この投稿では、システムのアーキテクチャ、約3年間の進化的開発、および開発速度、生産性、コスト、シンプルさのトレードオフについて説明します。
単純化されたタスクは次のようになりました-インターネット経由でマイクロコントローラーをモバイルアプリケーションに接続する必要があります。 例-アプリケーションでボタンを押すと、マイクロコントローラーのLEDが点灯します。 マイクロコントローラーのLEDを消灯し、アプリケーションのボタンがそれに応じてステータスを変更します。
プロジェクトをキックスターターで開始してから、実稼働環境でサーバーを起動する前に、5,000人というかなりのベースの最初のユーザーがすでにいました。 おそらくあなたの多くは、多くのWebリソースが過去に置いた有名なhabr効果について聞いたことがあるでしょう。 もちろん、この運命を繰り返したくはありませんでした。 したがって、これは技術スタックとアプリケーションアーキテクチャの選択に反映されました。
発売直後、私たちのアーキテクチャ全体は次のように見えました。

1か月あたり80ドル(4 CPU、8 GB RAM、80 GB SSD)の1台のDigital Ocean仮想マシンでした。 余裕を持って撮影。 「負荷がかかったらどうなりますか?」 それから私たちは本当にそう思ったので、始めましょう。何千人ものユーザーが急いでくれます。 結局のところ、ユーザーを引き付けて誘惑することは、他のタスクとサーバーの負荷です-最後に考えることです。 当時の技術のうち、SSL / TCPソケットに独自のバイナリプロトコルを備えたJava 8とNettyしかありませんでした(はい、データベースなし、春、冬眠、tomcat、websphere、その他の血まみれの企業の魅力)。
