
グラフィックレンダリングのプログラミング中、私たちは30ミリ秒のGPUフレームを実現するために低レベルの最適化が必要な世界に住んでいます。 これを行うために、さまざまな手法を使用し、パフォーマンスを改善した新しいレンダリングパス(ジオメトリ属性、テクスチャキャッシュ、エクスポートなど)、GPR圧縮、レイテンシー非表示、ROPをゼロから開発しました...
CPUパフォーマンスを向上させる分野では、さまざまなトリックが一度に使用されましたが、 ALU計算を高速化するために現代のビデオカードに使用されていることは注目に値します( AMD GCNの低レベル最適化 、 Quake逆平方根 )。
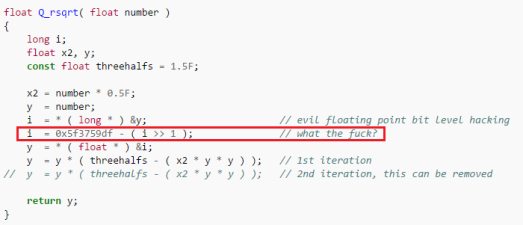
Quakeのクイック逆平方根
しかし最近、特に64ビットへの移行を考慮して、最適化されていないコードの数が増加していることに気付きました。以前に蓄積されたすべての知識が業界で急速に失われているかのようです。 はい、現代のプロセッサの高速平方根逆関数のような古いトリックは逆効果です。 しかし、プログラマーは低レベルの最適化を忘れてはならず、コンパイラーがすべての問題を解決することを期待してください。 決めないで。
この記事はハードウェアの完全なハードコアガイドではありません。 これは単なる紹介であり、リマインダーであり、CPU用の効果的なコードを記述するための一連の基本原則です。 私が追加できるプロセッサについて話している場合 でも、 「 低レベルの思考が今日でも有用であることを示したい」 。
この記事では、キャッシング、ベクトル・プログラミング、アセンブラー・コードの読み取りと理解、およびコンパイラーにとって便利なコードの作成を検討します。
なぜわざわざ?
休憩を忘れないでください
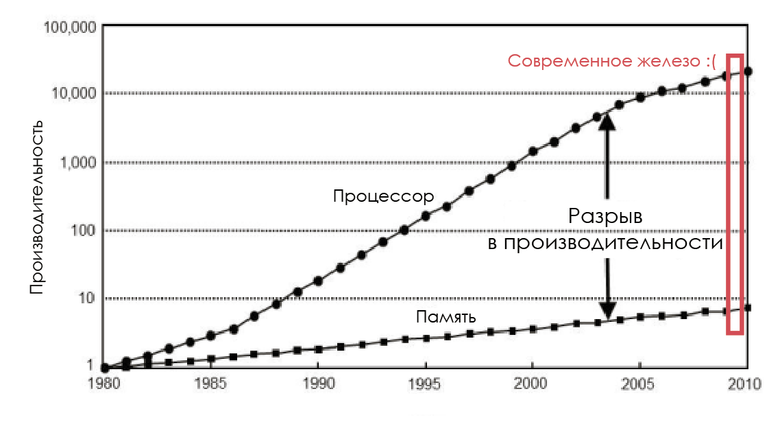
1980年代には、メモリバスの周波数はCPUの周波数と等しく、遅延はほぼゼロでした。 しかし、プロセッサのパフォーマンスはムーアの法則に従って対数的に増加し、RAMチップのパフォーマンスは不均衡に増加したため、メモリはすぐにボトルネックになりました。 そして、ポイントは、より高速なメモリを作成できないということではありません。それは可能ですが、 経済的に不利です。
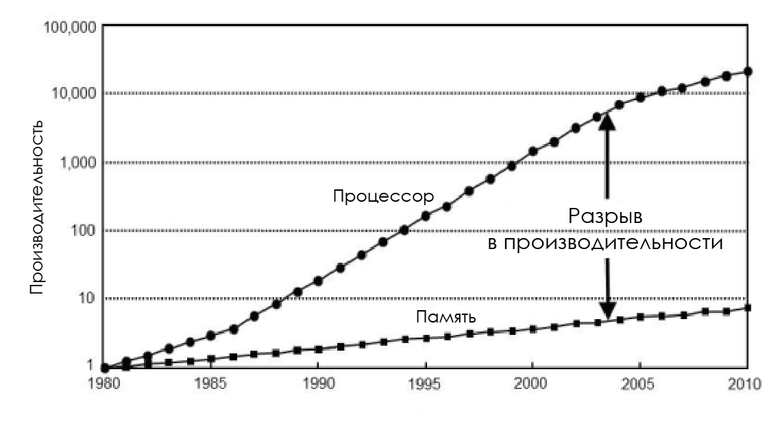
CPUとメモリの速度の変更
メモリパフォーマンスの影響を軽減するために、CPU開発者はプロセッサとメインメモリの間にこの非常に高価なメモリを少量追加しました。これがプロセッサキャッシュの表示方法です。
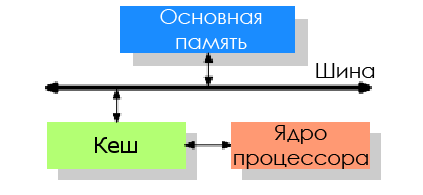
アイデアは次のとおりです。短期間に同じコードまたはデータが再び必要になる可能性が高いです。
- 空間的局所性:コード内でループするため、同じコードが繰り返し実行されます。
- 一時的なローカリティ:短時間使用されたメモリのセクションが互いに隣接していない場合でも、同じデータがすぐに再び使用される可能性が高いです。
CPUキャッシュは生産性を向上させるための複雑な手法ですが、プログラマーの助けがなければ正しく機能しません。 残念ながら、多くの開発者は、メモリ使用量とCPUキャッシュの構造のコストを認識していません。
データ指向アーキテクチャ
ゲームエンジンに興味があります。 増え続けるデータを処理し、変換してリアルタイムで表示します。 これと、効率的に問題を解決する必要性を考えると、プログラマーは自分が処理するデータを理解し、コードが機能する機器を知る必要があります。 したがって、彼はデータ指向設計(DoD)を実装する必要性を認識している必要があります。
それとも、コンパイラが私のためにそれを行うでしょうか?

