
こんにちは 私の名前はマルコで、Badooのシステムプログラマーです。 特定のことがどのように機能するかを完全に理解したいので、Linuxの共有ライブラリの微妙さも例外ではありません。 私はあなたにそのような分析の翻訳を提示します。 良い読書をしてください。
共有ライブラリをプロセスのアドレス空間にロードする際の共有ライブラリの特別な処理の必要性についてはすでに説明しました。 つまり、リンカが共有ライブラリを作成するとき、メモリ内のどこにロードされるかを事前に知りません。 このため、ライブラリ内のデータとコードへのリンクには問題があります。リンクを作成して、ライブラリのロード後に適切な場所を指すようにする方法は不明です。
LinuxおよびELFでは、この問題を解決する2つの主な方法があります。
- ロード時の再配置(ロード時の再配置)。
- アドレスに依存しないコード(位置に依存しないコード(PIC))。
ロード中に再配置を検討しました。 次に、2番目のアプローチ-PICを検討します。
最初はx86とx64(x86-64とも呼ばれる)の両方について話す予定でしたが、記事はどんどん成長し続け、より実用的にする必要があると判断しました。 したがって、この記事ではx86についてのみ説明し、x64については別のもので説明します(はるかに短いことを願っています)。 古いx86アーキテクチャを採用しました。x64とは異なり、PICを使用せずに設計されており、PICの実装はもう少し複雑です。
起動時の再配置の問題
前の記事で見たように、ブート時の再配置は非常に簡単で簡単な方法です。 そしてそれは動作します。 ただし、現時点ではPICの方がはるかに人気があり、共有ライブラリを作成する方法として推奨されています。 なぜですか?
再配置にはいくつかの問題があります。時間がかかり、テキストセクション(マシンコードを含む)がプロセス間の分離に適していません。
最初にパフォーマンスの問題について話しましょう。 ライブラリが再配置を必要とするシンボルに関する情報にリンクされている場合、再配置自体はロードに時間がかかります。 ローダーはソースコード全体を実行する必要がないため、この時間を長くすべきではないと考えるかもしれません。これらのシンボルをただ通過するだけです。 しかし、複雑なプログラムがいくつかの大きなライブラリをロードすると、オーバーヘッドが非常に急速に蓄積します。その結果、プログラムの起動時にかなりの遅延が生じます。
さて、テキストセクションを共有できないという問題についてのいくつかの言葉。 彼女はもう少し深刻です。 共有ライブラリが存在する主なタスクの1つは、メモリを節約することです。 一部のライブラリは、複数のアプリケーションで同時に使用されます。 テキストセクション(マシンコードが配置されている場所)を一度だけメモリにロード(およびmmapを使用して他のプロセスに追加)できる場合、かなり大量のRAMを保存できます。 ただし、再配置を使用する場合、これは不可能です。特定のプロセスの正しいポインターに置き換えるには、ブート時にテキストセクションを変更する必要があるためです。 ライブラリを使用するプロセスごとに、このライブラリの完全なコピーをメモリに保持する必要があることがわかります[1] 。 分離は発生しません。
さらに、テキストセクションを書き込み権限で保持する(およびローダーがリンクを修正できるように書き込み権限を使用する必要があります)ことは、セキュリティの観点からは悪いことです。 この場合、エクスプロイトを作成するのははるかに簡単です。
後で見るように、PICはこれらの問題をほぼ完全に解決します。
はじめに
PICの背後にある考え方は非常に単純です-グローバルオブジェクトおよび関数へのすべての参照のコードに中間層を追加します。 リンクおよびロードプロセスのアーティファクトをインテリジェントに使用する場合、テキストセクションを配置先のアドレスから実際に独立させることができます。 mmapを使用してセグメントをプロセスのアドレス空間内のさまざまなアドレスにマッピングできます。その中の1ビットを変更する必要はありません。 次のいくつかのセクションでは、これを実現する方法を示します。
主なアイデア番号1。 テキストセクションとデータセクション間のオフセット
PICが基にしている重要なアイデアの1つは、テキストセクションとデータセクション間のオフセットです。そのサイズは、リンク時にリンカーに認識されます。 リンカが複数のオブジェクトファイルを結合すると、それらのセクションが一緒に収集されます(たとえば、すべてのテキストセクションが1つの大きなテキストセクションに結合されます)。 したがって、リンカはセクションのサイズとそれらの相対位置の両方を知っています。
