こんにちは、私の名前はAlexander Zeleninで、私は 男のイグレットに ウェブ開発者。 1年半前、 オンラインゲームの開発について話しました 。 それで、少し成長しました...ソースコードの総量は「戦争と平和」を倍にしました。 ただし、この記事では、コードについてではなく、プロジェクトインフラストラクチャの構成について説明します。
目次
- 静かに眠りたい!
1.1。 安定した建築計画
1.2。 サーバー/データセンターの選択
1.3。 負荷分散
1.4。 すべてを監視
1.5。 リンクされたプロジェクト-別のサーバー
1.6。 サポートサービスの選択 - 心配をやめて開発を始める方法
2.1。 写真を保存する場所は?
2.2。 ホームネットワークのセットアップ
2.3。 バックアップおよびアーカイブ戦略
2.4。 あなたのドロップボックス
2.5。 仮想マシン
2.6。 Jira-Confluence-Bitbucket-Bamboo - 結果は何ですか?
- そして、ゲームはどうですか?
目次は年表を反映しておらず、少なくともどこかで一致します。 これはハウツーではなく、マニュアルなどでもありません。 これは、小さなプロジェクトの背後にあるもののアイデアを与えるために設計されたレビュー記事です。
ほぼすべてのアイテムにはかなり広範な歴史があり(私は意図的にすべてを大幅に削減しました)、独立した本格的な記事を利用しています。
この記事が需要があることが判明した場合、特定のツールを選択して構成する方法を示すサイクルを徐々に作成します。
ランダムな順序で読むことができます。
最終インフラストラクチャの重要な要素は、信頼性と保守コストです。
これらすべてを提供することで、1か月あたり1万5,000ルーブル未満のコストがかかり、そのほとんどがVPCによって消費されます。 そして、製品自体の安定性を犠牲にして、より安価なデータセンターを使用すれば、3000人に会うことができます。 これらの数値には、不良品の減価償却と交換が含まれます。
静かに眠りたい
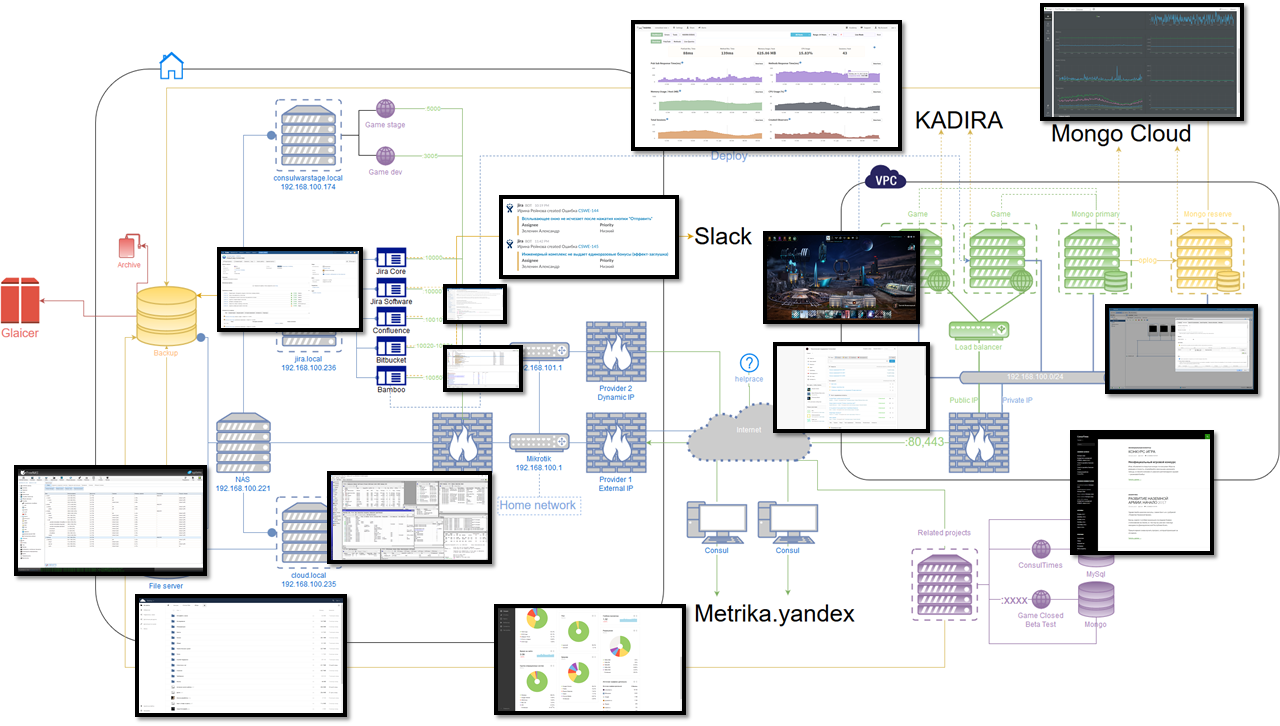
次の午前2時のプロジェクトの秋と朝までの作業能力の回復の後、これがこれ以上継続できないことが明らかになりました。 そして、これは図の右側に関する話です。
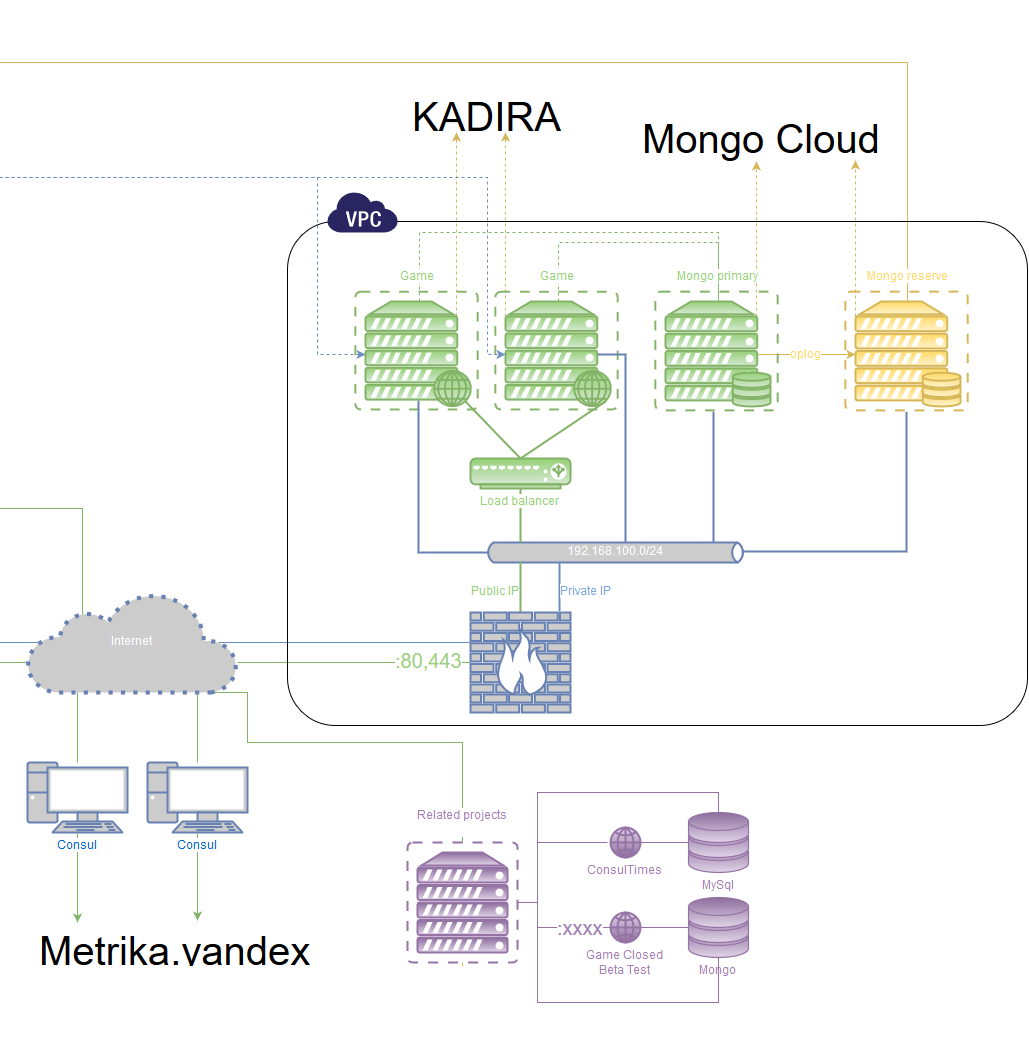
安定した建築計画
何が起こっても、あなたが平和に眠り、何らかの理由でプロジェクトが突然利用できなくなる心配がなく、穏やかな環境で急いで修理できるようにしたかったのです。 途中で、無料の水平スケーリングの可能性を追加したかったのです。
古典的なレシピは、異なるサーバーでアプリケーションの複数のインスタンスを実行し、より高いレベルでユーザーを作業に誘導することです。 同期ポイントはデータベースであるため、アプリケーション自体と同等の安定性が必要です。
1)データベース: MongoDB
少なくとも2つの異なる物理サーバーで実行されます。 1つはプライマリ、残りはセカンダリです。
なぜなら データベースとアプリケーションはさまざまなサーバーで実行され、任意のアクセス不能になる可能性があります;通信を復元するときは、完全に正しいデータ同期を達成する必要があります。 このため、MongoDBには特別なメカニズムがあります。サーバーをメインサーバーとして選択するには、少なくとも50%+ 1台のサーバーの接続が必要です。 また、アプリケーション用のサーバーがこの投票に参加するようにします-最初は2つのサーバーのみがデータベース用に計画されているという事実のため(50%+ 2の1は同じ2つです。つまり、投票には不十分です)。 このため、MongoDBには、データ自体なしでデータベースインスタンスを起動する特別な方法がありますが、これは投票モード( Arbiter )でのみです。 アプリケーションがインストールされている各サーバーに、このアービターが追加インストールされます。
追加のArbiterは、データセンターの外部にあるバックアップサーバーで実行されます。
合計で、2つのオンラインのデータベースサーバーと5つの調停者がいます(データベースサーバーも1つです)。
これで、データベースのどのインスタンスが落ちても、もう一方がメインのインスタンスになり、落ちたものは通信が復元されるまで読み取り専用になります。 通信の復元と完全な同期の後、再びメインになります。 何らかの理由で2番目のサーバーとバックアップサーバーが機能しなくなると、すべてのデータベースが読み取り専用モードになります。
