Habréでは、ブロック暗号化の新しい国内標準GOST R 34.12 2015「Grasshopper」の少なくとも2倍が言及され 、 ru_cryptは彼の投稿で新しい標準の基本的なメカニズムと変換を調べ、 sebastian_mgは基本的な変換の段階的なトレースに従事しました。 しかし、多くの質問は未回答のままでした。 新しいGOSTの速度はどれくらいですか? ハードウェアの最適化、効率的な実装、高速化は可能ですか?

標準GOST R 34.12 '15について
2015年6月19日の注文番号749により、GOST R 34.12 2015はブロック暗号化の新しい標準として承認されました。この標準は、標準化技術委員会26「暗号情報セキュリティ」によって導入されたInfoTeKS OJSCの参加により、ロシアのFSBの情報セキュリティおよび特別通信センターによって開発されました。 2016年1月1日に発効しました。
標準の公式pdf版をここからダウンロードし、参照実装をここからダウンロードします (両方のリンクはTC 26の公式ウェブサイトにつながります)。
この標準には、2つのブロック暗号の説明が含まれています。ブロック長が64ビットの「Magma」と、ブロック長が128ビットの「Grasshopper」です。 同時に、「Magma」は古い、よく知られているブロック暗号GOST 28147 '89の新しい名前です(実際、まったく新しいものではありません。古いブロック暗号標準が1994年まで開発されたのはこのコード名でした)。 。 「最後に、歴史は私たちに何かを教えてくれました」とあなたは言います、そしてあなたは正しいでしょう。
この記事では、ブロック長が128ビットで、コード名がGrasshopperである別の暗号について説明します。 都市の土地によれば、コードの名前は緑の昆虫とはまったく関係がありませんが、このコードの作者の名前の最初の音節、Kuz'min、Nechaev 、および会社によって形成されます。
バッタの説明
「Grasshopper」と「Magma」の違い
新しい暗号は、古い暗号とは大きく異なり、その主な利点は区別できます
- ブロックの長さの2倍( 128ビット、または16バイト 、
64ビット、または8バイト)、 - 非自明なキースケジュール( Feistelネットワークに対するキースケジュールとして
秘密キーの一部を循環キーとして使用する)、 - サイクル数の削減( 10サイクルに対して
32サイクル)、 - 暗号自体の根本的に異なるデバイス( LSX暗号
Feistelネットワーク)
基本的な変換
暗号はLSX暗号のクラスに属します。その基本的な変換(ブロック暗号化機能)は、連続する変換L (線形変換)、 S (置換)、 X (循環キーとの混合)の10サイクルで表されます。
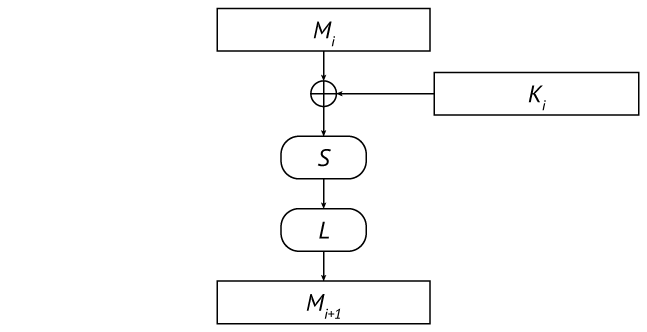
完全な基本的な変換サイクル
代数的に、暗号文Cは次のように平文Pに依存します。
つまり、9つの完全なサイクルの後に最後の不完全なキーが続きます(キーとの混合のみ)。 変換Xは、2を法とする単純加算により、次のサイクルの中間テキストを対応する循環キーと混合します。
変換Sは同じ固定置換を適用します 中間テキストの各バイトに:
変換Lは 、既約多項式を使用して構築された体GF(256)上の線形形式で表すことができます。
中間テキストのベクトル行にこのフィールドの上のマトリックスを掛けることになります(テキストとマトリックスの各バイトは、その係数で表されるフィールドの多項式です)。
/* S- . */ static void applySTransformation( uint8_t *block ) { for (int byteIndex = 0; byteIndex < BlockLengthInBytes; byteIndex += 8) { block[byteIndex + 0] = Pi[block[byteIndex + 0]]; block[byteIndex + 1] = Pi[block[byteIndex + 1]]; block[byteIndex + 2] = Pi[block[byteIndex + 2]]; block[byteIndex + 3] = Pi[block[byteIndex + 3]]; block[byteIndex + 4] = Pi[block[byteIndex + 4]]; block[byteIndex + 5] = Pi[block[byteIndex + 5]]; block[byteIndex + 6] = Pi[block[byteIndex + 6]]; block[byteIndex + 7] = Pi[block[byteIndex + 7]]; } } /* L- . */ static void applyLTransformation( const uint8_t *input, uint8_t *output ) { for (int byteIndex = 0; byteIndex < BlockLengthInBytes; ++byteIndex) { uint8_t cache = 0; for (int addendIndex = 0; addendIndex < BlockLengthInBytes; ++addendIndex) { cache ^= multiplyInGF256(LTransformationMatrix[addendIndex][byteIndex], input[addendIndex]); } output[byteIndex] = cache; } } /* . */ static void applyXSLTransformation( const uint8_t *key, uint8_t *block, uint8_t *temporary ) { applyXTransformation(key, block, temporary); applySTransformation(temporary); applyLTransformation(temporary, block); } /* ( ). */ void encryptBlock( uint8_t *restrict block, const uint8_t *restrict roundKeys ) { uint8_t cache[BlockLengthInBytes] = {0}; int round = 0; for (; round < NumberOfRounds - 1; ++round) { applyXSLTransformation(&roundKeys[BlockLengthInBytes * round], block, cache); } applyXTransformation(&roundKeys[BlockLengthInBytes * round], block, block); }
/* L. */ const uint8_t LTransformationMatrix[16][16] = { 0xcf, 0x6e, 0xa2, 0x76, 0x72, 0x6c, 0x48, 0x7a, 0xb8, 0x5d, 0x27, 0xbd, 0x10, 0xdd, 0x84, 0x94, 0x98, 0x20, 0xc8, 0x33, 0xf2, 0x76, 0xd5, 0xe6, 0x49, 0xd4, 0x9f, 0x95, 0xe9, 0x99, 0x2d, 0x20, 0x74, 0xc6, 0x87, 0x10, 0x6b, 0xec, 0x62, 0x4e, 0x87, 0xb8, 0xbe, 0x5e, 0xd0, 0x75, 0x74, 0x85, 0xbf, 0xda, 0x70, 0x0c, 0xca, 0x0c, 0x17, 0x1a, 0x14, 0x2f, 0x68, 0x30, 0xd9, 0xca, 0x96, 0x10, 0x93, 0x90, 0x68, 0x1c, 0x20, 0xc5, 0x06, 0xbb, 0xcb, 0x8d, 0x1a, 0xe9, 0xf3, 0x97, 0x5d, 0xc2, 0x8e, 0x48, 0x43, 0x11, 0xeb, 0xbc, 0x2d, 0x2e, 0x8d, 0x12, 0x7c, 0x60, 0x94, 0x44, 0x77, 0xc0, 0xf2, 0x89, 0x1c, 0xd6, 0x02, 0xaf, 0xc4, 0xf1, 0xab, 0xee, 0xad, 0xbf, 0x3d, 0x5a, 0x6f, 0x01, 0xf3, 0x9c, 0x2b, 0x6a, 0xa4, 0x6e, 0xe7, 0xbe, 0x49, 0xf6, 0xc9, 0x10, 0xaf, 0xe0, 0xde, 0xfb, 0x0a, 0xc1, 0xa1, 0xa6, 0x8d, 0xa3, 0xd5, 0xd4, 0x09, 0x08, 0x84, 0xef, 0x7b, 0x30, 0x54, 0x01, 0xbf, 0x64, 0x63, 0xd7, 0xd4, 0xe1, 0xeb, 0xaf, 0x6c, 0x54, 0x2f, 0x39, 0xff, 0xa6, 0xb4, 0xc0, 0xf6, 0xb8, 0x30, 0xf6, 0xc4, 0x90, 0x99, 0x37, 0x2a, 0x0f, 0xeb, 0xec, 0x64, 0x31, 0x8d, 0xc2, 0xa9, 0x2d, 0x6b, 0x49, 0x01, 0x58, 0x78, 0xb1, 0x01, 0xf3, 0xfe, 0x91, 0x91, 0xd3, 0xd1, 0x10, 0xea, 0x86, 0x9f, 0x07, 0x65, 0x0e, 0x52, 0xd4, 0x60, 0x98, 0xc6, 0x7f, 0x52, 0xdf, 0x44, 0x85, 0x8e, 0x44, 0x30, 0x14, 0xdd, 0x02, 0xf5, 0x2a, 0x8e, 0xc8, 0x48, 0x48, 0xf8, 0x48, 0x3c, 0x20, 0x4d, 0xd0, 0xe3, 0xe8, 0x4c, 0xc3, 0x16, 0x6e, 0x4b, 0x7f, 0xa2, 0x89, 0x0d, 0x64, 0xa5, 0x94, 0x6e, 0xa2, 0x76, 0x72, 0x6c, 0x48, 0x7a, 0xb8, 0x5d, 0x27, 0xbd, 0x10, 0xdd, 0x84, 0x94, 0x01, }; /* , L. */ const uint8_t inversedLTransformationMatrix[16][16] = { 0x01, 0x94, 0x84, 0xdd, 0x10, 0xbd, 0x27, 0x5d, 0xb8, 0x7a, 0x48, 0x6c, 0x72, 0x76, 0xa2, 0x6e, 0x94, 0xa5, 0x64, 0x0d, 0x89, 0xa2, 0x7f, 0x4b, 0x6e, 0x16, 0xc3, 0x4c, 0xe8, 0xe3, 0xd0, 0x4d, 0x20, 0x3c, 0x48, 0xf8, 0x48, 0x48, 0xc8, 0x8e, 0x2a, 0xf5, 0x02, 0xdd, 0x14, 0x30, 0x44, 0x8e, 0x85, 0x44, 0xdf, 0x52, 0x7f, 0xc6, 0x98, 0x60, 0xd4, 0x52, 0x0e, 0x65, 0x07, 0x9f, 0x86, 0xea, 0x10, 0xd1, 0xd3, 