はじめに
スポーツゲーム「チェッカー」は、コンピューターがまだ完全に計算していない人類のゲームの1つです。 科学者がコンピュータが決して失われない戦略を見つけたというニュースがあります。 このゲームに専念していた9年間で、私は1つのプログラムにしか出会うことができませんでした。 おそらく私のスポーツの経験から、それが上記の戦略を実行するプログラムであると想定することが可能になるでしょう。 驚いたことに、60 MBしか必要としませんでした。 それとも、基地によく訓練されたニューラルネットワークがあったのでしょうか? それでも、計算することは不可能だとは信じられません。 10 ^ 20のポジションしかないのですが、私のコンピューターはそのようなタスクに対処できませんか? また、ゲームの開始時に、対戦相手がサーベルを与えて戦術的優位に立つ戦術は本当にありませんか?! 私はそのようなデビューを見たことがありません。 確認に行きます...
組み合わせ問題を解決するためのアルゴリズムの実装
最初の試みは2年目の終わりに行われました。 C言語の質の高い研究の後、C ++を学ぶのに害はないと思いました。 この言語に関する多数の講義を見た後、私はいくつかのプロジェクトを取り上げたいと思いました。 そして彼はチェッカーを取り上げた。 変数を細かく処理することで、ポジションの合理的な計算により多くの時間を費やすことができました。 これらのアクションがグラフを使用したアクションに例えると、このアルゴリズムは幅優先検索と呼ばれる可能性があります。 アルゴリズムの停止は、グラフを完全に通過することでした。
ボード上の状況を説明するオブジェクトが1つありました。 1つのオブジェクトに保存された:
class Queue { public: Queue *pnr; /*pointer to next record*/ Queue *ppr; /*pointer to prev record*/ Map *pdb; /*pointer to draught board*/ char *action; /*actions of parents*/ Queue *pp; /*pointer to parent*/ Queue *pfc; /*pointer to first child*/ int nmd; /*Approval of the number of moves to a draw*/ int color; };
ここでは幅優先検索アルゴリズムが実装されているため、データは二重に接続されたシートに格納できます。この場合、pnrおよびpprポインターがこのコレクションを実装します。
pdb-ボードの配置へのポインター。
action-この位置を達成するために、親によって行われた進捗状況に関するデータ。 これは、チェッカーを移動するときのチェッカー「c3 – d4」または切断するときの「c3:e5」の移動の通常の記録のように見えました。 この変数は、現在の状況をより正確にデバッグするために必要でした。
pp 、 pfc-親および最初の子の位置へのポインター。 なぜなら 検索アルゴリズムは幅で実装され、二重にリンクされたリストで生成されたすべての位置は、次々に並んで配置されました。 したがって、データをツリーの形式で保存するには、最初の子へのポインターと、それ以降のすべての子が同じ親を参照するように保存するだけで十分です。 このアルゴリズムにより、親は子の結果を抽出できます。つまり、現在の状況を分析し、この動きまたはその動きが子を生じさせた結果のみを調べることができます。
nmd-ゲームが引き分けと見なされるまでに残っている動きの数を示す数値。 たとえば、1人に対して3人の女性の状況では、ゲームを完了するために15の移動のみが割り当てられます。 チェッカーの数が変わると、チェッカーがクイーンになった後、この数が再計算されます。
色 -誰の動きは今です。
スタックオーバーフローを非常に恐れており、関数にポインタを渡す方が良いと考えたため、オブジェクトをパラメータとして直接渡すことは避けた。 実装は簡単でした。キューから要素を取り出して調べ、後続の位置を生成してから、キューから次の要素を取り出して、というように円で囲みます。