監視も必要です(クラスターの状態を監視する):利用可能であること、データが配置されていること、バックアップが適切であることなど。
2)アプリケーション、 Nodejs
前のものと同様に、少なくとも2つの異なる物理サーバーがあります。 すべてのアプリケーションはピアです。 同期ポイントはデータです。
これは達成できる、なぜなら アプリケーション自体は状態を保存しないため、1人のユーザーが別のインスタンスに参加しても、これは何にも影響しません。
各サーバーには、 pm2およびnginxを使用して監視およびバランス調整されるアプリケーションの少なくとも2つのインスタンスがあります。
その上にヘルスモニタリングがあります。
サーバー/データセンターの選択
選択する前に、アプリケーションが消費するリソースの数を判断する必要があります。
なぜなら Meteorを使用する場合 、負荷テストの選択はMeteorDownで決まりました 。 ホームサーバーを確認し、アプリケーションに100%のリソースを割り当てます。
サーバー:Intel®Xeon®CPU E5-1620 v2 @ 3.70GHz(6コア)、32GB ECC DRR3メモリー。
彼は自分自身をテストします、すなわち ネットワークは考慮されません。 はい、これはすべて歪みを与えますが、許容範囲です。
ユーザーの行動のスクリプトが記述され、データセットが生成されます。 発射! 負荷は徐々に増加していますが、同時にメソッドへの応答時間は安定しています。 千オンライン、2、3、5、6。 徐々に、応答時間が長くなり始めます。 7-応答時間が0.5秒を超えています。 8-応答時間が許容できないほど長くなります(10秒以上)。 CPUにぶつかりました。
6000-オンラインのピークの10倍でした。 これは、2〜4倍小さいパラメーターに焦点を合わせながら、スケーリングを行うことを意味します。
1)クローズドベータテストの終了
ベータテスト中、登録はそれぞれ制限され、オンラインでも行われました。 上記のアーキテクチャはプロジェクトにさえありませんでした。 この時点まで、すべてが非常に安定していた。 現時点では、アプリケーション全体が同じKVM VPS 'ke(4コア2.2GHz、4GBのメモリ)で実行されていました。
ベータの開始までに、同様の特性のために2倍半のコストで「フォールトトレラントサーバー」に(一緒に)移動することが決定されましたが、すべてが非常に安定していてクールであるという保証の束のようです。
オープンベータテストの開始に伴い、支払いの受け入れが開始されたため、義務が増加し、ダウンタイムを許容できなくなりました。
2)MBT
打ち上げは非常に成功し、すべてがうまくいくように見えました。 突然、数週間後、午後に友人から電話があり、サイトが利用できないと報告されました。 OK、家に帰ります。 私はVPSが言葉からすべてであることがわかります。 再起動しようとしています-失敗しました。 私はテクニカルサポートを書いています-彼らは私に答えます:ディスクがクラッシュし、数時間で回復します。
STA? 「フォールトトレラントサーバー」のくだらない説明で、サーバーとストレージが別々に配置され、すべてがそこに複製され、100%の可用性があることを確認しました。
私はこれらの点を明確にし、彼らは30ルーブルを(ta da-da)補償することを教えてくれます! 6時間のダウンタイム。 素晴らしい。
さて、私は本当に運が足りず、いくつかの異常な出来事が起こったと仮定します。 私はそのような出来事の頻度と将来の発生の可能性を明確にします-彼らはすべてがうまくいくことを保証します。 2日後-午前4時の落下 ディスクはクラッシュしましたが、今回はデータの損失も伴います:-)
3)最初の動き
バックアップのおかげで、損失は24時間であり(その時点では1日1回バックアップがありました)、取引履歴により、パートナーが支払いを復元することは難しくありませんでした。 私は緊急に代替案を探しています。 私は見つけ、支払い、移動します。
3週間後、 状況はほぼ同じです。 うん 私にとって非常に重要な状況でした。
4)Tier 3、 DataLine
私はこのトピックをより深く研究します。大人の叔父はそのような問題をどのように解決しますか? 私は感じています、そして私たちは成長する時が来ました。
私は上記のスキームに取り組んでおり、最も信頼できるホスティング業者を探しており、 ロシア連邦での選択はそれほど大きくないという結論に達しました。 CloudLiteの簡易バージョンを備えたDataLineを除き、小さなプロジェクトでの作業に関心のある大企業はほとんどありません。
テスト期間のサポートに同意し、意図したとおりにすべてを展開します。 ドメインを移管します。