0x91, 0x91, 0xfe, 0xf3, 0x01, 0xb1, 0x78, 0x58, 0x01, 0x49, 0x6b, 0x2d, 0xa9, 0xc2, 0x8d, 0x31, 0x64, 0xec, 0xeb, 0x0f, 0x2a, 0x37, 0x99, 0x90, 0xc4, 0xf6, 0x30, 0xb8, 0xf6, 0xc0, 0xb4, 0xa6, 0xff, 0x39, 0x2f, 0x54, 0x6c, 0xaf, 0xeb, 0xe1, 0xd4, 0xd7, 0x63, 0x64, 0xbf, 0x01, 0x54, 0x30, 0x7b, 0xef, 0x84, 0x08, 0x09, 0xd4, 0xd5, 0xa3, 0x8d, 0xa6, 0xa1, 0xc1, 0x0a, 0xfb, 0xde, 0xe0, 0xaf, 0x10, 0xc9, 0xf6, 0x49, 0xbe, 0xe7, 0x6e, 0xa4, 0x6a, 0x2b, 0x9c, 0xf3, 0x01, 0x6f, 0x5a, 0x3d, 0xbf, 0xad, 0xee, 0xab, 0xf1, 0xc4, 0xaf, 0x02, 0xd6, 0x1c, 0x89, 0xf2, 0xc0, 0x77, 0x44, 0x94, 0x60, 0x7c, 0x12, 0x8d, 0x2e, 0x2d, 0xbc, 0xeb, 0x11, 0x43, 0x48, 0x8e, 0xc2, 0x5d, 0x97, 0xf3, 0xe9, 0x1a, 0x8d, 0xcb, 0xbb, 0x06, 0xc5, 0x20, 0x1c, 0x68, 0x90, 0x93, 0x10, 0x96, 0xca, 0xd9, 0x30, 0x68, 0x2f, 0x14, 0x1a, 0x17, 0x0c, 0xca, 0x0c, 0x70, 0xda, 0xbf, 0x85, 0x74, 0x75, 0xd0, 0x5e, 0xbe, 0xb8, 0x87, 0x4e, 0x62, 0xec, 0x6b, 0x10, 0x87, 0xc6, 0x74, 0x20, 0x2d, 0x99, 0xe9, 0x95, 0x9f, 0xd4, 0x49, 0xe6, 0xd5, 0x76, 0xf2, 0x33, 0xc8, 0x20, 0x98, 0x94, 0x84, 0xdd, 0x10, 0xbd, 0x27, 0x5d, 0xb8, 0x7a, 0x48, 0x6c, 0x72, 0x76, 0xa2, 0x6e, 0xcf, };
キースケジュール
実際、脆弱なキースケジュールなど、古い暗号の開発中に行われた多くの間違いは修正されました。 GOST 28147 '89暗号では、256ビットの秘密キーの8つの32ビット部分が、1番目から8番目、9番目から16番目、17番目から24番目の暗号化サイクルで循環キーとして直接使用されました。 そして、25から30秒までのサイクルでは逆の順序で:
そして、まさに非常に弱いキースケジュールであるため、完全なGOSTへのリフレクションで攻撃を実行できるようになり、その耐久性が256ビットから225ビットに低下しました(すべての交換ノードについて、1つのキーの2 ^ 32マテリアルから、この攻撃についてはここで読むことができます )。
新しい標準では、循環キーの生成はFeistelスキームに従って実行され、最初の2つの循環キーは256ビットの秘密キーの半分であり、次の各循環キーペアは、Feistel変換の8サイクルを前の循環キーペアに適用することによって取得されます。基本的な変換と同じLSX変換が使用され、回路の循環キーとして定数の固定セットが使用されます。
/* 34.12 '15. */ static void scheduleRoundKeys( uint8_t *restrict roundKeys, const void *restrict key, uint8_t *restrict memory ) { /* . */ memcpy(&roundKeys[0], key, BlockLengthInBytes * 2); for (int nextKeyIndex = 2, constantIndex = 0; nextKeyIndex != NumberOfRounds; nextKeyIndex += 2) { /* . */ memcpy(&roundKeys[BlockLengthInBytes * (nextKeyIndex)], &roundKeys[BlockLengthInBytes * (nextKeyIndex - 2)], BlockLengthInBytes * 2); /* . */ for (int feistelRoundIndex = 0; feistelRoundIndex < NumberOfRoundsInKeySchedule; ++feistelRoundIndex) { applyFTransformation(&roundConstants[BlockLengthInBytes * constantIndex++], &roundKeys[BlockLengthInBytes * (nextKeyIndex)], &roundKeys[BlockLengthInBytes * (nextKeyIndex + 1)], &memory[0], &memory[BlockLengthInBytes]); } } }
注釈
ここでは、ループ変換用の256ビットの補助メモリがmemory
ポインタに従って送信されますが、スタックに割り当てることもできます。
roundKeys循環キーを使用した配列の明示的なインデックス付けは、明確さと単純さのためroundKeys
行われ、ポインター演算で簡単に置き換えることができます。