シンプルな追加。 左側はC ++、右側は結果のアセンブラコードです。
AMD Jaguarプロセッサの上記の例を見てみましょう(ゲームコンソールで使用されるものと同様)(有用なリンク: AMDのJaguar Microarchitecture:メモリ階層 、 AMD Athlon 5350 APUおよびAM1プラットフォームレビュー-パフォーマンス-システムメモリ ):
- ダウンロード操作( キャッシュなしで約200サイクル)
- 実際の作業: Inc eax (1サイクル)
- ストレージ操作(〜3ループ、同じキャッシュライン)
このような単純な例でも、プロセッサの時間のほとんどはデータの待機に費やされ、より複雑なプログラムでは、プログラマーが基礎となるアーキテクチャに注意を払うまで状況は改善しません。
要するに、コンパイラは:
- 彼らは全体像を見ていないため、データがどのように編成され、どのようにアクセスされるかを予測することは非常に困難です。
- 算術演算は適切に最適化できますが、これらの演算は氷山の一角にすぎないことがあります。
コンパイラには、メモリアクセスの最適化に関して、操作の余地がかなりあります。 コンテキストはプログラマのみが知っており、どのコードを書きたいかを知っているのは彼だけです。 したがって、 情報フローの流れを理解し、最初に、最新のCPUから可能な限りすべてを圧縮するために、データ処理に進む必要があります。
残忍な真実:OOP対DoD
メモリアクセススキームのパフォーマンスへの影響(Mike Acton GDC15)
今日のオブジェクト指向プログラミング(OOP)は主要なパラダイムであり、将来のプログラマが主に研究しているものです。 実世界のオブジェクトとそれらの関係の観点から考えることができます。
クラスでは、通常、コードとデータがカプセル化されるため、オブジェクトにはすべての情報が含まれます。 構造の配列(構造の配列)および*構造/オブジェクトへの*ポインターの配列の使用を強制すると、OOPはキャッシュを使用したメモリへのアクセスの加速に基づく空間的局所性の原則に違反します。 プロセッサのパフォーマンスとメモリのギャップを覚えていますか?
過剰なカプセル化は、最新のハードウェアで作業する場合に有害です。
ソフトウェアを開発する際には、コード自体からデータ変換の理解に焦点を移す必要があり、また、現在のプログラミング文化とOOPサポーターによって課される状況に対応する必要があることを伝えたいと思います。
結論として、マイクアクトンが語った3つの大きな嘘を引用したいと思います( CppCon 2014:マイクアクトン、「データ指向設計とC ++」 )
-
ソフトウェアはプラットフォームです
- 使用するハードウェアを理解する必要があります
-
コードアーキテクチャは世界でモデル化されています。
- コードアーキテクチャはデータモデルと一致する必要があります
-
コードはデータよりも重要です
- メモリはボトルネックであり、データが最も重要なものです。
鉄を学ぶ
マイクロプロセッサーキャッシュ
プロセッサは物理的にメインメモリに直接接続されていません。 最新のプロセッサーでのRAMの操作(ロードとストレージ)はすべて、キャッシュを介して実行されます。
プロセッサが呼び出し(ロード)コマンドでビジーである場合、 メモリコントローラーはまず、読み取る必要があるメモリアドレスに対応するタグを持つエントリをキャッシュで検索します。 そのようなレコードが検出された場合、つまりキャッシュに記録された場合 、データはキャッシュから直接ロードできます。 そうでない場合- キャッシュミス -コントローラーは、より低いキャッシュレベル(たとえば、最初にL1D、次にL2、次にL3)、最後にRAMからデータを抽出しようとします。 その後、データはL1、L2、およびL3( キャッシュを含む )に保存されます。
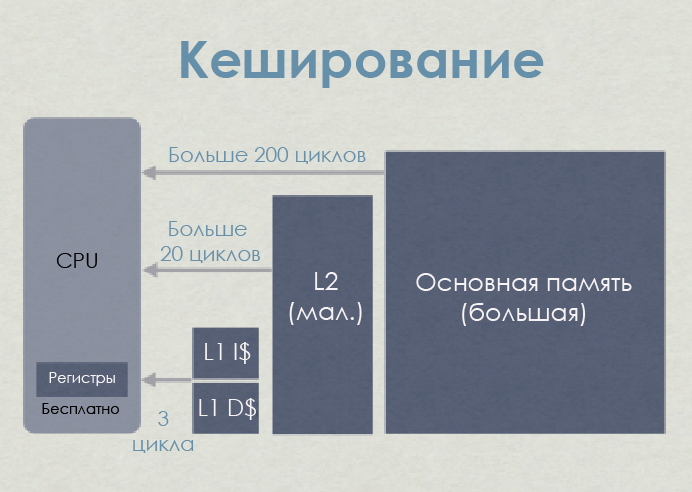
セットトップボックスのメモリレイテンシ-ジェイソングレゴリー
この簡略図では、プロセッサ(PS4およびXB1で使用されるAMD Jaguar)には、L1とL2の2つのキャッシュレベルがあります。 ご覧のとおり、データがキャッシュされるだけでなく、L1はコード命令キャッシュ(L1I)とデータキャッシュ(L1D)に分割されます。 コードとデータに必要なメモリ領域は互いに独立しています。 一般的に、L1IはL1Dよりもはるかに少ない問題を作成します。
レイテンシに関しては、L1はL2よりも桁違いに速く、メインメモリよりも10倍高速です 。 数字では悲しげに見えますが、すべてのキャッシュミスに対して全額を支払う必要はありません。 レイテンシー、スケジューリングなどを非表示にすることでコストを削減できますが、これはすでに投稿の範囲外です。

メモリアクセス遅延-Andreas Fredriksson
各キャッシュエントリ( キャッシュライン )には、いくつかの連続した単語(AMD JaguarまたはCore i7の場合は64バイト)が含まれています。 CPUが値を取得または保存する命令を実行すると、キャッシュライン全体がL1Dに渡されます。 保存する場合、書き込み先のキャッシュラインは、RAMに書き戻されるまでダーティとしてマークされます。
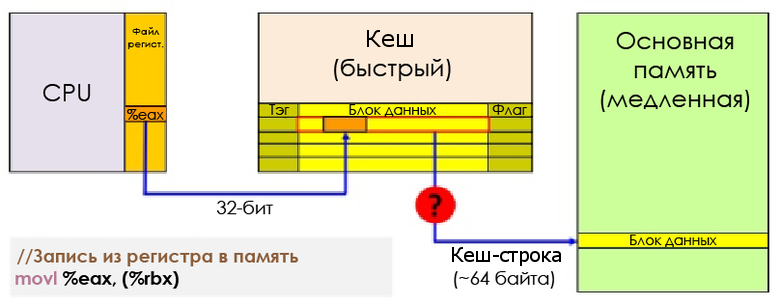