たとえば、テキストセクションの直後にデータセクションが続く場合があり、この場合、テキストセクションからデータセクションの先頭までの任意の命令からのオフセットは、テキストセクションのサイズからテキストセクションの先頭からこの命令までのオフセットを引いたものに等しくなります。 そして、これらの寸法と変位はすべてリンカに認識されています。
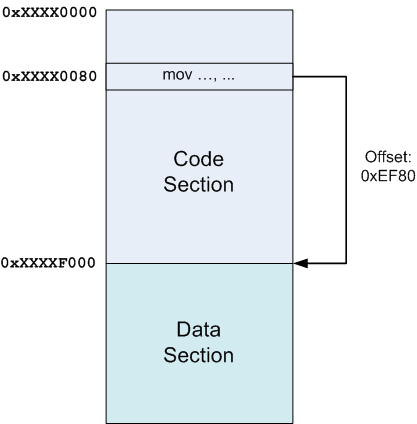
上記の図では、コードセクションはあるアドレス(リンクの時点では不明)0xXXXX0000(Xは文字通り「とにかく」を意味します)にロードされ、データセクションはその直後に0xXXXXF000にロードされました。 この場合、コードセクションのオフセット0x80の命令がデータセクションの何かをポイントする場合、リンカーは相対オフセット(この場合は0xEF80)を認識し、それを命令に追加できます。
他のセクションがコードセクションとデータセクションの間にマッピングされている場合、またはデータセクションがコードセクションの前にある場合、何も変更されないことに注意してください。 リンカはすべてのセクションのサイズを認識し、それらを配置する場所を決定するため、アイデアは変わりません。
主要なアイデア番号2。 x86でIPオフセットを機能させる
相対変位を使用できる場合は、上記のすべてが機能します。 結局のところ、x86上のデータへの参照(たとえば、MOV命令など)には絶対アドレスが必要です。 それで、私たちは何をしますか?
相対アドレスはあるが、絶対アドレスが必要な場合、命令ポインターまたは命令カウンター(IP)の値が欠落しています。 実際、定義上、相対アドレスはIPに対して相対的です。 x86では、IPを取得するための指示はありませんが、簡単なトリックを使用できます。 以下に、それを示す小さなアセンブラーの擬似コードを示します。
call TMPLABEL TMPLABEL: pop ebx
ここで何が起こっていますか:
- プロセッサは呼び出し命令TMPLABELを実行します。これはスタック上の次の命令のアドレス(pop ebx)を格納し、ラベルにジャンプします。
- ラベルの命令はpop ebxであるため、次のように実行されます。 この命令は、ebxのスタックから値を取得します。 しかし、これは命令自体のアドレスです。 そのため、実際、ebxにはIP値が含まれています。
グローバルオフセットテーブル(GOT)
これで、x86アドレスに依存しないアドレス指定がどのように実装されるかについて最終的に説明するすべてができました。 また、グローバルオフセットテーブル(グローバルオフセットテーブルまたはGOT)を使用して実装されます。
GOTは、アドレスがデータセクションにある単なるテーブルです。 コードセクションの一部の命令が変数にアクセスしたいとします。 絶対アドレス(再配置が必要)を介してアクセスする代わりに、GOTのエントリを参照します。 GOTのデータセクションには厳密に定義された場所があり、リンカーはそれを認識しているため、この呼び出しも相対的です。 そして、GOTのエントリには既に変数の絶対アドレスが含まれています。
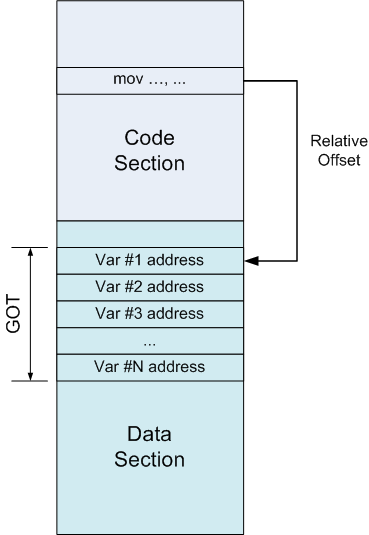
疑似アセンブラーでは、これは絶対アドレス指定の置き換えのように見えます。
// edx mov edx, [ADDR_OF_VAR]
レジスタと小さなパッドを介してアドレス指定する場合:
どういうわけかGOTアドレスを見つけてebxに入れます:
lea ebx、ADDR_OF_GOT
変数アドレス(ADDR_OF_VAR)がGOTのオフセット0x10にあるとします。 この場合、次のステートメントはADDR_OF_VARをedxに入れます。
mov edx、DWORD PTR [ebx + 0x10]
最後に、変数に戻り、その値をedxに入れます。
mov edx、DWORD PTR [edx]
したがって、GOTを介して呼び出しをリダイレクトすることにより、コードセクションの再配置を取り除きました。 ただし、データセクションに再配置も作成しました。 なんで? GOTには、上記のスキームが機能するための変数の絶対アドレスが含まれている必要があるためです。 それで、利益はどこにありますか?