applyFTransformation
関数は、巡回変換を回路のセミブロックに適用し、たとえば次のようにこれらのセミブロックを交換します。
/* . */ static void applyFTransformation( const uint8_t *restrict key, uint8_t *restrict left, uint8_t *restrict right, uint8_t *restrict temporary1, uint8_t *restrict temporary2 ) { memcpy(temporary1, left, BlockLengthInBytes); applyXSLTransformation(key, temporary1, temporary2); applyXTransformation(temporary1, right, right); swapBlocks(left, right, temporary2); }
const uint8_t roundConstants[512] = { 0x6e, 0xa2, 0x76, 0x72, 0x6c, 0x48, 0x7a, 0xb8, 0x5d, 0x27, 0xbd, 0x10, 0xdd, 0x84, 0x94, 0x01, 0xdc, 0x87, 0xec, 0xe4, 0xd8, 0x90, 0xf4, 0xb3, 0xba, 0x4e, 0xb9, 0x20, 0x79, 0xcb, 0xeb, 0x02, 0xb2, 0x25, 0x9a, 0x96, 0xb4, 0xd8, 0x8e, 0x0b, 0xe7, 0x69, 0x04, 0x30, 0xa4, 0x4f, 0x7f, 0x03, 0x7b, 0xcd, 0x1b, 0x0b, 0x73, 0xe3, 0x2b, 0xa5, 0xb7, 0x9c, 0xb1, 0x40, 0xf2, 0x55, 0x15, 0x04, 0x15, 0x6f, 0x6d, 0x79, 0x1f, 0xab, 0x51, 0x1d, 0xea, 0xbb, 0x0c, 0x50, 0x2f, 0xd1, 0x81, 0x05, 0xa7, 0x4a, 0xf7, 0xef, 0xab, 0x73, 0xdf, 0x16, 0x0d, 0xd2, 0x08, 0x60, 0x8b, 0x9e, 0xfe, 0x06, 0xc9, 0xe8, 0x81, 0x9d, 0xc7, 0x3b, 0xa5, 0xae, 0x50, 0xf5, 0xb5, 0x70, 0x56, 0x1a, 0x6a, 0x07, 0xf6, 0x59, 0x36, 0x16, 0xe6, 0x05, 0x56, 0x89, 0xad, 0xfb, 0xa1, 0x80, 0x27, 0xaa, 0x2a, 0x08, 0x98, 0xfb, 0x40, 0x64, 0x8a, 0x4d, 0x2c, 0x31, 0xf0, 0xdc, 0x1c, 0x90, 0xfa, 0x2e, 0xbe, 0x09, 0x2a, 0xde, 0xda, 0xf2, 0x3e, 0x95, 0xa2, 0x3a, 0x17, 0xb5, 0x18, 0xa0, 0x5e, 0x61, 0xc1, 0x0a, 0x44, 0x7c, 0xac, 0x80, 0x52, 0xdd, 0xd8, 0x82, 0x4a, 0x92, 0xa5, 0xb0, 0x83, 0xe5, 0x55, 0x0b, 0x8d, 0x94, 0x2d, 0x1d, 0x95, 0xe6, 0x7d, 0x2c, 0x1a, 0x67, 0x10, 0xc0, 0xd5, 0xff, 0x3f, 0x0c, 0xe3, 0x36, 0x5b, 0x6f, 0xf9, 0xae, 0x07, 0x94, 0x47, 0x40, 0xad, 0xd0, 0x08, 0x7b, 0xab, 0x0d, 0x51, 0x13, 0xc1, 0xf9, 0x4d, 0x76, 0x89, 0x9f, 0xa0, 0x29, 0xa9, 0xe0, 0xac, 0x34, 0xd4, 0x0e, 0x3f, 0xb1, 0xb7, 0x8b, 0x21, 0x3e, 0xf3, 0x27, 0xfd, 0x0e, 0x14, 0xf0, 0x71, 0xb0, 0x40, 0x0f, 0x2f, 0xb2, 0x6c, 0x2c, 0x0f, 0x0a, 0xac, 0xd1, 0x99, 0x35, 0x81, 0xc3, 0x4e, 0x97, 0x54, 0x10, 0x41, 0x10, 0x1a, 0x5e, 0x63, 0x42, 0xd6, 0x69, 0xc4, 0x12, 0x3c, 0xd3, 0x93, 0x13, 0xc0, 0x11, 0xf3, 0x35, 0x80, 0xc8, 0xd7, 0x9a, 0x58, 0x62, 0x23, 0x7b, 0x38, 0xe3, 0x37, 0x5c, 0xbf, 0x12, 0x9d, 0x97, 0xf6, 0xba, 0xbb, 0xd2, 0x22, 0xda, 0x7e, 0x5c, 0x85, 0xf3, 0xea, 0xd8, 0x2b, 0x13, 0x54, 0x7f, 0x77, 0x27, 0x7c, 0xe9, 0x87, 0x74, 0x2e, 0xa9, 0x30, 0x83, 0xbc, 0xc2, 0x41, 0x14, 0x3a, 0xdd, 0x01, 0x55, 0x10, 0xa1, 0xfd, 0xcc, 0x73, 0x8e, 0x8d, 0x93, 0x61, 0x46, 0xd5, 0x15, 0x88, 0xf8, 0x9b, 0xc3, 0xa4, 0x79, 0x73, 0xc7, 0x94, 0xe7, 