すべてのユーザーデータは単にメモリに保存され、定期的にファイルにダンプされました。
try (BufferedWriter writer = Files.newBufferedWriter(fileTo, UTF_8)) { writer.write(user.toJson()); }
サーバーを上げるプロセス全体が1行になりました。
java -jar server.jar &
打ち上げ直後のピーク負荷は40川秒でした。 本当の津波は決して起こらなかった。
それにもかかわらず、私たちは一生懸命働き、絶えず新しい機能を追加し、ユーザーからのフィードバックを聞きました。 ユーザーベースは、ゆっくりではあるが着実に、そして毎月5-10%増加し続けています。 サーバーの負荷も増加しました。
最初の主要な機能はレポートでした。 実装を開始した時点で、システムの負荷はすでに1か月あたり10億リクエストに達していました。 さらに、ほとんどの要求は温度センサーなどの実際のデータでした。 すべてのリクエストを保存することは非常に高価であることは明らかでした。 だから、私たちはトリックに行きました。 各リクエストを保存する代わりに、メモリ内の平均値を詳細な粒度で計算します。 つまり、1分以内に数値10と20を送信した場合、この分の出力は値15になります。
最初は誇大広告に屈して、このアプローチをApache Sparkに実装しました。 しかし、配備に関しては、シープスキンはろうそくに値しないことに気付きました。 当然、それは「正しい」「企業」でした。 しかし今では、居心地の良いモノリシックの代わりに2つのシステムを展開して監視する必要がありました。 さらに、データのシリアル化と送信のためにオーバーヘッドが追加されました。 一般的に、スパークを取り除き、メモリ内の値をカウントし、それを1分ごとにディスクにダンプします。 出力は次のようになります。
