仕事の目的
- プロキシサーバーを使用してサイトを解析します。
- データをCSV形式で保存します。
- 見つかったデータの検索エンジンを作成しています。
- インターフェイスを構築します。
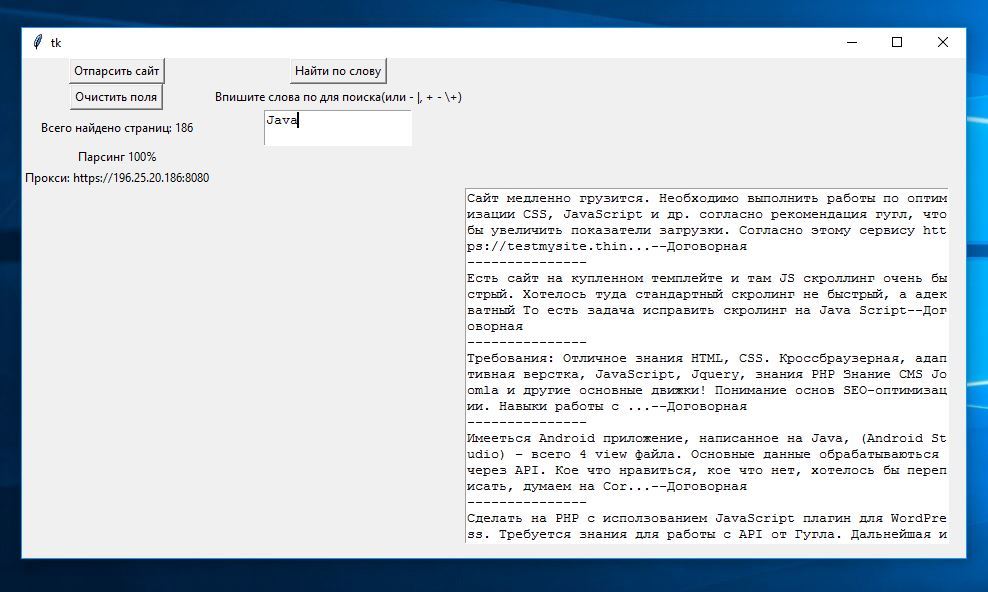
Pythonプログラミング言語を使用します。 データをダウンロードするサイトはwww.weblancer.net (このサイトの古いバージョンの解析はここに投稿されました )で、 www.weblancer.net / jobsで求人があります。 それからデータを受け取ります-これは、名前、価格、アプリケーションの数、カテゴリ、提案された仕事の簡単な説明です。
プロキシを使用してログインするとは、偽のアドレスでサイトにログインすることを意味します。 IPアドレスによる禁止保護のあるサイトの解析に役立ちます(つまり、頻繁に短期間にサイトにアクセスする場合)。
モジュールのインポート
直接解析のためのモジュール:リクエストとBeautifulSoup、それらは十分にあります。 データをcsv形式で保存するには、同じ名前のモジュールcsvが役立ちます。 tkinterモジュール(より良いインターフェイスを取得したいので、 pyQt5モジュールを使用することをお勧めします)は、インターフェイスの操作に役立ちます。 データの取得および置換作業は、reモジュールによって実行されます。
import requests # HTTP- import urllib.request # HTTP from lxml import html # xml html, html import re # from bs4 import BeautifulSoup # HTML import csv # CSV import tkinter # from tkinter.filedialog import * #
変数
以前に使用したプロキシと2つのテキスト変数を格納する配列を作成し、サイトアドレスを最初のものと同等にし、2番目のものをグローバルとして宣言します(グローバル変数を使用するとプログラムのパフォーマンスに悪影響を与える可能性がある、 ここでの使用について詳しく説明します )関数でデータを受け取ります。
global proxy1 # proxy1 = '' # BASE_URL = 'https://www.weblancer.net/jobs/' # massiv = [] #
tkinterの変数:
root = Tk() # root.geometry('850x500') # txt1 = Text(root, width = 18, heigh = 2) # txt2 = Text(root, width = 60, heigh = 22) # lbl4 = Label(root, text = '') # btn1 = Button(root, text = ' ') # btn2 = Button(root, text = ' ') # btn3 = Button(root, text = ' ') # lbl1 = Label(root, text = ' ') # lbl2 = Label(root, text = '') # lbl3 = Label(root, text = '') #
Variable.grid(行、列)-表示ウィンドウ内の要素の位置を決定します。 バインド-キーストローク。 次のコードは、プログラムの最後に配置されます。
btn1.bind('<Button-1>', main) # btn2.bind('<Button-1>', poisk) # btn3.bind('<Button-1>', delete) # lbl2.grid(row = 4, column = 1) lbl4.grid(row = 5, column = 1) lbl3.grid(row = 3, column = 1) btn1.grid(row = 1, column = 1) btn3.grid(row = 2, column = 1) btn2.grid(row = 1, column = 2) lbl1.grid(row = 2, column = 2) txt1.grid(row = 3, column = 2) txt2.grid(row = 6, column = 3) root.mainloop() #
主な機能
まず、メイン関数を作成します(プロシージャではなく関数なのはなぜですか?将来、バインド(キーストローク)で実行する必要があります。これは関数を使用する方が簡単です)。後で他の関数を追加します。 私たちに役立つ手順:
- config-ウィジェット要素に変更を加えます。 たとえば、ラベルウィジェットのテキストを置き換えます。
- update-ウィジェットの更新に使用されます。 問題が発生します-ウィジェットはループが完了した後にのみ変更されます。更新により、サイクルパスごとにウィジェットのコンテンツを更新できます。
- re.sub(パターン、可変文字列、文字列)-文字列内のパターンを検索し、指定された部分文字列で置き換えます。 パターンが見つからない場合、文字列は変更されません。
- get-http-requestを作成します(「200」の場合)-サイトへの入り口は成功しました。