0x89, 0xa3, 0xc5, 0x09, 0xaa, 0x16, 0xe6, 0x5a, 0xed, 0xb1, 0xc8, 0x31, 0x09, 0x7f, 0xc9, 0xc0, 0x34, 0xb3, 0x18, 0x8d, 0x3e, 0x17, 0xd9, 0xeb, 0x5a, 0x3a, 0xe9, 0x0f, 0xfa, 0x58, 0x34, 0xce, 0x20, 0x43, 0x69, 0x3d, 0x7e, 0x18, 0xb7, 0x49, 0x2c, 0x48, 0x85, 0x47, 0x80, 0xe0, 0x69, 0xe9, 0x9d, 0x53, 0xb4, 0xb9, 0xea, 0x19, 0x05, 0x6c, 0xb6, 0xde, 0x31, 0x9f, 0x0e, 0xeb, 0x8e, 0x80, 0x99, 0x63, 0x10, 0xf6, 0x95, 0x1a, 0x6b, 0xce, 0xc0, 0xac, 0x5d, 0xd7, 0x74, 0x53, 0xd3, 0xa7, 0x24, 0x73, 0xcd, 0x72, 0x01, 0x1b, 0xa2, 0x26, 0x41, 0x31, 0x9a, 0xec, 0xd1, 0xfd, 0x83, 0x52, 0x91, 0x03, 0x9b, 0x68, 0x6b, 0x1c, 0xcc, 0x84, 0x37, 0x43, 0xf6, 0xa4, 0xab, 0x45, 0xde, 0x75, 0x2c, 0x13, 0x46, 0xec, 0xff, 0x1d, 0x7e, 0xa1, 0xad, 0xd5, 0x42, 0x7c, 0x25, 0x4e, 0x39, 0x1c, 0x28, 0x23, 0xe2, 0xa3, 0x80, 0x1e, 0x10, 0x03, 0xdb, 0xa7, 0x2e, 0x34, 0x5f, 0xf6, 0x64, 0x3b, 0x95, 0x33, 0x3f, 0x27, 0x14, 0x1f, 0x5e, 0xa7, 0xd8, 0x58, 0x1e, 0x14, 0x9b, 0x61, 0xf1, 0x6a, 0xc1, 0x45, 0x9c, 0xed, 0xa8, 0x20, };
交換ユニットデバイス
標準では、置換ノードは値の表によって定義されます。 暗号開発者は、このテーブルは、線形プロパティと差分プロパティの要件を考慮して、値のランダムテーブルを並べ替えることによって取得されると主張しています。

置換レイヤー、S変換
/* pi 34.12 2015. */ const uint8_t Pi[256] = { 0xfc, 0xee, 0xdd, 0x11, 0xcf, 0x6e, 0x31, 0x16, 0xfb, 0xc4, 0xfa, 0xda, 0x23, 0xc5, 0x04, 0x4d, 0xe9, 0x77, 0xf0, 0xdb, 0x93, 0x2e, 0x99, 0xba, 0x17, 0x36, 0xf1, 0xbb, 0x14, 0xcd, 0x5f, 0xc1, 0xf9, 0x18, 0x65, 0x5a, 0xe2, 0x5c, 0xef, 0x21, 0x81, 0x1c, 0x3c, 0x42, 0x8b, 0x01, 0x8e, 0x4f, 0x05, 0x84, 0x02, 0xae, 0xe3, 0x6a, 0x8f, 0xa0, 0x06, 0x0b, 0xed, 0x98, 0x7f, 0xd4, 0xd3, 0x1f, 0xeb, 0x34, 0x2c, 0x51, 0xea, 0xc8, 0x48, 0xab, 0xf2, 0x2a, 0x68, 0xa2, 0xfd, 0x3a, 0xce, 0xcc, 0xb5, 0x70, 0x0e, 0x56, 0x08, 0x0c, 0x76, 0x12, 0xbf, 0x72, 0x13, 0x47, 0x9c, 0xb7, 0x5d, 0x87, 0x15, 0xa1, 0x96, 0x29, 0x10, 0x7b, 0x9a, 0xc7, 0xf3, 0x91, 0x78, 0x6f, 0x9d, 0x9e, 0xb2, 0xb1, 0x32, 0x75, 0x19, 0x3d, 0xff, 0x35, 0x8a, 0x7e, 0x6d, 0x54, 0xc6, 0x80, 0xc3, 0xbd, 0x0d, 0x57, 0xdf, 0xf5, 0x24, 0xa9, 0x3e, 0xa8, 0x43, 0xc9, 0xd7, 0x79, 0xd6, 0xf6, 0x7c, 0x22, 0xb9, 0x03, 0xe0, 0x0f, 0xec, 0xde, 0x7a, 0x94, 0xb0, 0xbc, 0xdc, 0xe8, 0x28, 0x50, 0x4e, 0x33, 0x0a, 0x4a, 0xa7, 0x97, 0x60, 0x73, 0x1e, 0x00, 0x62, 0x44, 0x1a, 0xb8, 0x38, 0x82, 0x64, 0x9f, 0x26, 0x41, 0xad, 0x45, 0x46, 0x92, 0x27, 0x5e, 0x55, 0x2f, 0x8c, 0xa3, 0xa5, 0x7d, 0x69, 0xd5, 0x95, 0x3b, 0x07, 0x58, 0xb3, 0x40, 0x86, 0xac, 0x1d, 0xf7, 0x30, 0x37, 0x6b, 0xe4, 0x88, 0xd9, 0xe7, 0x89, 0xe1, 0x1b, 0x83, 0x49, 0x4c, 0x3f, 0xf8, 0xfe, 0x8d, 0x53, 0xaa, 0x90, 0xca, 0xd8, 0x85, 0x61, 0x20, 0x71, 0x67, 0xa4, 0x2d, 0x2b, 0x09, 