
すべてのHabrahabr読者の皆さん、こんにちは。この記事では、Androidプラットフォームでのニューラルネットワーク、およびその結果としてのJavaプログラミング言語を使用した実装の研究における私の経験を共有したいと思います。 私のニューラルネットワークの知識は、Prismaアプリケーションが登場したときに起こりました。 ニューラルネットワークを使用してすべての写真を処理し、選択したスタイルを使用してゼロから複製します。 これに興味を持った私は、まずはHabréの記事と「チュートリアル」を探しました。 そして驚いたことに、ニューラルネットワークの動作のアルゴリズムを段階的に明確に説明した記事は1つも見つかりませんでした。 情報は断片化されており、重要な点が欠けていました。 また、ほとんどの著者は、詳細な説明に頼らずに、1つまたは別のプログラミング言語でコードを表示しようと急いでいます。
したがって、ニューラルネットワークを非常によくマスターし、さまざまな外国のポータルから膨大な量の情報を見つけたので、一連の出版物で人々とこれを共有し、ニューラルネットワークに精通し始めたばかりの場合に必要なすべての情報を収集します。 この記事では、Javaに重点を置くことはせず、すべてを例で説明して、自分でこれを必要なプログラミング言語に転送できるようにします。 後続の記事では、株式や通貨の動きを予測する、Android用に作成されたアプリケーションについて説明します。 言い換えれば、ニューラルネットワークの世界に飛び込み、情報のシンプルでアクセス可能なプレゼンテーションを待ち望んでいる人、または何かを理解せずにそれを引き出したい人だけが猫を歓迎します。
私が最初に発見した最も重要な発見は、アメリカのプログラマー、ジェフヒートンのプレイリストでした。彼は、ニューラルネットワークの動作原理とその分類を詳細かつ明確に分析しました。 このプレイリストを見た後、最も単純な例から始めて、ニューラルネットワークを作成することにしました。 おそらく、新しい言語を習い始めたばかりのとき、最初のプログラムはHello Worldになることをご存知でしょう。 これは一種の伝統です。 機械学習の世界には独自のHello worldもあり、このニューラルネットワークは排他的論理和(XOR)の問題を解決します。 テーブルは排他的であるか、このように見えます
| a | b | c |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
ニューラルネットワークとは
ニューラルネットワークは、シナプスによって相互接続された一連のニューロンです。 ニューラルネットワークの構造は、生物学から直接プログラミングの世界に入りました。 この構造のおかげで、マシンはさまざまな情報を分析し、さらには記憶することができます。 ニューラルネットワークは、着信情報を分析するだけでなく、記憶からそれを再現することもできます。 興味のある方は、TED Talksのビデオ1本 、 ビデオ2をご覧ください。 言い換えると、ニューラルネットワークは人間の脳の機械的解釈であり、電気的インパルスの形で情報を送信する何百万ものニューロンが存在します。
ニューラルネットワークとは
ここまでで、最も基本的なタイプのニューラルネットワークの例を検討します-これは直接配信ネットワーク(以下、SPRと呼びます)です。 また、後続の記事では、より多くの概念を紹介し、リカレントニューラルネットワークについて説明します。 SPRは、その名前が示すように、ニューラルレイヤーのシリアル接続を備えたネットワークであり、その中で、情報は常に一方向にのみ送られます。
ニューラルネットワークとは何ですか?
ニューラルネットワークは、人間の脳が行うことと同様の分析計算を必要とする複雑な問題を解決するために使用されます。 ニューラルネットワークの最も一般的なアプリケーションは次のとおりです。
分類 -パラメーターによるデータの分布。 たとえば、入り口で人々のセットが与えられ、誰にクレジットを与えるか、誰にクレジットを与えないかを決定する必要があります。 この作業は、ニューラルネットワークによって実行でき、年齢、支払能力、信用履歴などの情報を分析します。
予測とは、次のステップを予測する機能です。 たとえば、株式市場の状況に基づいた株式の上昇または下落。
認識は現在、ニューラルネットワークの最も幅広いアプリケーションです。 写真を探しているときや携帯電話のカメラで、顔の位置を特定して強調表示するなど、Googleが使用します。
ここで、ニューラルネットワークの仕組みを理解するために、そのコンポーネントとそのパラメーターを見てみましょう。
ニューロンとは何ですか?
