
フロントオフィス生物学
目的:銀行には、製品ごとに膨大な種類の銀行商品とサービスがある銀行があります(詳細については、 www.sberbank.ruを参照してください )。 異なる顧客グループのチャネルごとに、製品ごとにすべてのフロントエンドシナリオを自動化する必要があります(はい、はい-顧客カテゴリごとに1つのチャネルに異なるサービスシナリオを設定できます)。
退屈でわかりにくいように聞こえますが。 ただし、金融セクターを自動化する必要があった人は、自動化のためのフロントエンドシナリオの数と必要な機能要素の数を把握できます。 単純な工学的推定値は、おおよそ次の指標を示します。
- シナリオの数(前処理):〜10 3
- スクリプト内のビジュアルフォームの数:〜10 4
- スクリプト内の印刷フォームの数:〜2ᵡ10 3
すでに良い。 何らかのテクスチャーがありますが、これまでのところ、これはダイナミクスや進化のない何らかの凍結されたエコシステムです。
しかし
- 製品の総数とサービスシナリオに依存している人は、四半期ごとに新しい販売計画に同意し、クロスセリングの一環として古いスクリプトを置き換え、追加の「ハイブリッド」シナリオを選択する必要がある新しい製品とプロモーションを発行します。 1年間、古い機能はすべて新しいものに置き換えることができます。
- 視覚フォームのデザインが定期的に依存する人々は、デザインまたはフォーム記入の原則のいずれかを根本的に変更する傾向があり、スクリプト、フォーム、関連機能のすべての集団の置き換えを想定し、最大で10桁まで増加させる必要があります
- ロシア連邦中央銀行は、恐竜を殺したmet石として、すべての人に影響を与える可能性があり、機能全体を見直して修正するための新しい条項が必要です。
しかし、機能の数の増加に好影響を与える要因もあります。
- セグメント指向またはパーソナライズされたサービスプロセスを構築する可能性に対するビジネスへの期待。これは、サービスシナリオの数が10個まで増加するための良い土です
- 当然、すべてのシナリオは、ランディングページの有効性、またはオペレーター自身の職場の利便性についてテストする必要があります。これにより、シナリオ自体の数が生成されない場合、視覚フォームの人口が10 5-6まで増加します
- 種内闘争には長期的な傾向があります。 たとえば、リモートメンテナンスはオフィスサービスを締め出し、リモートチャネルのフロントエンド機能は独自に成長します。 同時に、オフィスはあきらめません-「リモート遺伝子プール」の一部を取得し、オムニチャネルサービスの新しいシナリオを作成しようとします-〜105 -∞
