
良いニュースは、興味深いタスクがどこでも私たちを取り囲んでいることです。 強い欲望と勇気のある仕事は、目標への道のりを驚かせます-どんな規模の仕事でもあなたの強みになります、ちょうどそれを始めてください。
最近、1Cクエリ言語パーサーとその通常のSQLへの変換プログラムを作成しました。 これにより、1Cの参加なしに1Cへのリクエストを処理することができました:)正規表現の最小作業バージョンは2週間でした。 別の月は、文法を通じて本格的なパーサーに費やされ、さまざまな1Cオブジェクトのデータベース構造のニュアンスを引き出し、特定の演算子と関数を実装しました。 その結果、ソリューションはほぼすべての言語構成をサポートし、ソースコードはGitHubに投稿されます 。
カットの下で、なぜそれが必要なのか、どのようにしてそれが可能になったのかを説明し、興味深い技術的な詳細にも触れます。
どのようにすべてが始まりましたか?
私たちは大規模な会計会社Buttonで働いています。 1005人のクライアント、75人の会計士、11人の開発者がいます。 当社の会計士は、
 会計士の仕事で最も難しい段階は報告です。 1Cはレポートを作成できるように見えますが、そのためにはデータベースの現在の状態が必要です。 誰かがすべての主要な文書をシステムに入力し、銀行取引明細書をインポートし、必要な会計文書を作成して実施する必要があります。 さらに、私たちの最愛の州での報告の締め切りは厳密に制限されているため、会計士は通常、眠れない時間のプレッシャーから別のプレッシャーに生きています。
会計士の仕事で最も難しい段階は報告です。 1Cはレポートを作成できるように見えますが、そのためにはデータベースの現在の状態が必要です。 誰かがすべての主要な文書をシステムに入力し、銀行取引明細書をインポートし、必要な会計文書を作成して実施する必要があります。 さらに、私たちの最愛の州での報告の締め切りは厳密に制限されているため、会計士は通常、眠れない時間のプレッシャーから別のプレッシャーに生きています。
会計士はどうすれば人生を楽にすることができるのだろうと考えました
会計ベースの軽微なエラーが原因で、多くのレポートの問題が発生することが判明しました。
- 取引相手または契約の複製。
- 一次文書の複製;
- TINのない取引相手;
- 遠い過去または未来の日付を含むドキュメント。
 リストされた問題は、1Cクエリ言語を使用して簡単に見つけることができるため、クライアントデータベースの自動監査を行うというアイデアが浮上しました。 私たちはいくつかのリクエストを書き、すべての1Cベースで毎晩それらを実行し始めました。 Googleの便利なプレートで会計士に発見された問題を示し、あらゆる可能な方法でプレートを空にしておくことを求めました。
リストされた問題は、1Cクエリ言語を使用して簡単に見つけることができるため、クライアントデータベースの自動監査を行うというアイデアが浮上しました。 私たちはいくつかのリクエストを書き、すべての1Cベースで毎晩それらを実行し始めました。 Googleの便利なプレートで会計士に発見された問題を示し、あらゆる可能な方法でプレートを空にしておくことを求めました。
標準のCOM API 1Cを介してこれらの要求を実行することはお勧めできません。 まず、約1,000個のデータベースを取得し、各データベースですべてのクエリを実行するには10時間かかります。 第二に、それは1Cサーバーを大幅にロードします。これは通常、甘くはありません。 監査のために、現在の人々の日々の仕事を遅くすることは不快です。
一方、典型的な1Cリクエストは次のようになります。
select doc. as Date, doc. as Number, doc.. as Inn, doc.. as CounterpartyInn, (doc..) as CounterpartyType, doc. as Description, doc. as Sum from . doc where not doc.. and doc. and doc. = (..) and (doc.) = (&Now)
SQLに非常に似ているという事実にもかかわらず、そのようなことはデータベースを直接取得して実行するだけでは機能しません。
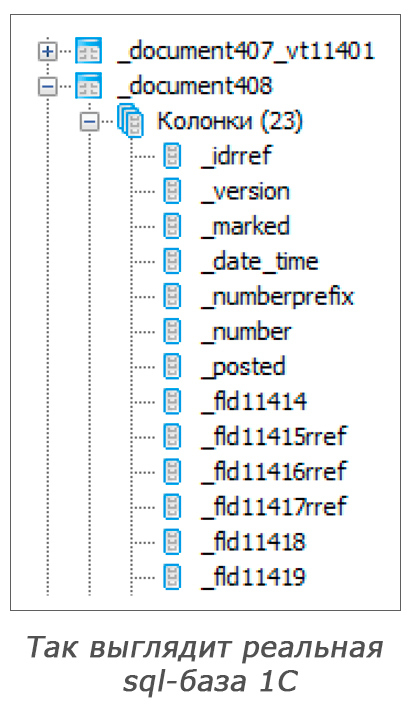 これには、3つの本当の理由があります。
これには、3つの本当の理由があります。
- データベース内のテーブルと列のマジックネーム。 これは、 1Cが要求からの名前への対応を文書化するため、簡単に解決されます。
- ネストされたプロパティ。 たとえば、SQLの
doc..
