
とげのある道を進むためのステップ
- 目的に使用できるニューラルネットワークの実装を見つける必要があります。
- トレーニングに使用できるデータ(ケース)を準備します。
- モデルをトレーニングします。
この記事を作成してくれた私のパトロンに感謝します。
アレクサンドル・シェペリエフ、セルゲイ・テン、アレクセイ・ポリエタイエフ、ニキータ・ペンジン、アンドレイ・カルナウホフ、マトヴェエフ・エフゲニー、アントン・ポチョムキン。 あなたもここで彼らの一人になれます 。
目的に使用できるニューロンの実装
TensorFlowにはRNN(再帰的ニューラルネットワーク)の実装が含まれており、 英語/フランス語のペアの翻訳モデルをトレーニングするために使用されます 。 チャットボットのトレーニングに使用するのはこの実装です。
「チャットボットをしているのに、なぜ翻訳モデルを学習しようとしているのか」と尋ねられる人がいるかもしれません。 しかし、これは最初の段階でのみ奇妙に見えるかもしれません。 ちょっと考えて、「翻訳」とは何ですか? 翻訳は、2つの段階のプロセスとして表すことができます。
- 着信メッセージの言語に依存しないプレゼンテーションを作成します。
- 最初のステップで受け取った情報の翻訳言語への表示。
ここで、同じRNNモデルをトレーニングした場合、Eng / Freペアの代わりに映画のEng / Engダイアログを置き換えるとどうなるでしょうか? 理論的には、単純な単一行の質問に答えることができるチャットボットを取得できます(ダイアログのコンテキストを記憶する機能はありません)。 これは、最初のボットには十分なはずです。 さらに、このアプローチは非常に簡単です。 将来的には、最初の実装から始めて、チャットボットをより合理的にすることができます。
後で、チャットボット( 検索ベースモデルなど )により適した、より複雑なネットワークをトレーニングする方法を学習します。
せっかちな人のために:記事の冒頭の写真は、実際にはわずか5万回のトレーニングを繰り返した後のボットとの会話の例です。 ご覧のように、ボットはいくつかの質問に対して多少なりとも有益な回答をすることができます。 ボットの品質は、トレーニングの反復回数とともに向上します。 たとえば、最初の200回の反復の後で彼がどのように答えたかは次のとおりです。
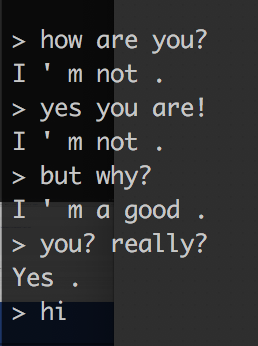
このシンプルなアプローチにより、異なるキャラクターのボットを作成することもできます。 たとえば、スターウォーズやロードオブザリングの物語からの対話で彼を訓練することができます。 さらに、ボットに同じヒーローの対話のかなり大きな部分がある場合(たとえば、映画「Friends」のチャンドラーのすべての対話)、このヒーローのボットを作成できます。
トレーニング用のデータ(企業)の準備
最初のボットをトレーニングするために、「 Cornell Movie Dialogs Corpus 」 フィルムのダイアログボックスを使用します。 それを使用するには、ダイアログをトレーニングに必要な形式に変換する必要があります。 このために、私は小さなスクリプトを用意しました 。
READMEファイルを読んでパッケージの詳細とこのスクリプトの機能を理解してから、記事を読み続けることを強くお勧めします。 ただし、すぐにコピーして実行してすぐに学習できるデータを取得できるコマンドが必要な場合は、次のとおりです。
tmp# git clone https://github.com/b0noI/dialog_converter.git Cloning into 'dialog_converter'… remote: Counting objects: 59, done. remote: Compressing objects: 100% (49/49), done. remote: Total 59 (delta 33), reused 20 (delta 9), pack-reused 0 Unpacking objects: 100% (59/59), done. Checking connectivity… done. tmp# cd dialog_converter dialog_converter git:(master)# python converter.py dialog_converter git:(master)# ls LICENSE README.md converter.py movie_lines.txt train.a train.b
実行が終了すると、さらにトレーニングに使用できる2つのファイルが作成されます。train.aとtrain.bです。
モデルトレーニング
これは最もエキサイティングな部分です。 モデルをトレーニングするには、以下を行う必要があります。
- 強力でサポートされているTensorFlow(これは非常に重要です)ビデオカード(読み取り:NVIDIA)を搭載したマシンを見つけます。
- Eng / Freペアの変換モデルのトレーニングに使用される元の「translate」スクリプトを変更します。
- トレーニングのために車を準備します。
- トレーニングを開始します。
- 待って
- 待って
- 待って
- 私は真剣です...待たなければなりません。
- 利益
Atlantis学習マシンを見つける
このプロセスをできるだけ単純にするために、AWSで使用される、組み立てられたAMI- " Bitfusion TensorFlow AMI "を使用します。 GPUをサポートして構築されたTensorFlowが事前にインストールされています。 執筆時点では、Bitfusion AMIにはTensorFlowバージョン0.11が含まれていました。
AMIイメージからEC2インスタンスを作成するプロセスは非常に単純であり、その検討はこの記事の範囲外です。 ただし、 インスタンスタイプやSSDのサイズなど、プロセスに関連する2つの重要な詳細に注意する価値があります 。 タイプには、p2.xlargeを使用することをお勧めします。十分なビデオメモリ(12 Gb)を備えたNVIDIA GPUを搭載した最も安価なタイプです。 SSDのサイズに関しては、少なくとも100GBを割り当てることをお勧めします。
