パート2-DBSCAN
パート3-時系列クラスタリング
パート4-自己組織化マップ(SOM)
パート5-成長中の神経ガス(GNG)
初心者のデータアナリストに彼が知っている分類方法を尋ねると、統計、ツリー、SVM、ニューラルネットワークなど、かなりまともなリストが得られるでしょう。しかし、クラスタリング方法について質問すると、自信のある「k-means!」が得られるでしょう。すべての機械学習コースで考慮されるのは、この金色のハンマーです。 多くの場合、修正(k-中央値)や連結グラフメソッドさえも実現しません。
k-meansがそれほど悪いわけではありませんが、その結果はほとんど常に安価で怒っています。 より高度なクラスタリング方法がありますが、誰がどの方法をいつ使用するかを知っているわけではなく、その仕組みを理解している人はほとんどいません。 いくつかのアルゴリズムに対して秘密のベールを開きたいと思います。 アフィニティ伝播から始めましょう。
クラスタリング手法の分類に精通しており、すでにk-meansを使用しており、その長所と短所を知っていることを前提としています。 理論に深く入り込まないようにしようと思いますが、単純な言語でアルゴリズムのアイデアを伝えようとします。
アフィニティ伝播
アフィニティ伝播(AP、別名近接分布法)は、データセットの要素間の類似性の入力行列を受け取ります これらの要素に割り当てられたラベルのセットを返します。 苦労せずに、すぐにテーブルにアルゴリズムを配置します。

ハ、それは広まるものでしょう。 メインサイクルを考慮すると、3行のみです。 (4)-明示的なラベル付け規則。 しかし、それほど単純ではありません。 ほとんどのプログラマーは、これら3行がマトリックスで何をするのかまったく明確ではありません。 、 そして 。 公式に近い記事で説明されています そして -それぞれ「責任」と「可用性」のマトリックス。サイクルでは、潜在的なクラスターリーダーと他のポイントとの間に「メッセージング」があります。 正直なところ、これは非常に表面的な説明であり、これらのマトリックスの目的が何であるか、またはそれらの値がどのように、なぜ変化するかは明確ではありません。 それを理解しようとすると、おそらくここのどこかに導かれます。 これは良い記事ですが、準備ができていない人が数式で詰まったモニター画面全体に耐えることは困難です。
だから私はもう一方の端から始めます。
直感的な説明
ある空間、ある状態では、ドットが生きています。 ポイントには豊富な内部世界がありますが、いくつかのルールがあります 隣人がどれほど似ているかを伝えることができます。 さらに、彼らはすでにテーブルを持っています すべてが書かれている場所 彼女はほとんど変わらない。
