ITMが今日のIBMにおけるこのような機能の唯一の製品ではないことを言及する価値があります。 最近、IBM Application Performance Managementと呼ばれる製品が登場しましたが、そのアーキテクチャについては別の機会に登場しました。
ITMの機能を考慮すると、多数のネットワーク機器の監視に使用することはお勧めしません。 あらゆる種類の異常な状況がありますが、通常はIBM Tivoli Network Managerがこれに使用されます。
zabbixについて言及します。 私はよく彼と顧客に会い、よく聞いた。 かつて、顧客は10秒ごとにエージェントからデータを受信するという要件に非常に感銘を受けました。 彼は、ITMである期間の平均的なトリガーを作成できないことに非常に失望しました(議論できるなら、松葉杖を作ることができますが、なぜですか?)。 彼はzabbixに精通していました。
zabbix(NetXMSと同様の状況)では、トリガーが履歴データを分析します。 これは非常にクールですが、私はそれを必要としませんでした。 zabbixエージェントは、データをサーバーに(またはzabbixプロキシ経由で)渡します。 データはデータベースに保存されます。 次に、トリガーが機能し、強力なマクロシステムがそれらを支援します。 したがって、基本的な機能を実行するための鉄の性能には要件があります。
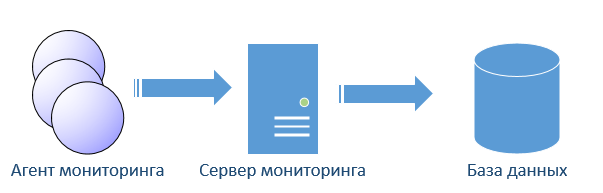
ITMには独自の特性があります。 ITMサーバーはすべてのデータをエージェントからのみ受信します。 SNMPプロトコルなどは組み込まれていません。サーバーは、データベースが組み込まれたマルチスレッドアプリケーションです。 トリガーの操作におけるITMの機能(これらは状況ですが、一般的な用語を遵守するためにトリガーを呼び出します)。 トリガーはエージェントで実行されます。 さらに、これらのトリガーは条件付きのSQLクエリです。 サーバーはトリガーをバイナリsqlコードにコンパイルし、実行のためにエージェントに渡します。 エージェントのアーキテクチャは、データベースのように見えます。
すべての種類のメトリックはすでにエージェントに組み込まれており(比較的最近、アプリケーション/スクリプトからデータを受信する機能が追加されました)、リレーショナルデータベースではタブレットとして記述されています。 エージェントは、指定された間隔に従ってsql要求を実行します。 「データベース」と呼ばれる素人のレイヤーは、オペレーティングシステム(OS)に必要なクエリを実行し、データをテーブルの形式で配置します。 OSへのリクエストの頻度は30秒以下です。 つまり、テーブル内のデータは多くの場合30秒です。 更新しないでください。 エージェントが多くの単調なトリガーを実行できることは明らかであり、これは負荷に大きな影響を与えませんが、これも30秒を超える頻度です。 彼はデータを収集しません。 また、エージェントが実行するSQLクエリが0行を返すまで、エージェントがサーバーを妨害しないことも興味深いです。 SQLクエリが複数の行を返すとすぐに、これらすべての行がサーバーに送信されます(トリガー条件が発生しました)。 次に、サーバーは、別のストリームが通過するまで一時テーブルにデータを配置し、追加の条件を確認してシステムでイベントを生成します。 質問を先取りして、エージェントはログなどのイベントをどのように処理しますか? これで問題はありません。エージェントはそのようなデータをアクティブモードのサーバーにすぐに送信します。
したがって、結論。 ITMサーバーデータベースには履歴は含まれず、ライブデータのみが含まれます。 トリガーは、負荷の一部を引き受けるエージェントの側で実行されます。
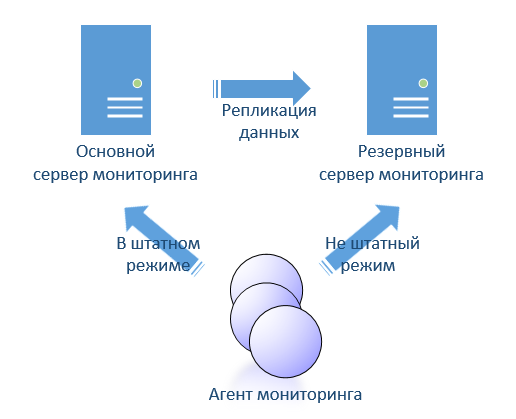
また、オープンソースを考慮して、私はすぐにフォールトトレランスの実装について疑問に思いました。 何が欲しいのか見当がつかなかった。 ITMではホットスタンビー(ホットスタンバイ)を実装できるため、オープンソースでこのようなものが欲しいです。 ITMでは、これは非常に簡単に実装されます。 データベースをアクティブからパッシブに複製する2つのサーバー。 両方のサーバーがエージェント設定で指定されています。 エージェントは2つのサーバーを自動的に切り替えます。
ITMの履歴のコレクションは、同じトリガーによって実装されますが、システムでのみ履歴としてマークされ、個別に構成されます。 履歴設定に従って、サーバーは履歴のSQL実行要求をエージェントに送信しますが、それらは無条件です(select * from tableなど)。 これらのSQLの結果は、エージェントテーブル内のすべてのデータです。 このデータはファイルに追加されます。 エージェントは、定期的に履歴データを特別なウェアハウスプロキシエージェントに送信します。これにより、通常はウェアハウスと呼ばれる特別なデータベースにデータが格納されます。 エージェントがサーバーまたはプロキシエージェントとの接続を失った場合、履歴ファイルの増大を除いてひどいことは起こりません。 エージェントは、できるだけ早くプロキシ履歴を提供します。 ITMサーバーはウェアハウスデータベースにアクセスできないため、履歴に加えてトリガーが失敗します。

私はオープンソースが好きで、手頃な価格のソリューションには長所と短所があります。 アーキテクチャの選択は、ソリューションが最初に適用された場所によって決定されたという一定の感覚があります。 ITMコアは別の会社の腸で生まれたようで、明らかに90年代前半のどこかにあります。 当時はメモリがほとんどなく、プロセッサは現代の標準では弱いと思います。 このため、洗練されたリソース節約ソリューションが求められていました。