レジスタからメモリへの書き込み
キャッシュに新しいデータをロードできるようにするには、ほとんどの場合、まずキャッシュラインを削除してスペースを解放する必要があります。
- 排他的キャッシュ:取得されると、キャッシュラインはL1DからL2に移動します。 これは、L2にスペースを割り当てる必要があることを意味し、メインメモリへのデータの再転送につながる可能性があります。 取得した行をL1DからL2に運ぶと、キャッシュミスの遅延に影響します。
- 包括的キャッシュ: L1Dの各キャッシュラインはL2でも表されます。 L1Dからの抽出ははるかに高速であり、それ以上のアクションは不要です。
新しいIntelおよびAMDプロセッサは、 包括的なキャッシュを使用します。 これは最初は間違いのように思えるかもしれませんが、次の2つの利点があります。
- 取得時にキャッシュラインを別のレベルに移動する必要がないため、キャッシュミスの遅延が減少します。
- あるカーネルが別のカーネルが使用しているデータを必要とする場合、別のカーネルの動作を中断することなく、キャッシュの上位レベルから最新バージョンを抽出できます。 したがって、マルチコアアーキテクチャの開発では、包括的キャッシュが非常に一般的になりました。
キャッシュラインの衝突:複数のコアがキャッシュラインを効率的に読み取ることができますが、書き込み操作によりパフォーマンスが低下する可能性があります。 「偽共有」の概念は、異なるカーネルが同じキャッシュラインにある独立したデータを変更できることを意味します。 キャッシュコヒーレンスプロトコルによると、カーネルがキャッシュラインに書き込むと、同じメモリを参照する別のコアのラインが無効になります( キャッシュスリップ 、キャッシュトラッシング)。 その結果、各書き込み操作中にメモリロックが発生します。 誤った分離は、異なるコアを異なる行で動作させることで回避できます(余分なスペースを使用する-余分なパディング、構造を64バイトずつ揃えるなど)。

各スレッドの異なるキャッシュラインにデータを書き込むことにより、誤った分離を回避します
ご覧のとおり、ハードウェアアーキテクチャを理解することは、見過ごされる可能性のある問題を検出して修正するための鍵です。
Coreinfoはコマンドラインユーティリティです。 プロセッサにあるすべての命令セットに関する詳細情報を提供し、各論理プロセッサに割り当てられているキャッシュもレポートします。 Core i5-3570Kの例を次に示します。
*--- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64 *--- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64 *--- Unified Cache 0, Level 2, 256 KB, Assoc 8, LineSize 64 **** Unified Cache 1, Level 3, 6 MB, Assoc 12, LineSize 64 -*-- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64 -*-- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64 -*-- Unified Cache 2, Level 2, 256 KB, Assoc 8, LineSize 64 --*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64 --*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64 --*- Unified Cache 3, Level 2, 256 KB, Assoc 8, LineSize 64 ---* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64 ---* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64 ---* Unified Cache 4, Level 2, 256 KB, Assoc 8, LineSize 64
ここで、32 Kb L1キャッシュ、32 Kb L1命令キャッシュ、256 Kb L2キャッシュ、および6 Mb L3キャッシュ。 このアーキテクチャでは、L1とL2が各コアに割り当てられ、L3はすべてのコアで共有されます。
AMD Jaguar CPUの場合、各コアには専用のL1キャッシュがあり、L2は4コアのグループ-クラスター間で共有されます(JaguarにはL3はありません)。
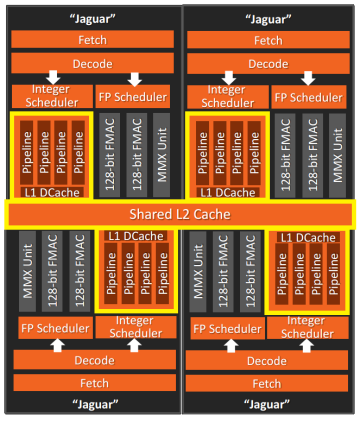
4コアクラスター(AMD Jaguar)
このようなクラスターを使用する場合は、特別な注意が必要です。 カーネルがキャッシュラインに書き込むと、他のカーネルでは無効になり、パフォーマンスが低下する場合があります。 さらに、このようなアーキテクチャでは、すべてがさらに悪化する可能性があります。カーネルによって同じクラスターにある最も近いL2からデータを抽出するには約26サイクルかかり 、L2から別のクラスターを抽出するには最大190サイクルかかります。 RAMからデータを取得するのに匹敵します!