世界で一人でいるのは退屈なので、ドットは趣味のグループに集まりたいと思っています。 リーダー(例)の周囲に円が形成され、パートナーシップのすべてのメンバーの利益を表します。 各ポイントは、できるだけ彼女に似ている誰かのリーダーを見たいと思っていますが、他の多くの人が彼らを好きなら、他の候補に我慢する準備ができています。 ポイントはかなり控えめであることを付け加えてください。誰もが他の誰かがリーダーになるべきだと考えています。 次のように、低い自尊心を再定式化できます。 各ポイントは、グループ化に関しては、それ自体のようには見えないと考えています ( ) リーダーになるポイントを説得することは、それに似た仲間からの集合的な励まし、または逆に、社会にそれのような人が全くいない場合です。
ポイントは、彼らがどのようなチームになるか、またその総数を事前に知りません。 組合は上から下へと進みます。最初はグループの社長にしがみついていて、それから同じ候補者を支持しているのは誰なのかを反映するだけです。 リーダーとしてのポイントの選択には、3つのパラメーターが影響します:類似性(既に説明されています)、責任、アクセシビリティ。 責任(責任、表 要素付き )の責任 見たい 彼のリーダー。 グループリーダーの候補者には、各ポイントごとに責任が割り当てられます。 可用性(可用性、表 、要素付き )-潜在的なリーダーからの応答があります なんて良い 興味を表す準備ができている 。 責任とアクセシビリティポイントは、自分自身を含めて計算されます。 大きな自己責任(はい、自分の興味を表明したい)と自己利用可能(はい、自分の興味を表せる)がある場合にのみ、つまり 、ポイントは生来の自己疑念を克服することができます。 通常のポイントは、最終的に彼らが最高額を持っているリーダーに参加します 。 通常、最初に、 そして 。
簡単な例を見てみましょう:内なる世界全体が猫を愛している点X、Y、Z、U、V、W、 。 Xは猫にアレルギーがあります。 、Yはそれらをクールに扱い、 、およびZは単純にそれらに依存していません。 。 Uには家に4匹の猫がいます )、Vには5( )、およびWは40( ) 相違の絶対値として非類似性を定義する 。 Xは、1つの条件点でYと異なり、Uでも6と同じです。 次に、類似点、 -これは非類似度のマイナスです。 類似性がゼロのポイントはまったく同じであることがわかります。 よりネガティブ 、より強いポイントが異なります 。 少し直感に反しますが、まあまあです。 例の「自己相似性」のサイズは2ポイント( )