- content-HTMLコードを取得できます。
- L.extend(K)-リストLを拡張し、リストKのすべての要素を最後に追加します
def main(event): # event ( ) page_count = get_page_count(get_html(BASE_URL)) # , , http- BASE_URL lbl3.config(text=' : '+str(page_count)) # lbl3 page = 1 # projects = [] # while page_count != page: # , page proxy = Proxy() # , proxy = proxy.get_proxy() # proxy- lbl4.update() # lbl4.config(text=': '+proxy) # global proxy1 # proxy1 = proxy # try: # for i in range(1,10): # (range - , ). , page += 1 # lbl2.update() # lbl2.config(text=' %d%%'%(page / page_count * 100)) # 100% r = requests.get(BASE_URL + '?page=%d' % page, proxies={'https': proxy}) # parsing = BeautifulSoup(r.content, "lxml") # html- BeautifulSoup ( ) projects.extend(parse(BASE_URL + '?page=%d' % page, parsing)) # parse ( html-) save(projects, 'proj.csv') # csv, projects except requests.exceptions.ProxyError: # continue # while except requests.exceptions.ConnectionError: # continue # while except requests.exceptions.ChunkedEncodingError: # , continue # while
サイトページのカウント
URLを取得する関数を作成します。
def get_html(url): # url, page_count[count] response = urllib.request.urlopen(url) # «» httplib, , return response.read() # read
urlを使用して、すべてのページを探しています。
def get_page_count(html): # html soup = BeautifulSoup(html, 'html.parser') # html- url , paggination = soup('ul')[3:4] # , lis = [li for ul in paggination for li in ul.findAll('li')][-1] # lis, for link in lis.find_all('a'): # var1 = (link.get('href')) # var2 = var1[-3:] # , return int(var2) #
受信プロキシ
コードの一部はIgor Danilovから取られました。 __init __(self) -クラスのコンストラクターを使用します。ここで、selfは、作成時にオブジェクトが置き換えられる要素です。 重要! __init__両側に2つのアンダースコア。
class Proxy: # proxy_url = 'http://www.ip-adress.com/proxy_list/' # , - proxy_list = [] # def __init__(self): # self r = requests.get(self.proxy_url) #http- get, url str = html.fromstring(r.content) # lxml.html.HtmlElement result = str.xpath("//tr[@class='odd']/td[1]/text()") # for i in result: # if i in massiv: # yy = result.index(i) # result del result[yy] # result self.list = result # def get_proxy(self): # self for proxy in self.list: # if 'https://'+proxy == proxy1: #, , : global massiv #massiv massiv = massiv + [proxy] # url = 'https://'+proxy # return url #
ページの解析
これで、サイトの各ページに必要なデータが見つかりました。 新しい治療法:
- find_all-ページのhtmlコード内で、ブロック内のブロックと要素を検索します。
- テキスト-サイトに表示されるテキストのみをHTMLコードから受信します。