たくさんの利益があります。 データセクションでの再配置は、コードセクションでの再配置よりもはるかに少ない数の問題に関連しています。 これには、ブート時の再配置中に発生する2つの問題に対応する2つの理由があります。
- コードセクションの再配置は変数の呼び出しごとに必要ですが、GOTの再配置はすべての変数にのみ必要です。 通常、変数へのアクセスは変数よりも顕著に多いため、より効率的です。
- データセクションはすでに書き込み可能であり、プロセス間で共有されていないため、その中の再配置は問題ありません。 しかし、コードセクションに再配置がなくなるという事実により、このセクションを読み取り専用にし、プロセス間で共有することができます。
GOTを介した呼び出しのあるPIC(例)
次に、PICの仕組みを示す本格的な例を示します。
int myglob = 42; int ml_func(int a, int b) { return myglob + a + b; }
このコードブロックは、(-fpicおよび-sharedフラグを使用して)共有ライブラリにコンパイルされますlibmlpic_dataonly.so。
ml_func関数に注目して、コンパイラーが生成したものを見てみましょう。
0000043c <ml_func>: 43c: 55 push ebp 43d: 89 e5 mov ebp,esp 43f: e8 16 00 00 00 call 45a <__i686.get_pc_thunk.cx> 444: 81 c1 b0 1b 00 00 add ecx,0x1bb0 44a: 8b 81 f0 ff ff ff mov eax,DWORD PTR [ecx-0x10] 450: 8b 00 mov eax,DWORD PTR [eax] 452: 03 45 08 add eax,DWORD PTR [ebp+0x8] 455: 03 45 0c add eax,DWORD PTR [ebp+0xc] 458: 5d pop ebp 459: c3 ret 0000045a <__i686.get_pc_thunk.cx>: 45a: 8b 0c 24 mov ecx,DWORD PTR [esp] 45d: c3 ret
命令のアドレス(出力の左端の番号)をポイントします。 このアドレスは、ライブラリがマップされたアドレスからのオフセットです。
- 43fで、次の命令のアドレスが「キーアイデアNo. 2」のセクションで前述したのと同じ方法でecxに配置されます。
- 444では、命令からGOTへの既知のオフセットがecxに配置されます。 したがって、ecxはGOTへのポインタとして機能するようになりました。
- 44aで、GOTからのレコードである[ecx-0x10]の値が取得され、eaxに入れられます。 これは、myglob変数のアドレスです。
- 450では、すでにmyglobを取得してeaxに入れています。
- 次に、パラメーターaとbがmyglobに追加され、値が返されます(したがって、eaxに残します)。
readelf -Sを使用して、リンカがGOTを配置した場所を見つけることもできます。
Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al <snip> [19] .got PROGBITS 00001fe4 000fe4 000010 04 WA 0 0 4 [20] .got.plt PROGBITS 00001ff4 000ff4 000014 04 WA 0 0 4 <snip>
計算機を入手して、コンパイラを確認しましょう。 myglobを探しています。 前述したように、__ i686.get_pc_thunk.cxを呼び出すと、ecxに次の命令のアドレスが設定されます。 これは0x444 [2]です。 次の命令は、それに0x1bb0を追加します-その結果、ecxで0x1ff4を取得します。 最後に、myglobアドレスを含むGOT要素を取得するには、[ecx-0x10]を実行します。 したがって、この要素はアドレス0x1fe4を持ち、これはセクションヘッダーによるとGOTの最初の要素です。
