
3月16日、 ML Boot Camp III機械学習コンテストは終了しました。 私は本当の溶接工ではありませんが、それでも、結果の最終表で7位を達成することができました。 この記事では、このようなチャンピオンシップへの参加を開始する方法を共有したいと思います。これは問題を解決するときに初めて注意を払う価値があり、私のアプローチについてお話します。
MLブートキャンプIII
これは、Mail.Ru Groupが主催するオープンな機械学習チャンピオンシップです。 タスクとして、プレイヤーがオンラインゲームにとどまるか、それとも退場するかを予測することが提案されました。 データとして、主催者は過去2週間の処理済みのユーザー統計を提供しました。
- maxPlayerLevel-プレーヤーが渡したゲームの最大レベル。
- numberOfAttemptedLevels-プレーヤーが通過しようとしたレベルの数。
- triesOnTheHighestLevel-最高レベルで行われた試行の回数。
- totalNumOfAttempts-試行の総数。
- averageNumOfTurnsPerCompletedLevel-正常に完了したレベルで完了した移動の平均数。
- doReturnOnLowerLevels-プレイヤーがすでに完了したレベルでゲームに戻るかどうか。
- numberOfBoostersUsed-使用されるブースターの数。
- fractionOfUsefullBoosters-成功した試行中に使用されたブースターの数(プレーヤーはレベルをパスしました);
- totalScore-得点の合計数。
- totalBonusScore-獲得したボーナスポイントの総数。
- totalStarsCount-得点の合計数。
- numberOfDaysActuallyPlayed-ユーザーがゲームをプレイした日数。
選手権に関する詳細は、プロジェクトのウェブサイトで見つけることができます。
ルールを読む

家電製品の説明書とは対照的に、有用な情報があります。 探すべきもの:
- 入力および出力データの形式。
- 1日あたりの区画の最大数。
- 品質基準/評価関数。
最後の、おそらくルールの最も重要な部分、なぜなら この関数を使用して、最小化(場合によっては最大化)する必要があります。 今回は、 対数損失関数が使用されました。
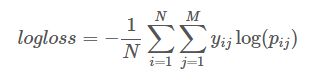
ここに
Nは例の数です
Mはクラスの数です(2つしかありません)
Pijは、例iがクラスjに属する予測確率です。
Yij-例iが実際にクラスjに属する場合は1、そうでない場合は0
この式は、回答に対する自信を強く「罰する」ことに注意することが重要です。 したがって、解決策として、プレイヤーが明確な「1」と「0」の代わりにプレイを続ける確率を送信する方がより有益です。
場合によっては、評価関数を調べると、少しずらして余分なポイントを獲得できます(過去および現在のコンテストの勝者がしたように )。
さまざまなメトリックの詳細については、 こちらをご覧ください 。
ツールキット

チャンピオンシップ中に使用できるツールは多数あります。 機械学習についての人々の話があなたに宣誓のように聞こえる場合、MLを駆け抜けて、 ここで基本的なアルゴリズムに精通することをお勧めします。
今回は、ほとんどの参加者がPythonとRのいずれかを選択しました。一般的な推奨事項:1つの言語に固執し、使用可能なツールの機能をより深く研究します。 両方の言語に適したソリューションがあり、最も人気のあるライブラリ(XGBoostなど)は、あちこちで利用できます。
緊急の必要がある場合は、別のパッケージを使用して、ある種の個別の計算をいつでも行うことができます。 たとえば、t-SNE変換は、Python実装では無力になり、すべてのメモリを消費します。
pythonを選択し、最終的なソリューションでは次のライブラリを使用しました。
- scikit learnは機械学習のための素晴らしいツールキットです。 最初は、彼女だけに制限できます。
- XGBoost-勾配ブースティング。 機械学習選手権のお気に入りのライブラリの1つ。
- LightGBMはXGBoostの代替です。私の場合、前回よりも1桁速く動作しましたが、結果の精度はわずかに低下しました。
- Lasagneは、Theanoを使用してニューラルネットワークを作成およびトレーニングするためのライブラリです。 別の方法として、Kerasを試すことができます-それは少し単純に見え、それに関するより多くのドキュメントに出くわしました。 しかし、交差点の馬は変わらず、最初の選択に固執することにしました。
最初の提出