0x5b, 0xcb, 0x9b, 0x25, 0xd0, 0xbe, 0xe5, 0x6c, 0x52, 0x59, 0xa6, 0x74, 0xd2, 0xe6, 0xf4, 0xb4, 0xc0, 0xd1, 0x66, 0xaf, 0xc2, 0x39, 0x4b, 0x63, 0xb6, }; /* , pi, 34.12 2015. */ const uint8_t InversedPi[256] = { 0xa5, 0x2d, 0x32, 0x8f, 0x0e, 0x30, 0x38, 0xc0, 0x54, 0xe6, 0x9e, 0x39, 0x55, 0x7e, 0x52, 0x91, 0x64, 0x03, 0x57, 0x5a, 0x1c, 0x60, 0x07, 0x18, 0x21, 0x72, 0xa8, 0xd1, 0x29, 0xc6, 0xa4, 0x3f, 0xe0, 0x27, 0x8d, 0x0c, 0x82, 0xea, 0xae, 0xb4, 0x9a, 0x63, 0x49, 0xe5, 0x42, 0xe4, 0x15, 0xb7, 0xc8, 0x06, 0x70, 0x9d, 0x41, 0x75, 0x19, 0xc9, 0xaa, 0xfc, 0x4d, 0xbf, 0x2a, 0x73, 0x84, 0xd5, 0xc3, 0xaf, 0x2b, 0x86, 0xa7, 0xb1, 0xb2, 0x5b, 0x46, 0xd3, 0x9f, 0xfd, 0xd4, 0x0f, 0x9c, 0x2f, 0x9b, 0x43, 0xef, 0xd9, 0x79, 0xb6, 0x53, 0x7f, 0xc1, 0xf0, 0x23, 0xe7, 0x25, 0x5e, 0xb5, 0x1e, 0xa2, 0xdf, 0xa6, 0xfe, 0xac, 0x22, 0xf9, 0xe2, 0x4a, 0xbc, 0x35, 0xca, 0xee, 0x78, 0x05, 0x6b, 0x51, 0xe1, 0x59, 0xa3, 0xf2, 0x71, 0x56, 0x11, 0x6a, 0x89, 0x94, 0x65, 0x8c, 0xbb, 0x77, 0x3c, 0x7b, 0x28, 0xab, 0xd2, 0x31, 0xde, 0xc4, 0x5f, 0xcc, 0xcf, 0x76, 0x2c, 0xb8, 0xd8, 0x2e, 0x36, 0xdb, 0x69, 0xb3, 0x14, 0x95, 0xbe, 0x62, 0xa1, 0x3b, 0x16, 0x66, 0xe9, 0x5c, 0x6c, 0x6d, 0xad, 0x37, 0x61, 0x4b, 0xb9, 0xe3, 0xba, 0xf1, 0xa0, 0x85, 0x83, 0xda, 0x47, 0xc5, 0xb0, 0x33, 0xfa, 0x96, 0x6f, 0x6e, 0xc2, 0xf6, 0x50, 0xff, 0x5d, 0xa9, 0x8e, 0x17, 0x1b, 0x97, 0x7d, 0xec, 0x58, 0xf7, 0x1f, 0xfb, 0x7c, 0x09, 0x0d, 0x7a, 0x67, 0x45, 0x87, 0xdc, 0xe8, 0x4f, 0x1d, 0x4e, 0x04, 0xeb, 0xf8, 0xf3, 0x3e, 0x3d, 0xbd, 0x8a, 0x88, 0xdd, 0xcd, 0x0b, 0x13, 0x98, 0x02, 0x93, 0x80, 0x90, 0xd0, 0x24, 0x34, 0xcb, 0xed, 0xf4, 0xce, 0x99, 0x10, 0x44, 0x40, 0x92, 0x3a, 0x01, 0x26, 0x12, 0x1a, 0x48, 0x68, 0xf5, 0x81, 0x8b, 0xc7, 0xd6, 0x20, 0x0a, 0x08, 0x00, 0x4c, 0xd7, 0x74, };
ただし、すべての秘密は遅かれ早かれ明らかになり、交換ノードを選択する方法も例外ではありません。 Alex Biryukov率いるルクセンブルグの暗号作成者チームは、交換ノードの統計的特性にある種のパターンを検出し、その結果、受信方法を復元することができました。 この方法の詳細については、iacr.orgで公開されている記事をご覧ください。

置換ノードの秘密構造
アルゴリズム最適化
InfoTeKS OJSCの研究者チーム、特にMikhail BorodinとAndrey Rybkinは、AES(Rijndael)暗号の高速実装からベクトル列乗算のアルゴリズム最適化を借りることができました。これにより、フィールドでのO(n ^ 2)乗算の従来の実装を置き換えることができますO(n)は、事前に計算されたテーブルを使用して長さO(n)の2つのベクトルを法として加算し、2014年にRusCrypto会議で報告されました。
要するに、最適化は次のようになります。あるベクトルUの積の結果として、
行列A上
ベクトルVが判明しました。
このベクトルの成分を計算する従来の方法は、ベクトルUの行に行列Aの列を順次スカラーで乗算することです。
ベクトルVの n個の各コンポーネントの計算は、フィールドでの乗算のn演算と2を法とするn-1加算演算を意味するため、すべての成分の計算の複雑さはO(n ^ 2)です。 はい、もちろん、毎回フィールドで乗算することはできません。対数と指数のテーブルを事前計算できます。 マトリックス要素のすべての可能なバイトの積を事前計算することもできます(マトリックスは固定されており、暗号化中に変化しません)。256バイトの作品を256個まで保存できます。 行列は同じ要素を持っていますか? さて、テーブルの数は減らすことができますが、漸近的な複雑さは変わりません。