ふう、うまくいくようだ。 しかし、どういうわけかゆっくり。 要求は約300ミリ秒で返されます 。 しかし、同時に負荷の増加はありませんでした。 安定した300msでした。
そのままにして、数日間見ることにしました。 一般に、安定性は満足しましたが、抑制は迷惑でした。
何が起こっているのかを理解し始め、すぐにボトルネックがディスクであることが明らかになりました。ユーザーアクティビティを非常に注意深く記録しており、常に記録キューがありました。 CloudLiteのフレームワーク内では、 VSANディスクのみが提供され、問題を修正するためにSSDに移動することは不可能であることが判明しました。
もう1つの方法は、既にディスク上に複製されたingoバージョンのmongoを実行することでしたが、いくつかはありましたが、mongoは、1つのサーバーで1年あたり15,000ドル(pa-ba-ba)のエンタープライズ専用のフルバージョンのin-memoryを提供します。 私の場合、特に現在のレベルの代替ソリューション(SSDへの移行)と比較すると、これは完全に不当でした。 Linuxでメモリパーティションを作成し、そこにデータベースを展開するという難しいオプションもありましたが、私はそのようなハッキングのファンではなく、このアプローチで起こりうる問題を計算することは問題でした。
一般的に、SSDに移行する必要がありました。 DataLineでは、これは契約の締結と別のプラットフォームでのみ利用可能です。
また、テスト期間も提供されました。 そこにすべてを新たに展開し、今回は後続の自動化のすべての手順を文書化しました。 繰り返されるドメインの移管...万歳! すべてが迅速かつ正常に機能します。
事後、この動きにとても満足していると言いたいです。なぜなら、 DataLineによる単一のダウンタイムはありませんでした(すでに8か月以上)。
DNSグリッチ(他のあらゆる種類の小さなプロジェクトがそこに住んでいたため、私はまだ最初のホストでマスターゾーンをホストしていました)が原因で1つの興味深いダウンタイムがありました。 まあつまり 古いサーバーとすべてのDNSアドレスを返すようになりました。
このエラーをキャッチするのは非常に困難でした。なぜなら それは誰かのために働いたが、誰かはそうしなかった(最初は私のために働いた)。 しかし、ルーターのDNSキャッシュをリセットすると、すべてがすぐに見えるようになりました。
その結果、ドメインはDataLineにも転送されました(これまでのところ)(問題なく)。
負荷分散
そのため、今では複数のサーバーとさらに多くのアプリケーションインスタンスがあり、最大のパフォーマンスを達成するために、それらの間でユーザーを多少なりとも均等に分散する必要があります。
タスクは、サーバーへのバランスとサーバー内のバランスの2つのステップに分かれています。
1)サーバーとのバランス
データセンターレベルで解決されます。 アプリケーションを備えたすべてのサーバーはプールに入力され、サーバー自体の選択は2つのパラメーターに従います。最初のパラメーターはCookieで、ない場合はIPハッシュです。 1人のユーザーからの要求は常に同じサーバーに送られるため、キャッシュはより効率的に機能します。

なぜなら すべてのアプリケーションサーバーが等しいため、重みは同じです。 5秒の可用性チェックを追加します。
できた
現在、ユーザーリクエストはサーバー上で十分に分散されており、サーバーの1つが使用できなくなった場合、5秒以内にユーザーが別のサーバーに転送されます。
2)サーバー内のバランス
いくつかのオプションがあります。 なぜなら pm2を使用してnodejsプロセスを開始するため、必要な数のアプリケーションインスタンスを(コアの数で) クラスターモードで起動することができます。これはノードによって既に解決されます。 このアプローチの欠点は、 スティッキーセッションメカニズムが機能しないことですが、 ソケット接続を保持するため、アプリケーションの別のインスタンスへの切り替えは、中断が発生した場合にのみ可能です。 私たちの場合、これは問題を引き起こしません。
2番目のオプションは、異なるポートでforkモードでアプリケーションを起動し、nginxを介してそれらをプロキシすることです。 ここでの利点は、nginxが静的変数とSSL証明書も配布できることです(ちなみに、SSLはまだ接続されていませんが、すぐに手が届きます)。
設定でアプリケーションポートを登録します。
3)チェック
サーバーの負荷を確認し、均等に分散されていることを確認します。 いいね!