単一サーバーのモノリスシステムは問題なく機能しました。 しかし、明らかな欠点がありました。
- サーバーはニューヨークにあるため、たとえばアジアなどの遠隔地では、アプリケーションをインタラクティブに使用するときに遅延が視覚的に表示されていました。 たとえば、スライダーを使用してランプの輝度レベルを変更したとき。 重要なことは何もありませんでしたし、ユーザーの誰も文句を言っていませんでしたが、私たちは世界を変えています。
- デプロイにはすべての接続を切断する必要があり、サーバーは再起動するたびに約5秒間使用できませんでした。 開発のアクティブフェーズでは、1か月あたり約6回の展開を行いました。 面白いのは、このような再起動のすべての時間において、サーバーが利用できないことに気付いたユーザーが一人もいないということです。 つまり、再起動は非常に高速(hello springおよびtomcat)であったため、ユーザーはまったく気付きませんでした。
- 1つのサーバーの障害、データセンターがすべてを敷き詰めました。
発売から8か月後、新機能のストリームは少し眠くなり、私はこの状況を変える時間ができました。 タスクは簡単でした。異なる地域の遅延を減らし、同時にシステム全体が落ちるリスクを減らしました。 まあ、すべてをすばやく、簡単に、安く、最小限の労力で行います。 結局のところ、スタートアップ。
2番目のバージョンは次のとおりです。
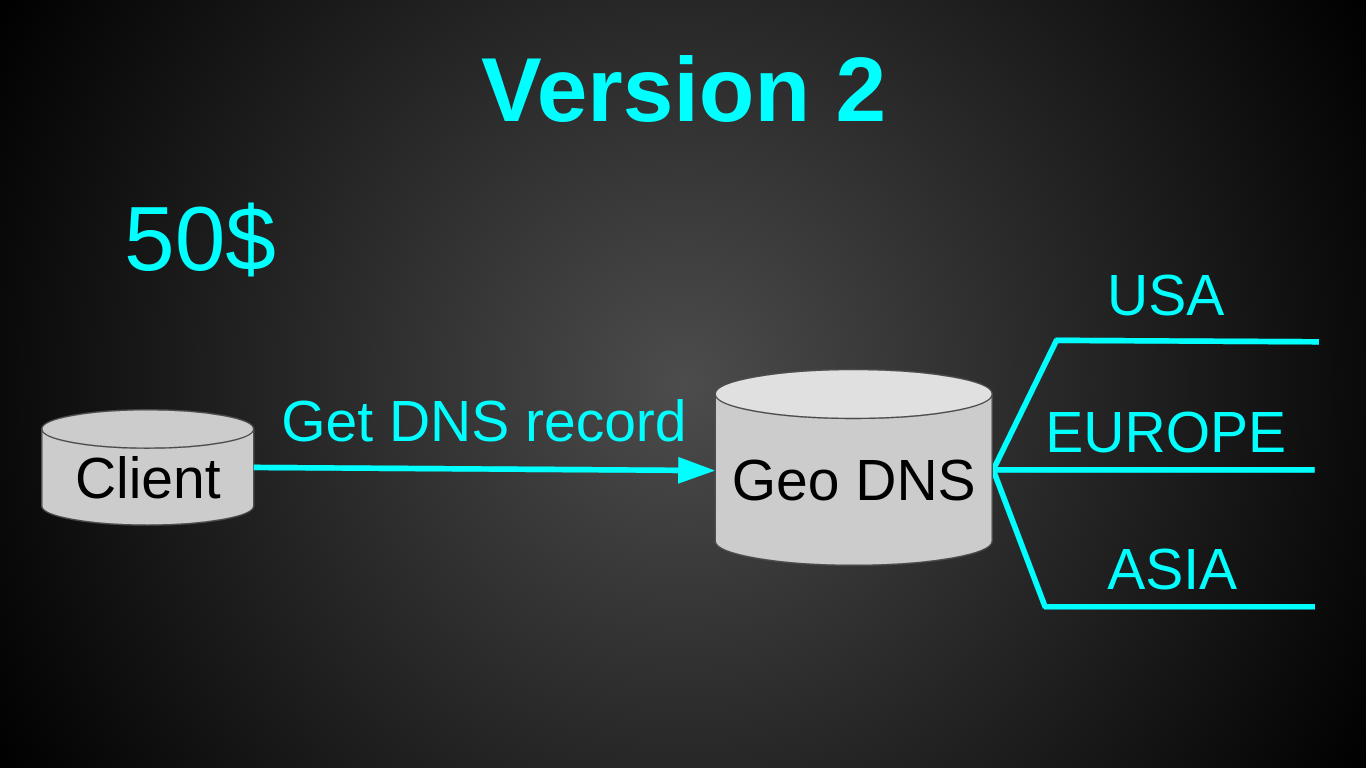
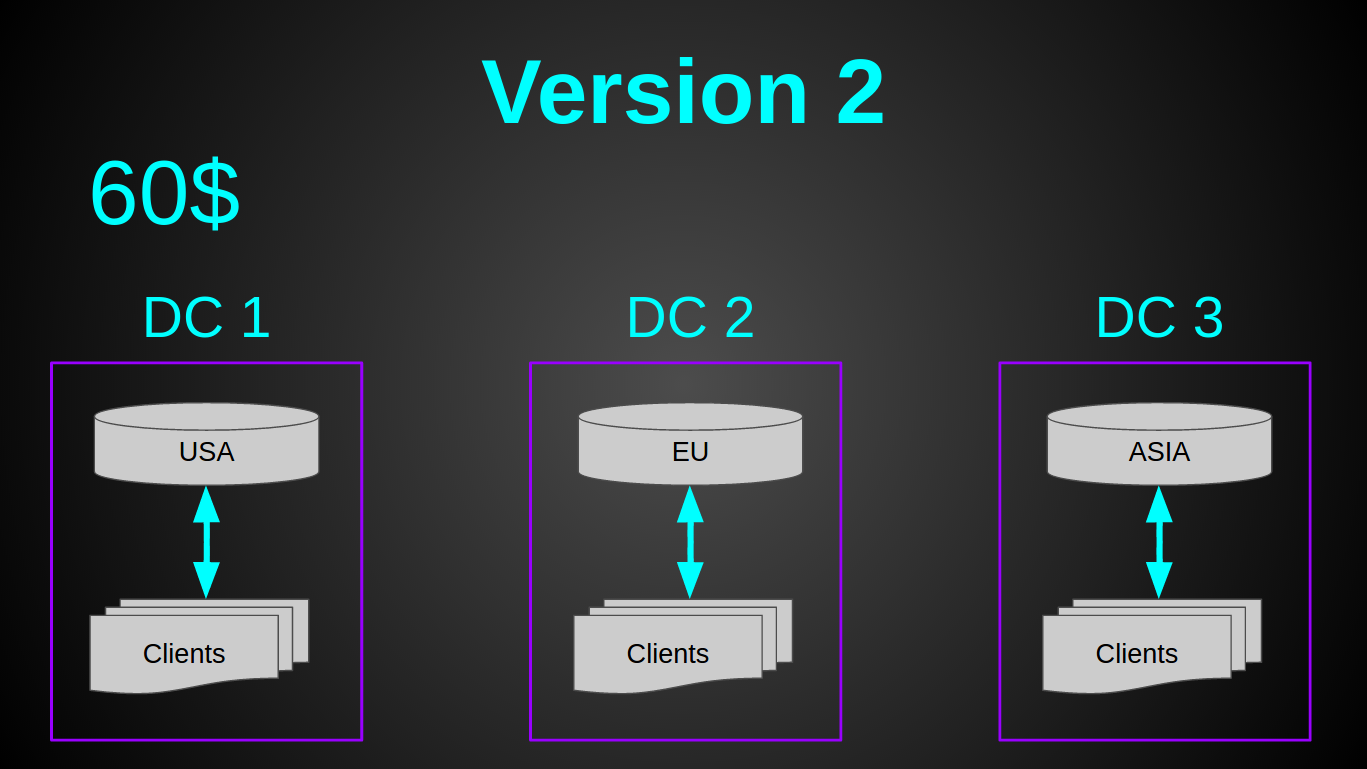