最初に、すべての入力データを読み取って、ゼロのみで構成されるテスト回答を表示してみましょう。
>>> import numpy as np >>> import pandas as pd >>> X_train = pd.read_csv('x_train.csv', sep=';') >>> X_test = pd.read_csv('x_test.csv', sep=';') >>> y_train = pd.read_csv('y_train.csv', header=None).values.ravel() >>> print(X_train.shape, X_test.shape, y_train.shape) (25289, 12) (25289, 12) (25289,) >>> result = np.zeros((X_test.shape[0])) >>> pd.DataFrame(result).to_csv('submit.csv', index=False, header=False)
データのロード/保存を確認し、評価用の基準点を受け取ったら、単純なモデルをトレーニングできます。 例として、RandomForestClassifierを取り上げました。
>>> from sklearn.ensemble import RandomForestClassifier >>> clf = RandomForestClassifier() >>> clf.fit(X_train, y_train) >>> result = clf.predict_proba(X_test)[:,1] >>> pd.DataFrame(result).to_csv('submit.csv', index=False, header=False)
前の例を再度実行して検証のために結果を送信すると、高い確率で別の推定値が得られます。 これは、多くのアルゴリズムが乱数ジェネレーターを使用するためです。 この動作は、最終結果に対するモデルの将来の変更の影響の評価を非常に複雑にします。 この問題を回避するために、次のことができます。
>>> np.random.seed(2707) >>> clf = RandomForestClassifier(random_state=2707) ...
または
>>> runs = 1000 >>> results = np.zeros((runs, X_test.shape[0])) >>> for i in range(runs): … clf = RandomForestClassifier(random_state=2707+i) … clf.fit(X_train, y_train) … results[i, :]=clf.predict_proba(X_test)[:,1] >>> result = results.mean(axis=0)
2番目のオプションでは、より安定した結果が得られますが、計算により多くの時間を必要とすることは明らかであるため、既に最終チェックに使用しました。
その他の例は、オーガナイザーのチュートリアルにあります。 ここでは、カテゴリ属性の操作に関する情報を見つけることができますが、この記事では触れません。
データ準備