すべてを監視
すべてのタスクと同様に、まず、収集するデータを理解しようとします。
- アプリケーションの状態、負荷、エラーなどに関するデータ。
- データベースの正常性データ、データサイズ、レプリケーション、ラグなど。
- ユーザーデータ、入力デバイス、画面解像度、リファラーなど。
- ゲーム内のアクションに関するデータ。
1) Kadira.io
第一に、残念ながら、このサービスはまもなく存在しなくなります -収益性が低いことが判明しました。 しかし、開発者は、これらすべてを自宅で展開する方法に関するソースコードと情報を提供することを約束しました。 したがって、明らかに、プロジェクトのインフラストラクチャは補充を待っています。
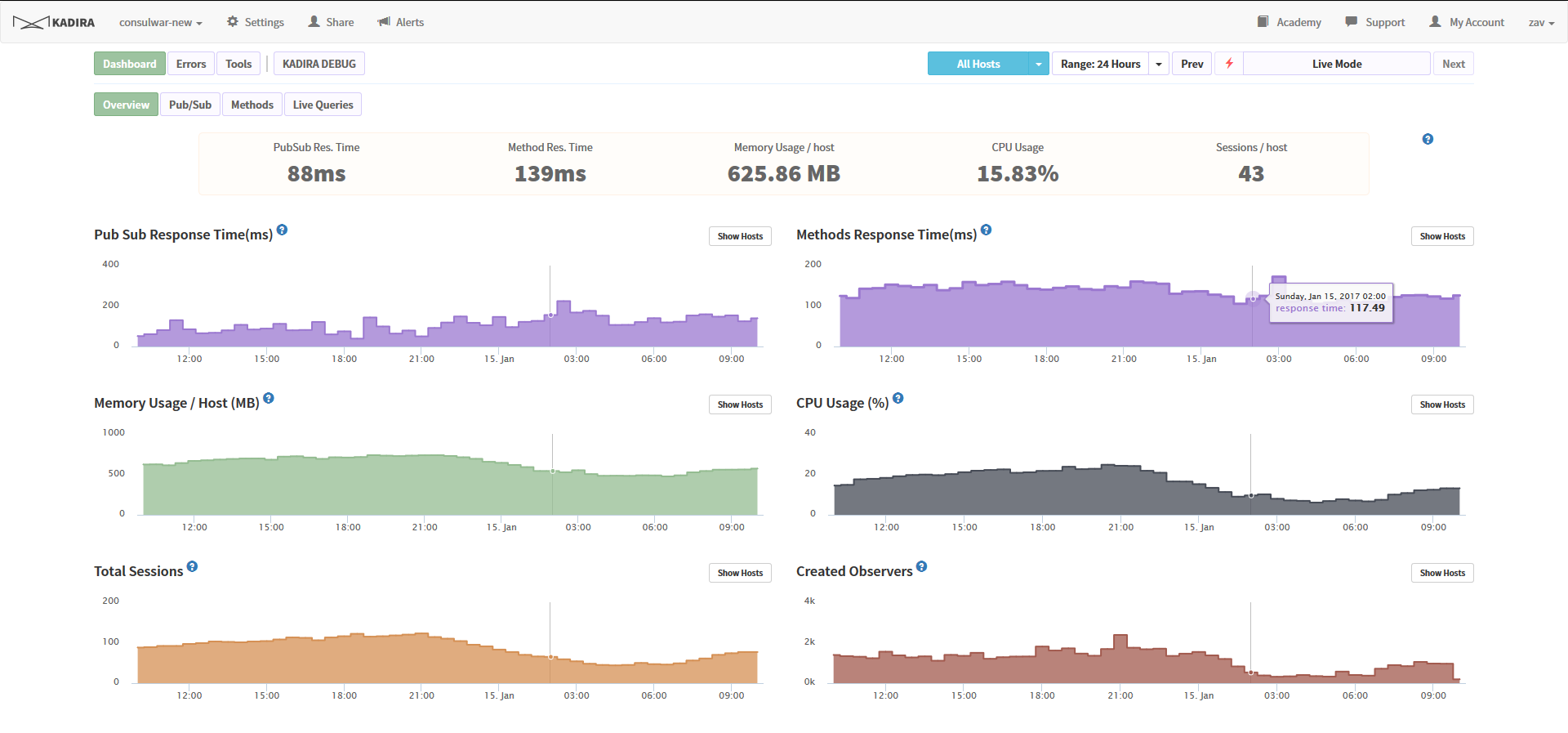
すぐに使えるすばらしいツールがあれば、車輪を再発明する必要はありません。 アプリケーションとの統合は、パッケージからモジュールをインストールし、構成に2行を記述するだけです。 出力では、リソースの監視、大量の要求のプロファイリング、現在のアクティビティの監視、エラーアナライザー、その他多数のものを取得します。