はleft join
2つのテーブル.
todoc..
と.
のleft join
対応しています。 -
,
などの1C固有の演算子と関数 。 また、適切なDBMS設計にさらに変換する必要があります。
これをすべて実現したので、1C方言からのクエリを通常のSQLに変換し、すべての物理PostgreSQLサーバーで並列に実行し、結果を結合してMS SQLの別のテーブルに入れるユーティリティを作成しました。 その結果、データ収集時間は10時間から3分に短縮されました。
正規表現
最初のバージョンでは、リクエスト変換ロジックを完全に正規表現で実装しました。 COM API 1Cには、データベースのGetStorage構造関数があります。 1Cクエリのオブジェクトとプロパティに対応するテーブルとフィールドに関する情報を返します。 いくつかの正規表現テンプレートを使用して、ある名前を別の名前に置き換えました。 オブジェクトとプロパティへのすべての呼び出しにエイリアスがあれば、これは非常に簡単に実現できました。
すべての面倒のほとんどは、添付プロパティによって提供されました。 1Cはそれらを関連テーブルに格納するため、
from
構造内のオブジェクトの元の名前を、必要なすべての
left join-
が存在するサブクエリに置き換える必要
left join-
。
リクエスト例
select doc.. from . doc -- select doc.gen0 from (select tContractor.inn gen0 from tDoc left join tContractor on tDoc.contractorId = tContractor.id) doc
プロパティの名前を変更し、左
join
を生成することに加えて、トランスレーターは多くの変換を使用しました。 そのため、たとえば、元のクエリのすべての
join
は、フィールド
(area)
等価性に関する追加条件を提供する必要がありました。 事実、1つのPostgreSQLデータベースには複数の1Cクライアントデータベースがあり、1つのクライアントのデータは、1Cがregionと呼ぶ特別な識別子によって別のクライアントのデータと異なります。 データベースでは、1Cは一連のデフォルトインデックスを作成します。 すべての要求は同じクライアント内で実行されるため、キーの最初のコンポーネントであるすべてに領域があります。 クエリが標準インデックスを使用し、それらを記述するときに考慮しないために、クエリをブロードキャストするときにこの条件を自動的に追加し始めました。
正規表現を使用することが正しい決定であることが判明しました 。これにより、最終結果を迅速に取得し、この事業全体から何か有用なものが得られたことを理解できるからです。 この方法で、最も簡単に利用できる手段で、概念と実験の証明を行うことをすべての人に推奨します。 そして、正規表現よりもテキストを扱うとき、より簡単で効果的なものは何ですか?