エントリーのしきい値を下げるために、主催者はデータをかなり適切に準備しましたが、さらに精製する必要はありませんでした。 さらに、トレーニングセット内の重複または外れ値を削除しようとしても、結果が悪化するだけでした。
重複については、それらがしばしば異なるクラスに属していることに注意する価値があります(同じデータを持つユーザーはゲームにとどまり、ゲームを離れることができます)。追加情報がなければ正確な予測をすることは困難です。 幸いなことに、ほとんどのモデルは独自にこれを行い、評価関数(この場合はログ損失)を最小化する確率を導き出しました。
UPD:3位の参加者は、この事実を彼の利益のために使用することができました。
オーガナイザーが作成したデータは、ルールの例外です。つまり、ルールを自分で処理するための準備が必要です。 重複する行と外れ値に加えて、データには欠損値が含まれる場合があります。 欠損値のある行を削除するのは無駄です 有用な情報がまだ含まれています。 したがって、2つのオプションが残っています。
- そのままにしておきます。一部のアルゴリズムは欠損値(NA)を処理できます。
- それらを復元してみてください。
復元するには、単純に、より一般的な(カテゴリ記号)、平均値、または中央値に置き換えることができます。 Pythonでは、このためにsklearn.preprocessing.Imputerクラスを使用できます。 他の属性(たとえば、同じレベルのユーザー間の平均値)を使用するより複雑な方法があります。他の列の欠損値を予測する別のモデルをトレーニングしようとしました。 そうそう、私は上記でデータが準備されており、欠損値がないことを書きました。実際、これは完全に真実ではありません。
ルールを注意深く読むと、ほとんどすべての兆候が2週間のログに基づく統計であることが明らかになります。 データのより詳細な調査によると、多くのユーザーが2週間前より早くプレイを開始しました。 それらが除外された場合、交差検証で信じられないほど良い成績を受け取り、残りの「汚れた」データの予測を改善することが勝利の鍵になると考えさせられました。 2週間前の時点でユーザーのデータを復元しようとしても大幅な増加はありませんでしたが、このソリューションを残し、後で他のソリューションと併用しました。
私に発生した別のトリックは、そのようなユーザーの属性の一部に-1を掛けることでした。 これは、トレーニング中に他のマスからそれらを分離し、特にメソッドの単純さを考えると、それ自体をよく示しています。
すべてのデータ:
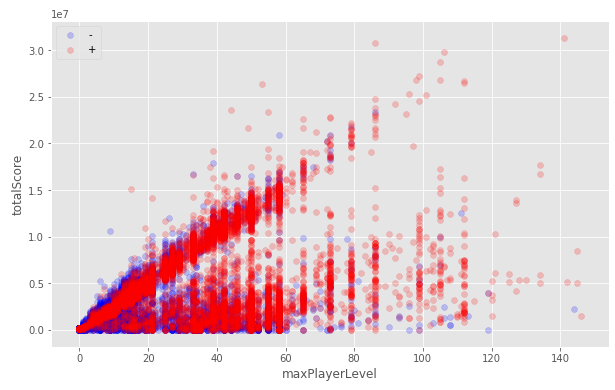
2週間以内にプレイを開始したユーザーのみ:

他の列からデータを回復しようとしています:
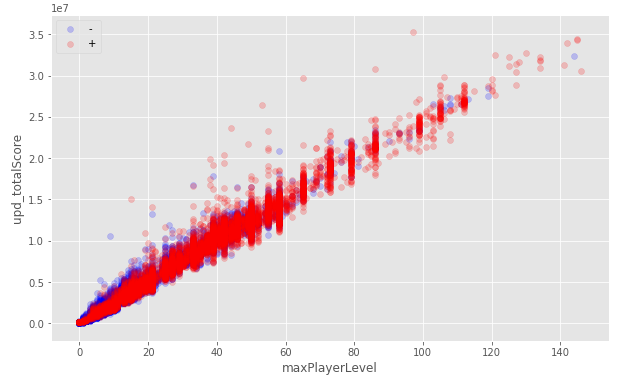
2週間前にプレイを開始したユーザー向けの「反転」:

特定のケースでは、すぐにいくつかの兆候を取り除くことが理にかなっています:
- 定数記号;
- 2つの強く相関する記号(必要なのは1つだけです)。
- ゼロ分散に近いサイン。
これにより計算速度が向上し、モデルの全体的な品質が向上する場合もありますが、機能の削除には非常に注意する必要があります。
最初の段階でデータを使用して最後にできることは、スケーリングです。 それ自体では、属性間の依存関係を変更しませんが、一部の(線形など)モデルの予測を大幅に改善できます。 Pythonでは、このためにsklearn.preprocessing.StandardScaler 、 sklearn.preprocessing.MinMaxScalerおよびsklearn.preprocessing.MaxAbsScalerのクラスを使用できます。
各データ変換は慎重に確認する必要があります。 ある場合に機能するものは、別の場合にはマイナスの効果をもたらし、逆もまた同様です。
常に(!)テストサンプルがトレーニングとまったく同じ変換を行うことを確認します。
自分自身を確認する