そして、あなたは他の方法で行くことができます。 製品ベクトルの各成分をn個のシングルバイトパッセージの合計として計算する代わりに、ベクトルに行列を掛ける機能を使用して、ベクトルのすべての成分をn個のベクトルの合計としてすぐに計算します。
変更されたように見えるでしょうか? 同じ操作ですが、順序は異なります。 ただし、まず、1バイトからnバイトまでの項の容量が増加し、そのような合計は長いレジスターで計算できます(また、そうすべきです)。次に、各項はベクトルの1(!)バイトの展開積です。固定行マトリックス上。
詳細は次のとおりです。フォームの製品を事前計算できます
つまり、行列Aの既知の行iにベクトルUのバイトiのすべての可能な値を乗算し、次のバイトにこの行を乗算する代わりに、単にテーブルから製品を読み取ります。 次に、ベクトルに行列を乗算すると、事前に計算されたテーブルから製品のn行を読み取り、これらの行をビット単位で加算して結果のベクトルVを取得することになります。 したがって、非常に簡単に言えば、ベクトルの加算が基本演算と見なされる場合、ベクトルと行列のO(n)への乗算を大幅に単純化できます。
GOST R 34.12 '15 n = 16の場合、ベクトルは16バイトまたは128ビット長であり、長いXMMレジスターに非常によく適合し、追加するための追加のプロセッサー命令(たとえば、 pxor
)が提供されます。
すべてが非常にクールですが、交換ノードはどうですか? 読者は確かに、一般的にベクトル化されないバイト置換ノードが存在する場合、そのようなL変換計算のアルゴリズム上の利点はすべて、変換前にベクトルをレジスターにロードし、変換後にアンロードするコストによって相殺されることに気付くでしょう。 いい質問です。
素晴らしく、非常にエレガントに解決されました。 交換ノードはL変換で単純に「接着」でき、事前に計算された製品ラインを
に
次に、完全な暗号化サイクルが1つになります
- キー(
pxor
)との混合、 - LS接着トランスフォームの適用(最良の場合、これはキャッシュから128ビットのベクターを16ダウンロードし、
pxor
を15追加することpxor
)。
もちろん、そのような最適化は無料ではありません。その使用のために、まず、それぞれが256 * 16 * 16バイト、または64 KBを含む製品ラインを持つ2つのテーブルのいずれかを一度に計算してキャッシュする必要があります。 なぜ2つのテーブルがあるのですか? 復号化に使用される逆変換では、 Lの逆行列による乗算が必要になるため、新製品が必要になります。
第二に、置換ノードをマトリックスで乗算して接着することは、最初にブロックに置換と乗算を適用した場合にのみ可能であるため、復号化アルゴリズムをわずかに変更する必要があります。 スキーム全体を単純に逆にすることで、暗号文からクリアテキストが取得されます(すべての変換は可逆です)。
「額」を復号化するとき、逆行列による乗算が最初に中間テキストに適用され、次に置換アクションが適用されることに注意してください。したがって、ここでこれらの変換を接着するには、復号化アルゴリズムを並べ替える必要があります。
変換の構成に注意してください
構成と同一
変換Lの線形性のため その後、復号化は次のように実行できます。
ここで、 SLに逆の各変換は、検討されたものと同様のスキームに従って実行できます。 製品ラインの計算されたテーブルは投稿しません。ネタバレには大きすぎます。 それらは、たとえばここにあります 。
SSE2を使用した最適化
原則として、基本的な変換では、すべてが明確であり、これらの最適化をすべてasmに置くことが残っています。
ブロックを操作するには、SSE2命令のセットを使用することをお勧めしますmovdqu
およびmovdqa
を使用して、データをレジスターにロードおよびアンロードします。
はい、GOST R 34.12 '15の実装には別の微妙な点があります。 上記のような一般的なアルゴリズムの最適化に加えて、パフォーマンスをさらに加速するには、アセンブラの機能とスケジューラの機能を考慮する必要があります。これらの機能は、異なる実行デバイスで並列実行の命令を配置できます。
アドレス演算の機能の説明
アルゴリズムの実装の最初の機能は、事前に計算されたテーブルの構造とオフセット付きの間接インデックスのアドレス指定を考慮しない場合、コンパイル時に次の製品ラインで追加の次の排気出力が得られることです。
pextrb xmmX, eax, i ; i (SSE 4.1) 32-- eax movzxd rcx, eax ; 64-- rcx add rcx, rcx ; pxor xmmY, [rbx + 8*rcx + 0xi000] ;
レジスタは以下を保存します:
-
rbx
には、テーブルのベースオフセットのアドレスが含まれます。 -
xmmX
には入力ブロックが含まれ、 -
xmmY
には出力単位(バッテリー、量)が含まれます。 -
eax
とrcx
は、オフセットバイトの割り当てと2rcx
に使用されます。
事前に計算されたテーブルは次のように配置されることに注意してください。
uint8_t table[16][256][16],
つまり、製品ラインの値はこのテーブルに連続して格納され、外部インデックスiはL変換行列のi番目の行に対応し、平均インデックスjは入力ブロックのi番目のバイトに等しく、内部インデックスkは次の項のバイトインデックスに対応します:
Xi = table[i][input[i]][0] ... [16]
したがって、次の項Xi
最初のバイトのアドレスは次のように表されます。
[Xi] = rbx + (0x1000 * i) + (16 * input[i]),
どこで
-
(0x1000 * i)
は現在の行のオフセットに対応しtable[i]
(table[i]
)。 -
(16 * input[i])