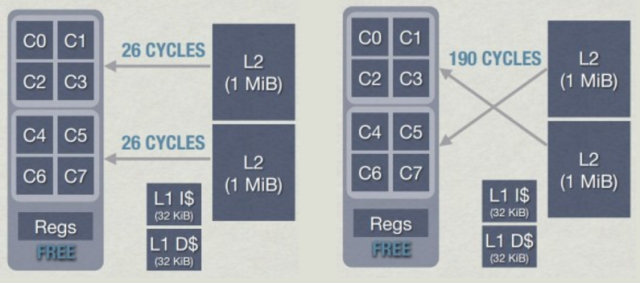
AMD JaguarのクラスターL2レイテンシー-ジェイソングレゴリー
キャッシュの一貫性の詳細については、 Cache Coherency Primerの記事を参照してください。
アセンブラーの基本
x86-64ビット、x64、IA-64、AMD64 ...またはx64アーキテクチャの誕生
IntelとAMDは、独自の64ビットアーキテクチャを開発しました:AMD64とIA-64。 IA-64は、x86アーキテクチャから何も継承していないという意味で、x86-32ビットプロセッサとは著しく異なります。 x86でのアプリケーションは、エミュレーションレベルを通じてIA-64で実行する必要があるため、このアーキテクチャではパフォーマンスが低下します。 x86との互換性がないため、IA-64は商用分野を除いて離陸しませんでした。 一方、AMDはより保守的なアーキテクチャを作成し、64ビット命令の新しいセットでx86を拡張しました。 Intel は、64ビット戦争に敗れ、同じ拡張機能をx86プロセッサに導入することを余儀なくされました。 このパートでは、x86アーキテクチャまたはAMD64とも呼ばれるx86-64ビットについて説明します。
長年にわたり、PCプログラマーはx86アセンブラーを使用して高性能コードを記述していました: mode'X ' 、CPUスキニング、衝突、ソフトウェアラスタライザー...しかし、32ビットコンピューターは徐々に64ビットコンピューターに置き換えられ、 アセンブラーコードも変更されました。
一部の処理が低速で、他の処理が高速である理由を理解するには、アセンブラーを知る必要があります。 また、組み込み関数を使用してコードの重要な部分を最適化する方法、およびソースコードレベルでのデバッグが意味をなさないときに最適化された(たとえば-O3)コードをデバッグする方法を理解するのにも役立ちます。
登録
レジスタは、ほとんどゼロのレイテンシ(通常は1プロセッササイクル)を備えた非常に高速なメモリの小さな断片です。 内部プロセッサメモリとして使用されます。 プロセッサ命令によって直接処理されたデータを保存します。
x64プロセッサには16個の汎用レジスタ(GPR)があります。 これらは特定のデータ型の保存には使用されず、実行時にはオペランドとアドレスが含まれます。
x64では、8つのx86レジスタが64ビットに拡張され、8つの新しい64ビットレジスタが追加されます。 64ビットのレジスタ名はrで始まります。 たとえば、 eax (32ビット)の64ビット拡張はraxと呼ばれます。 新しいレジスタの名前はr8からr15に変更されました。

一般的なアーキテクチャ(software.intel.com)
x64レジスタには以下が含まれます。
- 16個の64ビット汎用レジスタ(GPR)。最初の8個はrax、rbx、rcx、rdx、rbp、rsi、rdi、rspと呼ばれます。 2番目の8:r8 — r15。
- fpr浮動小数点レジスタ(x87 FPU)をカバーする8つの64ビットMMXレジスタ(MMX命令のセット)。
- 16個の128ビットベクトルXMMレジスタ(SSE命令のセット)。
新しいプロセッサの場合:
- XMMレジスターを拡張する256ビットYMMレジスター(AVX命令のセット)。
- XMMレジスターを拡張し、その数を32に増やす512ビットZMMレジスター(AVX-512命令のセット)。

ZMM、YMM、およびXMMレジスタ間の関係
歴史的な理由から、いくつかのGPRは異なる方法で呼び出されます。 たとえば、 axはレジスタAccumulator、 cx -Counter、 dx -Dataでした。 現在、 ハードウェアスタックの管理用に予約されているrsp (スタックポインター)とrbp (ベースポインター)を除き、それらのほとんどは特定の目的を失っています (ただし、 rbpはしばしば「最適化」され、GRPとして使用されます-フレームポインターを省略します) Clangで)。
x86レジスタの下位ビットには、 サブレジスタを使用してアクセスできます。 最初の8つのx86レジスタの場合、レガシー名が使用されます。 新しいレジスタ(r8 — r15)は、同じ、唯一の単純化されたアプローチを使用します。
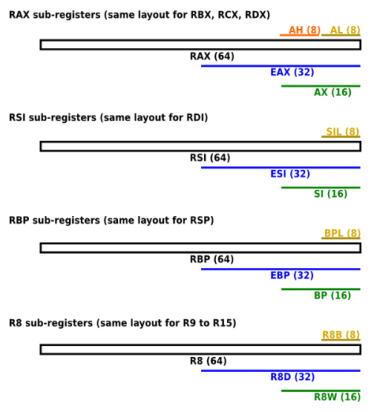
名前付きスカラーレジスタ
アドレッシング
アセンブラー命令に2つのオペランドが必要な場合、通常、最初のオペランドが宛先で、2番目のオペランドがソースです。 それぞれには、処理する必要があるデータ、またはデータのアドレスが含まれています。 3つの主なアドレッシングモードがあります。
- すぐに
- mov eax、4 ; 4をeaxに移動します
- 登録から登録へ
- mov eax、ecx ; ecxコンテンツをeaxに移動します
- 間接的:
- mov eax、[ebx] ; 4バイト(eaxサイズ)をeaxのebxアドレスに移動します
- mov byte ptr [rcx]、5 ; rcxで5 バイト移動します
- mov rdx、dword ptr [rcx + 4 * rax] ; dwordをrcx + 4 * rdxのraxアドレスに移動します
dword ptrは、サイズディレクティブと呼ばれます。 参照されるメモリ領域のサイズに不確実性がある場合、アセンブラにどのサイズをとるかを指示します(例: mov [rcx] 、5:バイトを書き込む必要がありますか?Dword?)。
これは、バイト(8ビット)、ワード(16ビット)、dword(32ビット)、qword(64ビット)、xmmword(128ビット)、ymmword(256ビット)、zmmword(512-ビット)。
SIMD命令セット