データセット全体は、トレーニングサンプルとテストサンプルの2つの部分に分かれています。 テストサンプルは、40/60の比率でパブリックと非表示に分割されます。 モデルがパブリックパーツの結果をどの程度正確に予測したかによって、チャンピオンシップ全体のリーダーボードの位置が決まり、非表示のパーツの予測スコアは最後にのみ利用可能になり、参加者の最終的な位置が決まります。
テストサンプルの公開部分の結果のみに焦点を当てると、モデルの再トレーニングと隠れた結果の発見後の評価の大幅な低下につながる可能性が高くなります。 これを回避し、モデルがどのように改善/悪化したかをローカルで確認できるようにするために、相互検証が使用されます。

データをK個のフォールドに分割します。K-1個のフォールドでトレーニングし、残りについては予測スコアを予測および計算します。 したがって、すべてのKフォールドについて繰り返します。 最終マークは、各フォールドの平均マークと見なされます。
平均値に加えて、推定値の標準偏差(std)に注意する価値があります。このパラメーターは、フォールドの平均推定値よりもさらに重要になる可能性があります。 は、さまざまなフォールドの予測の広がりがどれほど強いかを示しています。 stdの値はKの増加とともに大きくなる可能性があります。これを覚えておく価値があり、怖がらないでください。
重要な役割は、折り畳みの品質にあります。 分解時にクラス分布を維持するために、 sklearn.model_selection.StratifiedKFoldを使用しました 。 これは、クラスが最初は非常に不均衡な場合に特に重要です。 さらに、折り目(曜日、時間、ユーザーなど)によるデータの配布には他の問題がある可能性があり、個別に確認および修正する必要があります。
前と同様に、乱数ジェネレーターを使用する場合は常に、シード値を修正して、結果を再現できるようにします。
>>> from sklearn.model_selection import StratifiedKFold, cross_val_score >>> clf = RandomForestClassifier(random_state=2707) >>> kf = StratifiedKFold(random_state=2707, n_splits=5, shuffle=True) >>> scores = cross_val_score(clf, X_train, y_train, cv=kf) >>> print("CV scores:", scores) CV scores: [ 0.8082625 0.81059707 0.8024911 0.81431679 0.81926043] >>> print("mean:", np.mean(scores)) mean: 0.810985579862 >>> print("std:", np.std(scores)) std: 0.00564433052781
相互検証にさまざまなスキームを使用して、ローカル評価とパブリック評価の違いを最小限に抑えることが望ましいです。 推定値が一致せず、ローカル相互検証が正しいと見なされる場合、ローカル評価に依存するのが慣例です。
モデルを複雑にします(機能するものは見苦しくありません)

