パート2。データセンターのエネルギー供給の監視はどうですか。
パート3. NORD-4データセンターの例を使用した冷凍供給の監視。
パート4.ネットワークインフラストラクチャ:物理的な機器。
9月にデータセンターの監視デバイスに関する記事を約束しました 。 このトピックは広範であり、1つの記事でそれを取り除くことはできないため、一連の投稿を行うことにしました。 監視を設計および構成するときに覚えておくべき重要な基本ポイントから始めましょう。 次に、主要なエンジニアリングシステム(電源とコールドサプライ)について詳しく説明し、それらを監視するためのツールについて説明します。
記事では、私たちの経験、私たちが自分のデータセンターで試し、使用したことを共有します。 私たちは完全であるふりをしませんが、すべては教科書からではなく、人生からのものです。
コメントでは、編集方針に影響を与えて、特に関心のある監視の側面を検討のために提供することができます。

組織の問題を整理し、DataLineエディションでアルファベットの監視を始めましょう:)。 したがって、今日は、監視システムの設計、実装、および調整の段階で考慮する必要がある概念的な事項について説明します。 NagiosとCactiに基づいて構築された監視の例の主題を検討します。
監視とは何ですか?
このシリーズの記事では、「クラシック」モニタリング、つまり 自動制御なし。
監視は、さまざまな方法で解釈できます。システムとして、プロセスとして。 私たちの場合、これらは同じコインの両面です-一方が他方なしでは存在できません。
システムとしての監視は、機器とシステムのパラメーターを継続的に収集、保存、分析するのに役立ちます。 エンジニアは、観測されたオブジェクトの現在の状態と将来の動作について結論を下すためのデータを提供します。
監視システムはバックグラウンド情報のみを提供し、それは人とプロセス次第です。 定期的および緊急事態における明確な規制、責任者向けの組み込み通知システム-これらすべてにより、監視が単純なデータ収集からインフラストラクチャ管理に役立つツールに変わります。
監視システムに困惑する必要がある場合
次に、エンジニアリングインフラストラクチャの設計を開始します。 データセンターの立ち上げ後に監視を行うと、しばらくの間運用サービスが盲目的に機能します。 勤務中のエンジニアは、機器の操作のエラーを追跡することはできず、緊急事態前の状況を逃します。 この状況で利用できる唯一の監視方法は、すべてのエンジニアリングシステムとIT機器の物理的なツアーです。
例1:データセンターが稼働しました。 最初の数か月間、ホールはほとんど空で、3つのエアコンのうち1つだけが作動していました。 部屋がいっぱいになると、部屋の温度が上がりました。 監視がないため、運用サービスが2番目のサービス、および事故の場合はバックアップサービスをいつオンにするかを判断することは困難です。
サーバーまたはデータセンターの運用を中断せずに、運用段階で監視することでギャップを埋めることは困難であり、時には不可能です。 たとえば、現在のアナライザーを配電盤に設置するには、少なくとも1つのビームをオフにする必要があります。 最悪の場合、それらのスペースがなくなる可能性があるため、完全に新しいキャビネットを近代化または完全に変更する必要があります。
良い表現があります。測定できないものを制御することは不可能です。 これは、監視を行わないエンジニアリングインフラストラクチャの運用に関するものです。 事前に監視を検討してください。
あなたが従う必要があるもの
エンジニアリングインフラストラクチャの監視は、可能であれば3つのレベルで実行する必要があります。自律型センサー、機器、システム全般です。
自律センサーとは、主に漏れセンサー、温度センサー、音量センサー、モーションセンサーを意味します。
- 特にデータセンターが液体冷却剤または加湿機能付きフレオンを使用した冷却システムを使用している場合、漏れセンサーが常に必要です。 各エアコン、ユニット、パイプラインタップの下、つまり、注入できる場所に配置します。