2) MongoDBクラウド
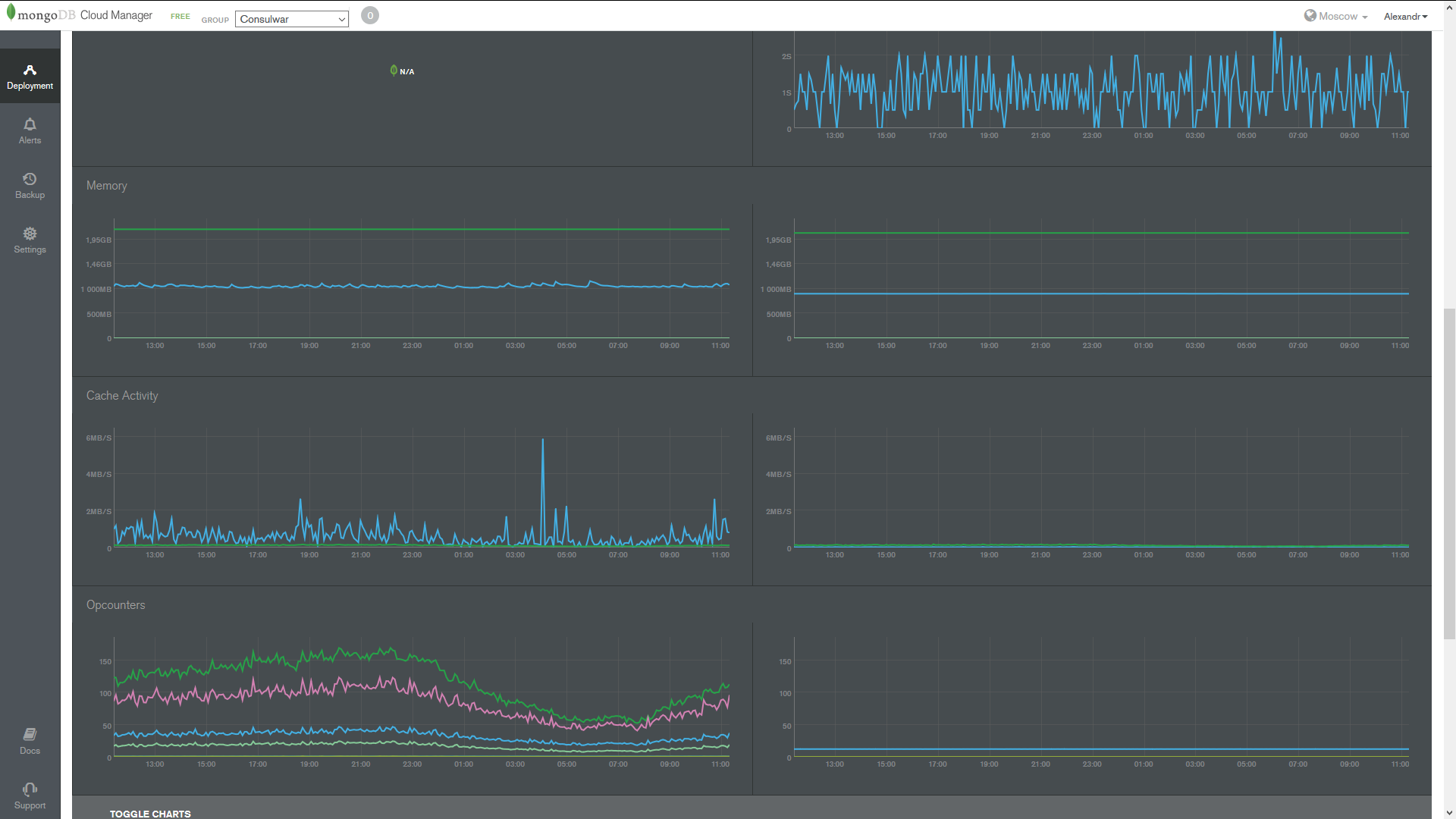
統合はそれほど複雑ではありませんが、それぞれアプリケーションではなくデータベースサーバーに配置されます。 モジュールを配置し、ウォッチャーを実行します。
すぐにデータベースサーバーリソースを監視し、リクエストの時間、レプリケーションの遅延、データベースを更新するためのヒントを確認します。
ここで非常にクールなことは、データベースがメールで利用できない場合に即座に通知することです。
3) Yandexメトリック
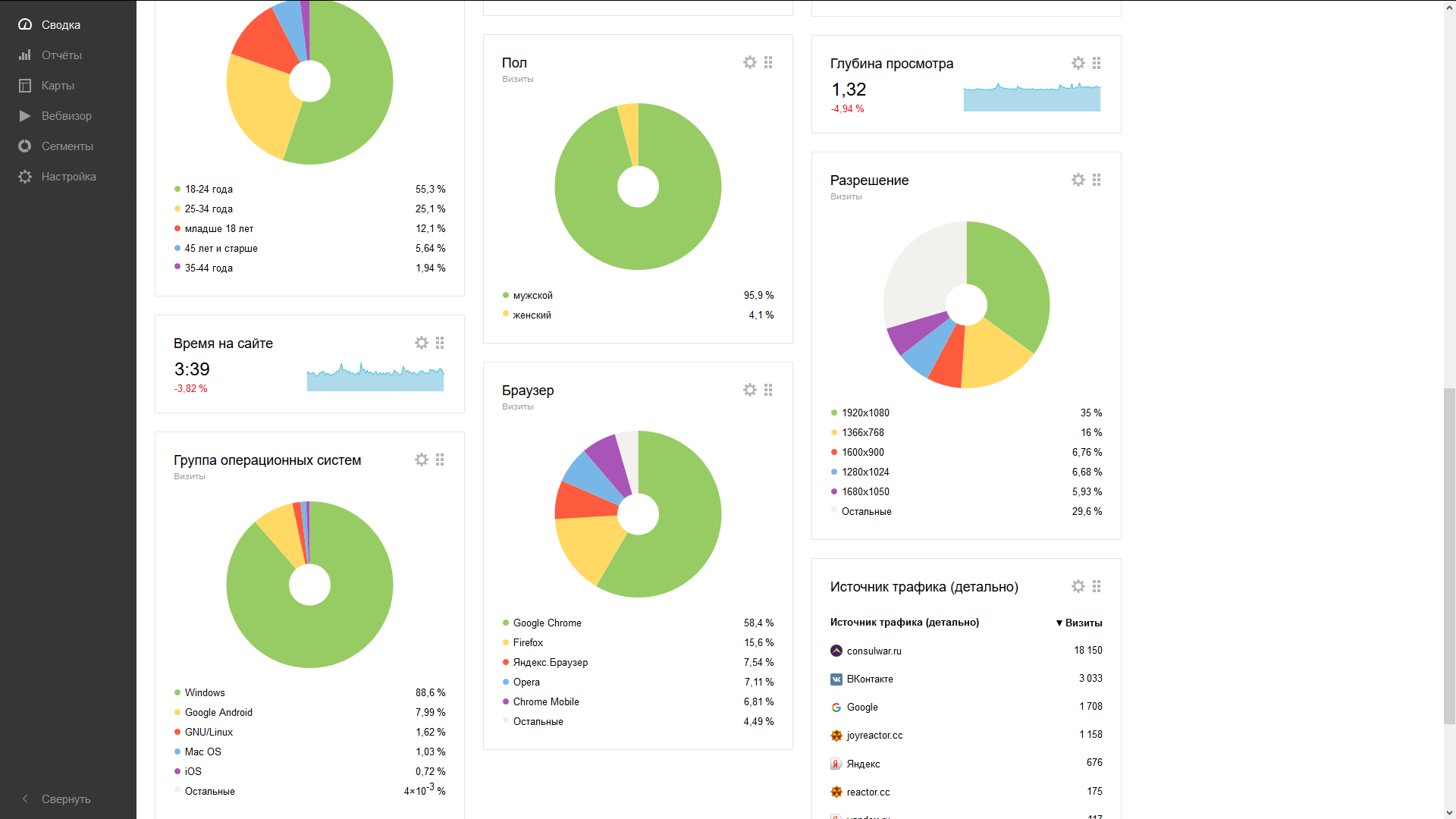
統合は、Kadiraよりも少し複雑です。 モジュールのインストールに加えて、ページの遷移についてメトリックスクリプトに通知するようにアプリケーションを変更する必要があります( SPAでは、どのモニターをモニターする必要があるかが常に明らかではないため、そのようにしたのです)。 目的のコードをルーターに追加すると、性別、年齢、遷移、訪問、デバイスなどの作業が完了します。 一箇所にすべて。 便利に!
