawlデータでトレーニングされた8400億の300次元GloVeインサートが使用されました。 これらの挿入物はここからダウンロードできます 。
Quoraでの重複投稿に関する私の記事で説明したように、以前は高密度モデルを配布していました。 挿入はGloVeによって初期化されました。
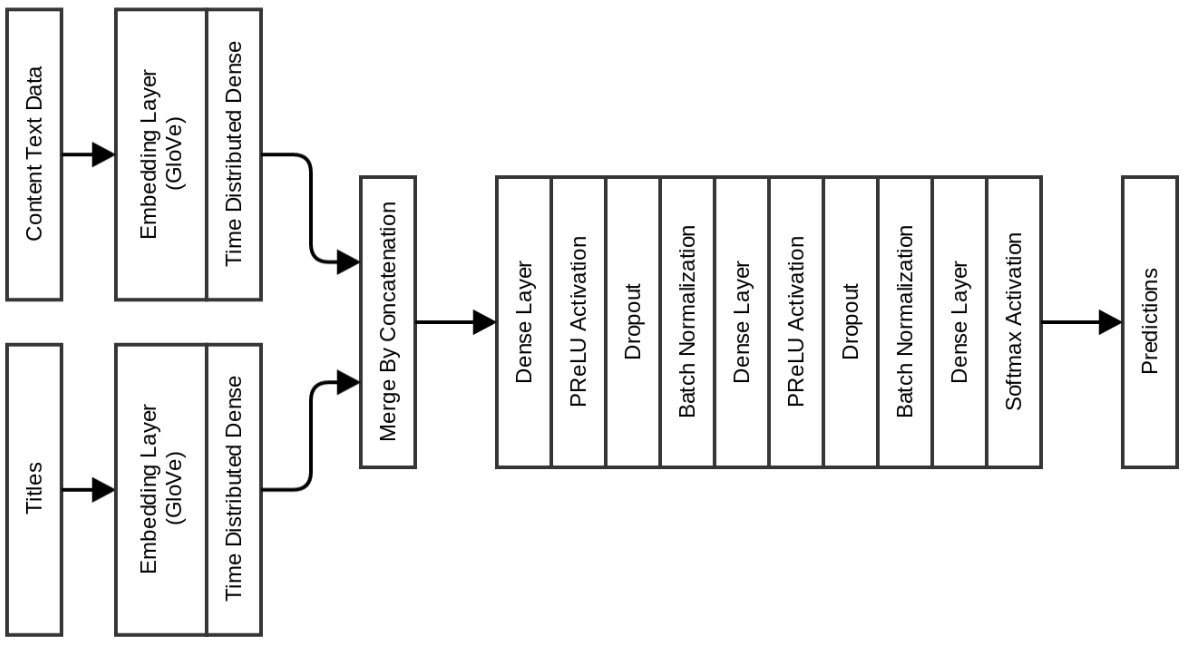
このモデルでは、検証精度が0.977であり、テストスイートの精度は0.971です。 このモデルを使用する利点は、期間ごとのトレーニング時間が10秒未満であるのに対し、以前のモデルは期間ごとに120〜150秒かかったことです。
したがって、クリックベイトを決定するための高速学習者ニューラルネットワークモデルが必要な場合は、上記のいずれかを選択してください。 より正確なモデルが必要な場合は、以下を参照してください:)
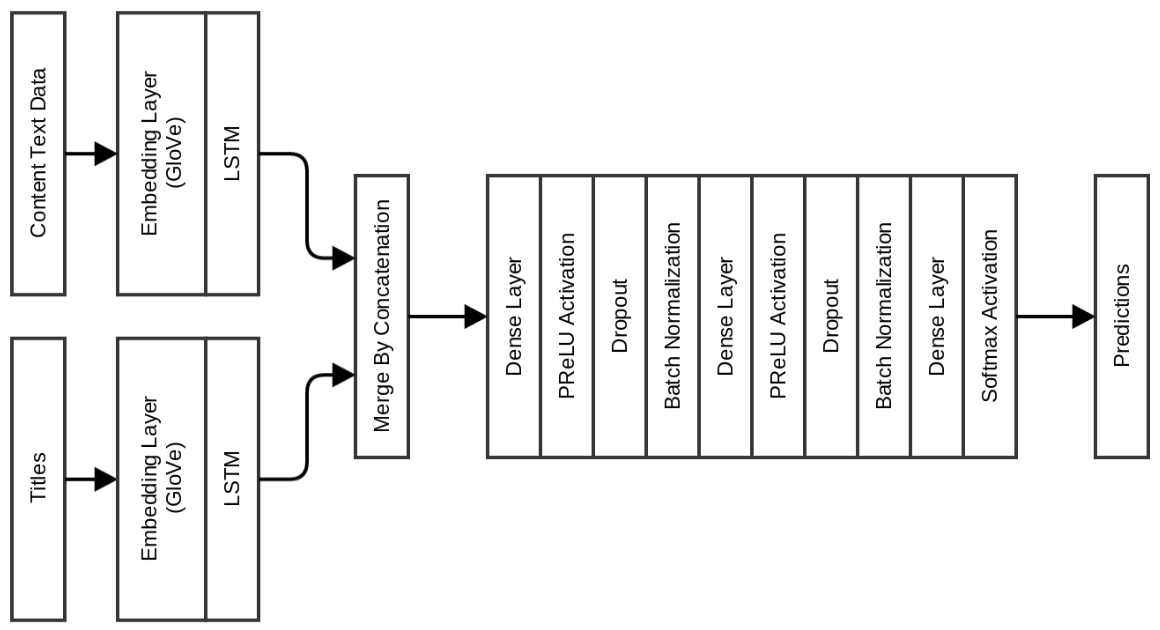
このネットワークにより、検証精度は0.983に大幅に向上しますが、テストの精度はわずかに向上して0.975になりました。