- 機械室の冷気と熱気の回廊、エンジニアリングインフラストラクチャがある部屋(ポンプ室、バッテリー室、メインスイッチボードなど)に温度センサーを設置します。
- ボリューム/モーションセンサー、ラックドアの開閉。 前のものとは異なり、それらはオプションです。 それらは、ホールで、またはフェンスで囲まれたラックのグループ(ケージ)で使用できます。
可能な場合は機器を監視する必要があります。すべて:UPS、DGU、エアコン、PDU、ABP、カメラなど。それぞれについて、次の情報を取得することが重要です。
- 動作しますか。
- 作業で発生するエラー。
- 個々のパラメーターの値(UPSの電圧、電流、ディーゼル発電機のタンク内の燃料レベル、エアコンの入口と出口の温度、ファン速度など)。
各機器を個別に追跡するだけでは不十分です。 システム全体を追跡して、全体像を理解します。 したがって、単一のチェーン内の機器の関係を確認でき、どの段階で誤動作が発生したかを理解しやすくなります。 システム内の機器の関係は、回路図を使用して視覚化できます。
例2:エンジンルームの配電盤が切断されています。 機器を個別に監視する場合、障害の原因(電源が供給されているシールドまたはUPS)を理解するのに時間がかかります。 目の前にシステム全体の図があれば、弱いリンクがすぐにわかります。

単一のチェーン内のすべての機器を示す電源システムの図。
モニタリング文書
オブジェクトと監視パラメータを決定するときに、システムのドキュメントを作成します。 その中で修正します:
- 監視対象のセンサーと機器のリスト。
- 設置場所;
- 監視されるパラメータと特定の値。
- 接続スキーム。
- アラーム通知のしきい値
また、これは設計段階で行うのが最適です。したがって、オペレーティングサービスには最初から完全なドキュメントがあり、次のことを理解しています。
- 関心のあるオブジェクトはすべて監視されていますか?
- 監視システム自体の故障の場合に問題を探す場所。
- 使用されるしきい値。
このようなチートシートがないと、運用サービスは監視システムを再度調査する必要があります。
システムの独立性と冗長性の監視
監視には、専用のネットワークセグメントを備えたサーバーとネットワーク機器を別々に使用することをお勧めします。
サーバーの1つに障害が発生しても、2番目のサーバーで監視が継続されるように、サーバーを予約する必要があります。 クラスタサーバーが異なるマシンルームに配置されている場合、非常に便利です。 次の投稿の1つで、このようなクラスターのデバイスと動作原理を詳細に調べます。
図が表示されるモニターである通知も、予備を備えた無停電電源に接続する必要があります。 ネットワーク上でも-ネットワークソケットは異なるスイッチに接続されます。 そのため、データセンターで何か面白いことが起こっても、職務エンジニアが絶滅したスクリーンに取り残されることはありません。
単一の監視センター
センサー、機器、およびシステムからのすべての情報は、単一のインターフェースに要約され、監視センターの画面に選択的に表示される必要があります。
勤務中の少なくとも1人のエンジニアが、この農場全体を24時間監視する必要があります。 ここでは、すべての通知は、責任者または部門に関するインシデントの形式で記録されます。
これは一種のMCCであり、データセンターでの事故発生時の最初の防衛線です。

OSTサイトの監視センター。
各専門部門では、さらに、この部門の責任範囲の一部である図とアラートを含む画面をハングさせることができます:運用エンジニア-1つの画面、ネットワーク担当者-その他。
可視化
通知の助けを借りてのみデータセンターの作業を監視することは可能ですが、明確にするために、主要なエンジニアリングシステムとそのパラメーターは、ダイアグラムとマップの形で視覚化する必要があります。

データセンターOST-2の概要図。
