
語彙を記憶するためのモバイルアプリケーションの開発に着手する前に、Skyengでは作業メモリのアルゴリズムと単語を記憶するアルゴリズムの研究に多くの時間を費やしました。 その結果、Awordの開発には少し時間がかかりましたが、結果に自信があります-単語の表示に特定のアルゴリズムを使用すると、語彙をより効率的に補充できます。
 市場には外国語を記憶するための多数のアプリケーションがあります。 それらはすべて、共通の機能-メイン学習ツールとしてのクラム(ドリル)の使用によって結合されます。 生徒が繰り返し単語を使う時間が長いほど、その単語を覚える可能性が高くなります。 たとえば、1時間で100語を学習することはかなり可能です。 ただし、6時間後に繰り返すことなく、それらの半分は忘れられます。 さらに6時間後、覚えられるのは15語までです。 これを防ぐには、定期的にセット全体を繰り返す必要があります(詰め込み)。
市場には外国語を記憶するための多数のアプリケーションがあります。 それらはすべて、共通の機能-メイン学習ツールとしてのクラム(ドリル)の使用によって結合されます。 生徒が繰り返し単語を使う時間が長いほど、その単語を覚える可能性が高くなります。 たとえば、1時間で100語を学習することはかなり可能です。 ただし、6時間後に繰り返すことなく、それらの半分は忘れられます。 さらに6時間後、覚えられるのは15語までです。 これを防ぐには、定期的にセット全体を繰り返す必要があります(詰め込み)。
学生がリストの繰り返しを一時停止した場合(1週間、1か月、休暇、就労中など)-単語が忘れられ、詰め込みが最初から開始される可能性が高くなります。 ある単語セットから次の単語セットに切り替え、しばらくして最初の単語を繰り返さなかった場合、彼は彼を忘れます。 そのような暗記を効果的に機能させるには、自分で、または教師の助けを借りて明確な学習計画を立て、それに従うことを厳守する必要があります。
私たちは、「ドリル」プロセスだけでなく、レッスン計画の準備と保守、および得られた知識の管理を提供するアプリケーションを作成することは可能でしょうか? 学習効率を最大化し、学生の時間を節約する方法は?
あなたは遠くから始める必要があります:私たちの記憶の構造について話すことによって、それは短期的または長期的です。
詰め込みと暗記
 短期は、それほど必要ではない正式な科目に合格した学生によく知られています。 試験の前夜に教科書を勉強すると、断片化された形式ではあるものの、ほとんどの情報が試験または試験に合格するのに十分な時間記憶に残る可能性が高くなります。 しかし、数日で痕跡なしに消えます(より正確には、研究はそれが消えないことを示していますが、意識の深さで非常に確実に隠れてそこから抽出するのが問題になります)。
短期は、それほど必要ではない正式な科目に合格した学生によく知られています。 試験の前夜に教科書を勉強すると、断片化された形式ではあるものの、ほとんどの情報が試験または試験に合格するのに十分な時間記憶に残る可能性が高くなります。 しかし、数日で痕跡なしに消えます(より正確には、研究はそれが消えないことを示していますが、意識の深さで非常に確実に隠れてそこから抽出するのが問題になります)。
長期記憶は、1年または5年後に受け取った情報を簡単に思い出せるようにするものです。 しかし、それが機能するためには定期的なトレーニングが必要であり、これらのトレーニングの最も効果的な形式は、教科書を読み直すのではなく、実際にコントロールの質問を確認するか、習得した知識を絶えず適用することです。
たとえば、新しいプログラミング言語を学習している学生は、このトレーニングを毎日のコーディングセッションの形で受けます。 C ++でオブジェクトの主題を理解したので、彼はそれを定期的に使用すれば永遠に記憶することができます。 そのため、教師はオブジェクト指向プログラミングを必要とします。些細なタスクでさえ、それなしで行うのが合理的です。
長期記憶は必ずしも必要ではありません。 化学者はすべての式を知る必要はありません。 弁護士は、刑法、民事法および手続法の完全版を頭に持つ必要はありません。 ディレクトリはいつでも支援できます。 彼らにとっては、仕事の原理とデータ検索の方向に関する知識を理解することがより重要です。
しかし、長期的な記憶が必要な領域があります。 最も明白なのは医学と言語学です。 医師は、まれでさえある病気の症状を覚えていなければなりません。 英語に堪能であると主張する人は、たとえ人生で英語に出会ったことがなくても、セレンディピティという言葉を知っているべきです。 もちろん、そのような長期記憶を発達させる最も効果的な方法は実践です。 医科大学の卒業生は、数年間居住またはインターンシップに送られます。 プロの翻訳者は、ネイティブスピーカー間のインターンシップに参加する必要があります。
しかし、そのような可能性がない場合はどうでしょうか? そして、在留中に医師が川崎症候群の症例に遭遇しなかった場合はどうなりますか?