は、現在の項Xi
オフセットに対応しtable[i][input[i]]
(table[i][input[i]]
)。
そのため、現在のバイトの値に16を掛ける必要がありますが、アドレス演算では8に等しい係数係数の最大値を使用できます。 したがって、コンパイラーはバイト値をrcx
にシフトし、それを2倍にして、 Xi
アドレスを計算する必要があります。
このような過剰を回避するために、SIMDのイデオロギーを使用して、アドレス演算ではなく、事前に指定された変位を計算できます。
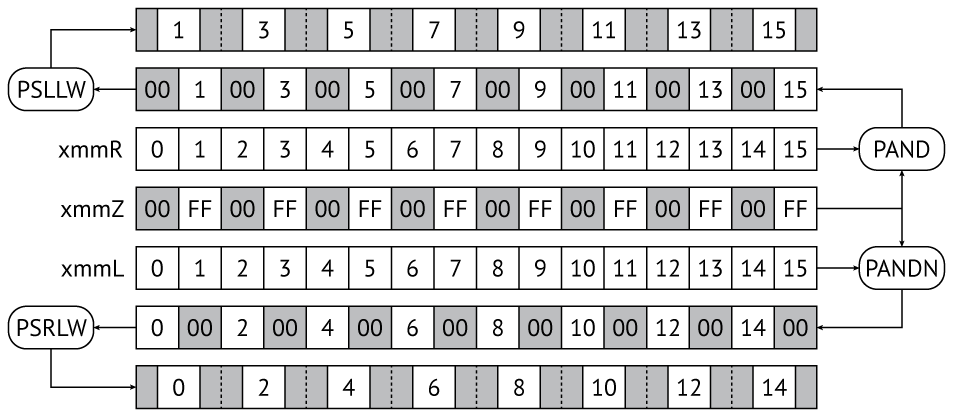
( Xi
)
0..15 , 00
FF
.
00FF 00FF 00FF 00FF 00FF 00FF 00FF 00FF
pand
pandn
; c psrlw
psllw
( 16) , .
, L - :
pand xmmR, xmmZ ; pandn xmmL, xmmZ ; psllw xmmR, 4 ; psrlw xmmL, 4 ;
xmmZ
. Xi
:
pextrw eax, i ; i pxor xmmY, [rbx + rax + 0xi000] ;
Intel AMD , , , , , .
, , , . LS - 128- Xi
, , , ( ) : .
.code extern bitmask:xmmword extern precomputedLSTable:xmmword encrypt_block proc initialising: movdqu xmm0, [rcx] ; [unaligned] loading block lea r8, [precomputedLSTable + 01000h] ; [aligned] aliasing table base with offset lea r11, [precomputedLSTable] ; [aligned] aliasing table base movdqa xmm4, [bitmask] ; [aligned] loading bitmask mov r10d, 9 ; number of rounds, base 0 round: pxor xmm0, [rdx] ; [aligned] mixing with round key movaps xmm1, xmm4 ; securing bitmask from @xmm4 movaps xmm2, xmm4 ; securing bitmask from @xmm4 pand xmm2, xmm0 ; calculating offsets pandn xmm1, xmm0 psrlw xmm2, 4 psllw xmm1, 4 pextrw eax, xmm1, 0h ; accumulating caches movdqa xmm0, [r11 + rax + 00000h] pextrw eax, xmm2, 0h movdqa xmm3, [r8 + rax + 00000h] pextrw eax, xmm1, 1h pxor xmm0, [r11 + rax + 02000h] pextrw eax, xmm2, 1h pxor xmm3, [r8 + rax + 02000h] pextrw eax, xmm1, 2h pxor xmm0, [r11 + rax + 04000h] pextrw eax, xmm2, 2h pxor xmm3, [r8 + rax + 04000h] pextrw eax, xmm1, 3h pxor xmm0, [r11 + rax + 06000h] pextrw eax, xmm2, 3h pxor xmm3, [r8 + rax + 06000h] pextrw eax, xmm1, 4h pxor xmm0, [r11 + rax + 08000h] pextrw eax, xmm2, 4h pxor xmm3, [r8 + rax + 08000h] pextrw eax, xmm1, 5h pxor xmm0, [r11 + rax + 0a000h] pextrw eax, xmm2, 5h pxor xmm3, [r8 + rax + 0a000h] pextrw eax, xmm1, 6h pxor xmm0, [r11 + rax + 0c000h] pextrw eax, xmm2, 6h pxor xmm3, [r8 + rax + 0c000h] pextrw eax, xmm1, 7h pxor xmm0, [r11 + rax + 0e000h] pextrw eax, xmm2, 7h pxor xmm3, [r8 + rax + 0e000h] pxor xmm0, xmm3 ; mixing caches add rdx, 10h ; advancing to next round key dec r10 ; decrementing round index jnz round last_round: pxor xmm0, [rdx] ; [aligned] mixing with round key movdqu [rcx], xmm0 ; [unaligned] storing block ret encrypt_block endp end
おわりに
; , Intel Core i7-2677M Sandy Bridge @ 1.80 GHz, 120 / SSE 1.3 / .
— , :
- ( , );
- , , .
34.12 '15 , . C99, , . CMake 3.2.1+ , C99. , ( compact ), , SIMD ( optimised ) SSE2 ( SIMD ).
Travis CI , ( , ) CTest std::chrono
C++11.