前頭汎関数は、栄養培地中の細菌のように増殖および進化する傾向があり、サービスチャネルの陳腐化を除き、外部の影響は指数の成長のみを曲げます。 Sberbankのフロントオフィス機能用のペトリバレルは、Unified Frontal System、つまりEFSである必要があります。
バビロニア系ではない
当然のことながら、このスケールの自動化は片方だけで構築することはできず、その後の変更をサポートしません。 水平な漸近線上にビルダーの膝の総数を表示するソリューションは、それほど明白ではありません。 たくさんのレンガがあり、それらを非常に迅速に折り畳む必要があるという事実に加えて、上部のフロアを崩壊させることなく、下部のフロアのフロアを交換できる必要もあります。
ターゲットソリューションの計算の複雑さは低く、機能は主にレゴブリックのような標準的なものに分解されるため、RADは高いビルド速度を実現します。
RAD自体は、ほぼすべてのフロントエンド業界ソリューションで利用できます。 ただし、構成コアまたは粒度の弱いアーキテクチャに基づいて構築されているため、上記の問題を重複で解決することはできません。 当然、これは構成コアには当てはまりません。サポート構造を削除または交換すると、必須の回帰とともに適用された機能全体が崩壊、再構築されます。
さらに、構成コアでは、前述の機能量の指数関数的増加という期待に応えることができません。 RADは通常の機能では高速ですが、RADでは既存のベースに基づいて新しいバットを「スポーン」することはできません。
ソリューションは、MDD(モデル駆動型開発)から来ました。 これは一見「主題指向言語」にすぎません-それは抽象的で難解なものです。 構成自体の「サブジェクト指向言語」を作成することを誰も気にしません。 さらに、タワーの異なるフロアの構成:アーキテクチャ、機能、銀行のエリア自体を相互に変換し、最終的に実行可能なコードに変換できます。 次のMDDの利点に依存しました。
- 最終的な実行可能コードは、変換アルゴリズムに触れることなく、常に再定義または機能を追加して、重要なプライベートソリューションを取得できます。
- 変換アルゴリズム自体は、すでに生成されたコードを変更せずに置き換えおよび拡張できます。 上で言ったように、彼の寿命は長くありません
- そして最も重要なことです。 既製のアプリケーション機能は、モデルの1つのタイプにすぎず、最終的なコードにすぎません。 そのため、彼にとっては、必要に応じて、アーキテクチャ、中央銀行の要件、A / Bテストを自動化する必要性、チャネルおよび消費者セグメント向けの特別なサービスシナリオを置き換えるときに、別のモデルでそれを追い越すアルゴリズムを考え出すことができます。