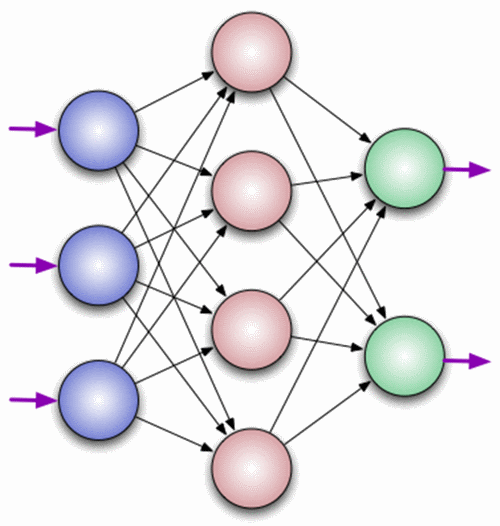
ニューロンは、情報を受け取り、その情報に対して簡単な計算を実行し、それを渡すコンピューティングユニットです。 これらは、入力(青)、非表示(赤)、出力(緑)の3つの主なタイプに分けられます。 また、ディスプレイスメントニューロンとコンテキストニューロンもあります。これらについては、次の記事で説明します。 ニューラルネットワークが多数のニューロンで構成される場合、レイヤーという用語が導入されます。 したがって、情報を受け取る入力レイヤー、それを処理するn個の隠しレイヤー(通常は3つ以下)、および結果を表示する出力レイヤーがあります。 各ニューロンには、入力データ(入力データ)と出力データ(出力データ)の2つの主要なパラメーターがあります。 入力ニューロンの場合:入力=出力。 残りの部分では、前の層からのすべてのニューロンの合計情報が入力フィールドに入り、その後、活性化関数を使用して正規化され(現時点ではf(x)を想像してください)、出力フィールドに入ります。
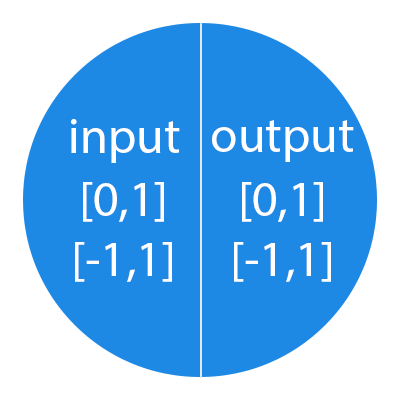
ニューロンは[0,1]または[-1,1]の範囲の数値で動作することを覚えておくことが重要です。 しかし、あなたが尋ねると、この範囲外の数字を処理しますか? この段階で最も簡単な答えは、1をこの数で割ることです。 このプロセスは正規化と呼ばれ、ニューラルネットワークで非常に頻繁に使用されます。 これについては後で詳しく説明します。
シナプスとは何ですか?

シナプスは、2つのニューロン間の接続です。 シナプスには1つのパラメーター(重量)があります。 彼のおかげで、あるニューロンから別のニューロンに送信されるときに入力情報が変化します。 次へ情報を送信する3つのニューロンがあるとします。 次に、これらのニューロンのそれぞれに対応する3つの重みがあります。 より多くの重みを持つニューロン、その情報は次のニューロンで支配的です(たとえば、色の混合)。 実際、ニューラルネットワークの重みのセットまたは重みのマトリックスは、システム全体の一種の脳です。 これらのスケールのおかげで、入力情報が処理され、結果に変わります。
ニューラルネットワークの初期化中に、重みがランダムな順序で配置されることを覚えておくことが重要です。
ニューラルネットワークはどのように機能しますか?