名前が.gotで始まる別のセクションがある理由は、後で説明します[3] 。 コンパイラーは、GOTの後にecxアドレスを配置し、負のオフセットを使用することにしたことに注意してください。 最終的にすべてが収束しても大丈夫です。 そしてこれまでのところ、すべてが収束しています。
しかし、まだ不足していることが1つあります。 myglobアドレスは、0x1fe4のGOT要素にどのくらい正確に表示されますか? 私が再配置に言及したことを思い出してください、それでそれを見つけましょう:
> readelf -r libmlpic_dataonly.so Relocation section '.rel.dyn' at offset 0x2dc contains 5 entries: Offset Info Type Sym.Value Sym. Name 00002008 00000008 R_386_RELATIVE 00001fe4 00000406 R_386_GLOB_DAT 0000200c myglob <snip>
ここでは、予想どおり、アドレス0x1fe4を指すmyglobの再配置です。 再配置のタイプはR_386_GLOB_DATであり、単にローダーに「このオフセットでsimpolの実際の値(つまり、そのアドレス)を入力する」ことを伝えます。 これですべてが明確になりました。 ライブラリをロードするときに、すべてがどのように見えるかを確認するためだけに残ります。 これを行うには、libmlpic_dataonly.soにリンクしてml_funcを呼び出し、gdbで実行する単純なドライバー(バイナリ)を作成します。
> gdb driver [...] skipping output (gdb) set environment LD_LIBRARY_PATH=. (gdb) break ml_func [...] (gdb) run Starting program: [...]pic_tests/driver Breakpoint 1, ml_func (a=1, b=1) at ml_reloc_dataonly.c:5 5 return myglob + a + b; (gdb) set disassembly-flavor intel (gdb) disas ml_func Dump of assembler code for function ml_func: 0x0013143c <+0>: push ebp 0x0013143d <+1>: mov ebp,esp 0x0013143f <+3>: call 0x13145a <__i686.get_pc_thunk.cx> 0x00131444 <+8>: add ecx,0x1bb0 => 0x0013144a <+14>: mov eax,DWORD PTR [ecx-0x10] 0x00131450 <+20>: mov eax,DWORD PTR [eax] 0x00131452 <+22>: add eax,DWORD PTR [ebp+0x8] 0x00131455 <+25>: add eax,DWORD PTR [ebp+0xc] 0x00131458 <+28>: pop ebp 0x00131459 <+29>: ret End of assembler dump. (gdb) i registers eax 0x1 1 ecx 0x132ff4 1257460 [...] skipping output
デバッガーはml_funcに入り、IP 0x0013144a [4]で停止しました。 ecxの値は0x132ff4(命令アドレスと0x1bb0)であることがわかります。 現時点では、操作中、これらはすべて絶対アドレスであることに注意してください-ライブラリはすでにプロセスのアドレス空間にロードされています。
そのため、myglobを含むGOT要素は[ecx-0x10]にあるはずです。 確認しましょう:
(gdb) x 0x132fe4 0x132fe4: 0x0013300c
つまり、0x0013300cがmyglobのアドレスであると予想されます。 私たちはチェックします:
(gdb) p &myglob $1 = (int *) 0x13300c
そうです!