覚えている場合は、URLをクリックしても表示されないものに基づいて数値記号も作成しました。 私の次の最終モデルには、ヘッダーデータとコンテンツテキストのLSTMに加えて、これらの機能も含まれています。
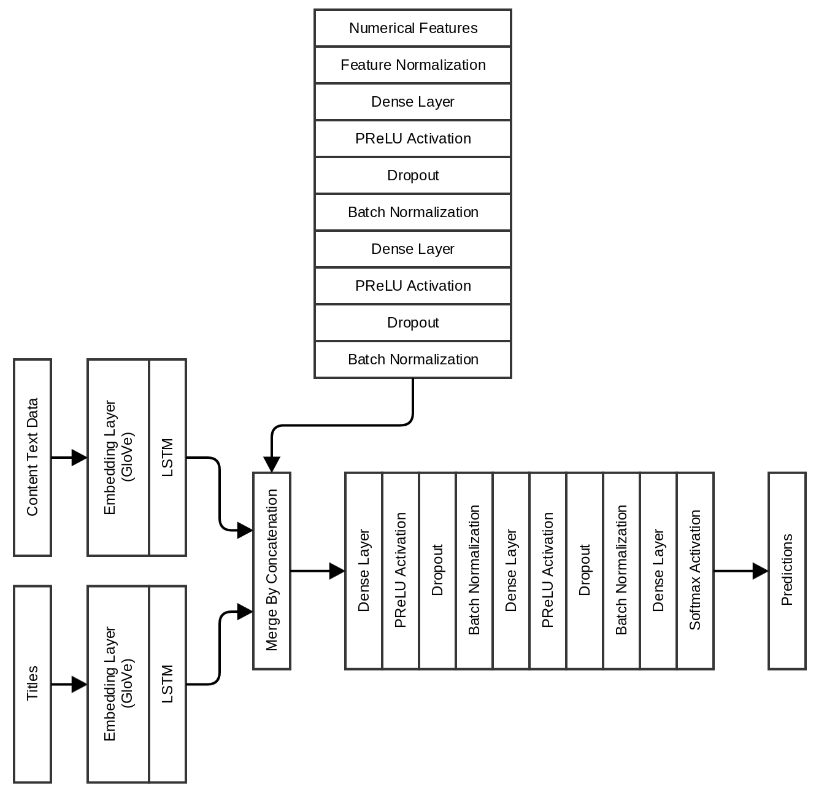
結局のところ、これは、テストスイートでの検証精度が0.996および0.991である最高のモデルです。 この特定のモデルでは、各期間に約60秒かかります。
次の表は、さまざまなモデルによって取得された精度指標をまとめたものです。

まとめると、タイトル、テキストコンテンツ、およびWebサイトの一部の機能を考慮し、検証中とテストスイートの両方で99%を超える精度を示すクリックベイトを決定するためのモデルを構築できました。
私が話したすべてのコードはGitHubで入手できます 。
すべてのモデルは、64 GBのメモリを搭載したUbuntu 16.04システムであるNVIDIA TitanXでトレーニングされました。
力を合わせてclickbaitを停止#StopClickBaits!
質問がある場合は、abhishek4 [at] gmail [dot] comにコメントするかメールしてください。