おそらくお気づきのように-GeoDNSを選択しました。 これは非常に迅速な決定でした-Amazon Route 53での30分間のセットアップ全体を読み取り、設定しました。 かなり安い-AmazonのGeo DNSルーティングには月50ドルかかります(もっと安い代替品を探していましたが、見つかりませんでした)。 とても簡単です-ロードバランサーは必要なかったからです。 そして、最小限の労力で済みます-コードを少し準備するだけで済みました(1日もかかりませんでした)。
現在、20ドル(3 CPU、2 GB RAM、40 GB SSD)+ Geo DNSで50ドルの3つのモノリシックサーバーがありました。 システム全体の月額は110ドルでしたが、価格が20ドル安くなるため、コアが2つ増えました。 新しいアーキテクチャへの移行時点では、負荷は2000川秒でした。 また、以前の仮想マシンは6%しかロードされていませんでした。
上記のモノリスの問題はすべて解決しましたが、新しい問題が発生しました-人が別のゾーンに移動すると、別のサーバーに移動し、何も機能しませんでした。 これは意図的なリスクであり、私たちはそれを受け入れました。 動機は非常に単純です-ユーザーは支払いません(その時点ではシステムは完全に無料でした)。 また、統計によると、アメリカ人のうち人生で少なくとも一度は30%しか出国せず、定期的に移動するのは5%だけです。 したがって、この問題はごく一部のユーザーにしか影響しないことが示唆されました。 予測は実現しました。 平均して、「プロジェクトがなくなったユーザーから2〜3日で約1通の手紙を受け取りました。 どうする セーブ!」 時間が経つにつれて、そのような手紙は非常に迷惑になり始めました(ユーザーのためにこれをすばやく修正する方法に関する詳細な指示にもかかわらず)。 さらに、そのようなアプローチは、私たちが切り替え始めたばかりのビジネスにはほとんど適さないでしょう。 何かをする必要がありました。