4)ゲーム内のアクション
もちろん、それらはアプリケーションデータベースに書き込まれます。 その後、分析にのみ必要な古いデータを別のサーバーに転送するように構成できます。 このため、モンガにはツールもあります 。
リンクされたプロジェクト-別のサーバー
時間が経つにつれて、プロジェクトはさまざまな追加を取得します。 たとえば、ユーザー自身が作成した新聞がありました。 当初は、プレイヤーの1人によって作成され、どこかでホストされていましたが、その後突然閉じられ、プレイヤーは姿を消しました。 ワードプレスにアナログを展開し、モデレーターがゲームに近いトピックに関する記事を公開できるようにすることが決定されました。

もちろん、少なくともセキュリティ上の理由から、これを既存のサーバーで実行することはできません。
マイナーサーバー、より安価なプロバイダーとの混在が決定されました。 それらの可用性は重要ではありません。
とにかく、データセンターのギャラリー3を撮影するためにキャパシティを借りたホスティング業者が選ばれました。
サポートサービスの選択
エラー情報を収集するには、公共の場所も必要です。 最良の選択肢は、プレイヤーから提案を収集し、それらに投票する可能性でした。 かなりオプション-変更ログをすぐに公開します。 中小企業または任意の制限までの無料配置の可能性は非常に望ましいものでした。
私は約30個のシステムを試して、最終的にヘルプレースに落ち着きました。
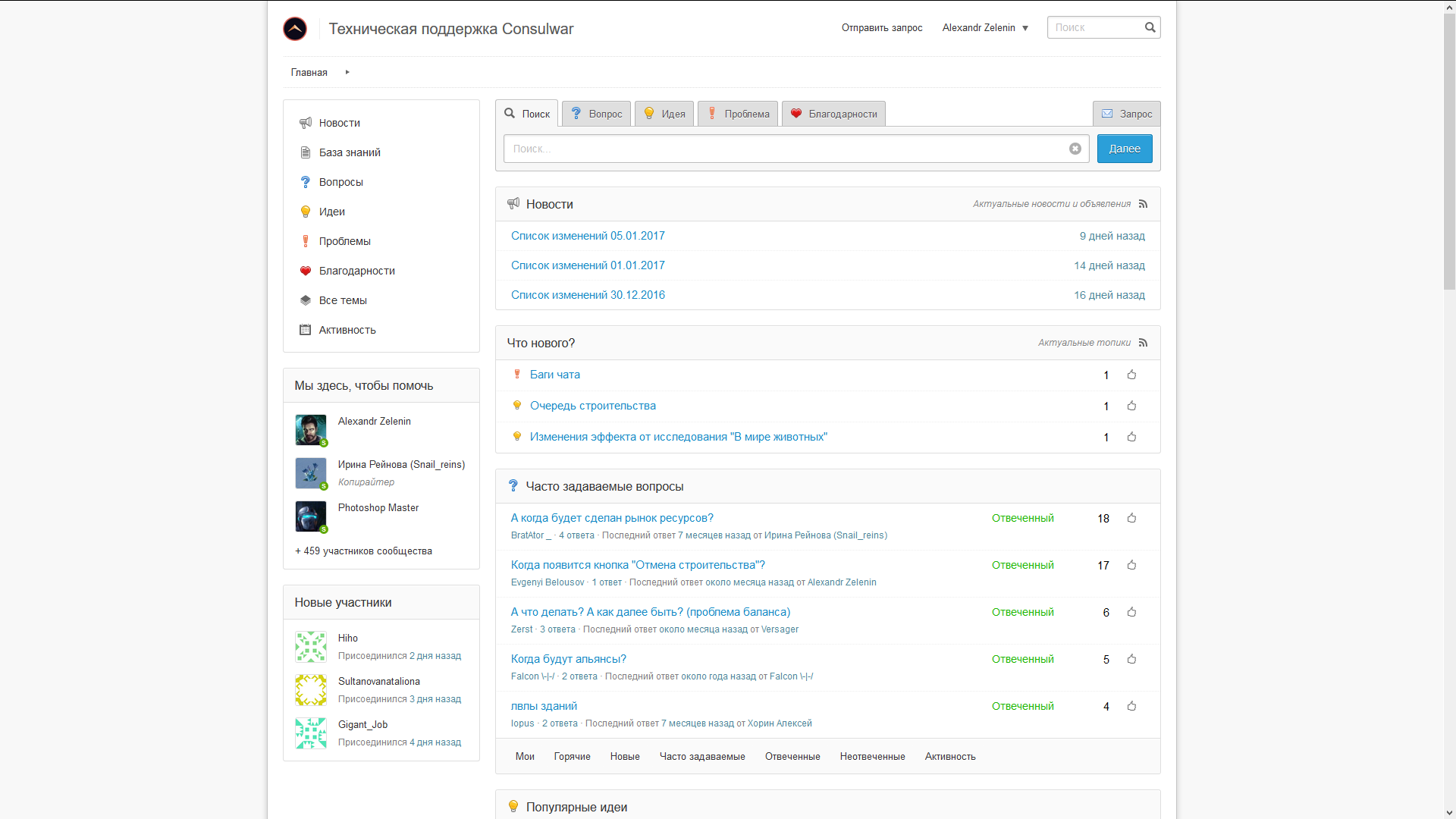
要求があったかのように直接。 通常、外部ログインとの統合がありますが、有料版のみです。 なぜなら 目標の1つは、メンテナンスコストを節約することでした。システムへの登録には別途必要です。
聴衆は常に何百ものエラーメッセージ、山ほどの提案や願いを喜んでいます。 時々、ゲームや開発者への控えめな賞賛さえすり抜けます:-)
心配をやめて開発を始める方法
そして、これはスキームの左側についての話です。
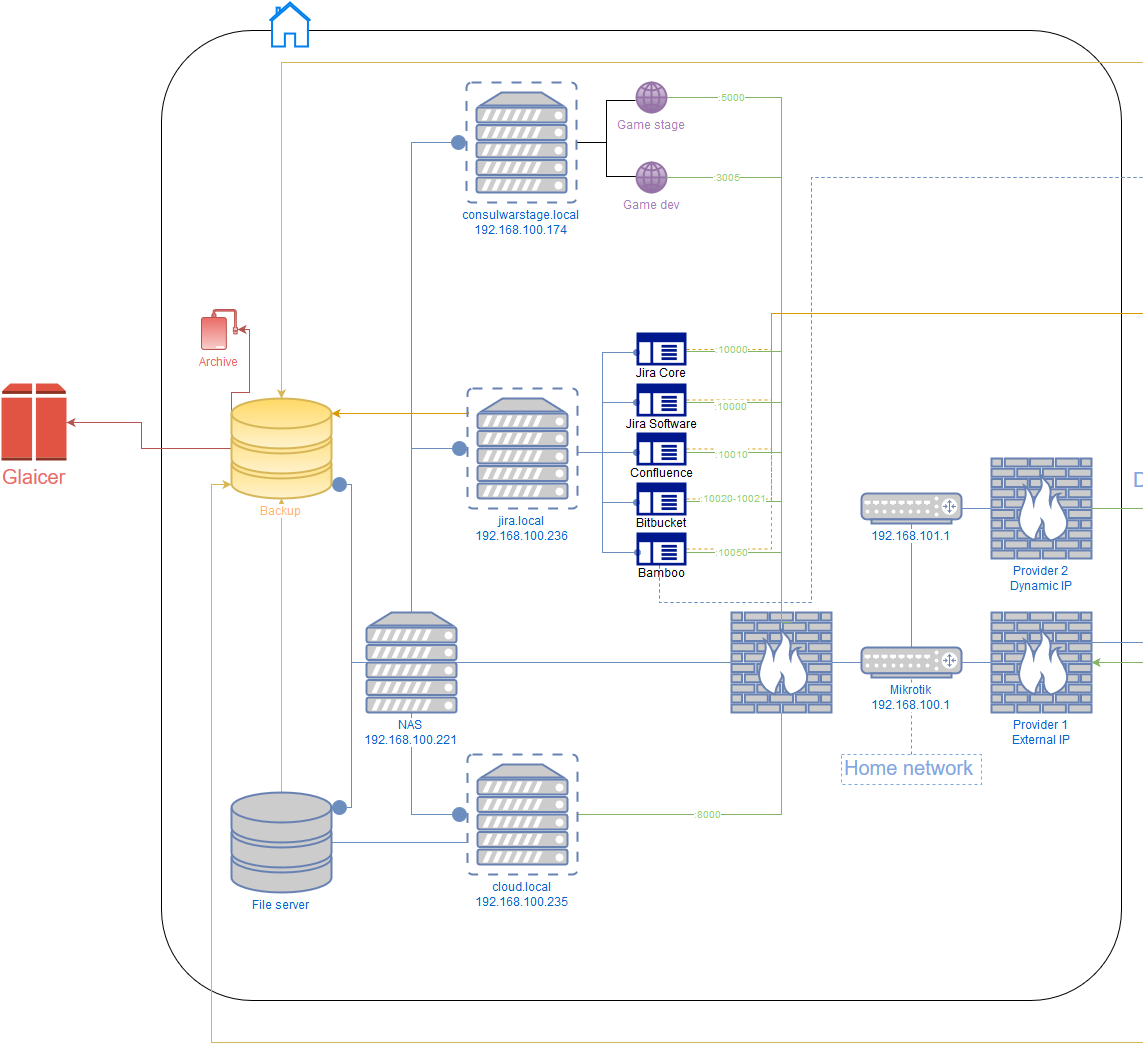
写真を保存する場所は?