結果:
閲覧:61.133アイテム
待機エントリ:264.050アイテム
RAM(2 GB)はそのようなデータでのみ終了しました。 このような結果は、短い組み合わせの問題にのみ適しています。
しかし、チェッカーの位置を操作するこの方法により、プログラムの「コア」の作業を慎重にデバッグすることができました。
「バージョン管理システム」への移行
このアルゴリズムでは、ボードに関するデータの保存に多くのメモリが費やされました。 メモリーの割り当てに必要な各位置。 さらに、現在のチェッカーの配置をより良くコーディングする方法については思いつきませんでした。
/* info about one checker */ class Checkers { public: chlive live; chstatus status; }; /* info about position a checker */ class PosCheckers { public: chcolor color; Checkers *ptrCheckers; }; /* battlefield */ class Map { public: PosCheckers coordinate[8][8]; };
color-チェッカーカラー。 黒、白、または空。
ptrCheckers-このフィールドにチェッカーがない場合、メモリを割り当てません。
ステータス -クイーンまたはチェッカー。
live-チェッカーは生きています。 このチェッカーを再度削減しないためにのみ。
座標[8] [8]の代わりに、座標[8] [4]だけを省くことができることを理解していますが、独自のコードの理解は非常に影響を受けます。
一般に、ポジションを維持するには多くのメモリが必要だったので、ドラフトのポジションを特定する責任をアクションに割り当てることにしました-「c3-d4」などのデータを含む親の進捗状況の記録。
さて、キューから要素を取得すると、最初から始めます。 私たちはチェッカーの開始位置を取り、すでに戻ってから、この子供を引き付けた動きを実行します。 したがって、ラインの各要素のボード上のチェッカーの配置が構築されました。
結果:
閲覧:1.845.265アイテム
キューエントリ:8.209.054アイテム
「バージョン管理システム」の拒否。 ディープサーチに行く
残念ながら、幅優先の検索には少なくともいくつかの重大な問題がありました。場合によっては、同じパーティの配置が作成されました。 そして、すでに作成された多くのデータを持つパーティーを認識するのは時間がかかりました。 また、メモリ不足になったときの対処方法も明確ではありませんでした。 イデオロギーの連鎖を復元するには、保存されたすべてのデータが必要でした。そのため、必要に応じて、どこかからメモリを「すくい取り」、結局はそうなりませんでした。
「詳細な」検索により、ローカル問題(組み合わせ問題の解決策)からグローバル問題(バッチ全体の誤計算)に移行することができました。 このアルゴリズムは、チェッカーの現在の配置を考慮し、子孫を生成し、それらから最初のチェッカーを選択し、それを現在のチェッカーの役割に割り当てます。 子孫がない場合、この位置で負けたことを示し、親との次の取り決めを検討します。
また、女性の存在下で繰り返し位置を計算しないために、すべての親の位置を調べることにしました。 ある場合、私はそれを考慮しませんが、次へ進みます。
結果が知られている星座からgreat孫の記憶を取り除くことが決定されました。 したがって、オーバーフローを回避することができました。 最も深い要素を検索するときにオーバーフローが発生しない場合。
また、位置を保存する新しい方法を追加することも決定されました-形状のリスト:
class ListCheckers { public: ListCheckers *pnr; chcolor color; chstatus status; int x,y; /* coordinate */ };
それにより、ログハウスの可能性をより迅速に見つけ始め、移動の可能性をチェックするチェッカーを整理しました。 これで、キューに格納された「位置」オブジェクトには次のフィールドがありました。