したがって、最初のステップでは、すべてのポイント みんなを責める (自分を含む)間の類似度に比例 そして との間の類似度に反比例 そして最も類似したベクトル ((1)c ) このように:
- 最も近い(最も類似した)ポイントは、他のすべてのポイントに対する責任の分布を定義します。 これまでの最初の2つよりも遠いポイントの位置は、 彼らだけに割り当てられました。
- 最も近いポイントに割り当てられた責任は、2番目に近いポイントの位置にも依存します。
- 手の届く範囲にある場合 多かれ少なかれ彼に似ている候補者がいくつかいます;それらはほぼ同じ責任を与えられます
- ある種のリミッターとして機能します-ポイントが他のすべてとは異なりすぎる場合、それ自体に依存する以外の選択肢はありません
もし それから したい 彼女の代表でした。 彼女が チームの創設者になりたい -何 別のチームに所属したい。
例に戻る:XはYの責任を負います ポイント、Z- ポイント、U- しかし、自分で 。 一般的に、Xは、Yが彼になりたくない場合、ヘイトグループのリーダーがZであることを気にしませんが、UおよびVと通信することはほとんどありません。 Wは他のすべてのポイントとは異なり、そのために何も残されていないため、 自分だけを指してください。
次に、ポイントは、彼らがリーダーになる準備ができているかを考え始めます(リーダーシップのために利用可能、利用可能)。 自分のためのアクセシビリティ(3)は、すべての肯定的な責任、つまりポイントに与えられた「投票」で構成されます。 のために それらを表すのが悪いと彼らが考えるポイントの数は関係ありません。 彼女にとって、主なことは、少なくとも誰かが彼女が彼らをうまく表現すると考えているということです。 在庫状況 のために どれくらい 私は自分自身と彼に関する肯定的なレビューの数を代表する準備ができています(2)(彼はチームの優れた代表者になると信じています)。 この値は、あまりにも多くの人がよく考えるポイントの影響を減らすために、上からゼロに制限されているため、さらに多くのポイントを1つのグループに結合せず、サイクルが制御不能になりません。 少ない あなたが収集する必要があるより多くの票 に 0に等しかった(つまり、この点は、その翼の下でも )
選挙の新しいラウンドが始まりますが、今 。 それを思い出してください 、そして 。 これは、異なる効果があります
- 。 それから 役割を果たさず、(1)すべてにおいて 右側は、最初のステップよりも小さくなりません。 基本的にポイントを遠ざける から 。 ポイントの自己責任は、彼女の観点からすると、最高の候補者が悪い評価をしているという事実から上昇します。