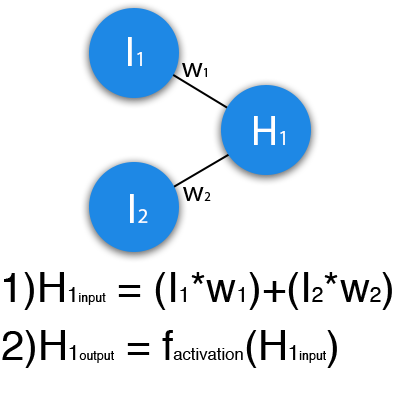
この例では、ニューラルネットワークの一部が示されています。文字Iは入力ニューロンを示し、文字Hは隠れニューロンを示し、文字wは重みを示します。 この式は、入力情報がすべての入力データの合計に対応する重みを乗算したものであることを示しています。 次に、入力に1と0を指定し、w1 = 0.4とw2 = 0.7とすると、ニューロンH1の入力データは1 * 0.4 + 0 * 0.7 = 0.4になります。 入力ができたので、入力値をアクティベーション関数に代入することで出力を取得できます(これについては後で説明します)。 出力ができたので、それを渡します。 そして、出力ニューロンに到達するまで、すべてのレイヤーに対して繰り返します。 このようなネットワークを初めて起動すると、ネットワークがトレーニングされていないため、答えが正しくないことがわかります。 結果を改善するために、私たちは彼女を訓練します。 しかし、これを行う方法を学ぶ前に、ニューラルネットワークのいくつかの用語とプロパティを紹介しましょう。
アクティベーション機能
アクティベーション関数は、入力データを正規化する方法です(これについては既に説明しました)。 つまり、入力に大きな数があり、それをアクティベーション関数に渡すと、必要な範囲の出力が得られます。 アクティベーション関数は多数あるため、最も基本的な関数である線形、シグモイド(ロジスティック)、双曲線正接を検討します。 主な違いは値の範囲です。
線形関数
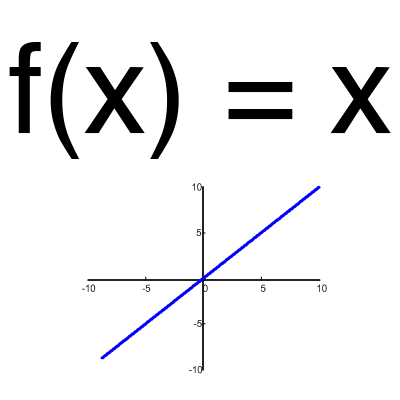
ニューラルネットワークをテストするか、変換せずに値を渡す必要がない限り、この関数はほとんど使用されません。
シグモイド
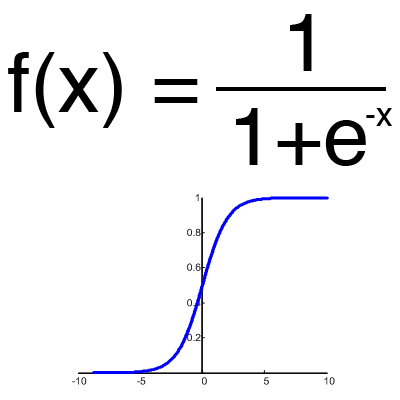
これは最も一般的なアクティベーション関数であり、値の範囲は[0,1]です。 ネットワーク上のほとんどの例を示していますが、ロジスティック関数とも呼ばれます。 したがって、負の値がある場合(たとえば、株価が上昇するだけでなく下降することもある場合)、負の値をキャプチャする関数が必要です。
双曲線正接
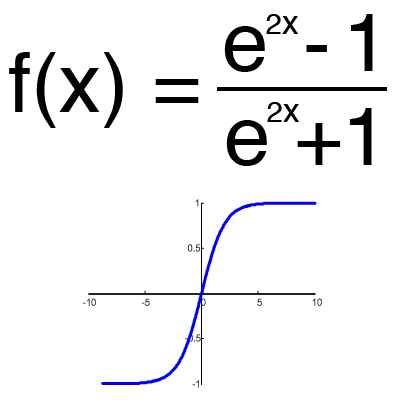
関数の範囲は[-1,1]であるため、値が負と正の両方になり得る場合にのみ双曲線正接を使用するのが理にかなっています。 この関数を正の値でのみ使用すると、ニューラルネットワークの結果が著しく悪化するため、実用的ではありません。
トレーニングセット
トレーニングセットは、ニューラルネットワークによって操作される一連のデータです。 or(xor)を削除する場合、4つの異なる結果しかありません。つまり、4つのトレーニングセットがあります:0xor0 = 0、0xor1 = 1、1xor0 = 1,1xor1 = 0。
反復
これは、ニューラルネットワークが1つのトレーニングセットを通過するたびに増加する一種のカウンターです。 言い換えれば、これはニューラルネットワークによって渡されるトレーニングセットの総数です。
時代
ニューラルネットワークが初期化されると、この値は0に設定され、手動で定義された上限があります。 時代が大きければ大きいほど、ネットワークのトレーニングが向上し、それに応じてその結果が向上します。 時代は、トレーニングセット全体(この場合は4セットまたは4回の反復)を実行するたびに増加します。

反復と時代を混同せず、その増分の順序を理解しないことが重要です。 Nが最初
