 Visual Studioの新バージョンの機能に関する記事では、主な技術革新の1つ(私の観点から)は、開発環境(devenv.exe)の以前のモノリシックプロセスを個別のプロセスで動作するコンポーネントに分離することでした。 これは、バージョン管理システム(libgitからgit.exeに移行)および一部のプラグインで既に実行されており、将来、VSの他の部分がサブプロセスに送信されます。 この点に関して、コメントで疑問が生じました。「しかし、プロセス間のデータ交換にはIPC( プロセス間通信 )の使用が必要なため、作業が遅くなりますか?」
Visual Studioの新バージョンの機能に関する記事では、主な技術革新の1つ(私の観点から)は、開発環境(devenv.exe)の以前のモノリシックプロセスを個別のプロセスで動作するコンポーネントに分離することでした。 これは、バージョン管理システム(libgitからgit.exeに移行)および一部のプラグインで既に実行されており、将来、VSの他の部分がサブプロセスに送信されます。 この点に関して、コメントで疑問が生じました。「しかし、プロセス間のデータ交換にはIPC( プロセス間通信 )の使用が必要なため、作業が遅くなりますか?」
いいえ、遅くなりません。 そして、ここに理由があります。
スピード
Windowsのプロセス間の通信を整理するためのさまざまなテクノロジーがあります:ソケット、名前付きパイプ、共有メモリ、メッセージング。 上記のすべての本格的なベンチマークを作成したくないので、すぐにHabréに似たものを探し、6年前にadontzがソケットと名前付きパイプのパフォーマンスを比較した記事を見つけましょう。 結果:ソケット-160 MB /秒、名前付きパイプ-755 MB /秒。 同時に、6年前に鉄とテストに使用された.NETプラットフォームを修正する必要があります。 つまり Cなどのコードを備えた最新のハードウェアでは、1秒あたり数ギガバイトになると安全に言えます。 同時に、Wikipediaが示唆しているように、たとえばDDR3メモリの動作速度は、周波数に応じて6400〜19200 MB / sであり、これらは真空での理想的なMB / sであり、実際には常に少なくなります。
結論1 :パイプの速度は、RAMの最大速度よりも数倍遅いだけです。 千倍ではなく、桁違いではなく、数倍です。 最新のOSは、仕事をうまくこなします。