- 。 両方の効果がここに表示されます。 このケースは2つに分かれています。
- -最大 ケース1と同じですが、ポイントに割り当てられた責任が増加します
- -最大 それから 最初のステップに過ぎません 減少します。 類推を続けると、まるでリーダーになるかどうかをすでに検討していたポイントが追加の承認を受けたかのようです。
- -最大 ケース1と同じですが、ポイントに割り当てられた責任が増加します
アクセシビリティは、競争に勝ち残るポイントを残します(W、 、しかし、これは(1)には影響しません。 修正を考慮しても、Wは他のポイントから非常に遠い)または他のポイントの準備ができているポイント(Y、(3)でXとZの加数に関して持っています)。 厳密に誰かに似ているわけではないが、誰かに似ているXとZは、競争から除外されます。 これは、負債の分配に影響し、可用性の分配などに影響します。 最終的に、アルゴリズムは停止します- 変更を停止します。 X、Y、ZはYを中心にチームを組みます。 UをリーダーとするUとVの友人。 よく、40匹の猫と。
アルゴリズムの決定ルールをもう一度見るために、決定ルールを書き直します。 (1)と(3)を使用します。 示す -事実のために調整された類似性 彼の指揮能力について話す ; -相違点 - 修正されました。
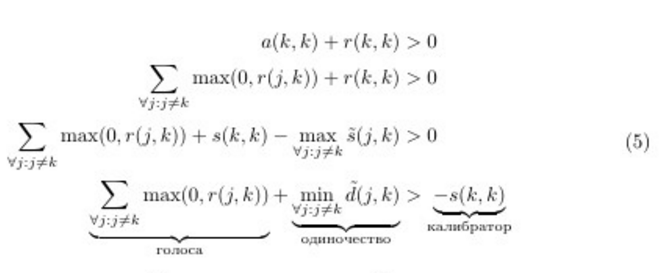
おおよそ最初に策定したもの。 このことから、ポイントの自信が低いほど、より多くの「投票」を収集する必要があるか、リーダーになるために必要な他の人との差が大きいことがわかります。 つまり 少ない 、グループが大きくなります。
さて、メソッドがどのように機能するかについての直感的な洞察をいくつか得ていただければ幸いです。 もう少し深刻です。 アルゴリズムを適用することのニュアンスについて話しましょう。
理論への非常に短い説明
クラスタリングは、制約付きの離散的な最大化問題として表すことができます。 類似性関数が要素のセットで与えられるようにします 。 私たちの仕事は、このようなラベルのベクトルを見つけることです 機能を最大化する
どこで -期間リミッターが等しい ポイントがあれば それがポイントを選んだ 彼らのリーダー( )しかし、彼女自身 自分をリーダーとは見なしません( ) 悪いニュース:完璧なものを見つける -これは、オブジェクト配置問題として知られるNP複雑な問題です。 それにもかかわらず、その解決策にはいくつかの近似アルゴリズムがあります。 