この記事のフレームワークで少し奇妙な見出しですが、ホームサーバーの出現を伴うのはこの質問でした。
インドへの旅行の前に、悪魔は最終日に私を引き寄せ、公認センターでキヤノンD350のマトリックスを掃除しました。 そこに、汚い性交を持つ「マスター」がゴミ箱の中のマトリックスをひっかきました。 飛行機まで8時間もかからなかったので、分解する時間はありませんでした。何かを決める必要があります。 レビューによると、彼らは駅で良い点を見つけ、そこに到着し、それをマスターに渡しました(失うものは何もありません)。 「マトリックスに何が起きたのか:-)」と尋ねられた男たちは、ねじれた。..なんとなくトリッキーに掃除し、受け入れられるように思えた(インドの写真はこのカメラで撮影された)。
しかし、家に到着すると、私は少し撃ち始めました。なぜなら 写真内のあらゆる種類の不快なスポットは、非常に成功したショットによって台無しにさえされました。
新しいカメラを撮影する時が来ましたが、 まもなく真剣に-FullFrameになります。 まず、Nikon D800が選択されました。 37メガピクセル...お母さん、 生の重さはどれくらいですか? 50-100メガバイト! (最後に、私はD750をより快適な重量のraw'okで取りました。)
私はアーカイブを保存するのが好きで(重複と完全に失敗したフレームのみを削除する)、時間が経つにつれて、ほんの少しのホームコンピューターが明らかになりました。 その重みで、テラバイトあたり12,000枚の写真になります。 これはたくさんあるように思えますが、実際には、数年あまりアクティブに撮影されていません。 理解のために-過去数年間で、アーカイブは5万枚の写真を超えました。 そして、はい、時々いくつかのタスクのために私は正しいものを見つけるために私の写真のアーカイブに戻ります。
少しグーグルで、私はNASがこれのためだけに発明されたことに気付きました。 それから私はZFSに出会い、彼が私がすでに数回経験した問題を検出するのが素晴らしいことに気付きました。

(エラー画像をダウンロードできなかったのは面白いことです。スクリーンショットを撮って切り取らなければなりませんでした。)
そのような問題を追跡することは困難です。 彼らはまだバックアップに飛ぶことができ、レイドで複製することができました。
また、NASA nifigが私の都市(カリーニングラード)で利用できなかったという事実によって救われましたが、今では状況はもう少し良くなっています。
非常に長い分析の後(一般に、ヘッダーの問題を解決するのに200時間以上かかりました)、サーバーを組み立ててそこにFreeNASを配置することにしました。

一般的に、私は長い間それをすぐに収集し、潜在的にシステムはペタバイトのストレージと半テラバイトのRAMに拡張します。 現在、12 TBのスペースと32 GBのメモリしかない。 合計コストは、既製のNASソリューション(4台のディスクから)に匹敵するか安価ですが、柔軟性と可能性ははるかに高くなっています。
ホームネットワークのセットアップ
古いdir-300ではサーバーを快適に操作できないことがすぐに明らかになりました。 たとえそれを撮って小さな写真を撮りに行き、200フレームを撮って15 GB(200 *〜75)をダンプし始めたとしても、コピープロセス自体は約20分かかります! 必要な速度を考えますか? テストから判断すると、計画されたWD Redストレージシステムのディスクは、毎秒100〜150メガバイトを出力します。これは、専用のギガビットチャネルが十分にあることを意味します。 そして、2人のユーザーが一度に? たとえば、家族の誰かが(別の物理ディスクから)HD 4kで映画を見ることにしましたか? したがって、少なくとも2つのチャネルをサーバーに送信する必要があります。
市場を分析した後、 MikroTikを採用する必要があることが明らかになりました 。 選択はCRS109-8G-1S-2HnDで決まりました-8つのギガビットポートと信じられないほどの構成オプション。
アクセス継続性
プロバイダー(Hello、Beeline!)のせいでネットワークにアクセスできなくなって、仕事をする機会を奪われたとき、私はとても怒っていました。 (まあ、はい、まだモバイルインターネットはありますが、特にここでニフィガを捕まえず、外部アンテナの形で別のソリューションを必要とするという事実にもかかわらず、それはまったく快適な作業でさえありません。)

2つのプロバイダー、BeelineとRostelecomが入り口で働いています。 最初は、それらを個別に構成する必要があり、それから始めました。
ああ、MikrotikルーターでBeelineを接続するこれらのダンス! 私たちはなんとかタンバリンやダンスとつながりましたが、私はたくさんの神経と時間を食べました。 さらに、場合によっては手動調整が必要になります。 言葉で言うと、ルーターで常に実行されるスクリプトを使用したソリューションはまったく好きではありませんでした。 ちなみに、入り口のビーラインは、Mikrotikからのすべてを配布していますが、これは二重に驚くべきことでした。
そしてRostelecomは光ファイバーをアパートに引っ張ります(このマーケティング担当者に熊手!)。追加のルーターなしではできません。 実際、ルーターをMikrotikに接続することはまったく問題ではありませんでした。実際、これは単なるネットワークであるためです。
外部IPが追加料金で(かなり前に)Beelineから購入されました。これは、認証および内部リソースへのアクセスの手段の1つとして常に使用していました。
しかし、これが同時に機能するためには、ネットワークとパッケージに関する知識を強化する必要がありました。 多かれ少なかれ簡単なセットアップと何が起こっているのかを理解するために、フェイルオーバーを伴う帯域幅ベースの負荷分散のプレゼンテーションを読むことをお勧めします。 簡単な方法。
内部リソースへのパブリックアクセス