ここで、元の「翻訳」スクリプトを変更する必要があります
この時点で、TensorFlowをトレーニングするマシンにsshでアクセスできると想定できます。
最初に、元のスクリプトを変更する必要がある理由について説明します。 実際、スクリプト自体では、モデルのトレーニングに使用されるデータソースをオーバーライドすることはできません。 これを修正するために、 機能リクエストを作成しました。 すぐに実装の準備を試みますが、現時点では、「リクエスト」に+1を追加して参加できます。
いずれにせよ、恐れることはありません- 変更は非常に簡単です。 しかし、ごくわずかな変更でさえ、すでにあなたのために行っており、変更されたコードを含むリポジトリを作成しました。 次のことを行うだけです。
ファイルの名前を「train.a」および「train.b」からそれぞれ「train.en」および「train.fr」に変更します。 トレーニングスクリプトは、英語からフランス語への翻訳方法を学習しているとまだ信じているため、これが必要です。
両方のファイルをリモートホストにアップロードする必要があります-これは、rsyncコマンドを使用して実行できます。
➜ train# REMOTE_IP=... ➜ train# ls train.en train.fr ➜ train rsync -r . ubuntu@$REMOTE_IP:/home/ubuntu/train
それでは、リモートホストに接続してtmuxセッションを開始しましょう。 tmuxがわからない場合は、SSHを介して簡単に接続できます。
➜ train ssh ubuntu@$REMOTE_IP 53 packages can be updated. 42 updates are security updates. ######################################################################################################################## ######################################################################################################################## ____ _ _ __ _ _ | __ )(_) |_ / _|_ _ ___(_) ___ _ __ (_) ___ | _ \| | __| |_| | | / __| |/ _ \| '_ \ | |/ _ \ | |_) | | |_| _| |_| \__ \ | (_) | | | |_| | (_) | |____/|_|\__|_| \__,_|___/_|\___/|_| |_(_)_|\___/ Welcome to Bitfusion Ubuntu 14 Tensorflow - Ubuntu 14.04 LTS (GNU/Linux 3.13.0-101-generic x86_64) This AMI is brought to you by Bitfusion.io http://www.bitfusion.io Please email all feedback and support requests to: support@bitfusion.io We would love to hear from you! Contact us with any feedback or a feature request at the email above. ######################################################################################################################## ######################################################################################################################## ######################################################################################################################## Please review the README located at /home/ubuntu/README for more details on how to use this AMI Last login: Sat Dec 10 16:39:26 2016 from 99-46-141-149.lightspeed.sntcca.sbcglobal.net ubuntu@tf:~$ cd train/ ubuntu@tf:~/train$ ls train.en train.fr
TensorFlowがインストールされ、GPUを使用していることを確認しましょう。
ubuntu@tf:~/train$ python Python 2.7.6 (default, Jun 22 2015, 17:58:13) [GCC 4.8.2] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcublas.so.7.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcudnn.so.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcufft.so.7.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcuda.so.1 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcurand.so.7.5 locally >>> print(tf.__version__) 0.11.0