興味のある方法で 、 そして は、2部グラフの頂点によって表され、その後、それらの間で情報が交換されます。これにより、確率論的な観点から、各要素に最適なラベルを評価できます。 ここで結論を参照してください 。 2部グラフでのメッセージの配信については、 こちらをご覧ください 。 一般に、近接度の広がりは信念の循環的な広がりの特別なケース(むしろ、狭まる)です(ループ状の信念の伝播、LBP、 こちらを参照)が、一部の場所では確率の合計(Sum-Productサブタイプ)ではなく、最大(Max-Productサブタイプ)それらの。 第一に、LBP-Sum-Productは桁違いに複雑であり、第二に、そこで計算上の問題に遭遇しやすくなり、第三に、理論家は、これがクラスタリング問題に対してより理にかなっていると言います。
APの作成者は、グラフのある要素から別の要素への「メッセージ」について多くのことを語っています。 この類推は、グラフ内の情報の普及による式の導出に由来します。 私の意見では、アルゴリズムの実装にはポイントツーポイントのメッセージはありませんが、3つのマトリックスがあるため、少し混乱します 、 そして 。 次の解釈をお勧めします。
- 計算するとき データポイントからのメッセージが送信されています 潜在的なリーダーへ -マトリックスを調べます そして 線に沿って
- 計算するとき 潜在的なリーダーからメッセージが送信されています 他のすべてのポイントへ -マトリックスを調べます そして 列に沿って
アフィニティ伝播は決定論的です。 彼には困難があります どこで -データセットのサイズ、および -反復回数、および メモリ。 スパースデータのアルゴリズムには変更がありますが、データセットのサイズが大きくなるとAPは非常に悲しくなります。 これはかなり深刻な欠陥です。 ただし、近接の広がりは、データ要素の次元に依存しません。 APの並列化バージョンはまだありません。 アルゴリズムの開始セットの形式での自明な並列化は、その決定論のため適切ではありません。 公式FAQには、リアルタイムデータを追加するオプションはないと書かれていますが、 この記事を見つけました。
APの加速バージョンがあります。 この記事で提案されている方法は、アクセシビリティと責任のマトリックスの更新をまったく計算する必要がないという考えに基づいています。なぜなら、他のポイントの太い部分のすべてのポイントは、それらから離れたインスタンスにほぼ同じであるためです。