もちろん、欠点もあります。 最初の明白なことは、コーナーの切り取りと構文の制限です。 プロパティとテーブルの正規表現はクエリでエイリアスを必要とし、一般に、たとえば定数文字列など、他の構成要素に誤って追いつく可能性があります。
別の問題は、テキスト解析ロジックの混乱と、必要なルールに従ったその変換です。 毎回、新しい機能を実装するとき、正規表現と行の
IndexOf
呼び出しを組み合わせた新しい地獄のようなものを発明する必要がありました。これにより、元のリクエストの対応する要素が分離されます。
そのため、たとえば、すべてのjoinにドメインの等価性の条件を追加するコードが見えました。
private string PatchJoin(string joinText, int joinPosition, string alias) { var fromPosition = queryText.LastIndexOf("from", joinPosition, StringComparison.OrdinalIgnoreCase); if (fromPosition < 0) throw new InvalidOperationException("assertion failure"); var tableMatch = tableNameRegex.Match(queryText, fromPosition); if (!tableMatch.Success) throw new InvalidOperationException("assertion failure"); var mainTableAlias = tableMatch.Groups[3].Value; var mainTableEntity = GetQueryEntity(mainTableAlias); var joinTableEntity = GetQueryEntity(alias); var condition = string.Format("{0}.{1} = {2}.{3} and ", mainTableAlias, mainTableEntity.GetAreaColumnName(), alias, joinTableEntity.GetAreaColumnName()); return joinText + condition; }
コードでは、
ColumnReference
と
JoinClause
を
ColumnReference
、元のリクエストのオブジェクトモデルを処理したかったのですが、リクエストテキストの正規表現で見つかったサブストリングとオフセットのみがありました。
このオプションは、前のオプションよりもはるかにシンプルで理解しやすいように見えることに同意します。
private void PatchJoin(SelectClause selectClause, JoinClause joinClause) { joinClause.Condition = new AndExpression { Left = new EqualityExpression { Left = new ColumnReferenceExpression { Name = PropertyNames.area, Table = selectClause.Source }, Right = new ColumnReferenceExpression { Name = PropertyNames.area, Table = joinClause.Source } }, Right = joinClause.Condition }; }
このようなオブジェクトモデルは、 抽象構文ツリー ( AST )と呼ばれます 。
AST
興味深いことに、元のクエリを解析したときではなく、SQLで結果をフォーマットするときに、ASTが初めて表示されました。 事実は、ネストされたプロパティのサブクエリを構築するためのロジックは非常に洗練されたものであり、それを簡素化するために(そしてSRPに従って)、プロセス全体を2つの段階に分割しました:最初にサブクエリを記述するオブジェクトのツリーを作成し、次にSQLで個別にシリアル化します。 ある時点で、これがASTであることに気付きました。正規表現の問題を解決するには、元のリクエストに対して作成する方法を学ぶ必要があります。