スカラー実装は、一度に1組のオペランドを持つ演算を示します。 ベクトル化は、一度に1つのデータチャンクを処理する代わりに、一度に複数のチャンクの処理を開始するときにアルゴリズムを変換するプロセスです(以下でその方法を説明します)。
最新のプロセッサは、並列データ処理のために一連のSIMD命令 (ベクトル命令)を利用できます。
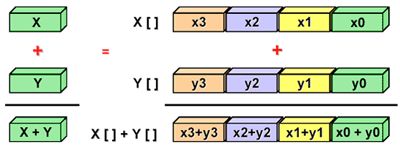
SIMD処理
x86プロセッサーで使用可能なSIMD命令セット:
- マルチメディア拡張(MMX)
- レガシー 64ビットベクトルレジスタにパックされた整数値の算術演算をサポートします。
- ストリーミングSIMD拡張機能(SSE)
- 128ビットのベクトルレジスタにパックされた浮動小数点数の算術演算。 整数と倍精度値のサポートがSSE2に追加されました。
- Advanced Vector Extensions(AVX)-x64のみ
- 256ビットのベクトルレジスタのサポートが追加されました。
- AVX-512-x64のみ
- 512ビットのベクトルレジスタのサポートが追加されました。
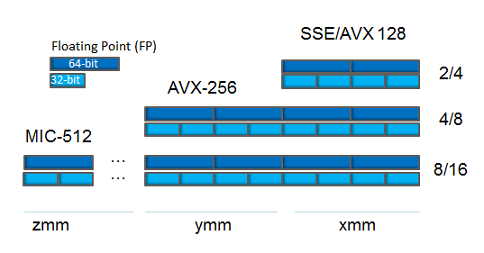
x64プロセッサのベクトルレジスタ
ゲームエンジンは通常、実行時間の90%をコードベースの小さな部分の起動に費やし、主にデータの反復と処理を行います。 このようなシナリオでは、SIMDが大きな違いを生む可能性があります。 SSE命令は通常、128ビットのベクトルレジスタにパックされた4つの浮動小数点値のセットの並列処理に使用されます。
SSEは主に、データの垂直表現(配列の構造、SoA)とその処理に焦点を当てています。 しかし、一般的に、 構造の配列(AoS)と比較したSoAのパフォーマンスは、メモリアクセスパターンに依存します。
- AoSはおそらく最も自然なオプションで、簡単に記述できます。 OOPパラダイムを満たします。
- すべてのメンバーが一緒にアクセスされる場合、 AoSのデータの局所性は向上します。
- SoAは、より多くのベクトル化機能(垂直処理)を提供します。
- SoAは、配列間でのみパディングを使用することにより、多くの場合より少ないメモリを使用します。
// Array Of Structures struct Sphere { float x; float y; float z; double r; }; Sphere* AoS; ( 8 ): ------------------------------------------------------------------ | x | y | z | r | pad | x | y | z | r | pad | x | y | z | r | pad ------------------------------------------------------------------ // Structure Of Arrays struct SoA { float* x; float* y; float* z; double* r; size_t size; }; : ------------------------------------------------------------------ | x | x | x ..| pad | y | y | y ..| pad | z | z | z ..| pad | r.. ------------------------------------------------------------------
AVXはSSEの自然な拡張です。 ベクトルレジスタのサイズは256ビットに増加します。つまり、最大8つの浮動小数点数を並列にパックおよび処理できます。 Intelプロセッサは最初に256ビットのレジスタをサポートしており、AMDに問題がある可能性があります。 ブルドーザーやジャガーなどのAMDの初期のAVXプロセッサは、256ビットの操作を128ビットのペアに分解するため、SSEと比較してレイテンシが増加します。
結論として、AVXのみ(コンピューターがIntelで実行されている場合は内部ツール用)に専念することはそれほど簡単ではなく、AMDプロセッサーはほとんどの場合、ネイティブにサポートしていません。 一方、x64プロセッサでは、SSE2にアプリオリに依存できます(これは仕様の一部です)。
異常な実行
プロセッサのプロセッサパイプラインがアウトオブオーダー(OoO)モードで実行されており、必要な入力データが利用できないために命令の実行が遅れている場合、プロセッサは入力データが準備されている後の命令を見つけようとします順番に最初に実行します。
命令の実行サイクル(命令サイクル)(または「受信-デコード-実行」サイクル)は、プロセッサがメモリから命令を受信し、実行する必要があるものを決定し、実行するプロセスです。 異常な実行モードでのコマンド実行のサイクルは次のようになります。
- 受信/デコード:命令はL1I(命令キャッシュ)から抽出されます。 次に、microoperationsまたはµopsと呼ばれる小さな操作に変換します。
- 名前の変更:レジスタとデータ間の既存の依存関係により 、実行ロックが発生する場合があります。 この問題を解決し、誤った依存関係を排除するために、プロセッサは実際の計算に使用される一連の名前のない内部レジスタを提供します。 レジスタ名の変更は、 アーキテクチャレジスタ (論理)への参照を名前のないレジスタ (物理)へのリンクに変換するプロセスです。
- リオーダーバッファ:受信済みの順序で保存されている保留中のマイクロ操作と、すでに完了しているがまだ廃棄されていないものが含まれます。
- ディスパッチング:並べ替えバッファーに格納されたマイクロ操作は、依存関係とデータの可用性を考慮して、任意の順序で並列実行モジュールに転送できます。 マイクロオペレーションの結果は、マイクロオペレーション自体とともに並べ替えバッファに書き戻されます。