PICで関数を呼び出す
それで、PICがデータアドレスに対してどのように機能するかを見ました。 しかし、関数はどうですか? 理論的には、同じ方法で関数が機能します。 関数のアドレスを含む呼び出しの代わりに、GOTからの要素のアドレスを含むようにします。そうすると、要素はブート時にすでに入力されています。
しかし、PICで関数を呼び出してもそのようには動作しません。実際には、すべてが多少複雑です。 方法を正確に説明する前に、このようなメカニズムを選択する動機について簡単に説明します。
最適化:遅延バインディング
共有ライブラリが関数を使用する場合、この関数の実際のアドレスはまだ不明です。 実際のアドレスの定義はバインディングと呼ばれます。これは、ローダーが共有ライブラリをプロセスのアドレス空間にロードするときに行うことです。 ローダーは特別なテーブル[5]で関数シンボルを探す必要があるため、バインディングは簡単ではありません。
したがって、各関数の実際のアドレスの決定には時間がかかります(それほど時間はかかりませんが、データよりも関数の呼び出しがはるかに多いため、このプロセスの期間は長くなります)。 さらに、ほとんどの場合、これは無駄に行われます。これは、通常のプログラムの起動中に、関数のごく一部しか呼び出されないためです(エラーまたは特別な条件が発生した場合にのみ必要な呼び出しの数を考えてください)。
このプロセスを高速化するために、「遅延」バインディングのbindingなスキームが考案されました。 「遅延」は、ITの最適化の一般的な用語であり、作業が最後の最後まで延期される場合です。 この最適化のポイントは、不必要な作業を行うことではありません。 そのような遅延最適化の例は、コピーオンライトメカニズムと遅延計算です。
「遅延」スキームは、別のレベルのアドレス指定-PLTを追加することで実装されます。
プロシージャリンケージテーブル(PLT)
PLTは、一連の要素(ライブラリが呼び出す外部関数ごとに1つの要素)で構成されるバイナリのテキストセクションの一部です。 PLTの各要素は、実行可能なマシンコードの小さな断片です。 関数を呼び出す代わりに、PLTからコードの一部が直接呼び出されます。このコードは既に関数自体を呼び出しています。 このアプローチは、しばしば「スプリングボード」と呼ばれます。 PLTの各要素には、GOTに独自の要素があり、関数の実際のオフセットが含まれています。 もちろん、ローダーがそれを検出した後。
一見、すべてがややこしいですが、すぐにすべてがより明確になることを願っています。次のセクションでは、詳細を図で説明します。
すでに述べたように、PLTを使用すると、関数アドレスの「遅延」定義を作成できます。 共有ライブラリが最初にロードされた時点では、関数の実際のアドレスはまだ定義されていません。
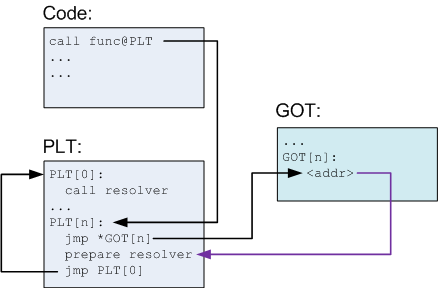
解説
- func関数はコード内で呼び出されます。 コンパイラは、この呼び出しをfunc @ plt呼び出しに変換します。これはPLTの要素の1つです。
- PLTは特別な最初の要素で構成され、その後に機能ごとに1つの構造化されたいくつかの要素が続きます。
- 最初の要素を除くすべてのPLT要素には、次の部分が含まれます。
•GOTから対応する要素に示されているアドレスにジャンプします。
•「決定」の方法に関する議論の準備。
•最初のPLT要素にある「定義」メソッドの呼び出し。 - PLTの最初の要素は、ローダー自体のコードにある「定義」メソッドの呼び出しです[6] 。 このメソッドは関数の実際のアドレスを決定します(これについては以下で詳しく説明します)。
- 関数の実際のアドレスが決定される前に、N番目のGOT要素は単にジャンプ後のアドレスを指します。 それが、ダイアグラム上の矢印が異なる色で強調表示されている理由です-これは実際のジャンプではなく、単なるポインタです。
funcが初めて呼び出された後に何が起こるか:
- PLT [n]が呼び出され、GOT [n]からアドレスへのジャンプが発生します。
- このアドレスは、「定義」メソッドの引数の準備が行われる場所であるPLT [n]を指しています。
- メソッドが呼び出されます。
- メソッドはfunc関数の実際のアドレスを決定し、それをGOT [n]に入れてfuncを呼び出します。
初回以降、チャートは少し異なります。

