
量子化されたレナが注目を集める
たとえば、古き良きGIF形式では、最大256色のパレットが使用されます。 一連の自撮りをgifアニメーション(必要な人)として保存する場合、最初に行うこと、またはこれに使用するプログラムを実行する必要があります-パレットを作成します。 Webセーフカラーなどの静的パレットを使用できますが、量子化アルゴリズムは非常にシンプルかつ高速ですが、結果は「それほどではない」ことになります。 画像の色に基づいて最適なパレットを作成できます。これにより、元の画像と最も視覚的に類似した結果が得られます。
最適なパレットを作成するためのアルゴリズムはいくつかあり、それぞれに長所と短所があります。 読者を退屈な理論や式で悩ませることはありません。第一に私は怠け者であり、第二にほとんどは興味がありません-彼らは単に写真を見て記事をめくるだけです。
次に、中央値セクションの方法、Floyd-Steinbergによるエラー(量子化ノイズ)を分散するアルゴリズム(だけでなく)、人間の目の色知覚の特異性、少しの
背景
むかしむかし、ノキアが暖かくてランプに支配されたスマートフォン市場であり、スマートフォン所有者が誇らしげに自分を「スマートフォン」と呼んだとき、私はその昔、series60用の簡単なpythonプログラムを書きました。 先日、アーカイブを掘り当てました。 GifTool-一連の画像からgifアニメーションを作成するためのプログラム。 その中で、中央セクション法、LZW圧縮アルゴリズムを使用して量子化を実装し、ファイル構造全体を独立して作成し、最終ファイルサイズを削減するために次のスライドの変更されていないピクセルに透明度を使用しました。 私は自分の記憶をリフレッシュしたかったのです。 私はコードを開いて... 10歳のたわごとを理解できないときの気持ちです。 当時はPEP8について知らなかったので、コードの可読性は少し劣っていました(そして、多くの初心者プログラマーのように、ミニマリズムが好きでした)。 彼は泣き、吐き出し、PyCharmでリファクタリングし、中央分離法をどのように実装したかを考え出し、すぐに「ダーティ」スクリプトを投げました。 動作します! パレットが作成され、出力イメージは許容されます。 そして、私は噛まれました-視覚的に元の写真にできるだけ近くなるように、より良い結果を達成できますか?
だから-中央値法。 彼は恥をかきやすい。 最初のステップは、画像内のすべての一意の色からRGBキューブを作成することです。 次に、最も長い辺に沿って切り取ります。 たとえば、7〜231(長さ231-7 = 224)の赤、32〜170(長さ170-32 = 138)の緑、12〜250(長さ250-12 = 238)の青の範囲があります。青い側の立方体を「カット」します。 結果のセグメントも長辺などに沿ってカットされます。 256セグメントを取得するまで。 各セグメントについて、平均色を計算します-これがパレットの取得方法です。
わかりやすくするために、ほとんどトピックになっている写真 
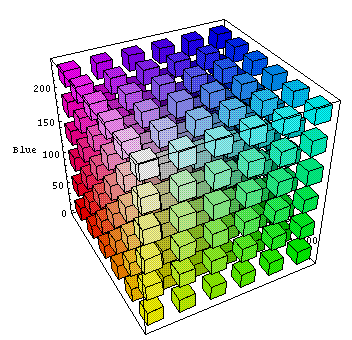
ここで何を改善できますか? 最初に頭に浮かぶのは、愚かにもすべての色を追加せずに[合計(色)/カウント(色)]で割ることによって平均色を計算することです。ただし、画像に各色が何回現れるかを考慮します。 つまり、各色に画像内の出現回数を掛け、得られた値を加算し、結果をこのセグメント内のすべての色の画像内の出現回数で除算します[合計(色*合計)/合計(合計)]。 その結果、最も一般的な色が計算で優先されますが、まれな色も調整を行うため、パレットが優れており、視覚的な色の偏差が小さくなっています。 最良の結果を得るには、色域を考慮することが依然として望ましいですが、私は後でそれを残しました。 2番目はそれほど明白ではありません-中央値セクションは、人間の目による色知覚の特性をまったく考慮していません。 緑の色合いは青の色合いよりもはるかによく知覚されます。 この誤解を修正することを決定し、立方体を「平坦化」しました。 この記事の係数を辺の長さに掛けました。 その結果、緑と赤の側面に多くのセクションがあり、青にはありません。 私はどこかでそのような解決策に出会ったことはありませんでした(たぶん見た目が悪い)が、結果は明らかです。
今では最適なパレットがありますが、もちろん完璧ではありません(まだ改善できることはわかっています)が、十分です。 次のステップは、画像の色のインデックス付けです。 最も簡単なオプション-どのセグメントが色で、そのようなインデックスです。 早くて簡単。 しかし、あるのは1つであり、1つでもないので、このステップに戻ります。
結果の画像の品質を改善する別の方法があります-エラー分散。 ここでも、すべてが非常に単純です-インデックス付きの色からパレットから対応する色を減算し、エラーを取得し、特定の式(テンプレート)に従って隣接するピクセルによってそれを散布します。最も有名なフロイド-スタインバーグ式、私はそれを使用しました。 エラーを分散させると、色間の急激な変化がぼやけ、視覚的には画像に多くの陰影(色)が含まれているように見えます。 興味深い場合は、エラー分散についての詳細をここで読むことができます 。 また、このアルゴリズムを終了し、エラーにすべて同じ係数を乗算することを決定しました。これは非常に良いアイデアでした-青い範囲のセクションが少ないため、大きなエラーが発生し、係数でエラーを修正せずに、散乱は多くのノイズを発生させました「。
これで、再びインデックス作成に戻ることができます。 エラーを拡散することで、ピクセルの色を変更し、RGBキューブにないピクセルを取得します(イメージカラーのみで構成されていることを思い出してください)。 インデックスを割り当てるために、色がどのセグメントにあるかだけを見ることができなくなりました。 解決策はすぐに見つかりました- パレットで最も近い色を見つけました 。 この式では、すべて同じ係数を代入しました。 パレットの色を選択した結果と、元の色を含むセグメントのインデックス、および最も近い色の検索結果を比較すると、最も近い色が多くの場合隣接するセグメントに表示されることがわかりました。 ソースカラーがセグメントの中心に近い場合、セグメントインデックスはパレットのカラーインデックスに対応しますが、ソースカラーがセグメントのエッジに近いほど、最も近い色が隣接するセグメントにある可能性が高くなります。 一般に、正しいインデックスパスは、パレットで最も近い色を見つけることです。 しかし、検索にはマイナスがあります-それは遅く、非常に遅いです。 pythonグラインダーを書くのは悪い考えです。
さて、私は一言で説明したかったのですが、奇妙な文章がたくさんありました。 私が書いたコードが説明よりも良いことを願っていますので、ここにgithubへのリンクがあります。 コードは数回書き直され、最初はアルゴリズムが改善されて満足のいく結果が得られましたが、写真を処理するときにRAMを大量に消費することが判明しました(最初に小さな写真でテストしました)。 sqlite)。 スクリプトの動作は非常に遅くなりますが、結果はPIL / PillowおよびGIMPを使用した量子化よりも優れています(この操作はインデックス付けと呼ばれます)。
視覚的なデモンストレーション:
オリジナル