それで、タワーを作る方法を理解するようになりました。それはいつか自分自身を構築し始めなければなりません。
魔法の獣とそれが住む場所
実はこの魔法の獣です
 生成プロセスを開始するためにボタンに留まります。 ユーザーの職場の様子は、以下のスクリーンショットに示されています。
生成プロセスを開始するためにボタンに留まります。 ユーザーの職場の様子は、以下のスクリーンショットに示されています。
建築家のワークステーション

AWPシステム分析

AWPシステム分析
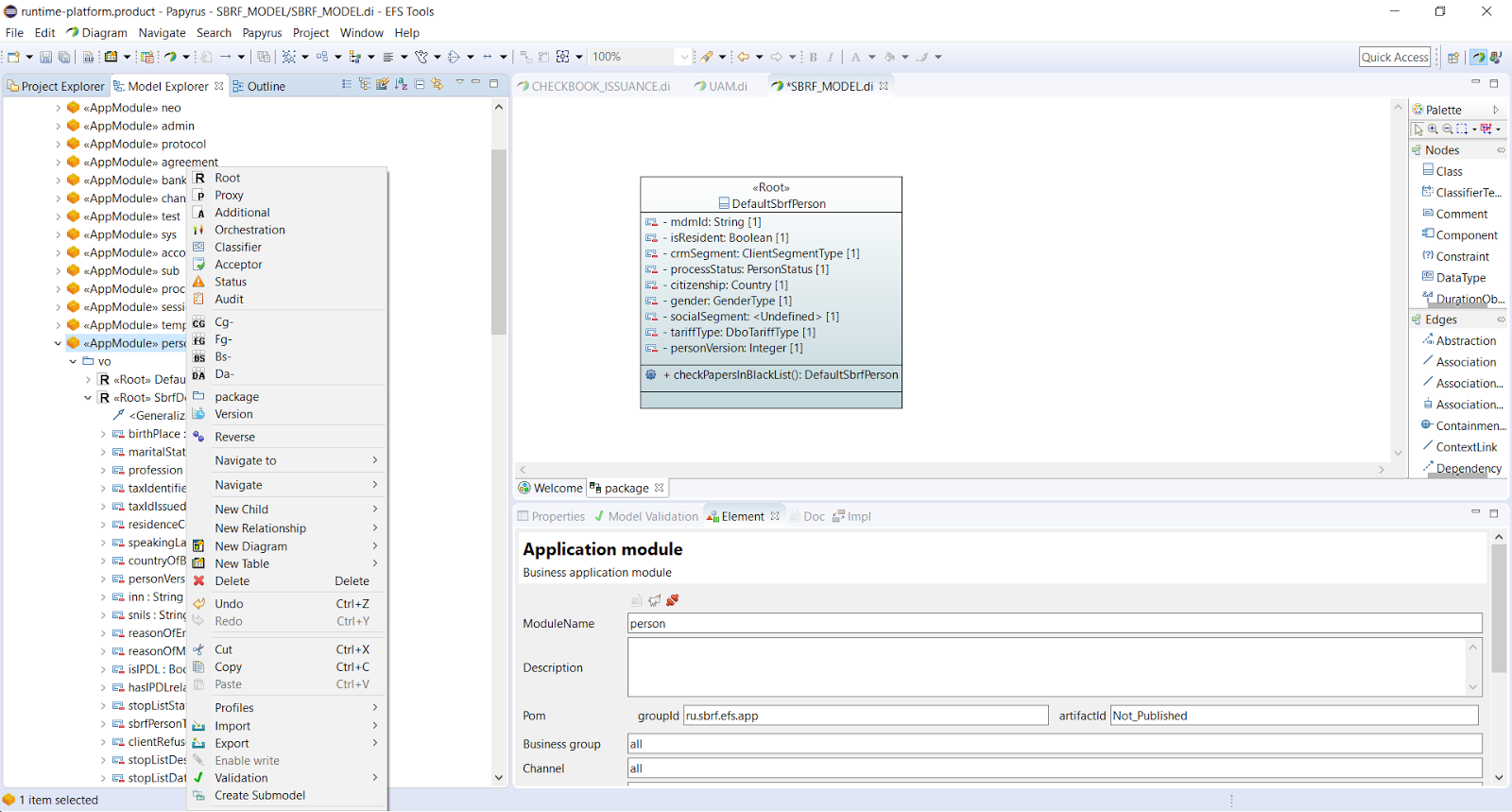
はい、システムアナリストをEclipse + Papyrusの背後に置きます。 これまでのところ、一般的な構成モデルは、レンダリングされたUMLオブジェクトのツリーに基づいて構築されており、要件の一般的な分解、プロセス構成のアーティファクト、ビジュアルフォーム、統合ポイント、エンティティとその属性、参照、 ESFプラットフォーム自体のシステムオブジェクトの束を構成できます。 少し後にJasperReportエディターが作成されます。
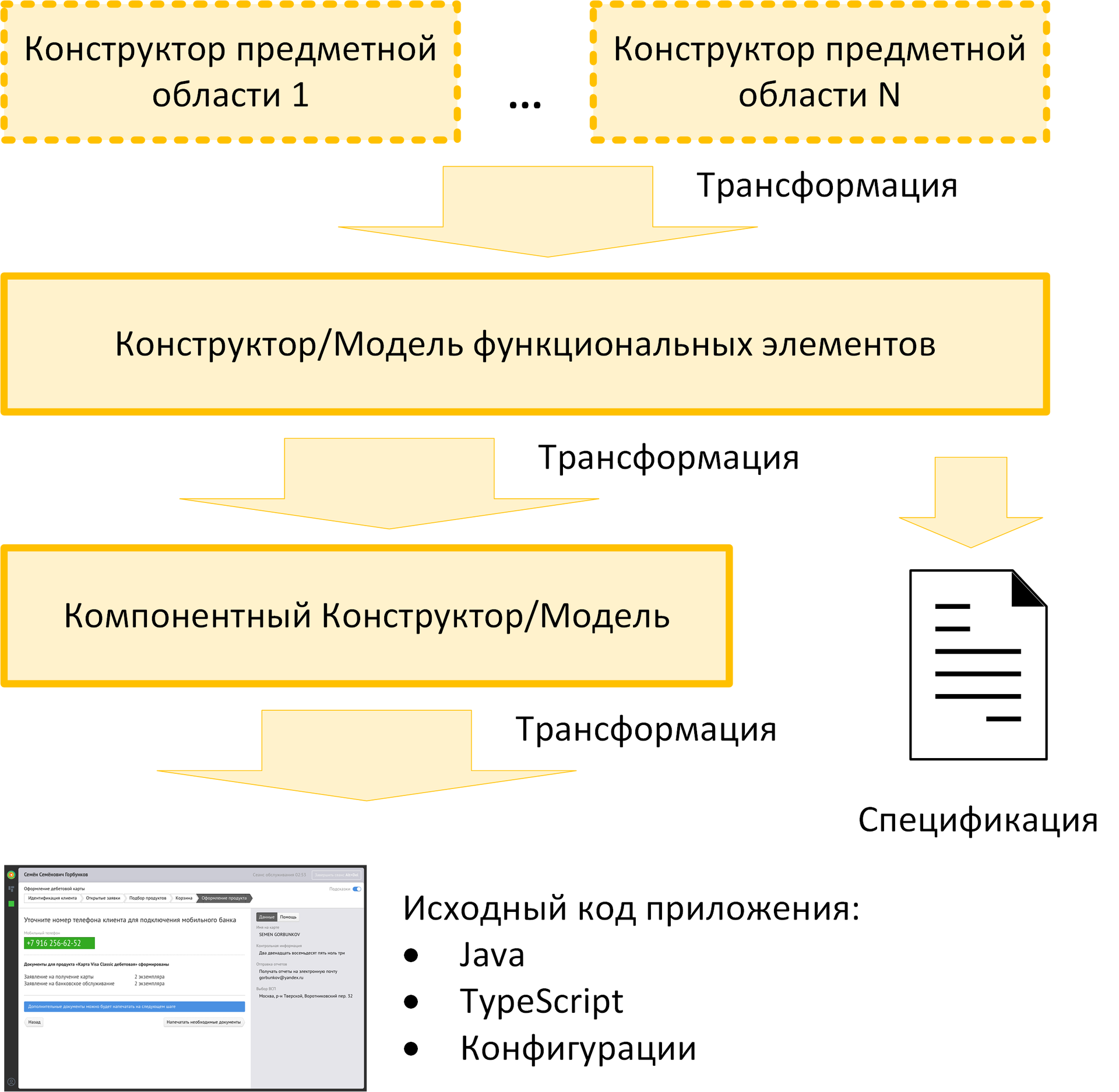
一般的なターゲット生成モデルを次の図に示します。 これまでにない最初のレベルは、ドメイン設計者のレベルです。 ドメインモデルのオブジェクトは、機能モデルのオブジェクトに変換されます。 たとえば、計画には、ステータスモデルを含む銀行商品のアプリケーションの設計者の実装が含まれます。 後者には独自のマジックボタンがあり、機能モデルのレベルでアプリケーションを操作するためのプロトタイププロセスを生成します。
一般的なコード生成モデル
2番目のレベルは、機能要素のモデルの実際のレベルです。 ITプロジェクトの最初の有用な成果物(機能要素の完全な仕様)を生成できます。
次世代の段階は、コンポーネントモデルの生成です。 最初のスクリーンショットでわかるように、モデルはかなり退屈に見えます。オレンジと白の正方形だけです。 これらは(次の用語ではアプリケーションモジュール)コンポーネントであり、次の段階で最終的なコードに変換されます。 各モジュール内で、主要なクラスは対応するロールで識別されます-典型的な相互作用パターン。 これらすべてが、最終的に実行可能なコードに変わります。
当然、ユニコーンで魔法のボタンを押すと、機能モデルのレベルで、変換のコンベヤー全体が一度に通過します。 しかし、このような段階的な生成の存在により、次のことが可能になります。