class Queue { public: ListCheckers *plch; /*pointer to list of checkers*/ ListChilds *pcs; /*pointer to list of childs*/ chcolor color; int draw; chresult result; };
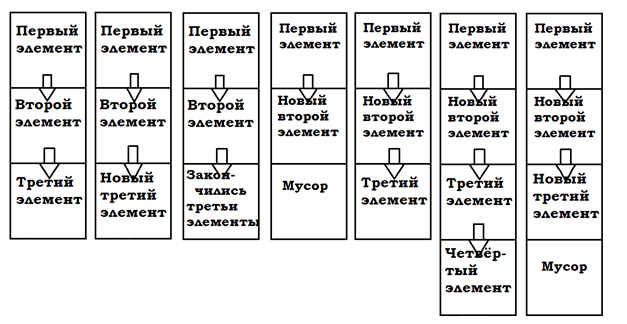
freeコマンドが100%の空きメモリを保証しないとは思っていませんでした 。 デバッグ中に、freeコマンドを実行した後、メモリがまったく解放されないことが判明しました。 フォーラムの暗闇のどこかで、freeはOSにメモリの解放に関する指示のみを与え、OSだけがメモリを解放するかどうかを決定することがわかりました。 一般的に、私のOSは「貪欲」だったため、別の方法でメモリを操作する必要がありました。 最初の「子供」のチェーンを維持するために、必要に応じてメモリを割り当てました。 そして、表示した「最初の」子を削除する代わりに、それに関するデータは次の子に関するデータで上書きされました。
このために、メモリを使用した動的な作業を担当する要素が開発されました。
class MainQueue { public: MainQueue* parent; /*pointer to parent's record*/ MainQueue* next_record; /*pointer to child's record*/ Queue* now; /*pointer to record on data with position*/ int draw; };
結果:
1日の連続操作の場合:
2.040.963ロットが作成されました
1.241.938ゲームが閲覧されました
ランダムアクセスメモリ上の占有場所:1.378 MB
ファイルを操作する
残念ながら、次の要素をこのように選択すると、同じ位置で長い間「ハング」してしまいます。 特に女性のための誤算で。 そのため、すでに表示された位置の結果が保存されるデータベースを実装したかったのです。 そのため、各バッチに関するデータを保存することにしました。
メモリの問題から離れて、私は再びそれに遭遇しました。 RAMが不足していたため、外部メディアを使用することにしました。 index.txtおよびqueue.txtファイルに書き込んだすべてのポジション。 queue.txtに、各バッチに関するデータを保存しました。 また、index.txt内-バッチ識別子とqueue.txt内のこのバッチに関する情報の場所、つまりオフセット。 データを圧縮したかったのですが、読みやすいままにしておきました。 まだフィニッシュラインまで遠いと思ったからです。 したがって、次の形式でデータを保存しました。
queue.txt : aaaaeaaaaacaaaaa aaaaeaaaaaakaaaa 50 U Aaaaaaeaaacaaaaa Aaaaaaauaacaaaaa 49 U aaaaaaeakaaaaaaa aaaaaaeacaaaaaaa 48 W Aaaaaaaaaauaaaaa 47 L … index.txt : Aaaaeaaaaaaacaaa000000000000000000000 aaaaeaaaaacaaaaa000000000000000000040 aaaaeaaaaaakaaaa--------------------- Aaaaaaeaaacaaaaa000000000000000000080 Aaaaaaauaacaaaaa000000000000000000178 …
ボード上では、ゲームセルは5つの状態を取ることができます。白/黒のチェッカー、白/黒のクイーン、または空です。 したがって、2つのセルにはさまざまな組み合わせで25の状態があります。 ラテンアルファベットには26文字があり、1つの文字で2つのゲームセルの状態を一度に記述するのに非常に適していることに注意してください。 これは、32個のゲームセルを備えたボード全体を16文字のラテンアルファベットで記述できることを意味します。 また、この位置で誰の動きを保存する必要があります。 次に、最初の文字が大文字の場合、移動は黒になります。 また、現在のラインナップからポジションドローを受け入れるまでの移動回数を覚えておく必要があります。 また、結果:W-win、L-lose、D-draw、U-unknown。 また、デバッグはそれほど難しくありません。
