このサイトはここにあり、そのソースコードはgithubで読むことができます。
カットの下では、データの収集方法、サイトの構築方法、クラウドの配置方法について詳細に説明されています。 そして、少し観察します。
素敵な読書を!
観察
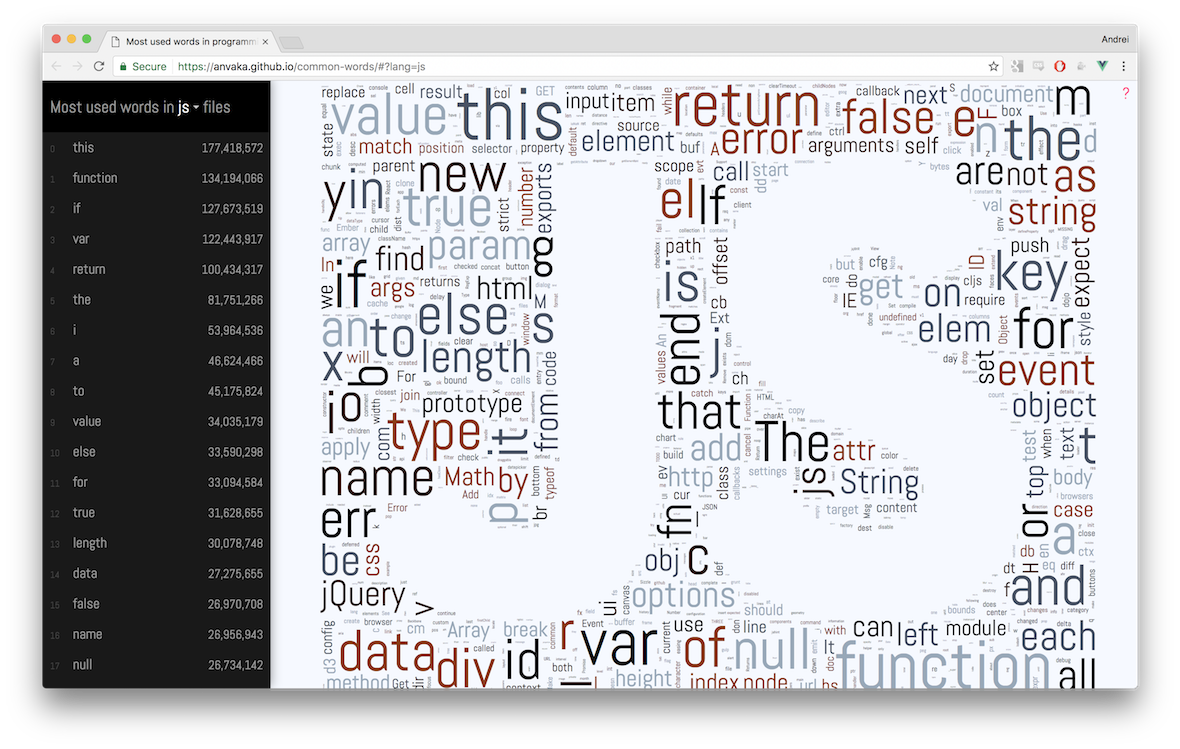
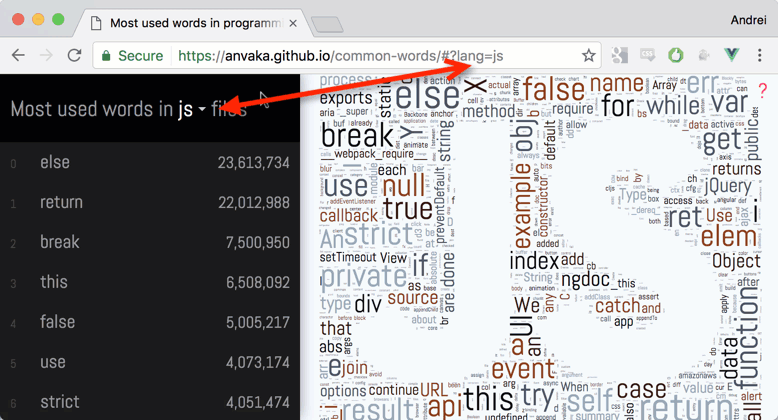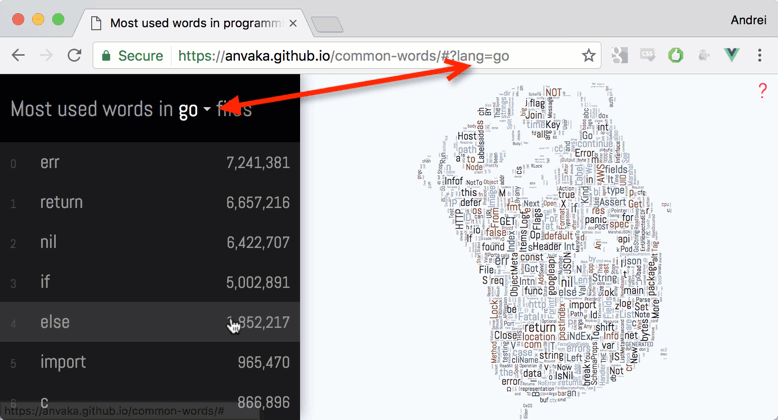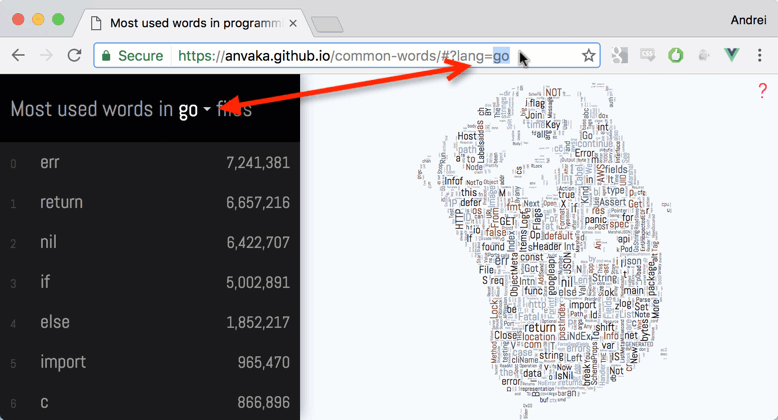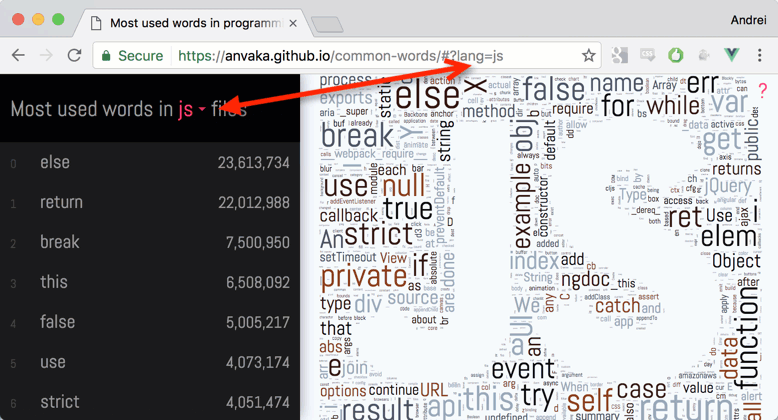
- すべてのプログラミング言語で最も人気のあるテキストは、ライセンスからのテキストでした。 すべての言語の中で、Javaが勝ちました。 最も人気のある966個の単語のうち、127個はライセンスに関するものでした。

おそらく、各.javaファイルにライセンスを追加する文化は、他の言語よりもはるかに強力です。 公式のハローワールドを見たことがありますか?
-
Lua
はわいせつな言葉がトップに入った唯一のプログラミング言語です。 見つけることができますか?
- Goでは、
err
が最も一般的な単語でした。 この言語には例外はありませんか?
どうやって?
BigQueryを使用してデータを収集しました。 GoogleはGitHubとともに、公開日付セットgithub_reposにソースコードの完全なスナップショットを投稿しました。 インデックスは2016年末に作成されました。
クラウドを構築するとき、データにいくつかの制限を課します。
- 単語を含む行の最大長は120文字を超えてはなりません。 これは、生成されたコード(たとえば、縮小されたjavascript)を取り除くのに役立ちます。
- 句読点(
, ; : .