他の方法で長期記憶を発達させる必要があります。 この分野の主な研究が医師と言語学者によって行われていることは驚くことではありません。
ポーランドの学生とドイツの心理学者
最も有名なSuperMemoメモリアルゴリズムの作成者であるPetr Wozniakは、ポズナン工科大学の学生として、80年代にこのプロセスを最適化することを考えました。 彼が自分のために設定したタスクの1つは、英語の完全な知識でした。彼は、仲間の学生が非常に満足している表面的な職業レベルに満足していませんでした。
ウォズニアックはかなり頑固な男であることが判明した。 彼は質問と回答を含む英語と生物学のカードのデータベースを作成し、毎日のトレーニングに従事し、日記に結果を注意深く書き留めました。 実験の終わりに、彼は英語で3000枚のカードと生物学で1.5千枚以上のカードを作りました。
ウォズニアックは、得られたデータに基づいた簡単な計算の助けを借りて、15,000の英単語の小さな辞書を記憶するには、トレーニングに毎日2時間を費やす必要があることを発見しました。 費やされる時間は単語の数に比例して長くなります。3万回を覚えるには、毎日4時間の繰り返しが必要です。 あまり便利ではありません。
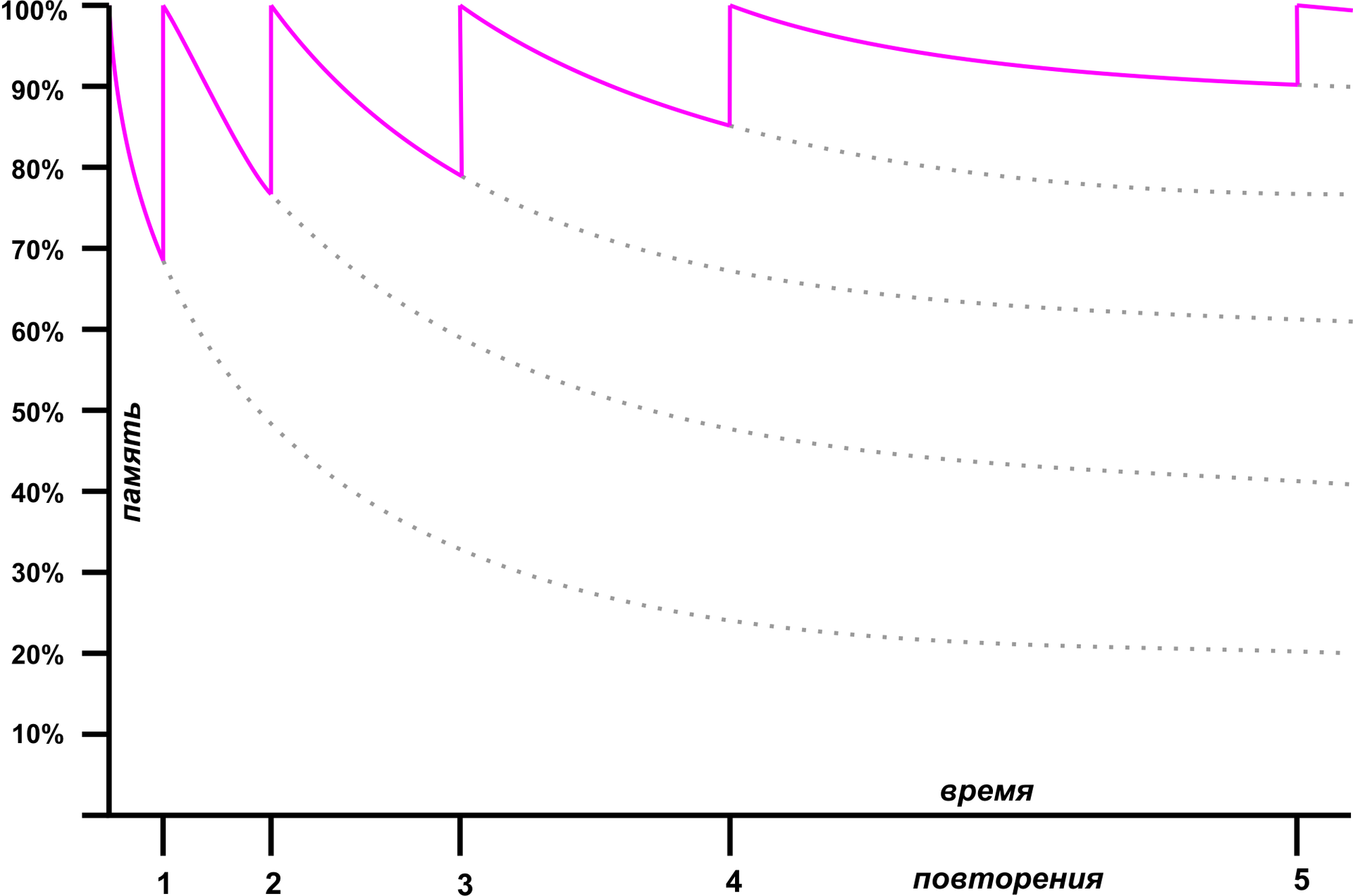
 幸いなことに、ピーター・ウォズニアックの100年前、ドイツの心理学者でもあるドイツのエビングハウスは非常に頑固な人物であり、同様の問題を懸念していました。 エビングハウスは1年間の実験を2回行いましたが、その間に無意味な音節セットを思い出しました。 その結果、いくつかの発見がなされましたが、その中で最も重要なのは忘却曲線です。
幸いなことに、ピーター・ウォズニアックの100年前、ドイツの心理学者でもあるドイツのエビングハウスは非常に頑固な人物であり、同様の問題を懸念していました。 エビングハウスは1年間の実験を2回行いましたが、その間に無意味な音節セットを思い出しました。 その結果、いくつかの発見がなされましたが、その中で最も重要なのは忘却曲線です。
Ebbinghausは、実験を繰り返すたびに情報を忘れる割合が減少することを実験的に発見しました。 データを最初に記憶した後、忘却は非常に高速です。約1時間後、約半分の材料が10時間後、頭から飛び出しました-65%。 ただし、調査後1か月で約20%が残っています。 ただし、最初の1時間にすべての素材を繰り返すと、素材を忘れるプロセスが大幅に遅くなり、1日で新しい繰り返しを行うことができます。 忘却の曲線を使用すると、繰り返しの回数を調整して、最小限のワークアウトで最大の材料の長期同化を行うことができます。
この方法は、スペースリピティションと呼ばれます。 30年代に、そのような手法が学習プロセスに有益な効果をもたらすことを示す実験が実施されました。 しかし、彼女はあまりにも複雑であるため、当時人気がありませんでした。質問と回答を含む数千枚のカードを準備し、正しくシャッフルし、時間通りに繰り返す必要がありました...しかし、コンピューターが登場しました。
英語を学ぶことを夢見ていましたが、トレーニングに1日4時間を費やすことを熱望していなかったポーランドの学生Petr Wozniakに戻りましょう。 彼は、インターバル繰り返し手法をアルゴリズム化することを決定し、最終的にSuperMemoプログラムを作成しました。 もちろん、すべてがシンプルとはほど遠いことが判明し、SuperMemoの開発は実際、彼の人生の仕事になりました。