ASTという用語は 、解析のニュアンスを議論するために広く使用されています。 このデータ構造は、通常、再帰性とループがないという特性を備えたプログラミング言語に典型的な構造をよく説明するため、 ツリーと呼ばれます(ただし、これは常に当てはまるわけではありません )。
たとえば、次のクエリを検討してください。
select p.surname as 'person surname' from persons p where p.name = ''
ASTの形式では、次のようになります。

図では、ノード-クラスのインスタンス、矢印、および署名-これらのクラスのプロパティ。
このようなオブジェクトモデルは、次のようにコードを介してアセンブルできます。
var table = new TableDeclarationClause { Name = "PersonsTable", Alias = "t" }; var selectClause = new SelectClause { FromExpression = table, WhereExpression = new EqualityExpression { Left = new ColumnReferenceExpression { Table = table, Name = "name" }, Right = new LiteralExpression { Value = "" } } }; selectClause.Fields.Add(new SelectFieldExpression { Expression = new ColumnReferenceExpression { Table = table, Name = "surname" } });
上記のASTの例が唯一の正しい例ではないことに注意してください。 クラスの特定の構造とクラス間の関係は、タスクの詳細によって決まります。 ASTの主な目標は 、問題の解決を促進し、典型的な操作のパフォーマンスを可能な限り便利にすることです。 したがって、目的の言語の構造を記述するのがより簡単で自然であればあるほど良いです。
正規表現からASTへの移行により、多くのハックを取り除き、コードをよりわかりやすく理解しやすくすることができました。 同時に、今や私たちのユーティリティは、ソース言語のすべての構成について知っていて、ツリーに適切なノードを作成する必要があります。 これを行うには、クエリ言語1Cの文法とそのためのパーサーを作成する必要がありました。
文法
そのため、ある時点で、元のリクエストのASTが必要であることが明らかになりました。 インターネットにはSQLを解析してASTを作成できる多くのライブラリがありますが、よく見ると、それらは有料であるか、SQLのサブセットのみをサポートしていることがわかります。 さらに、SQLの1C方言の認識にそれらをどのように適合させるかは明確ではありません。
そのため、独自のパーサーを作成することにしました。 パーサーは通常、認識したい言語の文法を記述することから始めます。 形式文法は、プログラミング言語の構造を記述するための古典的なツールです。 これは、推論のルール、つまり各言語構造の再帰的な定義に基づいています。
たとえば、これらのルールは算術式の言語を記述できます。
E → number | (E) | E + E | E - E | E * E | E / E
このようなレコードは、次のように読み取ることができます。
- 任意の数値
(number)
は式(E)
です。 - 式が角かっこで囲まれている場合、角かっこと共にこれもすべて式です。
- 算術演算で接続された2つの式も式を構成します。
出力規則が定義されているシンボルは、非終端記号と呼ばれます。 ルールが定義されておらず、言語の要素であるシンボル- ターミナル 。 ルールを適用すると、非端末から、端末のみが残るまで、他の非端末と端末で構成される文字列を取得できます。 上記の例では、
E
は非終端記号であり、文字
+, -, *, /
、および
number
は、算術式の言語を形成する終端記号です。
特別なツールがあります-パーサージェネレーターは、文法の形式で指定された言語の説明に従って、この言語を認識するコードを生成できます。 それらの中で最も有名なのは、 yacc 、 bison 、およびantlrです。 C#用の一般的ではないIronyライブラリがあります。 Habréには彼女に関する小さな記事が既にありましたが、 Scott Hanselmanが彼女について投稿しています。