問題を解決するための多くのオプションがありました。 これを行う最も安価な方法は、1つのサーバーにマイクロコントローラーとアプリケーションを送信することです(1つのサーバーから別のサーバーにメッセージを送信する際のオーバーヘッドを回避するため)。 一般に、新しいシステムの要件は次のようになりました。1人のユーザーの異なる接続は1つのサーバーに移動する必要があり、ユーザーの接続先を知るには、そのようなサーバー間の共有状態が必要です。
私はこのタスクに完全に合ったカッサンドラについて多くの良いレビューを聞きました。 したがって、私はそれを試してみることにしました。 私の計画は次のようになりました。
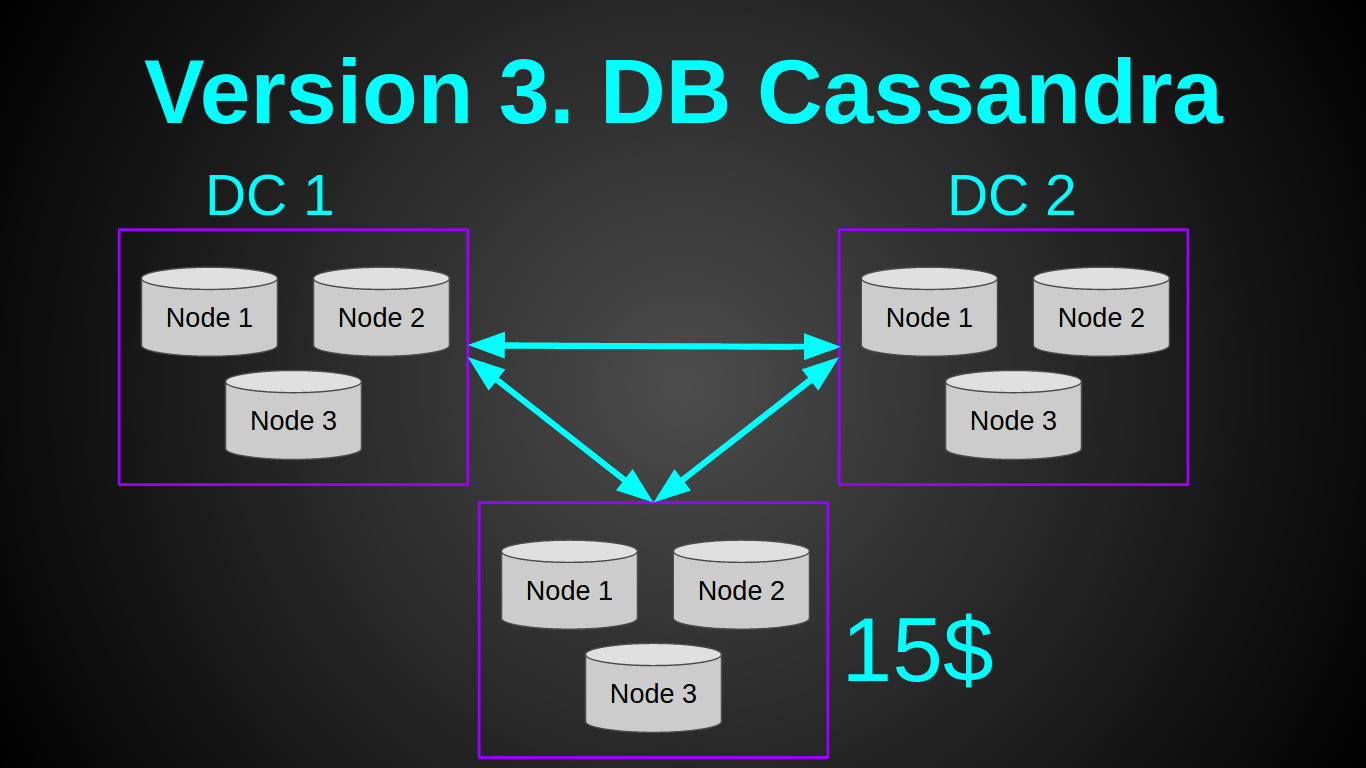
はい、私は悪党であり、素朴なチュクチの若者です。 5ドルのDO-512 MB RAM、1 CPUから、最も安価な仮想マシンでcassandraノードを1つ上げることができると考えました。 また、Rasp PIでクラスターを作成した幸運な人の記事も読みました。 残念ながら、私は彼の偉業を繰り返すことができませんでした。 記事で説明されているように、すべてのバッファを削除/トリミングしましたが。 1 GBのインスタンスでのみ1つのcassandraノードを上げることができましたが、10リバー秒の負荷でノードはすぐにOOM(OutOfMemory)から落ちました。 Cassandraは、2GBでほぼ安定して動作しました。 