試してみたいなら(それを続けてください!)、式(1-5)を手に入れることをお勧めします。 パーツ それらは、ニューラルグリッドReLuのように疑わしく見えます。 ELuを使用するとどうなりますか。 さらに、サイクルで何が起こっているかの本質を理解したので、必要な動作を担当する式にメンバーを追加できます。 したがって、特定のサイズまたは形状のクラスターに向けてアルゴリズムを「プッシュ」できます。 一部の要素が1つのセットに属する可能性が高いことがわかっている場合は、追加の制限を課すこともできます。 しかし、これは推測です。
必須の最適化とパラメーター
アフィニティ伝播は、他の多くのアルゴリズムと同様に、次の場合に早期に中断できます。 そして 更新を停止します。 このため、ほとんどすべての実装で2つの値が使用されます。最大反復回数と、更新の値がチェックされる期間です。
親和性の伝播は、何らかの優れたクラスタリングが存在する場合に計算振動を起こしやすい傾向があります。 問題を回避するために、まず最初に、類似性マトリックスにわずかなノイズが追加されます (決定論に影響を与えないように、順序のsklearn実装では、 )、そして次に、更新するとき そして 単純な割り当てではなく、 指数平滑化割り当てが使用されます。 さらに、2番目の最適化は一般に結果の品質に良い影響を与えますが、そのため、必要な反復回数が増加します 。 著者は、平滑化オプションの使用を提案しています。 デフォルト値で 。 アルゴリズムが収束しない、または部分的に収束する場合、増加 前に または前 対応する反復回数が増加します。
これが障害の外観です。中規模のクラスターの輪に囲まれた小さなクラスターの束:
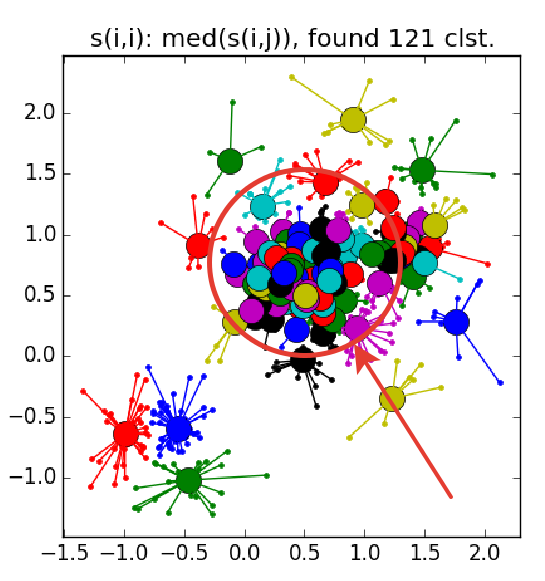
すでに述べたように、あらかじめ決められた数のクラスターの代わりに、パラメーター「自己相似性」が使用されます ; 少ない 、クラスターが大きくなります。 このパラメーターの値を自動的に調整するためのヒューリスティックがあります:すべての中央値を使用します より多くのクラスターの場合。 25パーセンタイルまたは少なくとも -少ない(まだカスタマイズする必要があります) 「自己相似性」の値が小さすぎるか大きすぎる場合、アルゴリズムは有用な結果をまったく生成しません。
として 言うまでもなく負のユークリッド距離を使用します そして しかし、誰もあなたの選択を制限しません。 実数のベクトルからのデータセットの場合でも、多くの興味深いことを試すことができます。 一般に、著者は、類似性の機能には特別な制限は課されていないと主張している 。 対称性ルールまたは三角形ルールが満たされることさえ必要ではありません。 しかし、あなたが持っているより独創的であることは注目に値する 、アルゴリズムが興味深いものに収束する可能性が低くなります。