)、演算子(+ - * ...
)および数字は無視されます。 たとえば、行a + b + 42
は、2つの単語a
とb
としてカウントされます - ライセンスのテキストが視覚化をオーバーロードしたため、ライセンスに固有のマーカーワードがあるすべての行(たとえば、
license
、noninfringement
)を削除しました。 - 大文字と小文字は区別されません。
This
とthis
は2つの異なる単語と見なされます。
データはどのように収集されましたか?
BigQueryは素晴らしいプラットフォームです。 githubのすべてのファイルの内容は、テーブルにプレーンテキストで保存されます。
| ファイル | 内容 |
|---|---|
| ファイル1.h | //ファイル1のコンテンツ\ n#ifndef FOO \ n#FOOを定義... |
| ファイル2.h | //ファイル2のコンテンツ\ n#ifndef BAR \ n#BARを定義... |
BigQueryを使用すると、通常のSQLクエリを記述し、驚くほど高速に実行できます。
最初に、すべてのファイルの内容を単語に分割し、
GROUP BY
を使用してそれらをカウントすることにしました。
| 言葉 | 何回会った |
|---|---|
| ファイル | 2 |
| 内容 | 2 |
| ... | ... |
残念なことに、このアプローチでは単語が文脈から外れます。 私は本当に言葉がどのように使われるかの例を示したいと思いました。

どうする? 単純に単語に分割する代わりに、ファイルが行ごとに分割される中間テーブルを作成しました。
| ひも | 会った回数 |
|---|---|
| //ファイル1のコンテンツ | 1 |
| #ifndef FOO | 1 |
| #ifndef FOO | 1 |
| ... | ... |
この中間ストレージにより、処理されるデータのサイズが〜2TBから〜12GBに削減されます。
このテーブルから最も人気のある単語を取得するために、各行を個々の単語に分割することができますが、同時に元の行を保持します。
| ひも | 言葉 |
|---|---|
| //ファイル1のコンテンツ | ファイル |
| //ファイル1のコンテンツ | 内容 |
| #ifndef FOO | ifndef |
| #define FOO | フー |
| ... | ... |
実際には何も変わっていないように思えます。 ただし、この解釈では、ウィンドウ関数を使用して各単語の上位10行を取得できます(
SELECT ... OVER (PARTITION BY ...)
- StackOverflowのこの質問のように )。
現在のリクエストコードは、 extract_words.sqlにあります。
ところで...私のSQLは非常にエントリーレベルです。 したがって、読者の皆さん、間違いを見つけた場合、またはより適切な方法を知っている場合は、お知らせください。
タグクラウドを描くには?
すべてのタグレンダリングの中心にあるのは、このアルゴリズムです。
`w`:
1. `w` (x, y)
2. - 1.
このコードは無限に実行される可能性があります。何回か繰り返した後に試行を停止するか、単語が収まるまでフォントサイズを小さくするからです。
簡単にするために、単語は長方形と考えることができます。 画面上のすべての長方形を、画面上の占有ピクセルと交差しないように配置しようとしています。
このアルゴリズムの最もリソースを消費する部分は、交差チェックです。 特に最後に、すべての空き領域が基本的にすでに占有されている場合、単語を挿入できる新しい領域を見つけることは非常に困難です(場合によっては不可能です)。
異なる実装は、占有スペースにインデックスを付けることにより、アルゴリズムのこの部分を高速化しようとします。
- 合計面積テーブルを使用する人もいます 。 これは、
O(1)
時間中に画面上で何かを発言したり、交差したりできる特別なデータ構造です。 残念ながら、画面上の変更後に構造を更新する必要があるため、パフォーマンスは平凡です。
- 占有されているスペースのインデックスを作成するために、さまざまなRツリーを使用する人々を見ました。 このアプローチでは、交差エリア検索は合計エリアテーブルよりも遅くなりますが、インデックスの維持は速くなります。 ただし、Rツリーの実装は最も簡単なタスクではありません。
私は何か他のものを試してみたかった。 占有スペースにインデックスを付ける代わりに、空き領域のインデックスが必要でした。 そのため、新しい到着の場所があることが保証されている大きな長方形をすぐに選択できます。
インデックスには、 quad-treeを使用しました。 ツリーの各中間ノードには、空きピクセルまたは占有ピクセルの数に関する情報が格納されます。 そのため、十分な空きピクセルがない象限を即座にスイープできます。
これを写真で見る最も簡単な方法。 JSロゴのクワッドツリーを次に示します。

白い空の長方形は空き領域です。 これらの空の長方形のいずれよりも小さい新しい長方形を追加する必要がある場合は、そこに安全に描画できます。
このアプローチは良い結果をもたらしますが、視覚的なアーチファクトにつながる可能性があります。 結局のところ、象限の交差点に新しい長方形を配置することはできません。

さらに、どのフリー象限にも十分なサイズがない場合はどうなりますか? また、隣接する象限を結合する場合、十分なスペースがありますか?