チューニング
MOアルゴリズムのハイパーパラメーターの選択は、クロス検証でこれらのパラメーターを使用してモデルの推定値を返す関数を最小化するタスクと見なすことができます。
この問題を解決するためのいくつかのオプションを検討してください。
- Bruteforce( sklearn.model_selection.GridSearchCV )。 徹底的な検索にもかかわらず、この方法は非常に効果的です。 XGBoostモデルを調整しました。 そして、これを行う方法に関する良いガイドがあり 、数日待つことはありません。 この方法は、時間を節約するためにハイパーパラメーターの意味をよりよく理解できるため、優れています。
- ランダム化されたブルートフォース( sklearn.model_selection.RandomizedSearchCV )。 さらに、パラメーターの数に関係なくリバウンドの数を設定できることに注意してください。
- ハイパーオプト 。 レイヤーの数が異なるニューラルネットワークを含め、多数のハイパーパラメーターを一度に選択できます。これは、反発する構成を見つける必要がある場合に特に便利です。
- 微分進化 。
- 手動フィットなど
ちなみに、相互検証にScikit Learnライブラリのcros_val_score
メソッドを使用する場合、一部のアルゴリズムはトレーニング中に最小化するメトリックをfit
メソッドに取り入れることができます。 また、このパラメーターを相互検証用に設定するには、 fit_params
を使用する必要があります。
UPD:xgboostおよびLightGBMライブラリのeval_metric
パラメーターは、eval_setが早期停止のために評価されるメトリックを設定します。 言い換えると、データセットがfitメソッドに渡され、勾配ブースティングの各ステップでeval_metric
を使用してモデルが評価されますeval_metric
してステップする場合、 early_stopping_rounds
の評価は改善されず、トレーニングは停止します。
clf = xgb.XGBClassifier(seed=2707) kf = StratifiedKFold(random_state=2707, n_splits=5, shuffle=True) scores = cross_val_score(clf, X_train, y_train, cv=kf, scoring='neg_log_loss', fit_params={'eval_metric':'logloss'})
キャリブレーション(hello Garus!)
キャリブレーションの考え方は、モデルがクラス0.6に属するという予測を与えると、モデルがこの予測を与えたすべてのサンプルのうち、60%が実際にこのクラスに属するということです。 Scikit Learnのライブラリには、このためのsklearn.calibration.CalibratedClassifierCVクラスが含まれています。 これにより評価を改善できますが、相互検証メカニズムがキャリブレーションに使用されることを覚えておく必要があります。これは、トレーニング時間が大幅に増加することを意味します。
from sklearn.ensemble import RandomForestClassifier from sklearn.calibration import CalibratedClassifierCV kf = StratifiedKFold(random_state=2707, n_splits=5, shuffle=True) clf = RandomForestClassifier(random_state=2707) scores = cross_val_score(clf, X_train, y_train, cv=kf, scoring="neg_log_loss") print("CV scores:", -scores) print("mean:", -np.mean(scores)) clf = CalibratedClassifierCV(clf,method='sigmoid', cv=StratifiedKFold(random_state=42, n_splits=5, shuffle=True)) scores = cross_val_score(clf, X_train, y_train, cv=kf, scoring="neg_log_loss") print("CV scores:", -scores) print("mean:", -np.mean(scores)) CV scores: [ 1.12679227 1.01914874 1.24362513 0.97109882 1.07280166] mean: 1.08669332288 CV scores: [ 0.41028741 0.4055759 0.4134125 0.40244068 0.39892905] mean: 0.406129108769 <---
バギング
考え方は、トレーニングサンプルと属性の異なる(不完全な)セットで同じアルゴリズムを実行し、そのようなモデルの平均予測を使用することです。 いつものように、Scikit Learnにはすでに必要なものがすべて含まれているため、 sklearn.ensemble.BaggingClassifierクラスを使用するだけで時間を大幅に節約できます。
from sklearn.ensemble import RandomForestClassifier, BaggingClassifier kf = StratifiedKFold(random_state=2707, n_splits=5, shuffle=True) clf = RandomForestClassifier(random_state=2707) scores = cross_val_score(clf, X_train, y_train, cv=kf, scoring="neg_log_loss") print("CV scores:", -scores) print("mean:", -np.mean(scores)) clf = BaggingClassifier(clf, random_state=42) scores = cross_val_score(clf, X_train, y_train, cv=kf, scoring="neg_log_loss") print("CV scores:", -scores) print("mean:", -np.mean(scores)) CV scores: [ 1.12679227 1.01914874 1.24362513 0.97109882 1.07280166] mean: 1.08669332288 CV scores: [ 0.51778172 0.46840953 0.52678512 0.5137191 0.52285478] mean: 0.509910050424
もちろん、これをキャリブレーションと併用することを禁止する人はいません。
複合モデル
データをグループに分割して、異なるモデルを使用して予測する方が収益性が高いことは珍しくありません。 たとえば、一部の参加者は、プレーヤーのレベルに応じて異なるグループに分割し、異なるモデルで予測しました。
私の最高のモデルはこの原理を使用しました。 2つのグループに分けました。2週間以内にプレイを開始したグループと、それよりも早く開始したグループです。 さらに、最初のグループでは、最初のレベルを記録した時点のユーザーも追加しました。 これにより、全体的な評価が改善されました。 モデルとして、私はxgboostを異なるハイパーパラメーターで使用し、異なる記号セットを使用しました。 さらに、2番目のモデルをトレーニングするときにすべてのデータを使用しましたが、2週間前より早くプレイを開始したユーザーの場合、3に等しい重みを付けました。
汚いトリック
競争と機械学習アルゴリズムの実際の使用は完全に異なるものであることを理解する必要があります。 ここでは、巨大で遅いモデルを作成できます。これにより、計算に余分な日数がかかるため、評価の精度のパーセンテージが得られます。また、回答を手動で修正して精度を上げることもできます。 最も重要なことは、公開評価の再訓練に注意してください。
より多くのデータ!