サーキットを使用すれば、勤務中のエンジニアは、壊れたエアコンがどのエンジンルームにあるか、最も近いコールドコリドーの温度がどうなるかを理解しやすくなります。 さらに、視覚化により、エンジニアリングシステムの個々の要素間の関係を確認し、問題の原因をすばやく特定できます。
システムごとに異なるポーリング時間
ポーリング時間を設定するときは、エンジニアリングシステムの詳細を考慮してください。 電源システムの場合、測定値が多いほど良いです。 たとえば、監視では、電圧値は毎秒取得されます。 エアコンの場合、これは頻繁に行われるため、1分間隔で十分です。
システムごとに異なるポーリング時間を設定します。 そのため、重要なイベントを見逃すことはなく、リクエストが頻繁にシステムに負荷をかけることもありません。
適切に選択された通知しきい値
アラートがトリガーされるまでの重要な値を書き留めます。 警告と重大なエラーの少なくとも2つのレベルのアラートを提供することをお勧めします。 たとえば、Nagiosでは、警告とクリティカルはこの分離に対応しています。
- 警告は、機器またはシステムの一部のパラメーターが臨界値に近づいていることを警告します。
- criticalは、何かが故障した場合の緊急事態、ハードウェアエラーを意味します。
通知を正しく分離すると、誤報の数が減ります。 警告とクリティカルの間に明確な線を引くことは困難ですが、理解には経験が伴います。 モニターが事故で永久に赤くなる場合、何かが正しく構成されていません。 エンジニアにとって、このような監視はすぐに情報価値がなくなり、誤ったアラームが発生し、日常のアラートの中で実際の事故に気付かれない可能性があります。
必要に応じて、さまざまな種類の通知のしきい値を調整します。
警告とアラームの例
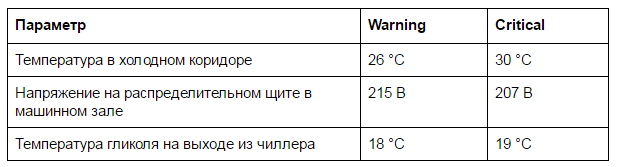
すべての事故報告は最新のものでなければなりません。 事故に関するメッセージが画面に表示されている場合、それはちょうど起こったことを意味します。 この通知が責任者のインシデントとして登録されるとすぐに、画面から消えます。
緊急時の手順を明確にする
事故を見逃さないことが重要ですが、事故に正しく対応し、事故に対する対応プロセスを開始することがさらに重要です。
勤務エンジニアは、行動するための明確な指示と、緊急の場合に通知する必要がある人々の連絡先を持つ必要があります。
エンジニアが指示の検索や解読に時間を費やす必要がないように、すべての情報は目の前にあり、明確に作成されている必要があります。
勤務エンジニアの利便性のために、各通知には、担当者の連絡先と指示を含むツールチップを添付できます。 規制は事前に規定されており、定期的なテスト中に実行可能性がチェックされます。
データセンターで事故が発生したときに、勤務中のエンジニアにゼロからアクションプランを考え出すことを強制しないでください。
電子メールとSMSアラート
適切に使用すると便利です。 小規模なサーバールームの場合、このようなアラートは24時間体制のエンジニアが代わりに使用できます。 大規模なデータセンターでは、これは勤務中の一種の予約エンジニアです。 しかし、ここでは、無理をせず、くしゃみの責任者に通知を送信しないことが重要です。
重大ではないエラー(上記では警告と呼びます)に関するアラートが多数ある場合、時間の経過とともにそれらは単に無視され、重大な事故は見過ごされます。
統計収集
オンライン監視に加えて、長期的な統計を収集すると便利です。 これにより、ダイナミクスのパラメーターを評価して、緊急事態につながる値を特定できます。 これらの統計を使用して、さまざまな負荷、さまざまな気象条件での機器の動作に関する結論を引き出すことができます。 同じ情報が、事故後のフライトの解析に使用されます。
これらはすべて、特定のエンジニアリングシステムの監視に関する話を始める前に、個別に注意したい点です。 次の記事では、データセンターとサーバーの電源システムで何をどのように監視するかを分析します。