1つのキャッサンダーノードの負荷を1000リバー秒に増やすことはできませんでした。 この段階で、私はcasandraを放棄しました。たとえそれが立派なパフォーマンスを示したとしても、1つのデータセンターの最小クラスターのコストは60年代になるからです。 当時の収入が0ドルであることを考えると、私にとっては高額でした。 昨日それをする必要があったので、私は計画Bに進みました。
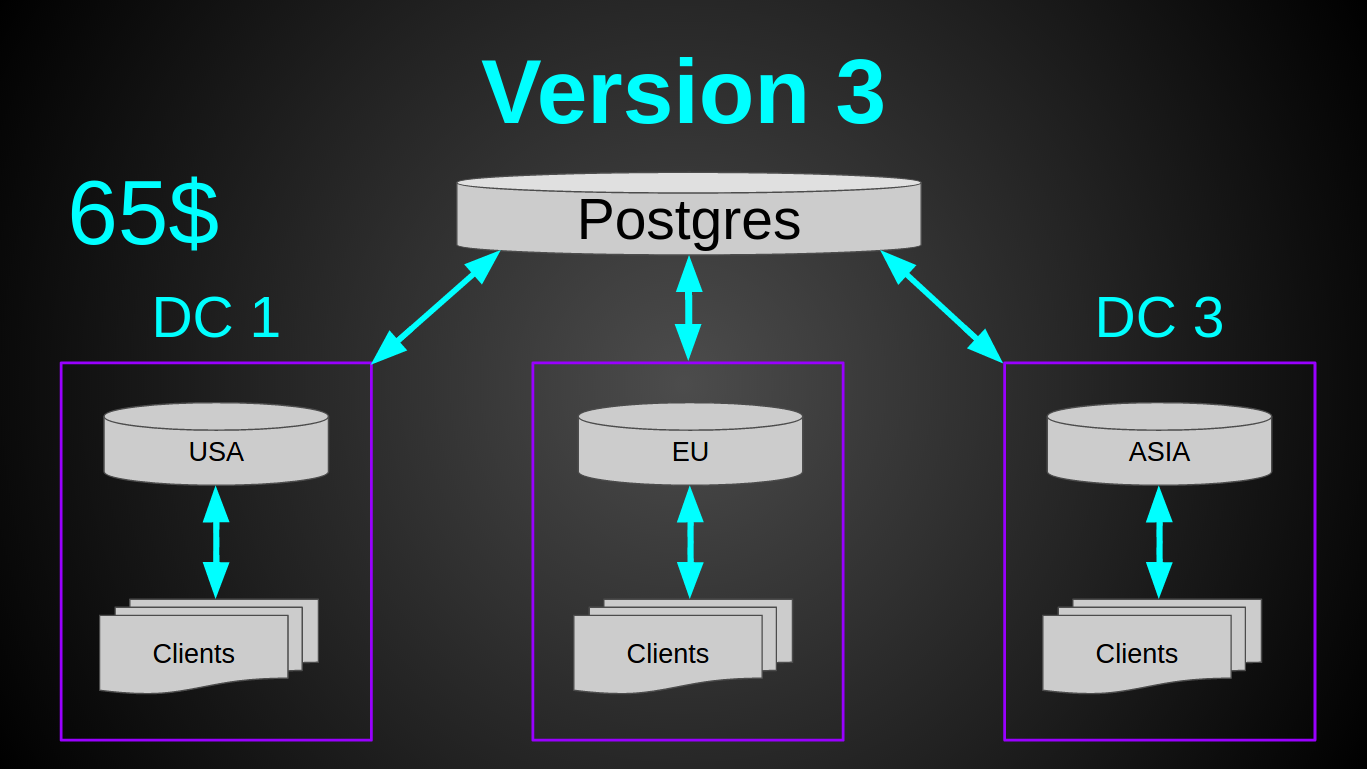
古き良きpostgres。 彼は私を決して失望させませんでした(大丈夫、ほとんどない、はい、完全な真空?)。 Postgresは最も安価な仮想マシンで完全に実行され、RAMをまったく消費せず、バッチで5000行を挿入するのに300ミリ秒かかり、10%のコアのみをロードしました。 必要なもの! データベースを各データセンターに展開するのではなく、1つの共通ストレージを作成することにしました。 postgresのスケーリング/シャード/マスター/スレーブは同じcasandraよりも難しいため。 そして、安全性のマージンがそれを可能にしました。
ここで、クライアントとそのマイクロコントローラーを同じサーバーに送信するという別の問題を解決する必要がありました。 本質的に、tcp / ssl接続とバイナリプロトコルに対してスティッキーセッションを作成します。 既存のクラスターを大幅に変更したくないので、Geo DNSを再利用することにしました。 これは、モバイルアプリケーションがGeo DNSからIPアドレスを受信すると、接続を開き、そのIPを介してログインを送信するというアイデアでした。 次に、サーバーは、ログインコマンドを処理し、「正しい」サーバーである場合はクライアントとの連携を続けるか、接続先のIPを示すリダイレクトコマンドを返します。 最悪の場合、接続プロセスは次のようになります。