Ironyライブラリの主な機能は、演算子のオーバーロードを使用して、文法規則を
C#
直接記述できることです。 結果は、ルールを記述する古典的な形式に非常に類似した形式の、非常に素晴らしいDSLです。
var e = new NonTerminal("expression"); var number = new NumberLiteral("number"); e.Rule = e + "+" + e | e + "-" + e | e + "*" + e | e + "/" + e | "(" + e + ")" | number;
シンボル| は、任意のルールオプション(論理OR)を適用できることを意味します。 +記号は連結であり、文字は互いに続く必要があります。
アイロニーは、 解析ツリーと抽象構文ツリーの概念を分離します。 解析ツリーは、文法規則の一貫した適用の結果であるテキスト認識プロセスの成果物です。 非終端記号はその内部ノードに配置され、対応するルールの右部分のシンボルは子孫に分類されます。
たとえば、ルールを適用するときの式
1+(2+3)
:
e 1 : E→E + E
e 2 : E→(E)
e 3 : E→番号
このような解析ツリーに対応します。

Parse Treeは言語に依存せず、単一の
ParseTreeNode
クラスによってIronyで記述されます。
反対に、 抽象構文ツリーは特定のタスクによって完全に決定され、このタスクに固有のクラスとそれらの間の関係で構成されます。
たとえば、上記の文法のASTは、1つの
BinaryOperator
クラスのみで構成される場合があります。
public enum OperatorType { Plus, Minus, Mul, Div } public class BinaryOperator { public object Left { get; set; } public object Right { get; set; } public OperatorType Type { get; set; } }
Left
プロパティと
Right
プロパティは
object
型です。 数値または別の
BinaryOperator
参照できます。

アイロニーを使用すると、文法のルールを適用しながら、葉から根に向かって順番にASTを作成できます。 これを行うには、各非
AstNodeCreator
デリゲートを
AstNodeCreator
できます。この非端末に関連付けられたルールのいずれかが適用されたときにIronyが呼び出します。 このデリゲートは、送信された
ParseTreeNode
基づいてそれに対応するASTノードを作成し、
ParseTreeNode
リンクを戻す
ParseTreeNode
ます。 デリゲートが呼び出されるまでに、Parse Treeのすべての子ノードは既に処理されており、
AstNodeCreator
はすでに呼び出されているため、デリゲートの本文では、既に読み込まれている子ノードの
AstNode
プロパティを使用できます。
このようにルート
AstNode
に到達すると、ASTルートノードが
AstNode
、この場合は
SqlQuery
で形成されます。
上記の算術式の文法では、AstNodeCreatorは次のようになります。
var e = new NonTerminal("expression", delegate(AstContext context, ParseTreeNode node) { // E → number, if (node.ChildNodes.Count == 1) { node.AstNode = node.ChildNodes[0].Token.Value; return; } // E → E op E if (node.ChildNodes[0].AstNode != null && node.ChildNodes[2].AstNode != null) { node.AstNode = new BinaryOperator { Left = node.ChildNodes[0].AstNode, Operator = node.ChildNodes[1].FindTokenAndGetText(), Right = node.ChildNodes[2].AstNode }; return; } // node.AstNode = node.ChildNodes[1].AstNode; });