- 最後に、機能層とコンポーネントアーキテクチャの組織に関係なく、ビジネスデザイナーの層を追加します。
- 機能要素の構成を拡張し、チャネル固有の機能要素を追加するには
- 機能に関係なくコンポーネントアーキテクチャを管理する
- あるレベルの関連する構成アイテムのグループを、1K〜2K行のコードで別のアイテムの別のグループに変換するコードの複雑さを制限します。
- 問題を詳細に解決しますが、グローバルには解決しません。 たとえば、変換タスクVO-> DTO-> VOには、「大丈夫、今週末は間違いなく飲む」という特定のソリューションがあります。
- 構成の特殊なケースの生成を自動化し、「自動化自動化」を行うために、各レイヤーにわずかに冗長な構成を用意します。 たとえば、チャネルフロントエンドシナリオの場合、A / Bテスト用のバリエーションセットの生成は自動的に実行できます。 さて、マッピング、マッピング、マッピング。
前の2つのセクションで述べたように、最後のポイントは特に重要です。 A / Bテストの自動化やスクリプトを新しいチャンネルに出力するタスクのために、10 4個の視覚的なフォームを10 5個に変えることができます。 同時に、人件費は2倍増加しません。
機能モデルの重要な要素は、膨大な数の検証です。 プロの開発者ではないユーザーにとって、コードがコンパイルされない、またはNPEがポップアップする理由は謎です。 同様の理由で、システムは、フロントエンドスクリプトの機能的なステップバイステップのデバッグプロセスのようなソリューションの標準を追加しました。
最終的なコードは、手動で修正および終了できる必要があります。 この種の修正、特に質問が機能/統合テスト中に小さな機能を追加したりバグを修正したりする必要がある場合、多くの場合、他の参加者に合格します-それらは仕様に反映されません。
構成の完全性を確保するために、リバースエンジニアリング(リバースエンジニアリング)を自動化する機能を開発しました。 別のアプリケーションモジュール(最初のスクリーンショットのオレンジ色のボックス)に対応する選択された機能ブロックのJavaモデルを構築し、コンポーネントモデルにあるものと比較してコードパターンを認識しようとします。 これまでのところ、この魔法は、適用されたエンティティ、パブリックAPI、および主要なシステムオブジェクトに対してほぼ成功しています。
今のところすべてです。 また、機器の内部機構、要件、アーキテクチャをより詳細に理解するために、次の記事では、ITの電気技師とアーキテクトの共通点について説明します。