サーバーには、外部ネットワークから利用可能なリソースがいくつかあります。 これを達成する方法は? 上記のように、私は外部IPを持っています。 外部IPは、* .home.domain形式のユニバーサルサブドメインによって参照されます
いくつかのロールアウトオプションがあります: レイヤー7またはポート別。
最初に、ルーターのレイヤー7を使用してセットアップし、アスタリスクの背後にあるものを確認し、必要な場所を指示しましたが、そのような使用はルータープロセッサに非常に大きな負荷をかけることがすぐに明らかになりました。 リソースが少数の人々によってのみ使用されることを考えると、より安価なポートアドレッシングを使用することが決定されました。
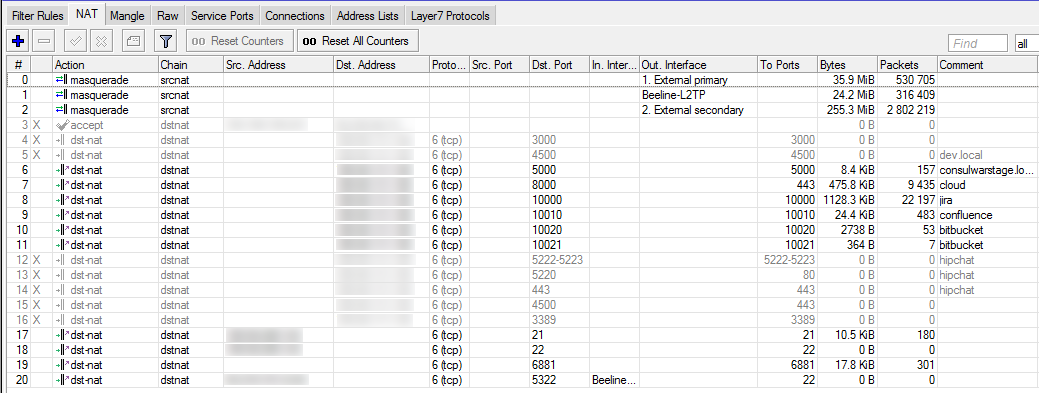
外部IP上の特定のポートへの接続を許可するルールをファイアウォールに記述し、 NATの内部IPとポートを使用して接続ルールを追加します ...動作します! (ちなみに、2つの接続が機能している場合、応答は要求と同じプロバイダーを経由する必要があります。これはスティッキー接続と呼ばれ、同じプレゼンテーションで説明されています。)
フルアクセス
私たちがしばらく別の国に去るとします。 ネットワーク内にいるかのように、フルアクセスを取得する方法は? もちろん、 VPNが必要です。
ルーターで、VPNサーバーを起動し、 ブリッジに追加し、ユーザーを作成します-それだけです。 追加のソフトウェアなしで、接続が作成されます。
バックアップおよびアーカイブ戦略
保存された情報の価値を共有することから始めましょう。 3つのグラデーションを区別します。
1) (, ).
2) , ().
3) , ( , ).
4 : (media), (photo), (work), (backup).
:
work media.
backup .
photo , backup 50%. jpg . , .
media , .. .
:
jail , read-only backup. Amazon Glaicer work , jpg' .
:
, . — . つまり . , , .
? , . 5 : , , .
, .. , .
dropbox
, . , — . Owncloud — .
jail . jail -. owncloud .
. . .
仮想マシン
, , .
Virtualbox — . , .. jail phpvirtualbox FreeNAS.
virtualbox , freenas, , .
, , , . git , nodejs , . , , . ? , — , .
Docker , - . , , : « Docker, — », , , . — , - , 1 :-)
Jira — Confluence — Bitbucket — Bamboo
RealtimeBoard , . .
GitLab , . - , .
, Jira - , . , 10 10$. 60$ .
ジラ
, — «».
20 .
— « ». , , «»:

1) -, «».
2) 6 : , , , , ( ), .
3) : , , .
4) . : (, ), , , , , post-. 10 .
5) : , , , — (, ).
6) , (, ).
7) . , « dev» bitbucket, , , dev. « » pull request' bitbucket' .
8) — «».
9) «» .
10) -, , « ».
11) - «» - «».
12)…
13) ???
999) Profit!
. :-) , , . , .
Confluence
. , Jira, .
, Jira. . , Jira . !
.
Bitbucket
Git , .
, Jira, .
protected master dev. force , 1 . . , .
Bamboo
Gitlab CI , Jira — .
, , , , , .
, 1 , .
: , dev stage , master , , , , . :)
Slack
Slack , .. .
. , , — . , . , → . 便利に。 ? .
, , - .
結果は何ですか?
その結果、あなたは平和に眠ることができます、なぜなら さまざまな予期しない状況の場合、すべての重要なシステムが動作し続け、完全に理解できない何かが発生した場合、少なくともすべての失われたデータを回復する機会が常にあります。
信頼できるネットワークストレージがあります。ユーザーは、安定性と速度に満足しています。システムのすべてのノードで何が起こっているかを知っており、それらを独立して改善できます。
必要に応じて、サーバーを数回クリックするだけで簡単に容量を増やすことができます。
ユーザーのリクエスト(エラー、アイデア、提案、質問)に対応し、何も失われたり忘れられたりしないようにします。作業のペースを確認し、正しく計画することができます。開発プロセスは、生きている人を含め、コードが数回チェックされるように設計されています。
新しいチームメンバーを紹介し、落ち着いてもらえます。彼らの行動は何も壊しません。
そして、ゲームはどうですか?
そして、ゲームはまだオープンベータ段階にあり、ゲームプレイ自体は現在の計画からはほど遠いですが、私たちはそれらに向かって動いています。 何が出るか、私たちは本当に好きです。 プレイヤーもそう願っています:)現在、アクティブな再設計が進行中です。これは、一部の画面が少し進んだ理由ですが、他のものは以前のものよりもはるかに優れています。

正直なところ、非常に小さなレビュー記事になると思いましたが、このようになりました。
私は繰り返します-絶対に各ポイントは、同様のボリュームの記事(またはサイクル)に値します。
時間と適切なムードが現れ次第、すべてを手配します。 私はいくつかの不正確さをおaびします-多くのことはメモリから書き込まれましたが、多くの時間が経過しました。 詳細な記事の準備では、すでに正確さがあります:)
まあ、最後まで読んだら、あなたは-よくやった。 それをありがとう 。