256色の最適なパレットであるGIMPでの量子化の結果+フロイド-ステンベルクによる色のぼけ(通常)

PIL /枕の量子化結果

コードによる量子化の結果

注目すべき点:GIMPのエラー分散は非常に「ノイズが多い」ため、PIL / Pillowは最適ではないパレットを作成し、実際にはエラー(色間の急激な遷移)を拡散しません。
違いが分からない場合は、 githubの他の例をご覧ください。
256色の最適なパレットであるGIMPでの量子化の結果+フロイド-ステンベルクによる色のぼけ(通常)
PIL /枕の量子化結果
image.convert(mode='P', dither=PIL.Image.FLOYDSTEINBERG, palette=PIL.Image.ADAPTIVE, colors=256)
コードによる量子化の結果
注目すべき点:GIMPのエラー分散は非常に「ノイズが多い」ため、PIL / Pillowは最適ではないパレットを作成し、実際にはエラー(色間の急激な遷移)を拡散しません。
違いが分からない場合は、 githubの他の例をご覧ください。
PS:このタスクをより良く、より速く処理する素晴らしいプログラムColor Quantizerがあります。そのため、私のスクリプトには実用的な意味はなく、「スポーツ」にのみ関心があります。
UPD: githubのプロジェクトを更新しました。 Octree量子化アルゴリズム(octreeツリー)、一般的なエラー分散式を追加し、赤の平均値で最も近い色を検索します。