私たちに提供されたデータから情報の最後の一滴を絞るために、あなたは(必要!)新しい兆候を生成しようとすることができます。 提供されるデータから適切な属性セットを作成することは、多くの場合、機械学習のチャンピオンシップを獲得する重要な要素です。
- 既存の特性を互いに乗算または分割することは、簡単ですが効果的な方法です。
- 新しい機能の抽出。 たとえば、日付からの曜日、テキストからの文字数など。
- 既存のフィーチャの非線形変換により、値の分布を通常に近づけることができます。これにより、場合によっては(同じニューラルネットワークが)最良の結果が得られます。 例:log(x)、log(x + 1)、sqrt(x)、sqrt(x + 1)など
- その他 あなたが十分な想像力を持っているすべて:番号を分割する2つの最大次数、社長との年齢差など。 最終モデルで使用された、私が生成したサインの1つは、次の式で計算されました。
raw_data['totalScore'] / (1 + np.log(1+raw_data['maxPlayerLevel']) * raw_data['maxPlayerLevel'])
多くの新しい兆候があるので、最高のスコアを与える最適なセットを何らかの方法で選択する必要があります。
PCAまたはTruncatedSVDを使用すると、特徴空間の次元を小さくして、アルゴリズムの速度を上げることができます。 ただし、データ間の非線形関係を無視するだけでなく、重要な機能を完全に失う大きなリスクがあります。
勾配ブースティングなどの多くのアルゴリズムは、デバイスが原因で、訓練されたモデルの特定の属性の重要性に関する情報を非常に簡単に取得できます。 この情報は、重要でない列を除外するために使用できます。
import matplotlib.pyplot as plt import xgboost as xgb from xgboost import plot_importance clf = xgb.XGBClassifier(seed=2707) clf.fit(X_train, y_train, eval_metric='logloss') for a, b in sorted(zip(clf.feature_importances_, X_train.columns)): print(a,b, sep='\t\t') plot_importance(clf) plt.show()
0.014771 numberOfAttemptedLevels 0.014771 totalStarsCount 0.0221566 totalBonusScore 0.0295421 doReturnOnLowerLevels 0.0354505 fractionOfUsefullBoosters 0.0531758 attemptsOnTheHighestLevel 0.0886263 numberOfBoostersUsed 0.118168 totalScore 0.128508 averageNumOfTurnsPerCompletedLevel 0.144756 maxPlayerLevel 0.172821 numberOfDaysActuallyPlayed 0.177253 totalNumOfAttempts

いつものように、標識の除去には非常に注意する必要があります。 重要でない特徴を削除すると予測の精度が損なわれる可能性がありますが、逆に最も重要な特徴を削除すると改善されます。 この方法を使用して、完全に絶望的な兆候を排除しました。
形質を選択するためのより古典的なアプローチがあります。 このコンテストでは、貪欲アルゴリズムを集中的に使用しました。そのアイデアは、セットに新しい機能を1つずつ追加し、最適な相互検証スコアを与えるものを選択することです。 また、サインを一度に1つずつ捨てることもできます。 これらのアプローチを交互に繰り返して、最終サンプルを採点しました。 これは書きやすいアルゴリズムですが、他のいくつかのセットとセットの精度を向上させる機能は無視されます。 この観点から、特性の使用をバイナリベクトルでエンコードし、遺伝的アルゴリズムを使用する方が生産的です。
エラー処理