- 解雇:リタイアメントユニットは、バッファ内のマイクロオペレーションのステータスを常にチェックし、実行されたマイクロオペレーションの結果をアーキテクチャレジスタ(ユーザーがアクセス可能)に書き込み、バッファからマイクロオペレーションを削除します。
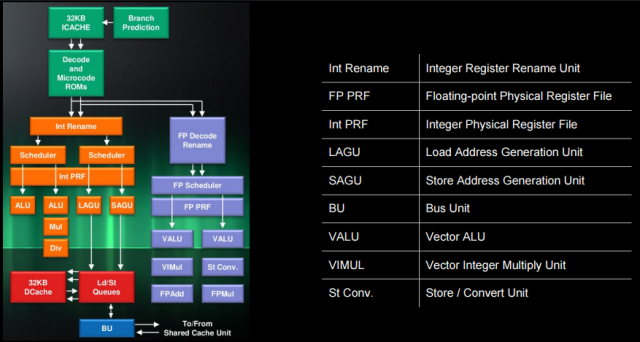
AMD Jaguarプロセッサアーキテクチャ
AMD Jaguarプロセッサアーキテクチャでは、上記のすべてのブロックを検出できます。 整数コンベアの場合:
- 「ROMのデコードとマイクロコード」
- =受信/デコードモジュール
- 「Int Rename」および「Int PRF」(物理レジスタファイル)
- =モジュールの名前変更
- ここに示されていないリタイアコントロールユニット(RCU)は、レジスタの名前変更とマイクロオペレーションの削除を制御します。
- ディスパッチャ
- 内部スケジューラ(ALU)
- 1つのマイクロ操作を異常な順序でコンベア(実行I0およびI1の2つのALUモジュール)に送信できます。
- AGU-manager(ロード/ストレージ)
- 1つのマイクロ操作を異常な順序でコンベヤー(2つのAGUモジュールの実行LAGU b SAGU)に転送できます。
- 内部スケジューラ(ALU)
マイクロオペレーションの例:
µops add reg, reg 1: add add reg, [mem] 2: load, add addpd xmm, xmm 1: addpd addpd xmm, [mem] 2: load, addpd
Agner Webサイトの指示のすばらしい表のAMD Jaguarセクションを見ると、このコードの実行パイプラインがどのように見えるかを理解できます。
mov eax, [mem1] ; 1 - load imul eax, 5 ; 2 - mul add eax, [mem2] ; 3 - load, add mov [mem3], eax ; 4 - store (Jaguar) I0 | I1 | LAGU | SAGU | FP0 | FP1 | | 1-load | | | 2-mul | | 3-load | | | | 3-add | | | | | | | 4-store | |
ここで、マイクロオペレーションで命令を壊すことにより、プロセッサーは並列実行モジュールを利用し、命令が実行されるときに遅延を部分的または完全に「隠す」ことができます(
3-load
つの異なるモジュールで
3-load
と
2-mul
が並列に実行されます)。
しかし、これは常に可能とは限りません。
2-mul
、
3-add
、
4-store
間の依存関係のチェーンにより、プロセッサはこれらのマイクロオペレーションを再編成できません(
4-store
には
3-add
結果が必要で、
3-add
は
2-mul
結果が必要です)。 したがって、並列実行モジュールを効果的に使用するには、依存関係の長いチェーンを避けてください。
Visual Studioオプション
コンパイラーによって生成されたアセンブラーを説明するために、msvc ++ 14.0(VS2015)とClangを使用します。 同じことを行い、異なるコンパイラの比較に慣れることを強くお勧めします。 これにより、システムのすべてのコンポーネントが相互にどのように相互作用するかをよりよく理解し、生成されたコードの品質について判断するのに役立ちます。
いくつかの有用性:
- [シンボル名の表示]オプションは、命令アドレスまたはスタックアドレスの代わりに、ローカル変数と関数の名前を逆アセンブル形式で表示できます。
- アセンブラーをより読みやすくします。
- プロジェクト設定> C / C ++>コード生成>基本ランタイムチェック 、値をデフォルトに変更します。
- 結果を.asmファイルに書き込みます。
- プロジェクト設定> C / C ++>出力ファイル>アセンブラ出力 、値をアセンブリとソースコードに設定します。
- フレームポインターを省略すると(フレームポインターの省略)、コンパイラーはebpを使用してスタックを制御しないように指示されます。
- / Oy(x86のみ、Clang:-fomit-frame-pointer、x64で動作)
基本的な分解例
ここでは、非常に単純なC ++コードの例とその逆アセンブリを見ていきます。 すべてのアセンブラコードは再編成され、完全にドキュメント化されているため、初心者でも簡単に使用できますが、命令の動作について疑問があるかどうかを確認することをお勧めします。
知覚を簡単にするために、機能のプロローグとエピローグは削除されていますが、ここではそれらについては説明しません。
注:ローカル変数はスタックで宣言されます。 たとえば、 mov dword ptr [rbp + 4]、0Ah; int b = 10は、ローカル変数 'b'が相対アドレス(オフセット)4でスタックにプッシュされ(rbpが参照する)、0Ahまたは10進数で10に初期化されることを意味します。
単純な精度の浮動小数点演算
算術浮動小数点演算は、x87 FPU(80ビット精度、スカラー)またはSSE(32ビットまたは64ビット精度、ベクトル化)を使用して実行できます。 X64は常にSSE2命令のセットをサポートし、 デフォルトでは浮動小数点演算に使用されます 。
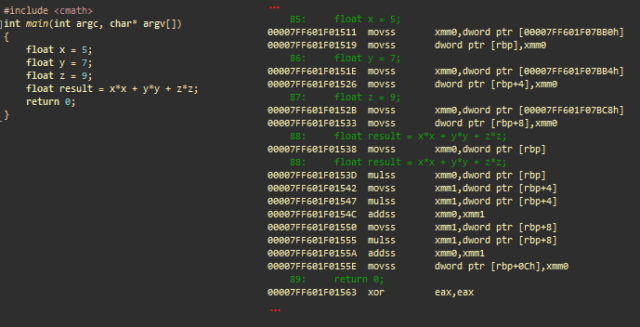
SSEを使用した単純な算術浮動小数点演算。 msvc ++
初期化
- movss xmm0 、dword ptr [adr]; xmm0のadrにある浮動小数点値をロードします
- movss dword ptr [rbp]、xmm0 ; スタックに保存します(float x)