データ量
名前付きパイプの速度として、上記の段落から同じ755 MB / sを使用してみましょう。 それはたくさんですか、それとも少しですか? たとえば、たとえば、名前付きチャンネルから毎秒60フレームのフレームレートで非圧縮FullHDビデオを受信し、それを使用して(エンコードまたはストリーミング)行うアプリケーションを作成した場合、355 MB /と つまり このような非常に高価な操作であっても、名前付きパイプの速度は2倍以上のマージンで十分です。 Visual Studioは、コンポーネントとの通信で何を操作しますか? さて、たとえば、git.exeのコマンドと彼の答えからのデータ。 これらは数キロバイトで、非常にまれなケースである-メガバイトです。 プラグインとのデータ交換を正確に推定することはほとんどできません(非常に異なるプラグインがあります)。 しかし、いずれにせよ、私が見た単一のプラグインは毎秒数百メガバイトを必要としません。
結論2 :Visual Studioで処理されるデータの詳細(テキスト、コード、リソース、画像)を考慮すると、名前付きパイプの速度は複数のマージンで十分です。
待ち時間
大丈夫、あなたは言う、スピード-スピード、しかしレイテンシーもあります。 結局、各操作には同期のために何らかのオーバーヘッドが必要になります。 はい、そうです。 そしてこれについて、最近記事を発表しました 。 ロックと同期のオーバーヘッドを過大評価しています。 そこにある問題はロック自体にはありません(ナノ秒かかります)が、人々は同期コードが貧弱で、デッドロック、 ライブロック、 競合 、共有メモリの損傷を認めているという事実にあります。 幸いなことに、名前付きパイプの場合、 API自体が非同期アプローチの利点を示唆しており、正しく動作するコードを書くことはそれほど難しくありません。
結論3 :非同期/マルチスレッドコードにはバグはありませんが、ロックがあっても非常に迅速に動作します。
実用例
さて、大丈夫、あなたは言う、それは十分な理論です、あなたは実用的な証拠が必要です! そして、我々はそれを持っています。 これは、世界で最も人気のあるデスクトップアプリケーションの1つであるGoogle Chromeブラウザです。 最初にいくつかの相互作用プロセスの形式で作成されたChromeは、このアプローチの利点をすぐに示しました-1つのタブが残りの部分をぶら下げるのを止め、プラグインの終了はブラウザのクラッシュを意味しませんでした。 