結果:
2時間、プログラムは4 MBのRAMしか必要としませんでしたが、数少ないパーティをカウントしました。 queue.txtには2918のエントリがあり、401 KBでした。 index.txtファイルには6095レコードが含まれており、重量は232 KBでした。 そのようなペースでは、計算できるのは5億= 5 * 10 ^ 8ポジションだけであり、私の1TBドライブは十分なメモリがないと報告しました。 はい、これは非常にすぐに起こります。 計算された位置は、ゲーム全体に弱い影響を及ぼします。
データ圧縮
プロジェクトを促進するためのオプションは3つしかありません。
- 5 ^ 32-数字のさまざまな配置、
2 * 5 ^ 32-その動きを与えられた
2 *(2 * 5 ^ 32)-占有スペースの最大量は〜9.32 * 10 ^ 22ビットです 。ただし、各配置で結果が2ビットに等しいことを示すのに十分です。
さらに、通常のバッチには5 * 10 ^ 20の異なる位置があります。
したがって、約2 *(2 * 5 * 10 ^ 20)= 2 * 10 ^ 21ビットは情報提供であり、残りの〜(9,12 * 10 ^ 21)は、このパーティでのドラフトのそのような配置が存在しないことを示します。
1TB = 8 * 10 ^ 12ビットが利用可能
高速データインデックスを維持しながら、このタスクの圧縮アルゴリズムを開発する必要があります。
- 通常のバッチでは、5 * 10 ^ 20の異なるポジションがあります。
迅速なインデックス作成のために、その「子供」の各位置と結果を保存します。 平均して、ポジションには約Yの子孫があります。
子孫への「リンク」をXビットでエンコードします。結果は2ビットで、Zのエントリ間のセパレーターです。各位置に対して(X * Y + 2 + Z)ビットを取得します。 合計(X * Y + 2 + Z)* 5 * 10 ^ 20ビットは 、初期配置で使用されるすべての位置のストレージに割り当てられる必要があります。
1TB = 8 * 10 ^ 12ビットが利用可能
高速データインデックスを維持しながら、このタスクの圧縮アルゴリズムを開発する必要があります。
- レコード内の繰り返しパターンを見つけて、リプレイをより短いレコードに置き換えて実装してみましょう。 アルゴリズムは理想的にはハフマンコードに似ています。
それほど高速ではないインデックス作成に悪影響を及ぼします。
合計で、データを≈10^ 22から10 ^ 13ビットに圧縮する必要があります。 そのため、データを99.9999999914163%だけ圧縮できるアルゴリズムを記述する必要がありました。 さらに、高速なインデックス作成を維持する必要があることをまだ考慮せずに、どのアルゴリズムでもこれが可能であるとは思いません。
結果:
すべての関係者に関するデータを保存することはまったく適用されません。
ランダムアクセスメモリでのみプロジェクトの作業に戻ります。 「プロセッサー」の作成
RAMのファイルに保存されたデータを保存するのが慣例でした。 これを行うために、データストレージ構造を変更することが決定されました。
class list_strings { public: list_strings* next; char* data; list_strings() { data = new char[17]; data[0] = '\0'; next = nullptr; } }; class Queue { public: ListCheckers *plch; /*pointer to list of checkers*/ list_strings *pcs; /*list of data of childs*/ chcolor color; chresult result; int to_draw; }