無料の象限を結合することが私の次のステップでした。 ターゲットの左右にクワッドを「拡張」します。 これにより、ビルド時間が若干遅くなりますが、アーティファクトが減り、より良い結果が得られます。

ところで...私のスタッカーコードはサイトで利用できません。 それは急いで書かれており、他のコンテキストで使用することは困難です。 優れたスタッカーが必要な場合は、
amueller / word_cloud
サイトはどのように作成されましたか?
テキストレンダリング
全体として、タグクラウドの構築速度に満足しています。 しかし、私のサイトのコンテキストでは、この速度では十分ではありませんでした。
SVGを使用して画面に単語を描画しました。 非常に多くのテキストSVG要素を描画すると、数秒間UIストリームを簡単にブロックできます。 タグクラウドのポジションは他にどこで取得できますか?
幸いなことに、スタッカーをオフラインで取り外すことができます。 ブラウザーがページを開いたときに単語の位置をその場で数えるのではなく、一度位置を数えてファイルに保存し、静的に描画することにしました。 これにより、UIストリームの最適化に集中できます。
ブラウザーを長時間ブロックしないようにするには、すべての作業を小さな断片に分割し、非同期で実行する必要があります。 イベントループの1回の繰り返しで、Nワードを追加して関数を終了し、ブラウザーが他のイベントを処理できるようにします。 次の反復で、さらに単語を追加します。
これらの目的のために、私はanvaka / raforを書きました 。 このライブラリは
requestAnimationFrame()
基づく適応型の非同期「for」ループです。 すべての反復はイベントループのさまざまな段階で実行されるため、UIストリームの負荷は軽減されます。 サイトの初期読み込みはよりスムーズに見えます。
ナビゲーションとズーム
マウス、キーボード、またはタッチスクリーンを使用して、Googleマップと同じように、ズームイン、地図の削除、画面上での移動ができます。 これはすべて、 panzoomライブラリを使用して行われます。
アプリケーションモデル
UIにvue.jsを使用しています。 使いやすく、操作も迅速です。 vueコンポーネントを別々のファイルに入れると特にクールです。js/マークアップ/スタイルを頻繁に切り替える必要はありません。 ホットリロードは開発を特に楽しいものにします。
アプリケーションの状態は、単一のappStateオブジェクトに保存されます。 プログラミング言語を選択すると、単語とそのコンテキストが非同期にロードされます。
コンポーネント間でイベントを交換するには、ミニライブラリngraph.eventsを使用します。 最初は、グラフライブラリ内のイベントの高速交換用に作成しました。 しかし、ここで彼女はコーディネーターとして正常に動作します。
最後に、 anvaka / query-stateは、プログラミング言語の選択に双方向バインディングでクエリ文字列をバインドします
結論として
このプロジェクトは、過去2か月間の私の夜の趣味です。 タグクラウドのすべての欠陥にもかかわらず、私は非常に興味がありました。
あなたもこの研究を楽しんだことを心から願っています:)!
読者の皆様、ご清聴ありがとうございました。 そして、彼女の限りないサポートとヒントをくれた私のソウルメイトに特に感謝します。