もちろん、名声と賞品は素晴らしいものですが、今回の私の主な動機は経験と知識を得ることでした。 そして、もちろん、学習プロセスには間違いがないわけではありません。 その分析により、私が何をしているかを最も理解することができました。 そして、あなたが私と同じくらい新しいなら、私のアドバイスは:すべてを試してみてください。 いくつかの異なる結果が得られるため、それぞれを他と比較して評価し、それらを互いに比較するのが簡単です。 そして、何が起きているのかがアルゴリズムの動作をより深く理解することにつながる理由を自分自身に説明しようとします。
上記の記事で説明したデータとモデルを使用するプロセスは線形ではなく、チャンピオンシップ中に定期的に新しいモデルに戻り、新しい機能の生成とそれらのモデルの調整に戻りました。 その結果、いくつかの優れたモデルが蓄積され、その結果を最終予測に使用しました。
あなたが死んだ場所で立ち往生している場合:
- ローカルミニマムについて覚えておいてください。おそらくいくつかのアイデアは最初に現在のアイデアよりも悪い結果をもたらすかもしれませんが、そのさらなる開発または他のアイデアとの組み合わせがあなたの「キラー機能」になります。
- ほとんど常に、課題のトピックに関する科学論文を見つけることができます。
- 他の選手権の参加者の決定を研究する(kaggle);
- さまざまなモデルまたはさらに多くの機能を生成してみてください。
より多くのモデル!

何度も苦しみ、眠れぬ夜を過ごした後、地元の履歴書で、そして理想的には一般に良いマークで、良いモデルを手に入れたとしましょう。 さらに、品質がやや劣るモデルをさらに2つ入手しました。 すぐに最後を投げないでください。 実際には、いくつかのモデルの予測をさまざまな方法で組み合わせて、さらに正確にすることができます。 これは非常に大きなトピックであり、 この記事から始めることをお勧めします 。 ここで、心に浮かんだ複雑さの異なる2つの方法を共有します。
最も単純なアプローチ、そして私の場合はより効果的なアプローチは、いくつかのモデルのソリューション間の平凡な算術平均であることが判明しました。 この方法のバリエーションとして、幾何平均を使用したり、モデルに重みを追加したりできます。
2番目のアプローチはスタッキングです。 ここでは、オート麦を食べることができます...アイデアは簡単です。第1レベルモデルの予測を別のアルゴリズムへの入力として使用します。 これらの予測に初期データが追加されたり、新しい機能を生成するために第1レベルのモデルの結果が使用される場合があります。 , ( -), . : holdout set out-of-fold predictions.
Holdout set — (~10%) , , . , .
OOF predictions — K , K-1 . . : , (Variant ), , -1 , (Variant A).

def get_oof(clf): oof_train = np.zeros((X_train.shape[0],)) oof_test = np.zeros((X_test.shape[0],)) oof_test_skf = np.empty((NFOLDS, X_test.shape[0])) for i, (train_index, test_index) in enumerate(kf.split(X_train, y_train)): x_tr = X_train[train_index] y_tr = y_train[train_index] x_te = X_train[test_index] clf.train(x_tr, y_tr) oof_train[test_index] = clf.predict_proba(x_te)[:, 1] oof_test_skf[i, :] = clf.predict_proba(X_test)[:, 1] oof_test[:] = oof_test_skf.mean(axis=0) return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)
? , (data leak), , . , , , .
1: OOF predictions -.
2: K~=10, 1 holdout set.
, , . -, , , .
自分を繰り返さないでください

, . . , / , -, OOF , - .. , , , . , , .
, , . .
まとめ
. telegram . , 6 8 .

GitHub .
, , , .
, .