また、Queueオブジェクトを格納する原則が変更されました。 MainQueueが書き換えられた後、MainQueueが指すQueueオブジェクトも書き換えられます。
「子供」を保存するための「pcs」フィールドは、「Aaaaaaaaacaaaaa」などのデータを含む単一リンクリストとして実装され、必要に応じて拡張されます。 割り当てられたメモリを繰り返し使用するため(上書き時)、データフィールドは '\ 0'-ゼロに等しくなり、フィールドに重要な情報が含まれていないことを示しました。 なぜなら 「オブジェクト」が変更されました。
結果:
最大使用可能メモリ領域:844 KB。 7時間実行すると、8.865.798.818の位置を表示できました。 ただし、ポジションは繰り返すことができます。 これらの結果は、許容可能なリードタイムで当事者の完全な計算を達成するには不十分です。
これで、位置をグラインドする「プロセッサ」があり、844 KBのRAMだけが必要であると言えます。つまり、残りのメモリを有効に使用できます。たとえば、既に計算された位置を計算しないように「キャッシュメモリ」を実装します。
「キャッシュ」を作成する
メモリからデータを最速で取得するために、RAMの最大スペースを埋めるハッシュテーブルが選択されました。 ハッシュ関数として、md5アルゴリズムの最後の番号が選択され、その入力にはエンコードされた記述位置が与えられました。 つまり、md5 0237d0d0b76bcb8872ecc05a455e5dcfの位置「Aaauaueaaacckaaa」は、f * 2 ^ 12 + c * 2 ^ 8 + d * 2 ^ 4 + 5 = 15 * 4096 + 12 * 256 + 13 * 16 + 5 = 64725に格納されます。
ハッシュテーブル内のレコードのストレージの単位はセルでした。 このアプローチにより、「古い」セルからデータを削除し、そのスペースを再利用できます。 廃止は、リングバッファを使用して実装されます。
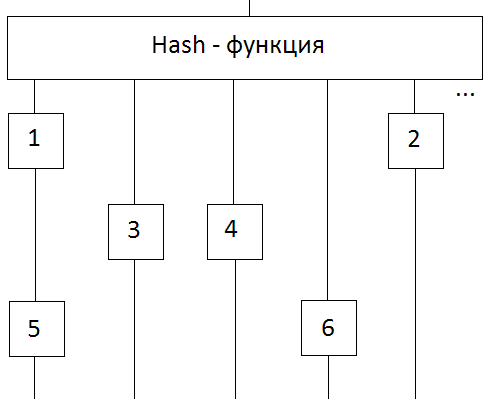
最初のアドレスでは、セルNo.1とNo.5がキャッシュに、2番目のNo.3 ...に、そしてリングバッファには、セルが時系列に格納されます。 最大5個のセルを保存できる場合、1番目のセルは現在の場所から「引き出され」、6番目のセルの場所に配置されます。 また、最初のアドレスのキャッシュメモリには、セル番号5のみが保存されます。
class mem_cel { public: mem_cel* pnhc; /* pointer to next in hash collection */ mem_cel* pphc; /* pointer to prev in hash collection */ mem_cel* pnrb; /* pointer to next "mem_cel" record in ring buffer */ mem_cel* pprb; /* pointer to prev "mem_cel" record in ring buffer */ chresult result; int draw; stringMap condition; };
条件フィールドは、チェッカーの望ましい配置を識別するために必要です。これは、同じキャッシュアドレスに異なる配置を格納できるためです。
ドローフィールドは、マッチリクエストを識別するために必要です。 メモリに3つの移動のみが割り当てられた位置のドローが含まれている場合、さらに移動がある場合は、勝ち負けのいずれかが可能です。
結果:
1時間実行すると、10,400.590のポジションを表示できました。 この誤算を高速化するために何かを実装する必要があります。 しかし、計算すると、私のコンピューターはせいぜい10 ^ 20 / 10.400.590 = 9.6 * 10 ^ 12時間= 4 * 10 ^ 11日以内に10 ^ 20の位置を計算します。
どのコードが「狭い首」であるかを見てみましょう。 この目的のために、OProfileプロファイラーを使用しました。