ご覧のとおり、TFバージョン0.11がインストールされており、CUDAライブラリを使用しています。 それでは、トレーニングスクリプトをお辞儀しましょう。
ubuntu@tf:~$ mkdir src/ ubuntu@tf:~$ cd src/ ubuntu@tf:~/src$ git clone https://github.com/b0noI/tensorflow.git Cloning into 'tensorflow'... remote: Counting objects: 117802, done. remote: Compressing objects: 100% (10/10), done. remote: Total 117802 (delta 0), reused 0 (delta 0), pack-reused 117792 Receiving objects: 100% (117802/117802), 83.51 MiB | 19.32 MiB/s, done. Resolving deltas: 100% (88565/88565), done. Checking connectivity... done. ubuntu@tf:~/src$ cd tensorflow/ ubuntu@tf:~/src/tensorflow$ git checkout -b r0.11 origin/r0.11 Branch r0.11 set up to track remote branch r0.11 from origin. Switched to a new branch 'r0.11'
r0.11ブランチが必要であることに注意してください。 まず、このブランチはローカルにインストールされたTensorFlowのバージョンと一貫しています。 第二に、変更を他のブランチに転送しなかったため、必要に応じて自分で変更する必要があります。
おめでとうございます! トレーニングを開始する段階に達しました。 このトレーニングを自由に実行してください。
ubuntu@tf:~/src/tensorflow$ cd tensorflow/models/rnn/translate/ ubuntu@tf:~/src/tensorflow/tensorflow/models/rnn/translate$ python ./translate.py --en_vocab_size=40000 --fr_vocab_size=40000 --data_dir=/home/ubuntu/train --train_dir=/home/ubuntu/train ... Tokenizing data in /home/ubuntu/train/train.en tokenizing line 100000 ... global step 200 learning rate 0.5000 step-time 0.72 perplexity 31051.66 eval: bucket 0 perplexity 173.09 eval: bucket 1 perplexity 181.45 eval: bucket 2 perplexity 398.51 eval: bucket 3 perplexity 547.47
使用するキーのいくつかについて説明しましょう。
- en_vocab_size-英語モデルが学習する一意の単語の数。 ソースデータの一意の単語の数が辞書のサイズを超える場合、辞書にないすべての単語は「UNK」(コード:3)としてマークされます。 しかし、必要以上に辞書を作成することはお勧めしません。 しかし、それ以下であってはなりません。
- fr_vocab_sizeは同じですが、異なるデータ(「フランス語」の場合)用です。
- data_dir-ソースデータのあるディレクトリ。 ここで、スクリプトはファイル「train.en」および「train.fr」を探します。
- train_dir-トレーニングの中間結果をスクリプトが記録するディレクトリ。
学習が継続し、すべてが計画通りに進むことを確認しましょう
トレーニングを開始しました。 しかし、プロセスが継続し、すべてが正常であることを確認しましょう。 6時間後、最初は何かが間違っていたことを最終的に知りたくありません。 グレブと私はすでに何らかの形で半知性を教えていた=)
まず、学習プロセスがGPUのメモリを「ビットオフ」することを確認できます。
$ watch -n 0.5 nvidia-smi
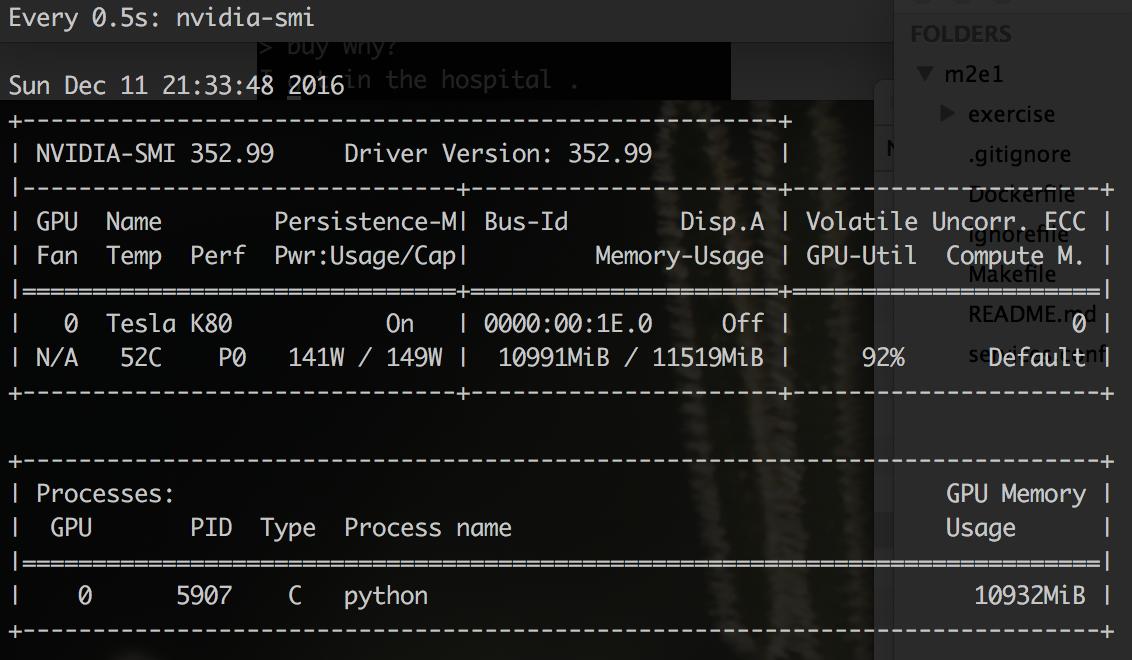
どうやら、それは気味が悪くなく、GPUのほとんどすべてのメモリが占有されています。 これは良い兆候です。 また、プロセスがエラーOutOfMemoryから「ひづめを投げる」ことを恐れないでください。 TFの起動時に、到達可能なGPU上のすべてのメモリを引き継ぐだけです。
次に、「train」フォルダを確認できます-いくつかの新しいファイルが含まれているはずです:
~$ cd train ~/train$ ls train.fr train.ids40000.fr dev.ids40000.en dev.ids40000.fr train.en train.ids40000.en vocab40000.fr
vocab4000を調べることが重要です。*そしてtrain.ids40000。*ファイル。 それは雰囲気があり、誠実でなければなりません、見てください:
~/train$less vocab40000.en _PAD _GO _EOS _UNK . ' , I ? you the to s a t it of You ! that ...