そのため、Ironyの助けを借りて、最初の要求に応じてASTを構築する方法を学びました。 最終的な分析では、結果のSQLクエリASTをソースASTから取得する必要があるため、AST変換用のコードを効率的に構造化する方法は1つだけです。 Visitorパターンはこれに役立ちます。
訪問者
Visitor (またはdouble dispatch )パターンはGoFで最も複雑なパターンの1つであり、したがって、おそらくほとんど使用されないパターンの1つです。 私たちの経験では、さまざまなASTの変換のために、1つのアクティブな使用しか見ていません。 具体的な例は、.NETのExpressionVisitorクラスです。これは、 linqプロバイダーを実行する場合、またはコンパイラーによって生成された式ツリーをわずかに修正する場合に必ず発生します。
訪問者はどのような問題を解決しますか?
ASTで作業するときによくしなければならない最も自然で必要なことは、ASTを文字列に変換することです。 たとえば、ASTを取り上げます。ロシアのテーブル名を英語に置き換え、
left join-
を生成し、1C演算子をデータベース演算子に変換した後、PostgreSQLで実行するために送信できる文字列を出力で取得する必要があります。
この問題の可能な解決策は次のとおりです。
internal class SelectClause : ISqlElement { //... public void BuildSql(StringBuilder target) { target.Append("select "); for (var i = 0; i < Fields.Count; i++) { if (i != 0) target.Append(","); Fields[i].BuildSql(target); } target.Append("\r\nfrom "); From.BuildSql(target); foreach (var c in JoinClauses) { target.Append("\r\n"); c.BuildSql(target); } } }
このコードについて、次の2つの重要な点を確認できます。
- 再帰を機能させるには、ツリーのすべてのノードに
BuildSql
メソッドが必要です。 -
BuildSql
メソッドは、すべての子ノードでBuildSql
を呼び出します。
次に、別のタスクを検討します。 PostgreSQLインデックスを取得するために、メインテーブルと結合されたすべてのフィールドの
area
フィールドの等価条件を追加する必要があるとします。 これを行うには、リクエスト内のすべての
JoinClause
を確認する必要がありますが、可能性のあるサブクエリを考えると、他のすべてのノードを確認する必要があります。
これは、上記と同じコード構造に従う場合、次のことを行う必要があることを意味します。
- ツリーのすべてのノードに
AddAreaToJoinClause
メソッドを追加します。 -
JoinClause
を除くすべてのノードでの実装は、子孫に呼び出しを転送する必要があります。
このアプローチの問題は明らかです。ツリー上でさまざまな論理操作を行うほど、ノードに存在するメソッドが増え、これらのメソッド間でコピーアンドペーストが増えます。
訪問者はこの問題を次の方法で解決します 。
- 論理演算はノード上のメソッドではなくなりますが、個別のオブジェクト
SqlVisitor
抽象クラスの継承者になります(次の図を参照)。 - 各ノードタイプは、
VisitSelectClause(SelectClause clause)
やVisitJoinClause(JoinClause clause)
など、ベースSqlVisitor-
個別のVisit
メソッドに対応しています。 -
BuildSql
およびAddAreaToJoinClause
は、1つの一般的なAccept
メソッドに置き換えられます。 - 各ノードは、パラメーターとして提供される
SqlVisitor-
の対応するメソッドに転送することで実装します。 - 具体的な操作は
SqlVisitor
から継承され、興味のあるメソッドのみを再定義します。 - ベース
SqlVisitor-
のVisit
メソッドの実装は、すべての子ノードのVisit
を呼び出すだけで、コードの重複を排除します。