近接伝播中に取得されるクラスターサイズはかなり小さな制限内で変化します。データセットに非常に異なるサイズのクラスターが含まれる場合、APは小さなクラスターをスキップするか、いくつかの大きなクラスターをカウントできます。 通常、2番目の状況はそれほど不快ではありません-修正可能です。 したがって、多くの場合、 APには後処理(グループリーダーの追加クラスタリング)が必要です。 他の方法が適していますが、タスクに関する追加情報がここで役立ちます。 正直なところ、孤独な点が彼らのクラスターで際立っていることを覚えておいてください。 このような排出は、後処理の前にフィルターで除去する必要があります。
実験
ふう、テキストの壁は終わり、写真の壁が始まった。 異なるタイプのクラスターでのアフィニティー伝搬を確認しましょう。
写真の壁
近接伝播は、データの次元よりも小さい次元のフォールドの形のクラスターでうまく機能します。 APは通常、折り目全体を強調表示しませんが、それを小さな断片、サブクラスターに分割します。これらは、後で接着する必要があります。 ただし、これはすでにそれほど難しくはありません。20ポイントでは、2万ポイントよりも簡単です。さらに、クラスターの伸長に関する追加情報があります。 これは、k-meansや他の多くの非専門アルゴリズムよりもはるかに優れています。
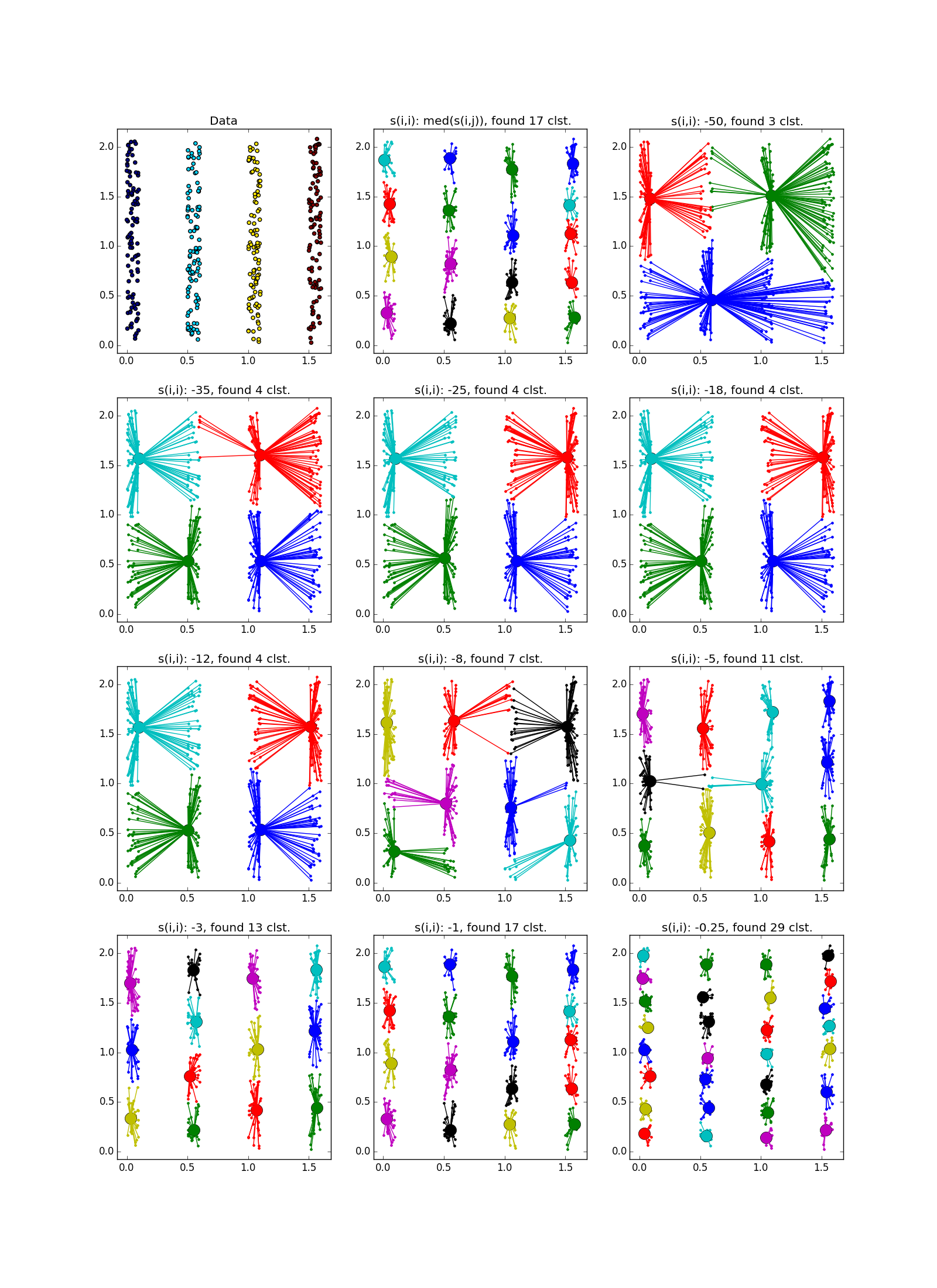
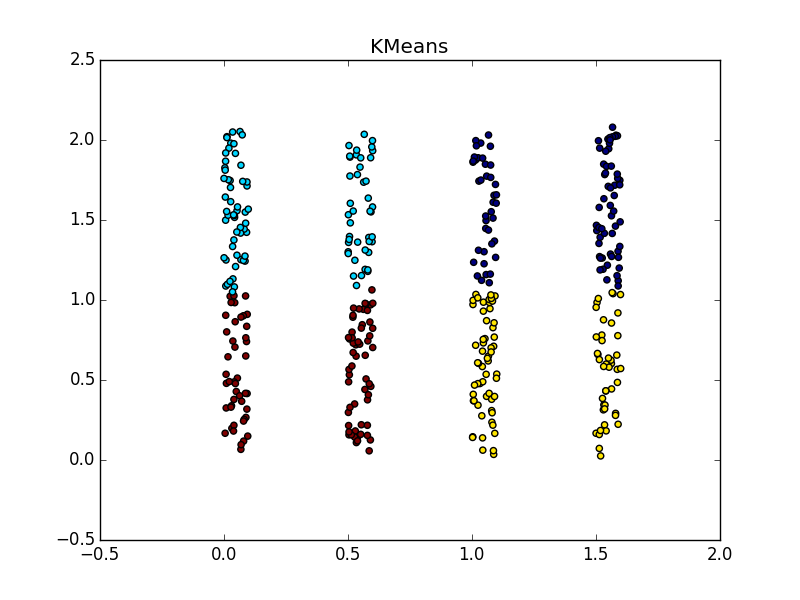
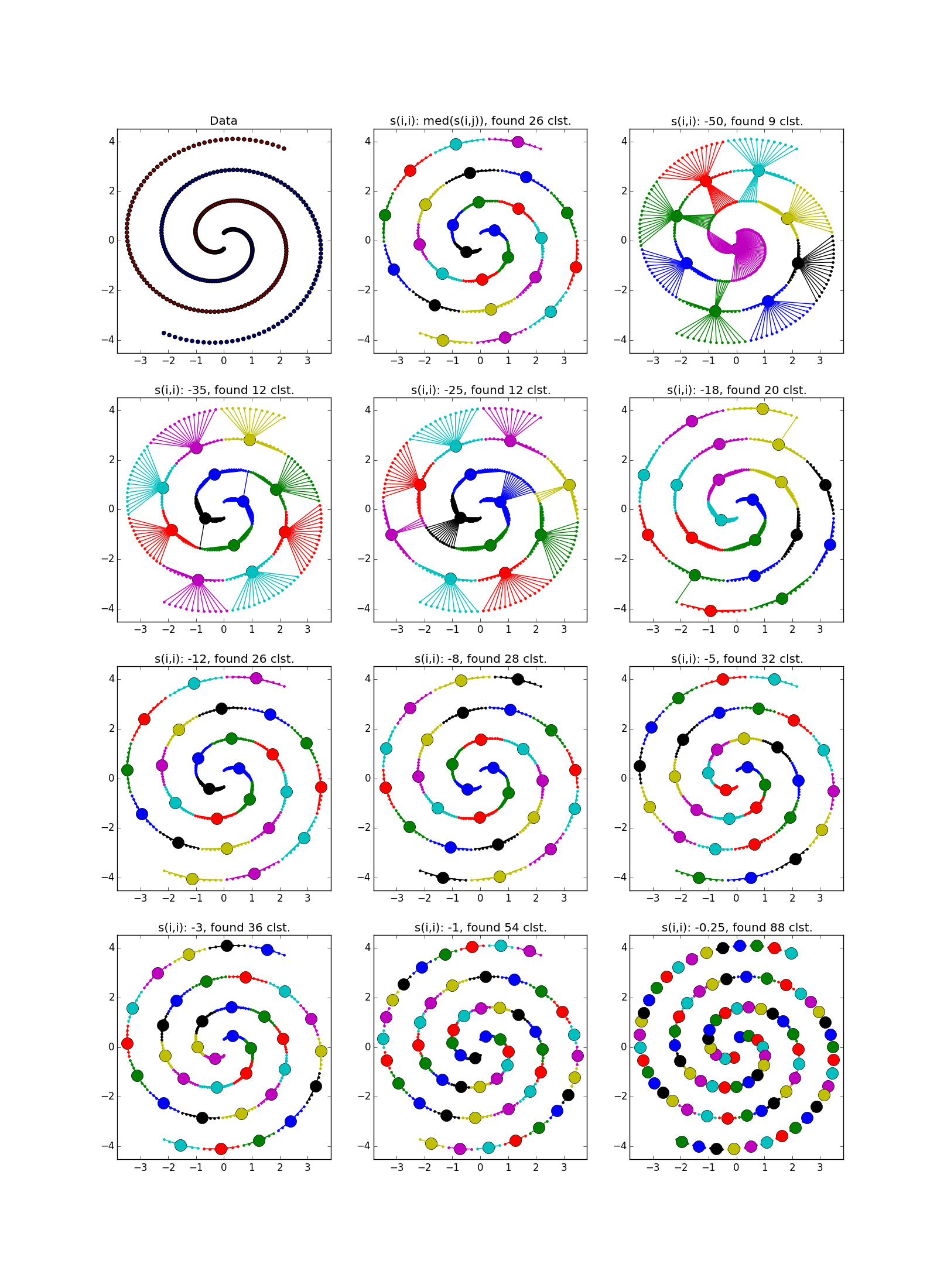
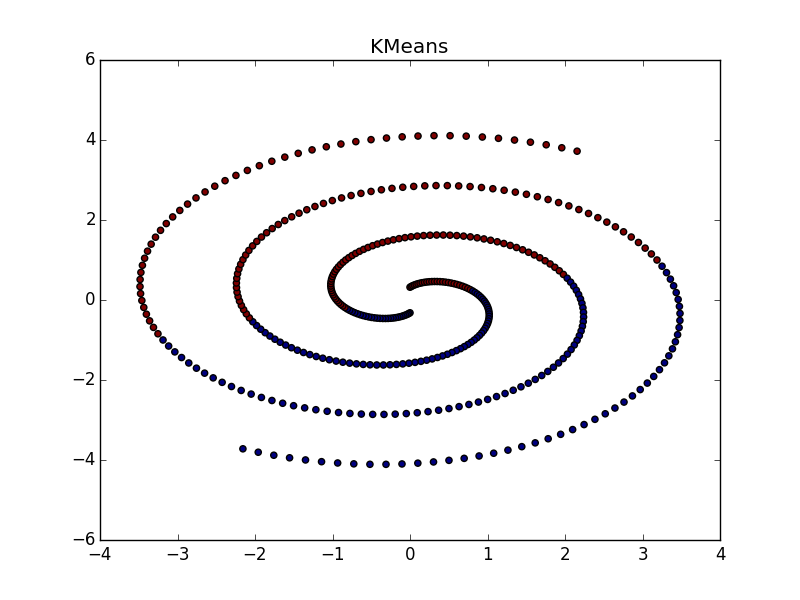
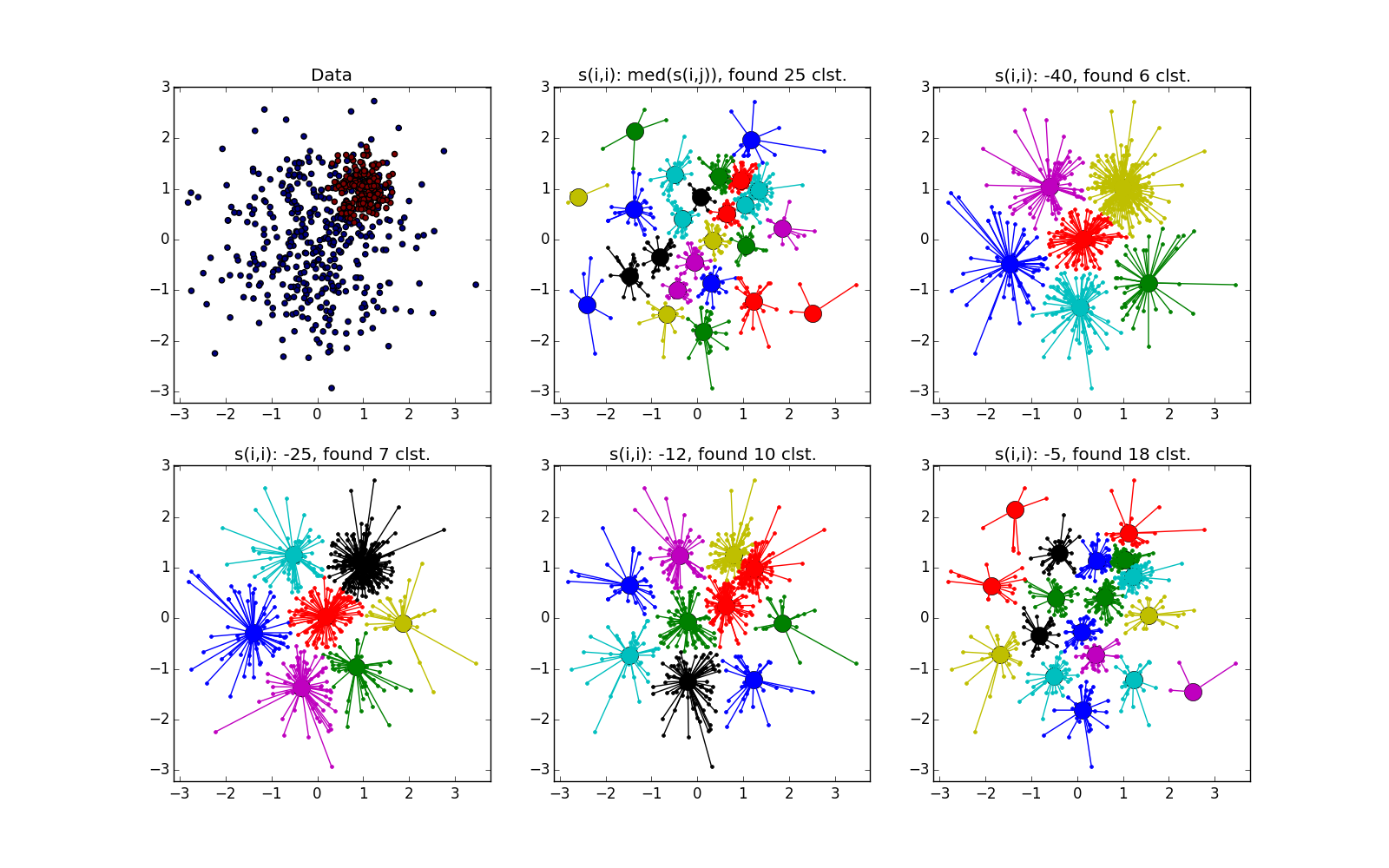
折り目が別の血塊を横切ると状況は悪化しますが、それでもAPはこの場所で何か面白いことが起こっていることを理解するのに役立ちます。
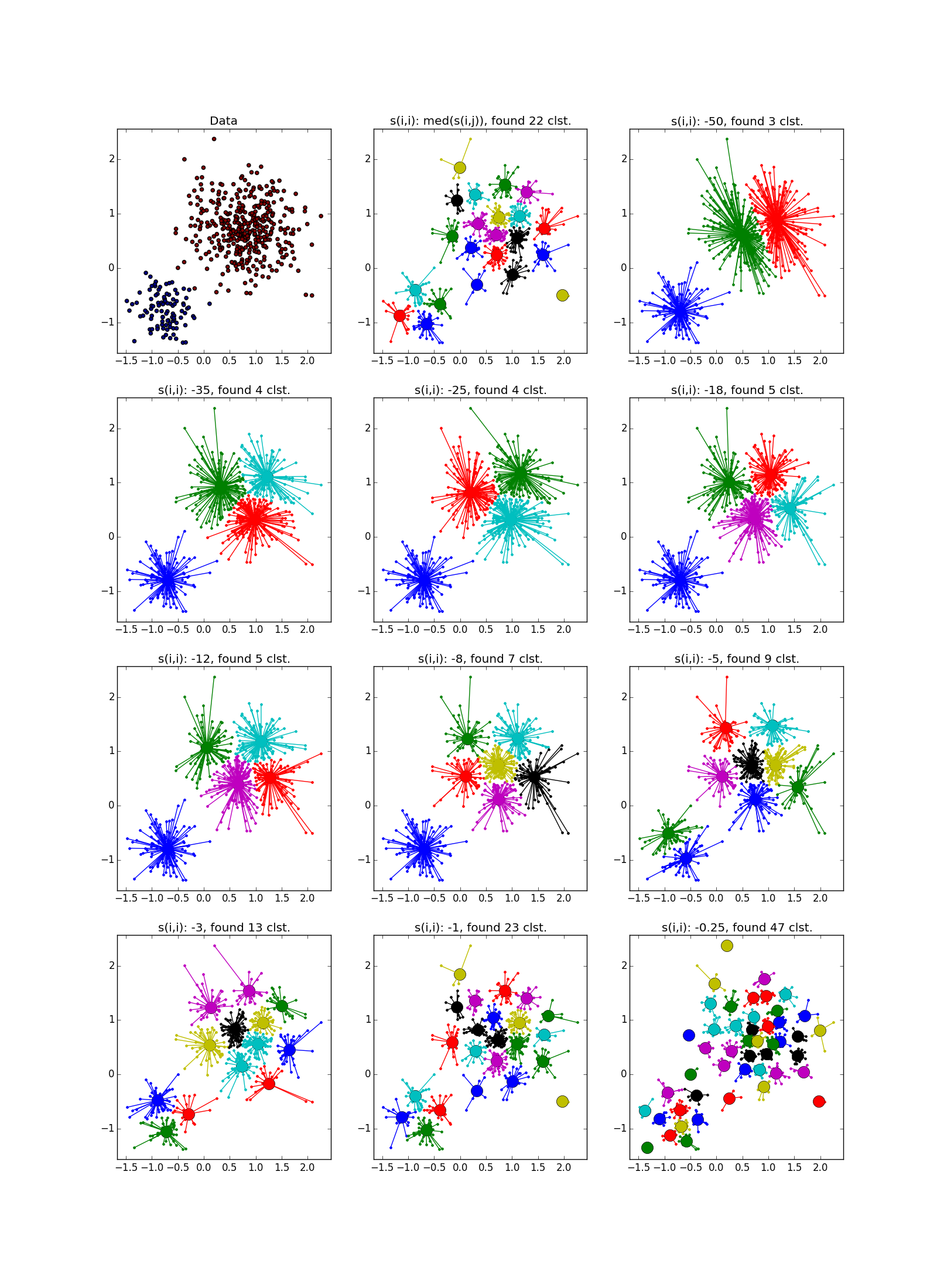
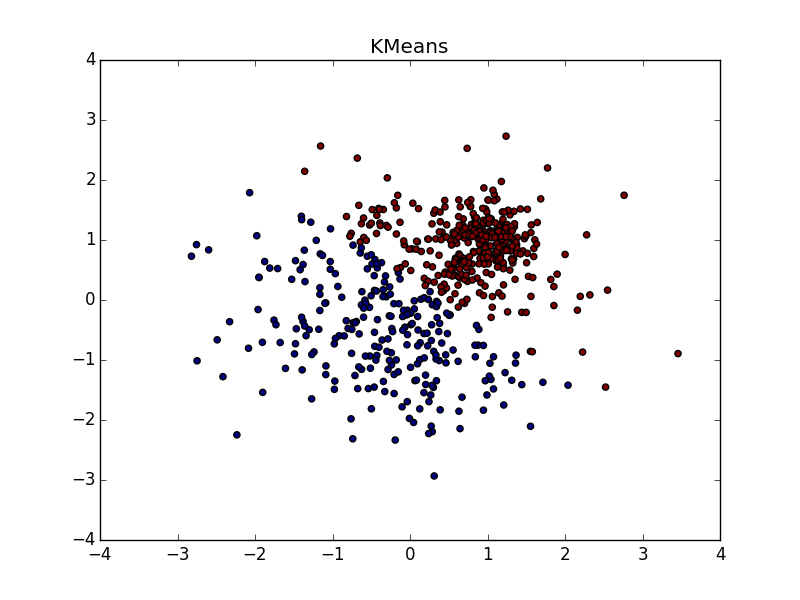
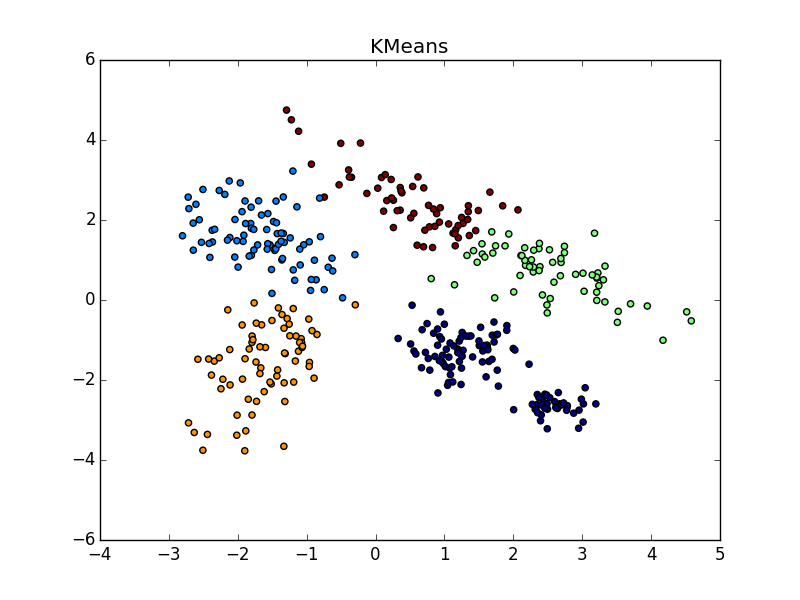
パラメータとポストプロセッサクラスタ化ツールの適切な選択により、異なるサイズのクラスタの場合にAPが勝ちます。 に注意してください -クラスターを上から右に組み合わせた場合、ほぼ完璧なパーティション。
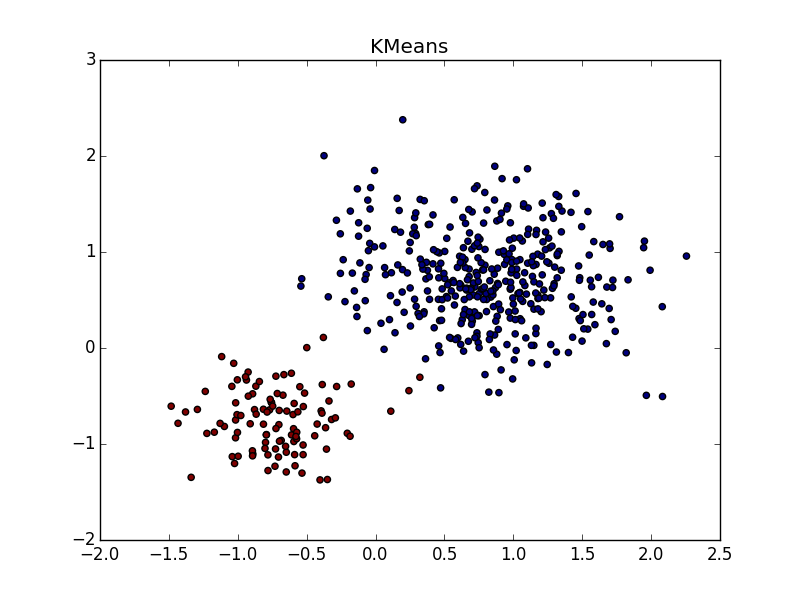