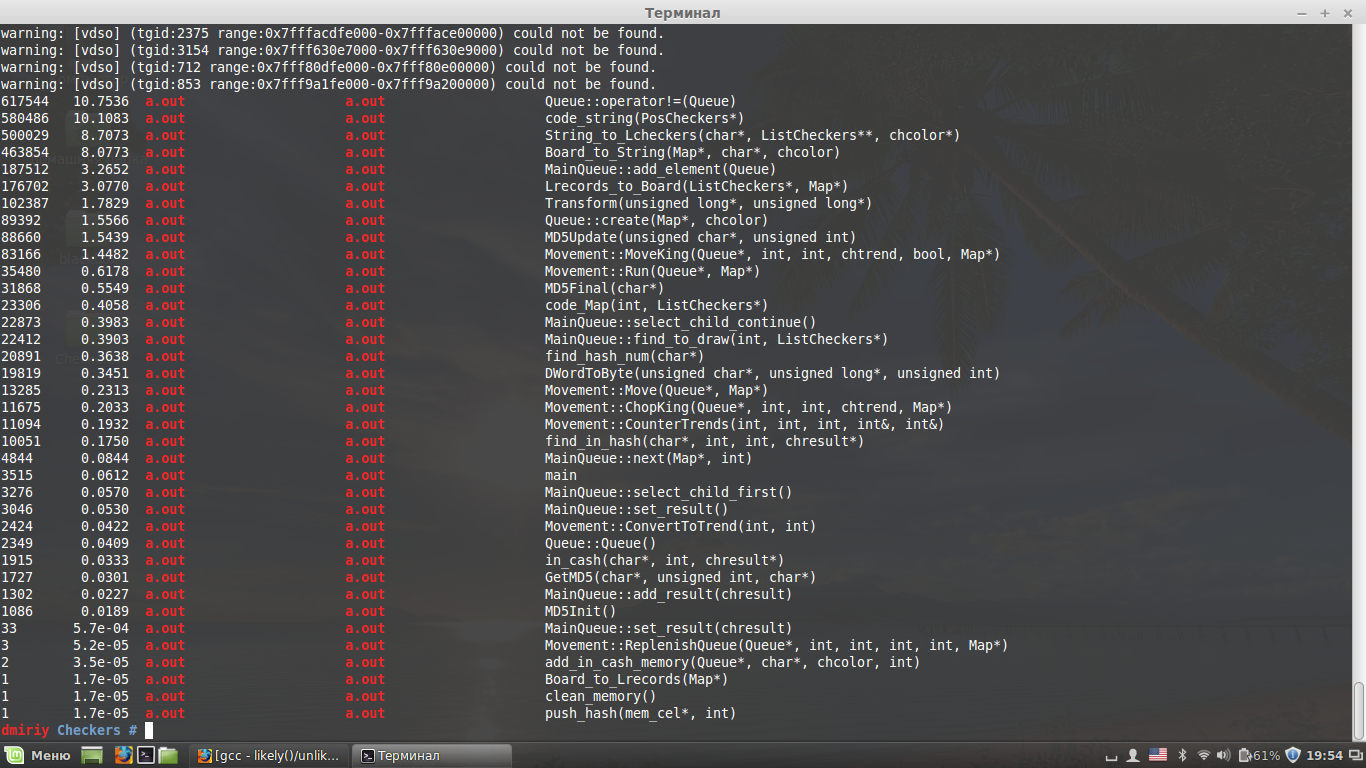
1。
Queue::operator!=(Queue)
キュー要素の違いを確認します。 新しいアイテムがキューに追加されたときに呼び出され、3つの位置を確認します。 チェックは、現在の位置につながったすべての要素で実行されます。
最適化:ボード上のピースの数またはステータスを変更する場合は、マークしてください。 異なる形状のセットを持つ位置を使用するには、チェックしないでください。
2。
code_string(PosCheckers*)
市松模様のアイテム要素を文字に変換するために使用されます。 Board_to_String(Map *、char *、chcolor)に必要です。
最適化:最初に、Board_to_String関数の呼び出し回数を減らします(Map *、char *、chcolor)
3。
String_to_Lcheckers(stringMap, ListCheckers**, chcolor*)
4。
Board_to_String(Map*, char*, chcolor)
頻繁に呼び出されます。 そのため、それらへの呼び出しの数を減らす必要があります。
テキストをチェッカーデータのコレクションに変換するには、String_to_Lcheckersが必要です。
Board_to_Stringは、位置をOPに保存できるテキストに変換するために必要です。
最適化:ボード上の同じ位置を表すために3つのデータ構造を操作する必要があるため:
Lcheckers-フィールド上のチェッカーのリスト。 移動の可能性を確認するためにチェッカーをすばやく選択する必要がありました。 マップまたは「ボード」-配列[8] [8]。 それは力の完全なバランスが含まれています。
stringMapまたは「String」-データを保存するための文字列。 したがって、あるデータ表現から別のデータ表現への変換の数を減らすか、データ構造の数を減らすようにする必要があります。
マジカルビットボード
思いがけず、私はhabrahabrの解決策を見つけました。 魔法のビットボードとロシアのチェッカーです。 この記事の著者は、4つの32ビットワードを使用してボードに関する情報をエンコードすることを提案しています。
言葉:
1)白のすべての数字の位置
2)黒のすべての図の位置
3)白いチェッカーの位置
4)黒色のチェッカーの位置
さらに、図の位置には次のように番号が付けられています。

さて、少なくとも1つのチェッカーを備えたログハウスの可能性を見つけるには、すべてのチェッカーの位置を対応する方向に移動するだけで十分です。
bitboard_t try_left_up = ((((checkers & possible_left_up) << 1) & enemy) << 1) & empty;
これにより、ログハウスとしての機会の検索が簡単になります。 残念なことに、私はこの記事の著者、彼がどのように女性と仕事をすることを決めたかを理解していませんでした。 現時点では私には美しいものがありません。もちろん、将来的に修正する必要があります。
したがって、上記の3つのデータ構造を1つに置き換えることができます。
typedef uint32_t bitboard_t; bitboard_t bbMap[4];
また、この変更により、md5を使用せずにハッシュテーブル内の番号を検索できるようになりました。 この使命は次の式を委ねられました。
#define HASH_NUM 0xFFFFFF hash_num = ((bbMap[0] ^ ~bbMap[1]) ^ ReverseBits(~bbMap[2] ^ bbMap[3])) & HASH_NUM;
ReverseBitsが少し反転しているところ。 例:番号0x80E0があり、0x0701になりました。
結果:
1時間実行すると、15.140.000のポジションを表示できました。これは間違いなく優れています。 しかし、これはまだ完全な誤算には十分ではありません。
修正されたバグ
以前は、1時間あたり754,000,000のポジションを示していました。 コードの恥ずべき誤植...