繰り返しが増加し、時代が増加し、逆も同様です。 つまり、最初に1つのセットのみでニューラルネットワークをトレーニングし、次に別のセットでトレーニングすることはできません。 各セットを時代ごとに1回トレーニングする必要があります。 したがって、計算のエラーを回避できます。
エラー
エラーは、予期される応答と受信された応答の不一致を反映する割合です。 間違いは時代ごとに形成され、減少するはずです。 これが起こらない場合、あなたは何か間違ったことをしている。 エラーはさまざまな方法で計算できますが、3つの主要な方法のみを考慮します。平均二乗誤差(以下、MSE)、ルートMSE、およびArctanです。 アクティベーション機能のように使用に制限はなく、最良の結果をもたらす方法を自由に選択できます。 各メソッドがエラーを異なる方法で考慮することを考慮するだけの価値があります。 アークタンでは、誤差が原則として機能するため、ほとんど常に誤差が大きくなります。差が大きいほど誤差が大きくなります。 ルートMSEのエラーは最小であるため、ほとんどの場合、MSEを使用して、エラーの計算のバランスを維持します。
MSE
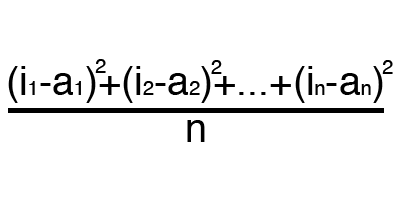
ルートMSE
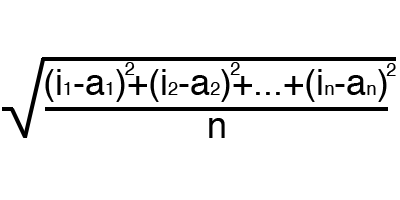
アークタン
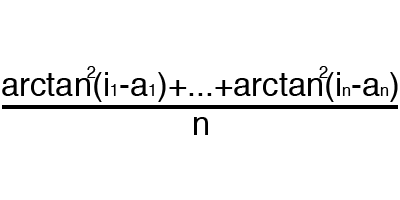
エラー計算の原理は、すべての場合で同じです。 各セットについて、受信した理想的な回答から除外してエラーを検討します。 次に、この差の正接を二乗または計算した後、結果の数をセットの数で除算します。
挑戦する
次に、自分自身をテストするために、シグモイドを使用して特定のニューラルネットワークの結果を計算し、MSEを使用してそのエラーを計算します。
データ:I1 = 1、I2 = 0、w1 = 0.45、w2 = 0.78、w3 = -0.12、w4 = 0.13、w5 = 1.5、w6 = -2.3

解決策
H1input = 1 * 0.45 + 0 * -0.12 = 0.45
H1output =シグモイド(0.45)= 0.61
H2input = 1 * 0.78 + 0 * 0.13 = 0.78
H2output =シグモイド(0.78)= 0.69
O1input = 0.61 * 1.5 + 0.69 * -2.3 = -0.672
O1output =シグモイド(-0.672)= 0.33
O1ideal = 1(0xor1 = 1)
エラー=((1-0.33)^ 2)/1=0.45
結果は0.33、エラーは45%です。
H1output =シグモイド(0.45)= 0.61
H2input = 1 * 0.78 + 0 * 0.13 = 0.78
H2output =シグモイド(0.78)= 0.69
O1input = 0.61 * 1.5 + 0.69 * -2.3 = -0.672
O1output =シグモイド(-0.672)= 0.33
O1ideal = 1(0xor1 = 1)
エラー=((1-0.33)^ 2)/1=0.45
結果は0.33、エラーは45%です。
ご清聴ありがとうございました! この記事が、ニューラルネットワークについて学ぶのに役立つことを願っています。 次の記事では、変位ニューロンと、バックプロパゲーションおよび勾配降下法を使用してニューラルネットワークをトレーニングする方法について説明します。
使用されるリソース:
- タイムズ
-2
-3