Chromeは、簡略化すると、1つのメインプロセス、タブのレンダリング、GPUとの対話、プラグインの個別のプロセスを開始します(実際、ルールは少し複雑です。Chromeは異なる状況に応じて子プロセスの数を最適化できますが、これは今ではあまり重要ではありません)。
Chromeのアーキテクチャについてはドキュメントで読むことができますが、簡単な図を次に示します 。
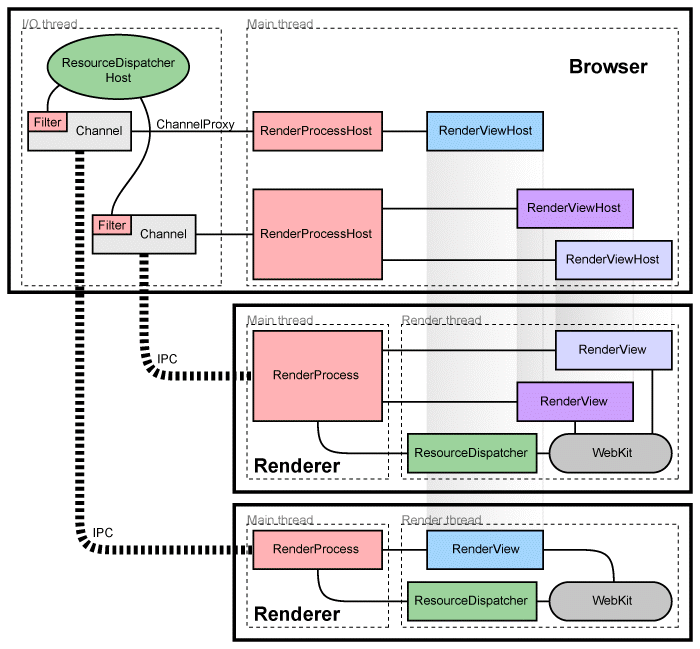
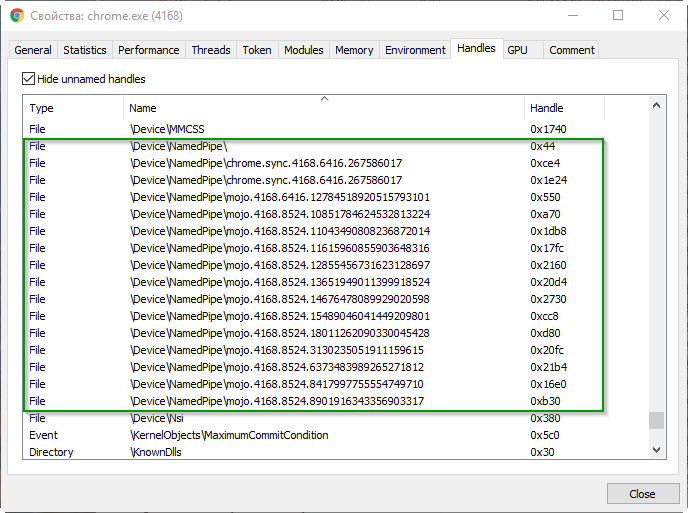
色付きの「ゼブラ」と銘刻文字IPCのある線の下の写真には何が隠されていますか? しかし、名前付きパイプだけが隠れています。 たとえば、 Process Hackerアプリケーション([Handles]タブ)を使用して表示できます。
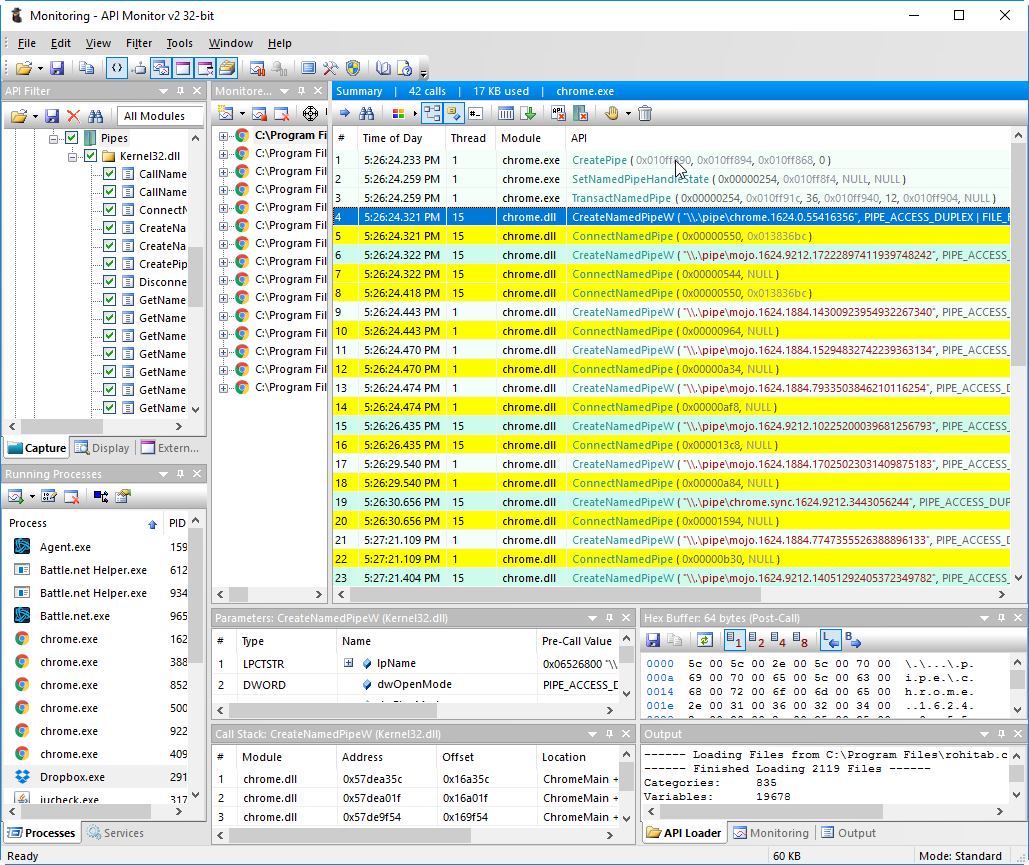
まあ、またはApi Monitorを使用して:
名前付きパイプはどのようにChromeを遅くしますか? あなた自身がこの質問に対する答えを知っています。 マルチプロセスアーキテクチャによりブラウザが高速化され、コア間の負荷分散、プロセスのパフォーマンスの制御、メモリの効率的な使用が可能になります。 たとえば、YouTubeから1分間のビデオを再生するときに、Chromeが名前付きパイプを介して駆動するデータの量を推定してみましょう。 これを行うには、優れたIO Ninjaユーティリティを使用できます(通常、パイプによるデータストリームには、恥ずかしがり、Wireshark、API Monitor、またはSysinternalsユーティリティのいずれも表示されません-残念!):
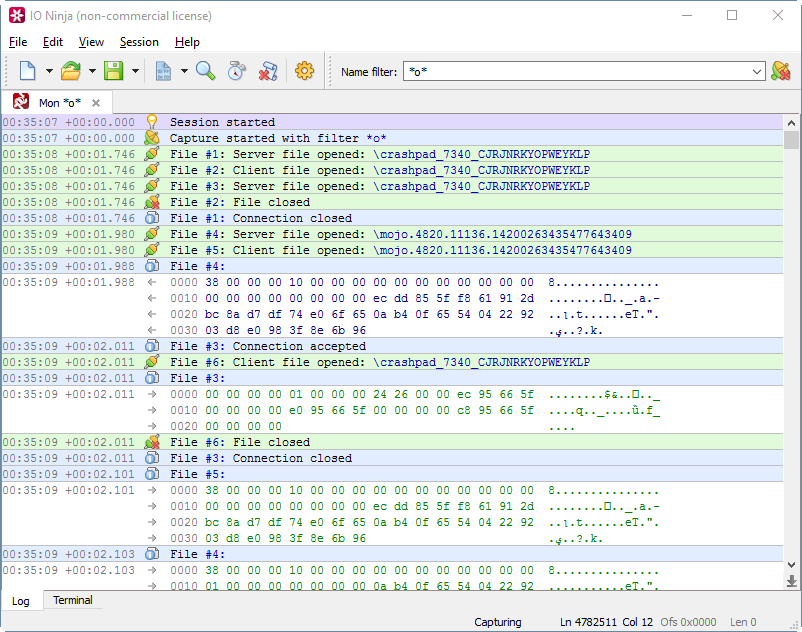
測定では、YouTubeの1分間の再生で、Chromeは名前付きパイプを介して76 MBのデータを転送します。 この場合、79715個の個別の読み取り/書き込み操作が発生しました。 ご覧のとおり、Chromeなどの深刻なプログラムでさえ、YouTubeなどの強力なサイトでさえ、名前付きチャンネルを混乱させませんでした。 そのため、Visual Studioには、モノリシックIDEをサブプロセスに分割することで利益を得るあらゆる機会があります。