ファイルの各行は、ソースデータで見つかった一意の単語です。 ソースデータの各単語は、このファイルの行番号を表す番号に置き換えられます。 PAD(0)、GO(1)、EOS(2)、UNK(3)などの技術用語があることがすぐにわかります。 このコードでマークされた単語の数(3)により、辞書のサイズを正しく選択する方法がわかるため、おそらく最も重要なのは「UNK」です。
ではtrain.ids40000.enを見てみましょう:
~/train$ less train.ids40000.en 1181 21483 4 4 4 1726 22480 4 7 251 9 5 61 88 7765 7151 8 7 5 27 11 125 10 24950 41 10 2206 4081 11 10 1663 84 7 4444 9 6 562 6 7 30 85 2435 11 2277 10289 4 275 107 475 155 223 12428 4 79 38 30 110 3799 16 13 767 3 7248 2055 6 142 62 4 1643 4 145 46 19218 19 40 999 35578 17507 11 132 21483 2235 21 4112 4 144 9 64 83 257 37 788 21 296 8 84 19 72 4 59 72 115 1521 315 66 22 4 16856 32 9963 348 4 68 5 12 77 1375 218 7831 4 275 11947 8 84 6 40 2135 46 5011 6 93 9 359 6370 6 139 31044 4 42 5 49 125 13 131 350 4 371 4 38279 6 11 22 316 4 3055 6 323 19212 6 562 21166 208 23 3 4 63 9666 14410 89 69 59 13262 69 4 59 155 3799 16 1527 4079 30 123 89 10 2706 16 10 2938 3 6 66 21386 4 116 8 ...
これはinput.enからのデータであると既に推測したと思いますが、すべての単語は辞書に基づいたコードに置き換えられています。 これで、「不明」(UNK / 3)としてマークされている単語の数を確認できます。
~/train$ grep -o ' 3 ' train.ids40000.en | wc -l 7977
その後の実験で、辞書のサイズを40kから45k、さらには最大50kまで増やすことができます。 しかし、「現状のまま」のプロセスを継続し、それを中断しません。
6時間後...「生き返った!」
十分な時間待った後、学習プロセスを愚かに殺すことができます。 心配する必要はありません。プロセスは200トレーニングステップごとに結果を保存します(この数は変更できます)。 あなたが待つ準備ができている期間を選択するためにトレーニングをお勧めします(それはあなたが車を借りるために支払うつもりの金額に依存するかもしれません)、またはあなたがトレーニングプロセスを完了させたいステップの数です。
この混乱を整理した最後の最も重要なことは、チャットを開始することです。 これを行うには、トレーニングに使用したチームに1つのキーを追加するだけです。
~/src/tensorflow/tensorflow/models/rnn/translate$ python ./translate.py --en_vocab_size=40000 --fr_vocab_size=40000 --data_dir=/home/ubuntu/train --train_dir=/home/ubuntu/train --decode ... Reading model parameters from /home/ubuntu/data/translate.ckpt-54400 > Hello! Hello . > Hi are you? Now , okay . > What is your name? My name is Sir Sir . > Really? Yeah . > what about the real name? N . . . real real . > are you a live? Yes . > where are you? I ' m here . > where is here? I don ' t know . > can I help you to get here? Yeah , to I ve ' t feeling nothing to me .
これはほんの始まりです! ボットを改善するためのアイデアをいくつか紹介します。
プロジェクトを支援したり、キャラクターを使ってボットを作成したりするには、次のことができます。
- EN / FR辞書に最適なサイズを見つけるロジックを実装します。
- train.en / train.frをどこかに公開して、他の人が最初から作成しないようにします。
- ボットマスターヨーダ(またはダースベイダー)を訓練します。
- 「ロードオブザリング」の宇宙のように、話すボットを訓練する。
- 「スターウォーズ」宇宙の人々のように話すボットを訓練します。
- 彼があなたのように話すことができるように、彼の対話でボットを訓練してください!