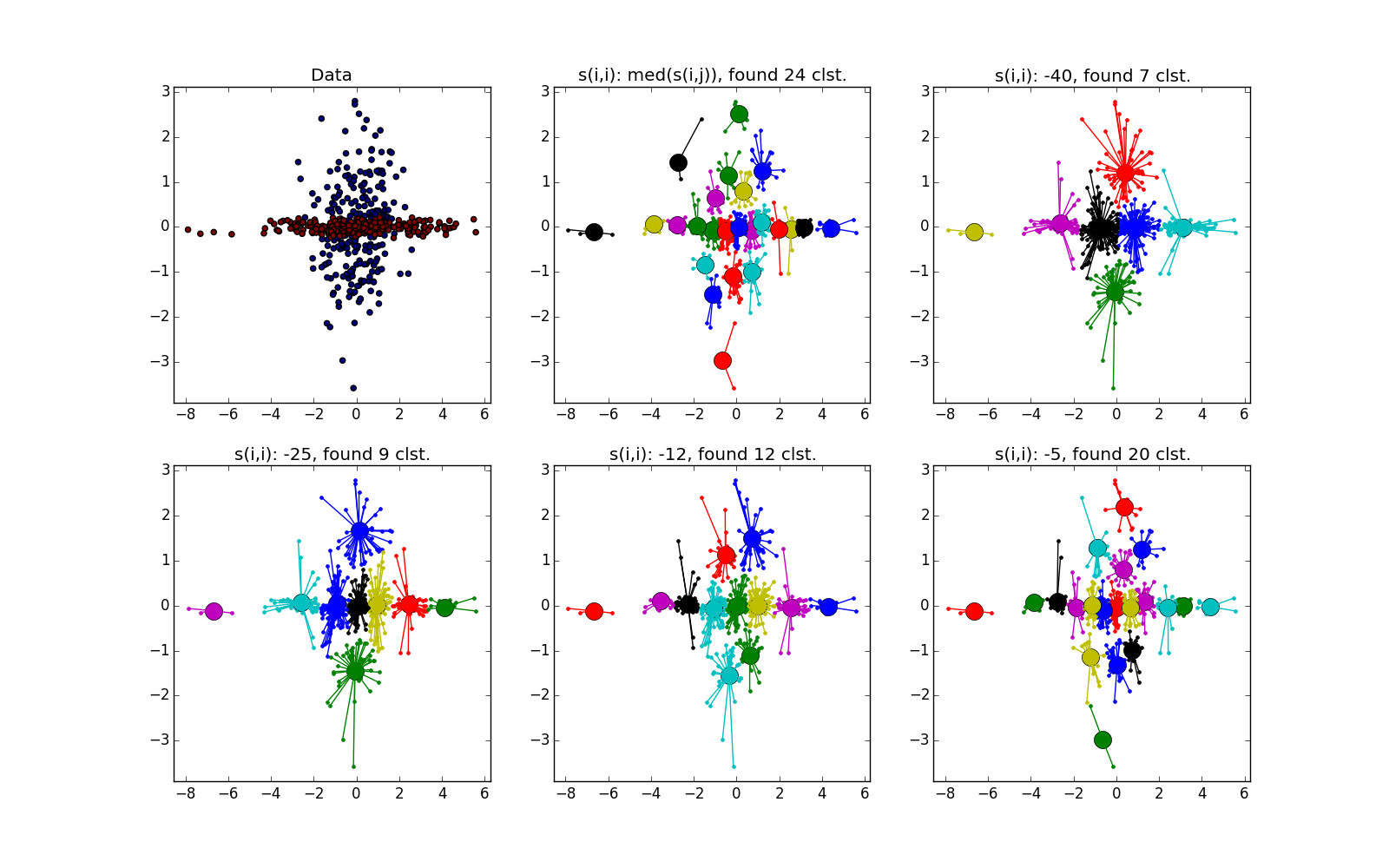
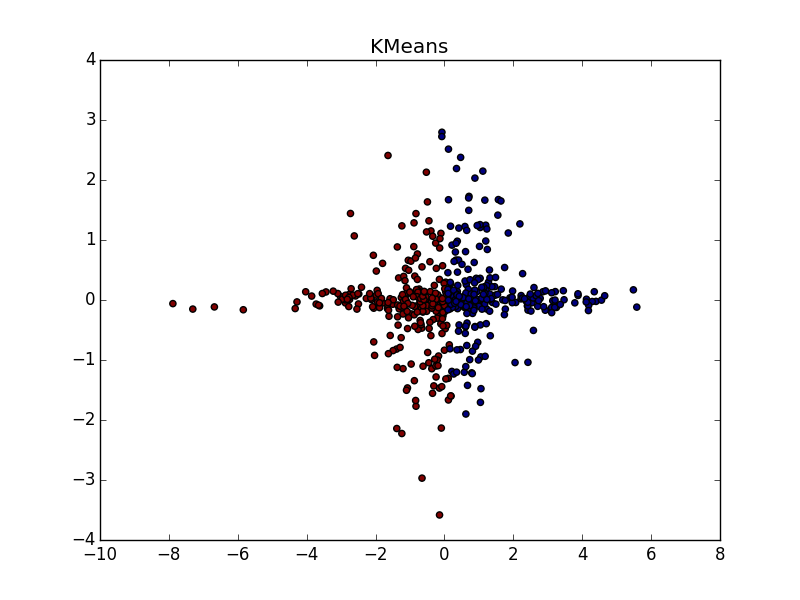
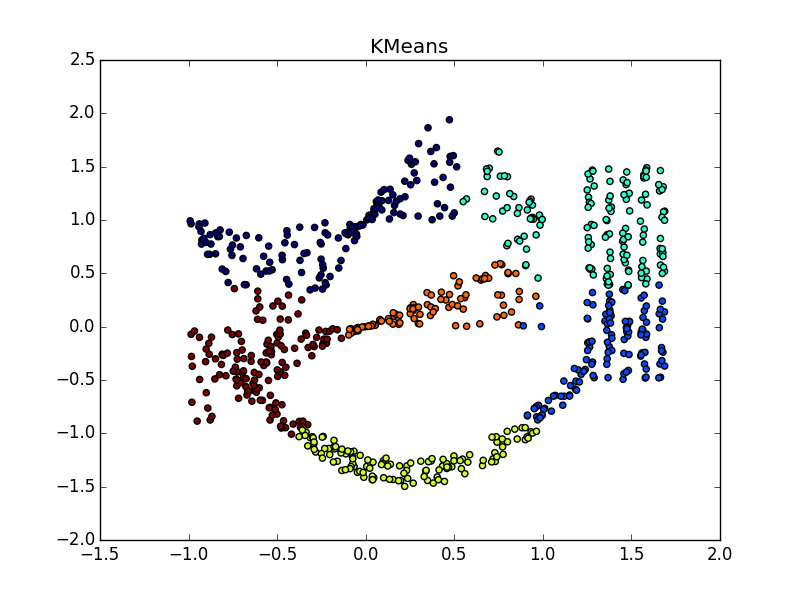
同じ形状のクラスターで、密度が異なる場合、APおよびk-meansプラスまたはマイナスパリティ。 ある場合には、正しく推測する必要があります , — 。


, , - k-means. , , «» , AP .
:
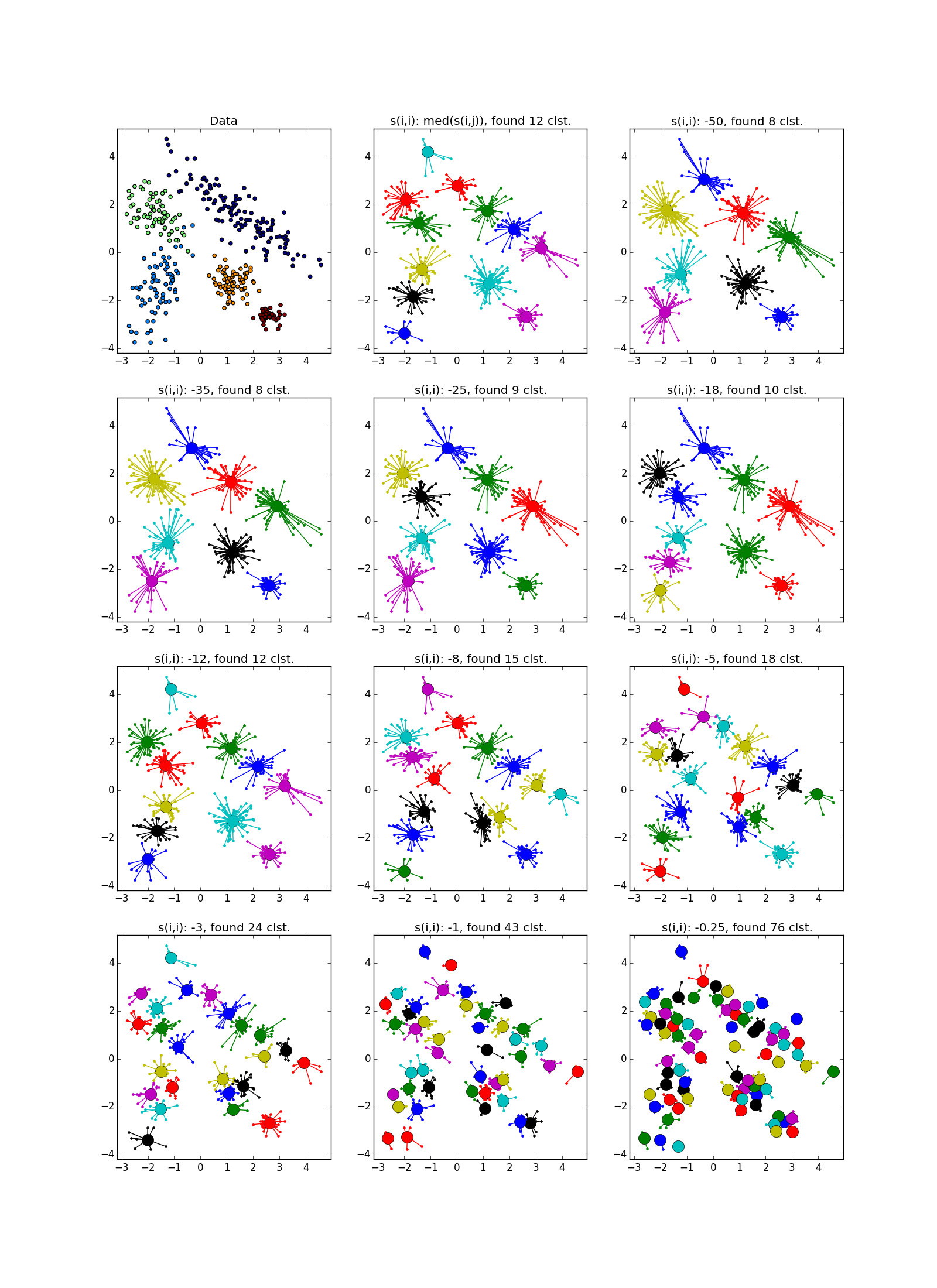
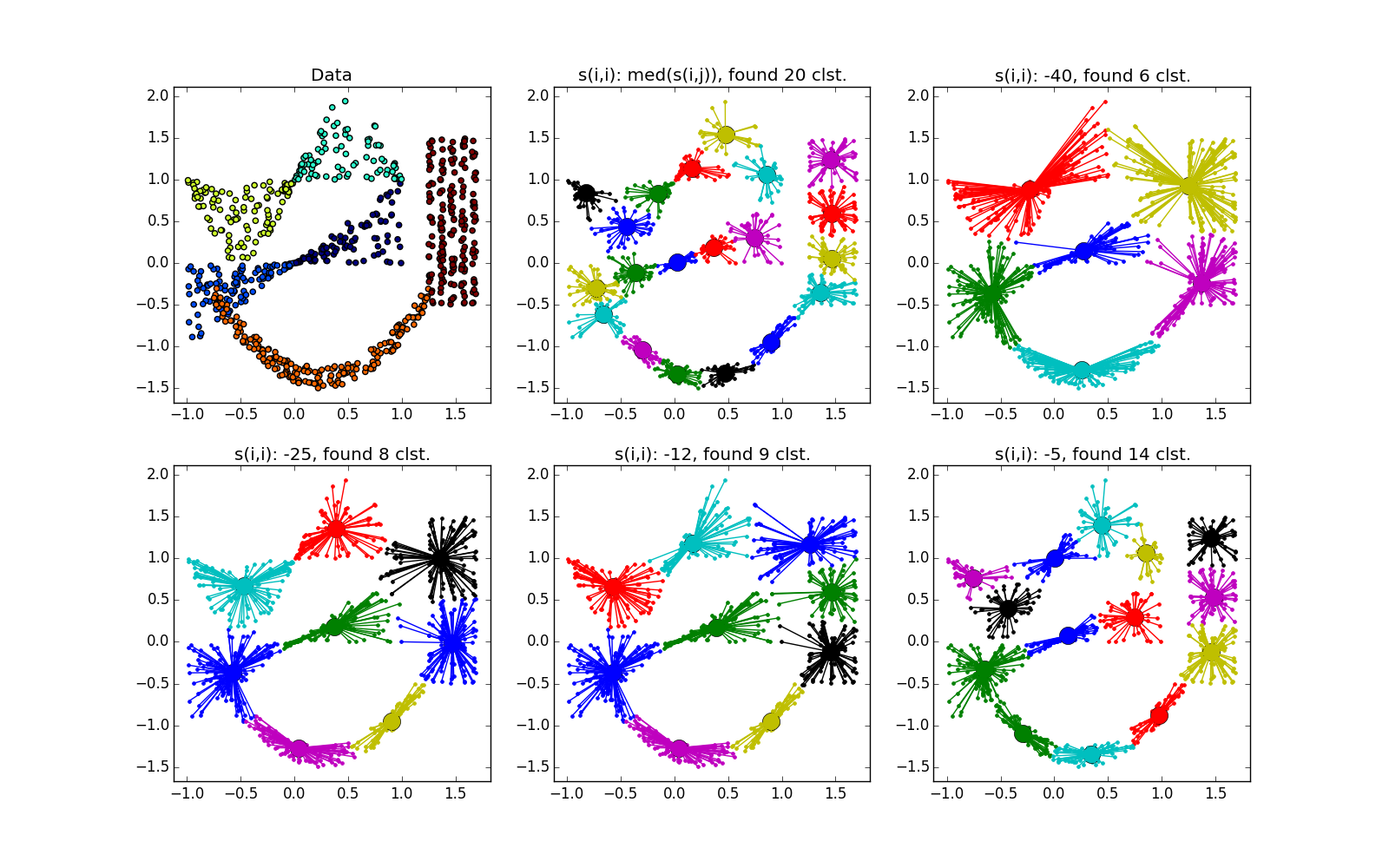
折り目が別の血塊を横切ると状況は悪化しますが、それでもAPはこの場所で何か面白いことが起こっていることを理解するのに役立ちます。
パラメータとポストプロセッサクラスタ化ツールの適切な選択により、異なるサイズのクラスタの場合にAPが勝ちます。 に注意してください -クラスターを上から右に組み合わせた場合、ほぼ完璧なパーティション。
同じ形状のクラスターで、密度が異なる場合、APおよびk-meansプラスまたはマイナスパリティ。 ある場合には、正しく推測する必要があります , — 。
, , - k-means. , , «» , AP .
:
まとめ
アフィニティ伝播を使用する場合
- あなたはそれほど大きくありません( )または大きな尺度ではなく、疎()データセット
- 事前にわかっている近接機能
- さまざまな形状の多数のクラスターと、わずかに異なる要素数が表示されることを期待しています。
- 後処理をいじる準備はできていますか
- データセット要素の複雑さは関係ありません
- 近接関数のプロパティは関係ありません
- クラスターの数は関係ありません
言われている様々な科学者が成功した親和伝播のために適用されていること
- 画像のセグメンテーション
- ゲノム内のグループの分離
- アクセシビリティによる都市の分割
- 花崗岩サンプルのクラスタリング
- Netflixでの映画のグループ化
これらすべてのケースで、結果はk-meansを使用するよりも優れていました。これ自体が何らかのスーパー結果であることではありません。これらすべてのケースで、他のアルゴリズムとの比較が行われたかどうかはわかりません。今後の記事でこれを行う予定です。どうやら、実際のデータセットでは、さまざまな幾何学的形状のクラスターに対処するために近接性を広げる機能が最も役立ちます。
まあ、それだけです。次回は、別のアルゴリズムを検討し、近接伝搬法と比較します。頑張って、ハブル!