間隔反復法のアルゴリズム化は、かなり明白なタスクです。 この方法の主な問題は、繰り返しが最も効果的な時間を正確に計算する必要があることです。 情報が忘れられた瞬間。 トレーニングを行うだけでなく、ユーザーに必要性をすぐに思い出させるプログラムを作成すると、理論的にはより効果的なトレーニングが可能になります。
独自の特性があります。 物忘れ曲線自体は普遍的な現象ですが、異なる指数は異なる人々と重なります。 誰かが20分で3回目を繰り返し、1時間で誰かが必要です。 後続の繰り返し間の距離も同様に変化します。 したがって、トレーニングは柔軟である必要があります。コースでは、アルゴリズムは特定の学生を忘れてそれに適応する速度を理解しようとします。
学習を成功させるための重要な問題は、人的要因です。 最小限の期間で最大量の情報を効果的に記憶するには、スケジュールを正確に守る必要があります。 実際には、これにより不便が生じ、学生は後で延期することにします。 その結果、適切な瞬間を逃したため、彼らはロールバックします-1、2、またはトレーニングの最初まで。 このロールバックも、オーバーヘッドコストを最小限に抑えるために正しく計算する必要があります。
Wordライセンス
Awordモバイルアプリは、「ワードライセンス」の概念に基づいています-期間限定のソフトウェアライセンスに似ています。 最初の暗記後、「ライセンス」は約1時間有効です。 言葉を繰り返さないと、それは忘れられます。 この時間の終わりに単語を繰り返すと、6時間前から新しい「ライセンス」が表示されます。 次の「ライセンス」は1日、その後3日間、1週間、1か月、6か月、2年です。 繰り返しのための最も効果的な瞬間は境界線であり、前の「ライセンス」が失効したとき、その言葉を覚えておくためには、いくつかの努力をする必要があります。 各単語のすべての「ライセンス」は学生のアカウントのサーバーに保存され、モバイルアプリケーションのタスクは、それらを更新する時間であることを時間内に思い出させることです。
Awordの基礎となる基本的なアルゴリズムは、この擬似コードで説明できます。
function makeRepetition( user, word, license ){ var timePassed = (new Date()) - license.startTime; var answer = showWordCard( word ); user.tuneParameters( license, timePassed, answer.quality ); word.tuneComplexity( license, timePassed, answer.quality ); if(answer.quality > 0) { license.next( timePassed ); } else { license.rollback( timePassed ); } }
このアルゴリズムのコアコードは、単語ごとに増加した「ライセンス」を与えることができるかどうか、または再度教える必要があるかどうかを決定します。 tuneParametersおよびtuneComplexity-調整アルゴリズムへの条件付きリンク。 回答の質(answer.quality)は0〜1の数値です。この数値は、生徒がすばやく単語を初めて学習した場合、1に等しくなります。 彼の記憶はうまく機能し、仕事は彼にとってあまりにも簡単でした。 この場合、アルゴリズムは繰り返し間隔を増やします。 回答の質が0.5未満に近い場合-プロンプトが出された後、回答は難しかった。 この生徒の標準的な繰り返し間隔が長すぎるため、さらにトレーニングを行う必要があります。