- L.append(K)-リストLの末尾にK要素を追加します。
def parse(html,parsing): # html parsing projects = [] # , table = parsing.find('div' , {'class' : 'container-fluid cols_table show_visited'}) # html-, , , , , for row in table.find_all('div' , {'class' : 'row'}): # cols = row.find_all('div') # price = row.find_all('div' , {'class' : 'col-sm-1 amount title'}) # cols1 = row.find_all('div' , {'class' : 'col-xs-12' , 'style' : 'margin-top: -10px; margin-bottom: -10px'}) # if cols1==[]: # , application_text = '' # else: # application_text = cols1[0].text # html- cols2 = [category.text for category in row.find_all('a' , {'class' : 'text-muted'})] # projects.append({'title': cols[0].a.text, 'category' : cols2[0], 'applications' : cols[2].text.strip(), 'price' : price[0].text.strip() , 'description' : application_text}) # projects return projects #
クリーニング機能
必要な削除手順は、指定された識別子またはタグでオブジェクトを削除することだけです。
def delete(event): # txt1.delete(1.0, END) # txt2.delete(1.0, END) #
データ検索
この関数は、必要な単語が記載されている説明の文を検索します。 このフィールドは、正規表現の知識を考慮して記述する必要があります(たとえば、python | Python、C \ + \ +)。
- csv.DictReader-コンストラクターは読み取り用のイテレーターオブジェクトを返します
ファイルからのデータ。 - split-セパレーターを使用して文字列をパーツに分割し、これらのパーツをリストで返します。
- join-リストを文字列に変換し、各要素を文字列として扱います。
- 挿入-インデックスによってリストにアイテムを追加します。
def poisk(event): # event file = open("proj.csv", "r") # , rdr = csv.DictReader(file, fieldnames = ['name', 'categori', 'zajavki', 'case', 'opisanie']) # poisk = txt1.get(1.0, END) # poisk = poisk[0:len(r)-1] # , ('\n') for rec in rdr: # , csv- data = rec['opisanie'].split(';') # data1 = rec['case'].split(';') # data = ('').join(data) # data1 = ('').join(data1) # w = re.findall(poisk, data) # if w != []: #, w , if data1 == '': # , , data1 = '' # txt2.insert(END, data+'--'+data1+'\n'+'---------------'+'\n') # , , , ,
データ保存
既に述べたように、データをcsv形式で保存します。 必要に応じて、関数を他の形式に書き換えることができます。
def save(projects, path): # path with open(path, 'w') as csvfile: # path w ( . . _, ) writer = csv.writer(csvfile) #writer - , csv - writer.writerow(('', '', '' , '' , '')) #writerow - for project in projects: # try: # writer.writerow((project['title'], project['category'], project['applications'], project['price'], project['description'])) # except UnicodeEncodeError: # description , writer.writerow((project['title'], project['category'], project['applications'], project['price'], '')) #
この情報があなたの仕事に役立つことを願っています。 がんばって。