GOT [n]はPLTを指すのではなく、実際のfunc [7]を指すようになりました。 そのため、関数が再び呼び出されると、次のことが起こります。
- PLT [n]が呼び出され、GOT [n]からアドレスへのジャンプが発生します。
- GOT [n]はfuncを指しているため、funcは単に呼び出されます。
言い換えると、「定義」メソッドを使用せずに、余分なジャンプをせずにfuncを呼び出すだけです。 このメカニズムにより、関数アドレスの「遅延」定義を作成でき、呼び出されない関数の定義は作成できません。
ライブラリは絶対アドレスが使用される唯一の場所はGOTであり、データセクションにあり、ローダーによるロード中に再配置されるため、ライブラリはダウンロード先のアドレスから完全に独立していることに注意してください。 PLTでもロードアドレスに依存しないため、読み取り専用のテキストセクションに含めることができます。
「決定」の方法の詳細には触れませんが、これはそれほど重要ではありません。 メソッドは、ブートローダー内の低レベルのコードの一部であり、その役割を果たします。 メソッドが呼び出される前に準備される引数は、関数のアドレスを決定する必要があり、結果を配置する場所を知らせます。
PLTおよびGOTを介した関数呼び出しを使用したPIC(例)
さて、実践で理論を強化するために、上記の方法を使用して関数呼び出しを示す例を考えてみましょう。
共有ライブラリのコードは次のとおりです。
int myglob = 42; int ml_util_func(int a) { return a + 1; } int ml_func(int a, int b) { int c = b + ml_util_func(a); myglob += c; return b + myglob; }
このコードはlibmlpic.soにコンパイルされ、ml_funcからml_util_funcを呼び出すことに焦点を合わせます。 ml_funcを逆アセンブルします。
00000477 <ml_func>: 477: 55 push ebp 478: 89 e5 mov ebp,esp 47a: 53 push ebx 47b: 83 ec 24 sub esp,0x24 47e: e8 e4 ff ff ff call 467 <__i686.get_pc_thunk.bx> 483: 81 c3 71 1b 00 00 add ebx,0x1b71 489: 8b 45 08 mov eax,DWORD PTR [ebp+0x8] 48c: 89 04 24 mov DWORD PTR [esp],eax 48f: e8 0c ff ff ff call 3a0 <ml_util_func@plt> <... snip more code>
興味深いのは、ml_util_func @ pltを呼び出すことです。 また、GOTアドレスがebxにあることに注意してください。 ml_util_func @ pltは次のようになります(実行権限のある.pltセクションにあります)。
000003a0 <ml_util_func@plt>: 3a0: ff a3 14 00 00 00 jmp DWORD PTR [ebx+0x14] 3a6: 68 10 00 00 00 push 0x10 3ab: e9 c0 ff ff ff jmp 370 <_init+0x30>
各PLT要素は3つの部分で構成されていることを思い出してください。
- GOTからアドレスにジャンプします(これは[ebx + 0x14]へのジャンプです)。
- 「定義」メソッドの引数の準備。
- 「定義」メソッドの呼び出し。
「定義」メソッド(PLTの要素0)は0x370にありますが、今は興味がありません。 GOTに何が含まれているかを見るのは非常に興味深いです。 これを行うには、再び電卓が必要です。
ml_funcで現在のIPを取得するトリックは0x483で行われ、0x1b71を追加しました。 したがって、GOTは0x1ff4にあります。 readelf [8]を使用すると、何があるかわかります。
> readelf -x .got.plt libmlpic.so Hex dump of section '.got.plt': 0x00001ff4 241f0000 00000000 00000000 86030000 $............... 0x00002004 96030000 a6030000 ........