- ...; yおよびzと同じ
x * xを計算します
- movss xmm0 、dword ptr [rbp] ; スカラーxをxmm0にロードします
- mulss xmm0 、dword ptr [rbp] ; xmm0(= x)にxを掛ける
y * yを計算し、x * xを加算します
- movss xmm1 、dword ptr [rbp + 4] ; xmm1にスカラーyをロードします
- mulss xmm1 、dword ptr [rbp + 4] ; xmm1(= y)にyを掛ける
- xmm0、xmm1を追加します。 xmm1(y * y)にxmm0(x * x)を追加します
z * zを計算し、x * x + y * yを加算します
- movss xmm1 、dword ptr [rbp + 8]; xmm1にスカラーzをロードします
- mulss xmm1 、dword ptr [rbp + 8]; xmm1(= z)にzを掛ける
- xmm0、xmm1を追加します。 xmm0(x * x + y * y)にxmm1(z * z)を追加します
最終結果を保存します。
- movss dword ptr [ rbp + 0Ch]、 xmm0 ; xmm0を結果に保存します
- xor eax、eax ; eax =0。eaxにはmain()の戻り値が含まれます
この例では、XMMレジスタを使用して単一の浮動小数点値を格納します。 SSEを使用すると、異なるデータ型で、単一の値と複数の値の両方を操作できます。 SSEの追加ステートメントを見てください。
- xmm0、xmm1を追加します。 1つのスカラー単精度浮動小数点値としての各レジスタ( s calar s ingle精度の浮動小数点値)
- addps xmm0、xmm1 ; 4つのパックされた単精度浮動小数点値としての各レジスタ(パックされたs ingle精度の浮動小数点値)
- xmm0、xmm1を追加 。 1つのスカラー倍精度浮動小数点値としての各レジスター( sカラーd倍精度浮動小数点値)
- addpd xmm0、xmm1 ; 2つのパックされた倍精度浮動小数点値としての各レジスター(パックされたダブル精度の浮動小数点値)
- paddd xmm0、xmm1 ; 各レジスターは、4つのパックされたDWORD値(パックされたDOUBLEワード(32ビット整数)値)
分岐
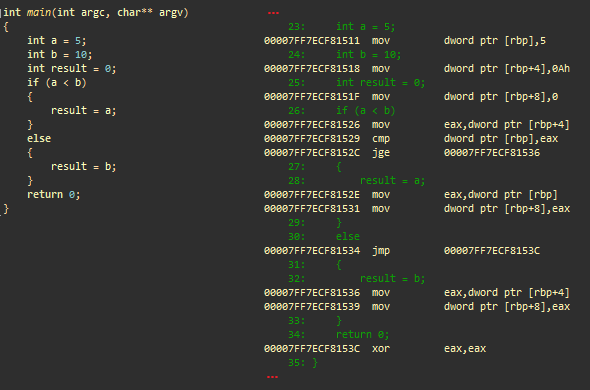
分岐の例。 msvc ++
初期化
- mov dword ptr [ rbp ]、5; 5をスタックに保存します(整数a)
- mov dword ptr [ rbp +4]、0Ah; スタックに10を保存します(整数b)
- mov dword ptr [ rbp +8]、0; スタックに0を保存します(整数の結果)
状態
- mov eax 、dword ptr [ rbp +4]; bをeaxにロードします
- cmp dword ptr [ rbp ]、 eax ; aとeax(b)を比較します
- jge @ ECF81536; aがb以上の場合に遷移します
'then'結果= a
- mov eax 、dword ptr [ rbp ]; AXを読み込みます
- mov dword ptr [ rbp +8]、 eax ; eaxをスタックに保存します(結果)
- jmp @ ECF8153C; ECF8153Cに行きます
'else'結果= b
- (ECF81536)mov eax 、dword ptr [ rbp +4]; bをeaxにロードします
- mov dword ptr [rbp + 8]、eax; eaxをスタックに保存します(結果)
- (ECF8153C) xor eax、eax; eax =0。eaxにはmain()の戻り値が含まれます
cmp命令は、最初のソースのオペランドを2番目のソースと比較し、結果に従ってRFLAGSレジスタのステータスフラグを設定します 。 ®FLAGSレジスタは、プロセッサの現在の状態を含むx86プロセッサステータスレジスタです。 cmp命令は通常、条件分岐 (例: jge )と組み合わせて使用されます。 遷移で使用される条件コードは、 cmp命令の結果に依存します( RFLAGS条件コード)。
整数と「for」ループを使用した算術演算
アセンブラーでは、ループは主に一連の条件分岐(= if ... goto)として表されます。
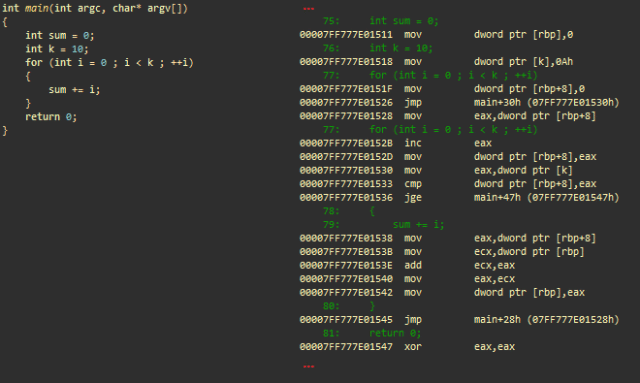
整数と「for」ループを使用した算術演算。 msvc ++
初期化
- mov dword ptr [ rbp ]、0; スタックに0を保存します(整数の合計)
- mov dword ptr [k]、0Ah; スタックに10を保存します(整数k)
- mov dword ptr [ rbp +8]、0; ループでの反復のためにスタック(整数i)に0を保存します
- jmp main + 30h; メイン+ 30時間になります
iのインクリメントを担当するコードの部分
- (メイン+ 28h)mov eax 、dword ptr [ rbp +8]; iをeaxにロードします
- inc eax ; 増分
- mov dword ptr [ rbp +8]、 eax ; スタックに保存します
終了条件のテストを担当するコードの部分(i> = k)
- (メイン+ 30時間)mov eax 、dword ptr [k]; eaxのスタックからkをロードします
- cmp dword ptr [ rbp +8]、 eax ; iをeax(= k)と比較します
- jge main + 47h; iがk以上の場合、遷移を行います(サイクルを完了します)
「実際の作業」:sum + = i