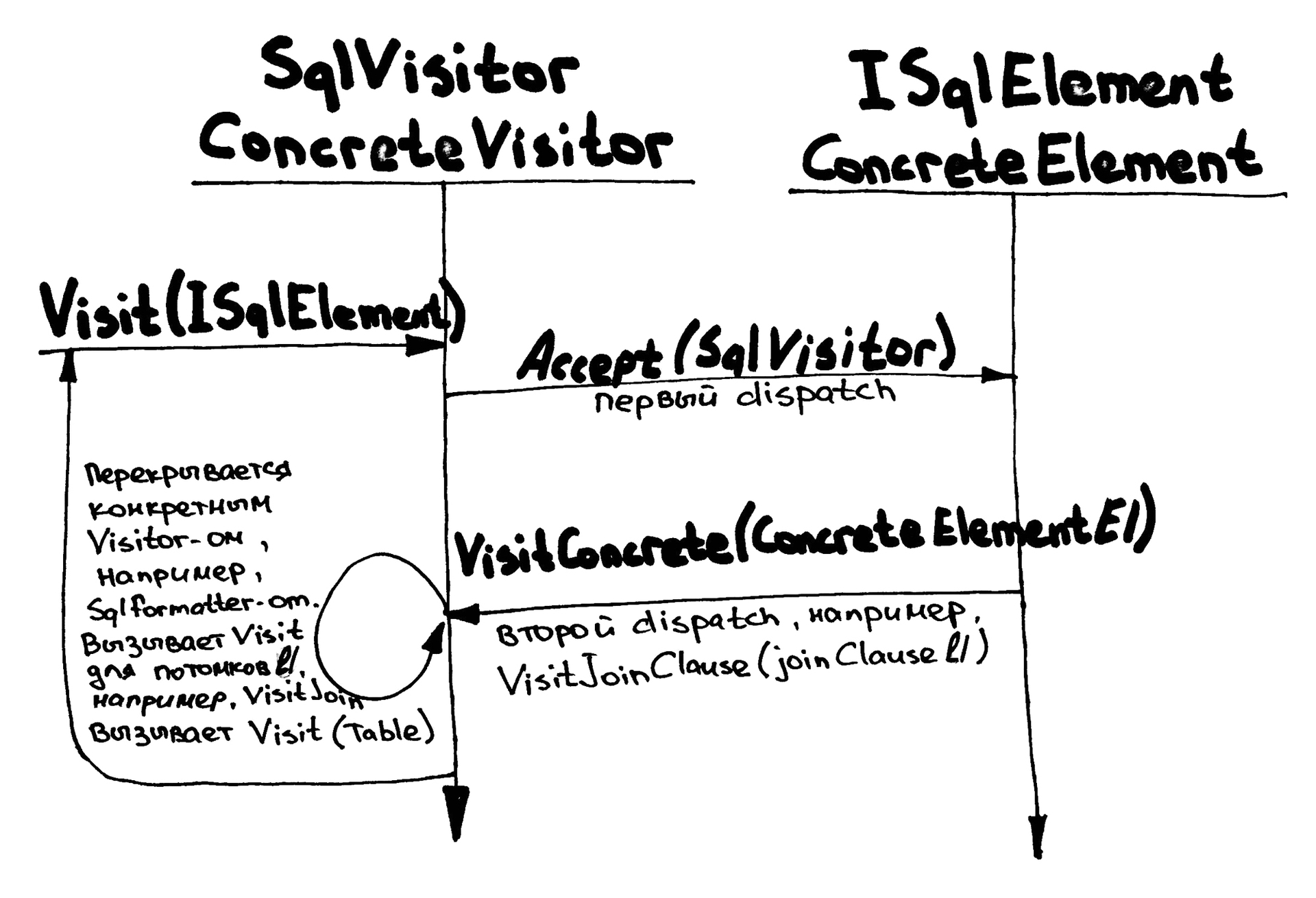
SQLのシリアル化の例は、次のように適合します。
internal interface ISqlElement { void Accept(SqlVisitor visitor); } internal class SqlVisitor { public virtual void Visit(ISqlElement sqlElement) { sqlElement.Accept(this); } public virtual void VisitSelectClause(SelectClause selectClause) { } //... } internal class SqlFormatter : SqlVisitor { private readonly StringBuilder target = new StringBuilder(); public override void VisitSelectClause(SelectClause selectClause) { target.Append("select "); for (var i = 0; i < selectClause.Fields.Count; i++) { if (i != 0) target.Append(","); Visit(selectClause.Fields[i]); } target.Append("\r\nfrom "); Visit(selectClause.Source); foreach (var c in selectClause.JoinClauses) { target.Append("\r\n"); Visit(c); } } } internal class SelectClause : ISqlElement { //... public void Accept(SqlVisitor visitor) { visitor.VisitSelectClause(this); } }
ダブルディスパッチという名前は、このスキームを非常に正確に説明しています。
- 最初のディスパッチは、特定のノードで
Visit
からAccept
に切り替えるときにSqlVisitor
クラスで発生します。この時点で、ノードのタイプがSqlVisitor
れます。 - ノードの
Accept
からSqlVisitor
特定のメソッドに切り替えると、2番目のディスパッチが最初に続きます。ここで、選択したノードに適用する必要がある操作がSqlVisitor
ます。
合計
この記事では、クエリ言語1Cの翻訳者をSQLクエリに準備するためのレシピについて詳しく説明しています。 正規表現を使った実験を行って、実用的なプロトタイプを取得し、そのものが有用であり、先に進む価値があることを確認しました。 そして、恥ずかしさと苦痛なしにコードを見ることが不可能になり、正規表現とジャグリングしても望ましい結果が得られなかったとき、私たちは深刻な一歩を踏み出しました-ASTと文法に切り替えました。 さらに、訪問者の助けを借りて、ASTを変換する方法を学びました。これにより、ある言語から別の言語への翻訳のロジックを実現しました。
私たちが一人でこのように行かず、 ドラゴンブックを開く必要さえなかったことは注目に値します。 ASTの解析と構築には、完成したIronyライブラリを使用しました。これにより、車輪を再発明するのではなく、適用された問題の解決にすぐに進むことができました。
会社の実際の結果は、データの受信速度を10時間から3分に短縮することです。 これにより、アナリストは、クライアントのビジネスと会計士の仕事に関する仮説を迅速に実験し、テストすることができました。 多くのクライアントがあり、それらのデータベースは5つの物理PostgreSQLサーバーに分散されているため、これは特に便利です。
上記のすべてを要約します。
- 実験を行い、可能な限り迅速かつ安価に概念実証を取得します。
- 野心的な目標を設定し、小さなステップでそれらに向かって進み、徐々に機器を目的の状態に仕上げます。
- ほとんどのタスクには、既製のソリューション、または少なくとも基盤が既にあります。
- 解析と文法は、通常のビジネスアプリケーションに適用できます。
- 特定の問題を解決すると、一般的な解決策が自動的に得られます。
ライブラリコードと使用例がGitHubでお待ちしています 。
余暇には、以下を読むことをお勧めします。