ml_util_func @ pltのGOTエントリは、オフセット+ 0x14または0x2008にあるようです。 上記の結論から判断すると、このアドレスのワードの値は0x3a6であり、これはml_util_func @ pltのプッシュ命令のアドレスです。
ブートローダーの仕事を支援するために、アドレスml_util_funcが書き込まれるGOTの場所のアドレスを含むエントリがGOTに追加されました。
> readelf -r libmlpic.so [...] snip output Relocation section '.rel.plt' at offset 0x328 contains 3 entries: Offset Info Type Sym.Value Sym. Name 00002000 00000107 R_386_JUMP_SLOT 00000000 __cxa_finalize 00002004 00000207 R_386_JUMP_SLOT 00000000 __gmon_start__ 00002008 00000707 R_386_JUMP_SLOT 0000046c ml_util_func
最後の行は、ローダーがml_util_funcシンボルのアドレスを0x2008に配置する必要があることを意味しています(これがこの関数のGOT要素です)。
この変更がGOTでどのように行われるかを確認できたらうれしいです。 これを行うには、GDBを再度使用します。
> gdb driver [...] skipping output (gdb) set environment LD_LIBRARY_PATH=. (gdb) break ml_func Breakpoint 1 at 0x80483c0 (gdb) run Starting program: /pic_tests/driver Breakpoint 1, ml_func (a=1, b=1) at ml_main.c:10 10 int c = b + ml_util_func(a); (gdb)
これで、ml_util_funcの最初の呼び出しの前にいます。 GOTアドレスはebxにあることを思い出してください。 何があるか見てみましょう:
(gdb) i registers ebx ebx 0x132ff4
必要な要素のオフセットは[ebx + 0x14]にあります。
(gdb) x/w 0x133008 0x133008: 0x001313a6
はい、0x3a6で終了します。 それは正しく見えます。 それでは、ml_util_funcを呼び出してもう一度見てみましょう。
(gdb) step ml_util_func (a=1) at ml_main.c:5 5 return a + 1; (gdb) x/w 0x133008 0x133008: 0x0013146c
0x133008の値が変更されました。 0x0013146cがml_util_funcの実際のアドレスであり、ブートローダーによってそこに配置されていることがわかります。
(gdb) p &ml_util_func $1 = (int (*)(int)) 0x13146c <ml_util_func>
予想通り。
ブートローダーによるアドレス決定を制御します
ここで、ローダーによって実行される「遅延」アドレス決定のプロセスは、いくつかの環境変数(およびldリンカーの対応する引数)によって構成できることに言及するときです。 これらの設定は、デバッグや特別なパフォーマンス要件に役立つ場合があります。
LD_BIND_NOW変数は、定義されている場合、レイジーではなく、起動時にすべてのアドレスを決定するようブートローダーに指示します。 その動作は、指定されている場合の上記の例のgdb出力を調べることで確認できます。 ml_util_funcのGOTからの要素には、最初の関数呼び出しの前でも関数の実際のアドレスが含まれていることがわかります。
対照的に、LD_BIND_NOTは、GOTを更新しないようにブートローダーに指示します。 つまり、この場合の各関数呼び出しは「定義」メソッドを通過します。
ブートローダーは、他のいくつかのフラグで構成されます。 man ld.soを探索することをお勧めします。 興味深い情報がたくさんあります。
PICコスト
このPICの問題に取り組み、解決しながら、移転問題との会話を始めました。 しかし、残念ながらPIC自体にも問題がないわけではありません。 それらの1つは、追加の間接アドレス指定のコストです。 これは、グローバル変数または関数にアクセスするたびに追加のメモリアクセスです。 災害の規模は、コンパイラ、プロセッサアーキテクチャ、およびアプリケーション自体によって異なります。
別の、それほど明白ではない問題は、PICを実装するために追加のレジスタを使用することです。 GOTアドレスを頻繁に決定しないために、コンパイラがアドレスをレジスタ(たとえば、ebx)に格納するコードを生成することは理にかなっています。 しかし、これはレジスター全体がGOTにのみ行くことを意味します。 通常、多くのパブリックレジスタを持つRISCアーキテクチャの場合、これはそれほど大きな問題ではなく、利用可能なレジスタがほとんどないx86などのアーキテクチャについては言えません。 PICを使用すると、レジスタが1つ少なくなります。つまり、より多くのメモリアクセスが必要になります。
おわりに
これで、アドレスに依存しないコードとは何か、そして読み取り専用の共有テキストセクションで共有ライブラリを作成するのにどのように役立つかがわかりました。
PICは、操作中の再配置と比較して長所と短所があり、結果は多くの要因(特に、プログラムが実行されるプロセッサのアーキテクチャ)に依存します。
ただし、欠陥にもかかわらず、PICはますます一般的なアプローチになりつつあります。 SPARC64などの一部のIntel以外のアーキテクチャでは、共有ライブラリにPICの使用が必須ですが、他の多く(ARMなど)では、PICをより効率的にするためにIP依存のアドレス指定が必要です。 それと、後継のx86-x64の両方に当てはまります。
パフォーマンスの問題とプロセッサアーキテクチャに焦点を合わせませんでした。 私の仕事は、PICがどのように機能するかを伝えることでした。 説明が十分に「透明」ではなかった場合は、コメントでお知らせください。詳細をお伝えします。