プロジェクトアルゴリズムが実装されたと思います。 したがって、機能の高速化に集中できます。
機能加速
ありそうな/ありそうにないものを読んだので、コードの「加速」を確認することにしました。 一般に、ifステートメントの実行中にプロセッサがどの命令をロードする必要があるかを示します。 その後、または後のいずれか。 たとえば、命令の選択が失敗した場合、プロセッサはアイドル状態になり、その後に指示される命令を待機します。 MSコンパイラーでは、このような命令は__assumeと呼ばれます。
このように各ifを実装したら、テストすることにしました:
__assume(selected == nullptr); if (selected != nullptr) { return selected; }
結果:
驚いたことに、コードは本当に加速しました。 最初の1時間で、16.750.000のポジションが計算されました。
アセンブラーの挿入を実装することを敢えてしませんでした。 私のコードはすぐに読めなくなり、これは私にとって重要な側面です。 プロジェクトの中断以来、私は時々数ヶ月に達しました。
計算された動きの深さを制限する
残念ながら、これはそう呼ばれる可能性があります。時間が経つにつれて、すべての位置を計算することはまだ不可能であることに本当に気付きました。 したがって、結果の機能を備えた移動リミッターを追加しました。
チェッカー= +1ポイント、女性= +3ポイント。 このアプローチは完全に真実ではないことを理解していますが、ほとんどの場合、有効な値を提供します。 したがって、私はこれにこだわることにしました。
結果:
始めたところに戻りました。 計算された動きの数に制限があるため、私のプログラムは現在、組み合わせの問題を解決するためのプログラムです。 しかし、これは恐ろしいことではなく、リミッターは削除できます。
全体的な結果:
最初の1時間で、約1,700万のポジションが計算されます。
次に何をする? 明確ではありません。CUDAを使用して計算を並列化できます...しかし、これを使用すると、1台のコンピューターで各プレイヤーの少なくとも50の動きを計算できるとは思いません。あなたが整理しなければならない位置の数を知るために...
あなたはアルゴリズムを変更する必要があります...どのように?アイデアはありません...広告されたニューラルネットワークを使用できますか?ニューラルネットワークは、ゲームの開始時にチェッカーの損失を評価するとは思わない。
これまで、より高速なコンピューターの外観/コスト削減の来るべき時期を待ちます。おそらく、コードアクセラレーションのより高度な技術が既に登場するでしょう。そして、ニューラルネットワークを勉強する間、間違っているのかもしれません。彼らは計算アルゴリズムの先頭に立つでしょう...待って、見てください。
一部のデータ:
最大レンダリング深度-表示されたアイテムの数
1-7
2から56は、(我々は...最初の移動の白はその後、それらのそれぞれブラックウォッチのための7点の新しい位置を生成する計算するには、さらにホワイトの第二の移動を行う必要がないことを確認してください7 + 7 * 7 ...作る)
3 - 267
4から1017
5 - 3570 6-11
460 7-34
455
8-95 921
9-265 026
10-699 718
11-1 793 576 12-4
352 835
13-10 571 175