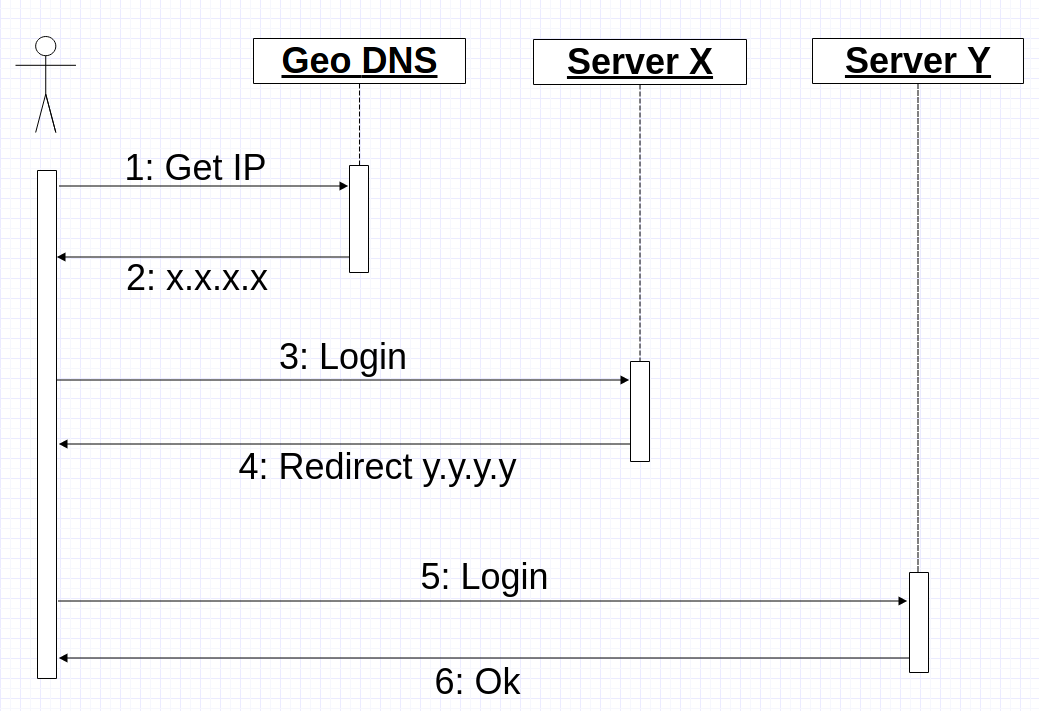
しかし、1つの小さなニュアンスがありました-負荷。 実装時のシステムは、すでに4,700河川/秒を処理していました。 〜3k個のデバイスが常にクラスターに接続されていました。 時々10kが接続されました。 つまり、現在の1年の成長率では、1万リバー秒になります。 理論的には、多くのデバイスが同じサーバーに同時に接続されている場合(たとえば、再起動時、ランプアップ期間)に状況が発生する可能性があり、突然すべてが「間違った」サーバーに接続された場合、データベースへの負荷が大きくなりすぎる可能性があります彼女の失敗。 したがって、私はそれを安全にプレイすることに決め、user-serverIPに関する情報を大根に伝えました。 最終的なシステムは次のとおりです。
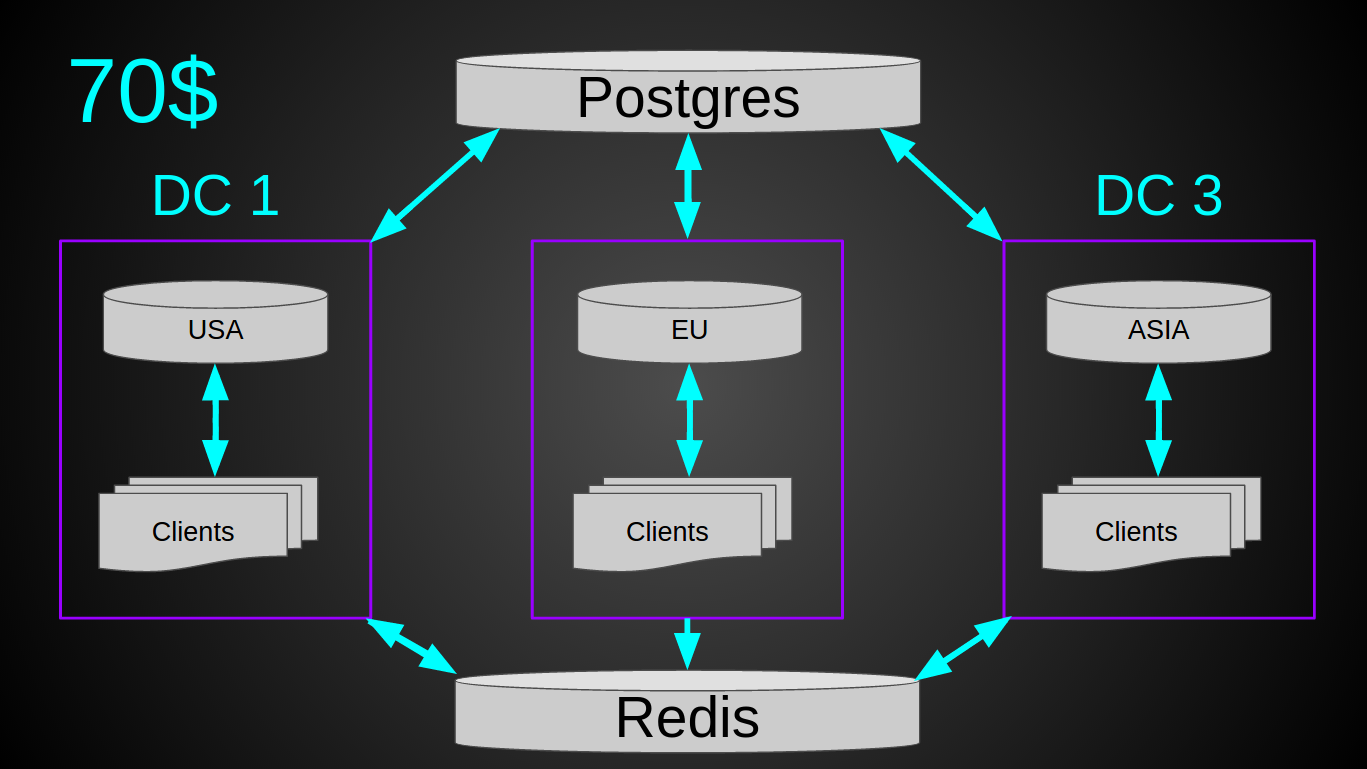
毎月120億の河川の現在の負荷では、システム全体に平均10%の負荷がかかります。 ネットワークトラフィック〜5 Mbps(シンプルなプロトコルのおかげで、イン/アウト)。 つまり、理論的には、120ドルのこのようなクラスターは、最大40kのリバー秒に耐えることができます。 利点-ロードバランサーは必要ありません。単純な展開、保守、監視は非常に原始的です。垂直方向に2桁成長する可能性があります(現在の鉄の使用により10倍、より強力な仮想マシンにより10倍)。
オープンソースプロジェクト。 ここでソースを見ることができます。
実際、それがすべてです。 記事をお楽しみください。 建設的な批判、アドバイス、質問を歓迎します。