- mov eax 、dword ptr [ rbp +8]; iをeaxにロードします
- mov ecx 、dword ptr [ rbp ]; ecxに量をロードします
- ecx、eaxを追加します。 eaxとecxをスタックします(ecx = sum + i)
- mov eax、ecx ; ecxをeaxに転送します
- mov dword ptr [rbp]、eax ; eax(量)をスタックに保存します
- jmp main + 28h; 遷移を行い、ループの次の反復を処理します
- (メイン+ 47h)xor eax、eax ; eax =0。eaxにはmain()の戻り値が含まれます。
SSE組み込み関数
, SSE ( — ). , :
- _mm_mul_ps mulps
- _mm_load_ps movaps
- _mm_add_ps addps
- _mm_store_ps movaps
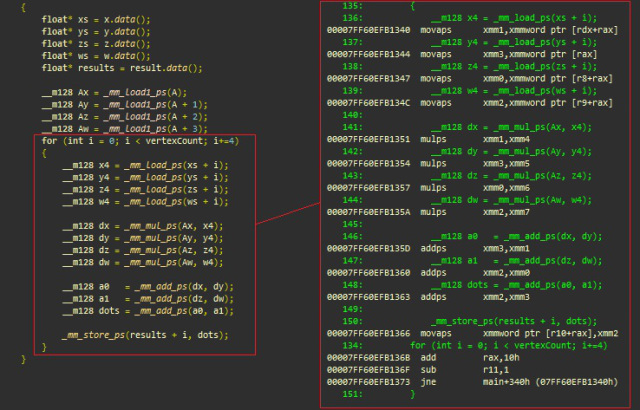
SSE, msvc++
(xmmword 128 dword)
- (main+340h) movaps xmm1 , xmmword ptr [rdx+rax] ; 128- xmmword ( ) xs+i xmm1
- movaps xmm3 , xmmword ptr [rax] ; 4 ys+i xmm3
- movaps xmm0 , xmmword ptr [r8+rax] ; 4 zs+i xmm0
- movaps xmm2 , xmmword ptr [r9+rax] ; 4 ws+i xmm2
dot(v[i], A) = xi * Ax + yi * Ay + zi * Az + wi * Aw , (vertices) :
- mulps xmm1, xmm4 ; xmm1 *= xmm4 xn.Ax, n [0..3]
- mulps xmm3, xmm5 ; xmm3 *= xmm5 yn.Ay, n [0..3]
- mulps xmm0, xmm6 ; xmm0 *= xmm6 zn.Az, n [0..3]
- mulps xmm2, xmm7 ; xmm2 *= xmm7 wn.Aw, n [0..3]
- addps xmm3, xmm1 ; xmm3 += xmm1 xn.Ax + yn.Ay
- addps xmm2, xmm0 ; xmm2 += xmm0 zn.Az + wn.Aw
- addps xmm2, xmm3 ; xmm2 += xmm3 xn.Ax + yn.Ay + zn.Az + wn.Aw
( + )
- movaps xmmword ptr [r10 + rax], xmm2 ; 128- xmmword (4 ) , r10+rax
- add rax , 10h; 16 rax ( = 4 )
- sub r11,1 ; r11–,
- jne main+34h;
AVX (256-, 8 ):
_m256 Ax = _mm256_broadcast_ss(A); ... for (int i = 0; i < vertexCount; i+=8) // 8 (256-) { __m256 x4 = _mm256_load_ps(xs + i); .. __m256 dx = _mm256_mul_ps(Ax, x4); .. __m256 a0 = _mm256_add_ps(dx, dy); .. _mm256_store_ps(results + i, dots); }
(switch)
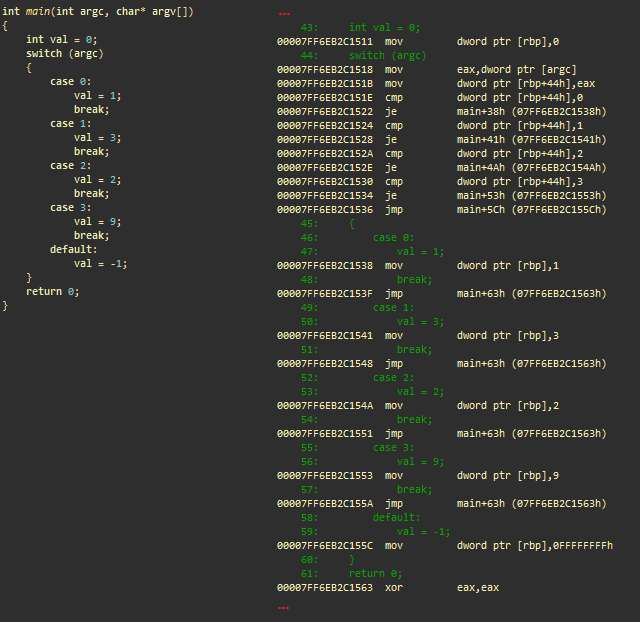
. msvc++
- mov dword ptr [ rbp ], 0; 0 ( )
- mov eax , dword ptr [argc]; argc eax
- mov dword ptr [ rbp +44h], eax ;
- cmp dword ptr [ rbp +44h], 0; argc to 0
- je main+38h; if argc == 0, main+38h (case 0)
- cmp dword ptr [ rbp +44h], 1; argc 1
- je main+41h; if argc == 1, main+41h (case 1)
- cmp dword ptr [ rbp +44h], 2; argc 0
- je main+4Ah; if argc == 2, main+4Ah (case 2)
- cmp dword ptr [ rbp +44h], 3; argc 3
- je main+53h; if argc == 3, main+53h (case 3)
- jmp main+5Ch; main+5Ch ( )
Case 0
- (main+38h) mov dword ptr [ rbp ], 1; 1 (val)
- jmp main+63h; main+63h,
Case 1
- (main+41h) mov dword ptr [ rbp ], 3; 3 (val)
- jmp main+63h; main+63h,
...
- (main+63h) xor eax, eax ; eax = 0. eax main()
. ++- if-else, . .
- What Every Programmer Should Know About Memory
- Intel Instrinsics Guide
- Jaguar Out-of-Order Scheduling
- The Intel Architecture Processors Pipeline
- x86-64bit Opcode and Instruction Reference
- Why do CPUs have multiple cache levels?