元の忘却曲線は、合成実験データに基づいて作成されました。 Ebbinghausは、最終的に最も純粋な結果を得るために、意味のない音節を意図的に使用しました。
現代の医学生は、例えば、薬理学に関するデータを記憶するために(また、一般に、文字のセットで構成される)、その初期の形で忘却曲線をうまく使用します。 ここに、例えば、材料を繰り返すための典型的な指示があります:
-最初の繰り返し-それを読んだ直後(制御質問の検証);
-2回目の繰り返し-20分後。
-3番目-1日で;
-4番目-3番目の48時間後;
-5番目-4番目の72時間後。
間隔反復法を使用して情報を効果的に保存できる汎用アルゴリズムがあります。 最も有名な(そして無料の)そのようなプログラムはAnkiです。 もちろん、外国語の学習に関連する特性を考慮していませんが、本当に重要なことを長い間覚えておく必要がある場合には非常に役立ちます。
 外国語を学ぶとき、私たちは混chaとした文字のセットではなく、意味のある言葉を扱っています。 生徒にとっての単語の有意性と理解度は、暗記の速度に直接影響します。 したがって、エンジニアは「ギア」という言葉を哲学者よりもずっと早く覚えます。 親しみやすく、簡単に表示される単語(「オーク」)は、エキゾチック(「fir」)よりも簡単に記憶されます。 その結果、ほぼ同じ暗記速度でグループを慎重に選択する必要があります。 SuperMemoアルゴリズムは、そのような選択のためにユーザーの主観的な評価を使用します-ユーザーが単語を与えるのがどれほど難しいか。 これは非常に正確な指標ではありません。 もう1つの要因は、プログラムを作成するために評価する必要がある学生の既存の語彙ベースです。 これもすべてアルゴリズム化する必要があります。 ただし、これらは個々の記事のトピックです。
外国語を学ぶとき、私たちは混chaとした文字のセットではなく、意味のある言葉を扱っています。 生徒にとっての単語の有意性と理解度は、暗記の速度に直接影響します。 したがって、エンジニアは「ギア」という言葉を哲学者よりもずっと早く覚えます。 親しみやすく、簡単に表示される単語(「オーク」)は、エキゾチック(「fir」)よりも簡単に記憶されます。 その結果、ほぼ同じ暗記速度でグループを慎重に選択する必要があります。 SuperMemoアルゴリズムは、そのような選択のためにユーザーの主観的な評価を使用します-ユーザーが単語を与えるのがどれほど難しいか。 これは非常に正確な指標ではありません。 もう1つの要因は、プログラムを作成するために評価する必要がある学生の既存の語彙ベースです。 これもすべてアルゴリズム化する必要があります。 ただし、これらは個々の記事のトピックです。
私たちのモバイルアプリケーションで使用されるアルゴリズムは、従業員とその友人からのボランティアで6ヶ月間テストされました。 これにより、いくつかの平均的なパラメーター(「ライセンス」の用語)を選択することができました。これらは最終的に、単語の長期記憶プロセスを最適化するために使用されます。 アプリケーションがすべてのユーザーに利用可能になったので、さらに多くの分析データを収集して、これらのパラメーターをさらに微調整できるようになります。 これはすべて、App Storeでモバイルアプリケーションをダウンロードすることで確認できます。 10月末に、アプリケーションはGoogle Playで利用可能になり、11月にWebで利用可能になります。
そして、もしあなた自身がそのような作品の開発に参加したいなら、私たちにはたくさんの興味深い空席があります!