
私たちの目標は、4つのIntel Xeon E7-8890 v4プロセッサを搭載したコンピューターでプログラムを効果的に動作させることです 。 システムには512 GBのRAMが搭載され、Linux 3.10.0-327.el7.x86_64がインストールされ、コードはIntel Parallel Studio XE 2016 U2を使用してコンパイルされました。
トランスポートネットワークで最適なルートを見つける問題は、「巡回セールスマン問題」として知られています。 実際には、これは、例えば、商品を輸送する最良の方法を見つけることです。 当初、この種のタスクの「効率」は最も安価な方法を選択することを意味していましたが、過去数十年にわたって「ルートコスト」の概念が拡大しました。 現在、これには環境への影響、エネルギーの価格、および時間が含まれます。 これに加えて、ビジネスおよびサプライチェーンのグローバル化により、トランスポートネットワークのサイズと複雑さ、ひいては計算の基礎となるモデルが大幅に成長したという事実に至りました。 一般的なルート最適化の問題は、NPハードとして分類されるようになりました。 通常、決定論的な方法は、このような問題の解決には適していません。
分散型マルチコアコンピューティングシステムの開発により、問題を解決するためのヒューリスティックな手法が開発され、特にいわゆるアリコロニー最適化(ACO)アルゴリズムが成功裏に適用されました。 次に、ACOの基本的な実装を分析するプロセスを見て、コードの段階的な改善について説明します。 今後、最適化手法により、プログラムを理論上達成可能なパフォーマンスおよびスケーラビリティレベルに近づけることができました。
antアルゴリズムについて
プログラムで使用されているアルゴリズムについて話しましょう。 アリのコロニーの行動に基づいています。 昆虫は食物源を探しており、他のアリを引き付けるフェロモンが通る道を示しています。 時間の経過とともに、フェロモンは蒸発します。つまり、長いパスは短いパスよりも魅力が少なくなります。 その結果、パスが短くなったり速くなったりするほど、より多くのアリが関心を持ち、パスに沿って通過するアリのそれぞれがさらに魅力的になります。
次の図は、トランスポートネットワークの例を示しています。 実線はノード間の直接ルートを示し、点線は間接ルートを示します。

トランスポートネットワークの例
単純なコンピューターエージェントは、確率論的アプローチを使用して、antアルゴリズムを使用してトランスポート問題の解決策を見つけることができます。 ただし、このアルゴリズムの並列実装は、いくつかの制限により異なりますが、過去にすでに調査されています。
そこで、2002年に、Marcus Randall氏は、タスクを並列化するためのアプローチを示す資料(Ant Colony Optimizationの並列実装、Journal of Parallel and Distributed Computing 62)を公開しました。 ただし、この実装では、フェロモンマトリックスを維持するために、それぞれがモデルの独立したユニットである「アリ」間の多数の相互作用が必要であり、それらは並行して作用しました。 その結果、ソリューションのパフォーマンスは、アリ間のメッセージパッシングインターフェイス(MPI)によって制限されていました。
2015年に、技術を使用して輸送ネットワークを最適化するための方法論を説明する資料が発行されました(Veluscek、M.、T。Kalganova、P。Broomhead、A.Grichnik、輸送ネットワーク最適化の複合目標法、Expert Systems with Applications 42) OpenMPおよび共有メモリ。 ただし、このアプローチは、処理コアとスレッドの数が比較的少ないシステムにのみ適しています。
アルゴリズムの基本的な実装
以下は、antアルゴリズムの並列実装の基礎となるアーキテクチャのブロック図です。 彼女と一緒に実験を始めました。

Antアルゴリズムの最適化されていない実装のスキーム
この図は、「月」ごとに起動される反復プロセスの数を示しています。 それぞれで、「アリ」のグループがネットワークにリリースされ、フェロモンマトリックスが構築されます。 各反復プロセスは完全に独立しており、独自のスレッドで実行されます。
ここでは静的なジョブ分散が使用され、各OpenMPスレッドがその役割を果たし、ローカルソリューションを見つけます。 すべてのスレッドの実行が完了すると、メインスレッドは見つかったローカルソリューションを比較し、グローバルになる最適なソリューションを選択します。
基本的なテスト結果
利用可能な処理コアの数を増やしたときに、アプリケーションが効果的にスケーリングするかどうかを調べる最も速い方法の1つは、次のとおりです。 まず、1つのプロセッサ(NUMAノード)で基本的なパフォーマンスインジケーターを取得します。 次に、この指標を、ハイパースレッディングテクノロジを使用した場合と使用しない場合の両方で、複数のプロセッサで起動時のパフォーマンスを測定した結果と比較します。 理想的なシナリオでは、パフォーマンスが処理コアの数のみに依存すると仮定すると、2つのソケットを備えたシステムは1つのシステムを備えたシステムの2倍のパフォーマンスを示します。
下の図では、アプリケーションの基本バージョンのテスト結果を見ることができます。 今、私たちのコードは理想からはほど遠いです。 ソケットの数が2(48コア)を超えた後、プログラムはあまりうまくスケーリングしません。 ハイパースレッディングが有効な4つのソケット(192個の論理コア)では、単一のソケットを使用する場合よりもパフォーマンスがさらに低下します。

アルゴリズムの基本的な最適化されていない実装のテスト
これは私たちが必要とするものではないので、VTuneアンプを使用してプログラムを研究する時が来ました。
VTune Amplifier XEを使用したアルゴリズムの基本的な実装の分析
アプリケーションが複数のプロセッサで正常に動作するのを妨げるものを見つけるために、VTune Amplifier XE 2016 Hotspot分析を使用し、プログラムの最も負荷の高いセクションを探します。 VTuneアンプで測定を行う際、収集されるデータのサイズを制限するために、ワークロードが削減されました(384の反復プロセス)。 他のテストでは全負荷(1000回の反復)を使用しました。
下の図は、VTuneレポートを示しています。 特に、Top Hotspotsグループのインジケーターと、連続コード実行に費やされた時間を確認できるSerial Timeインジケーターに関心があります。

トップホットスポットレポート
レポートから、アプリケーションがコードを連続して実行するのに多くの時間を費やしていることがわかります。これは、システムリソースの並列使用に直接影響します。 プログラムの最もロードされた部分は、文字列を操作するための標準ライブラリのメモリ割り当てモジュールです。これは、多数のコアでは十分に拡張できません。 これは重要な発見です。 事実、OpenMPは1つの共有メモリプールを使用するため、異なるスレッドから文字列コンストラクターまたはオブジェクトのメモリ割り当てモジュール(new演算子を使用)への膨大な数の並列呼び出しにより、メモリがボトルネックになります。 以下のCPA使用状況インジケーターを見ると、利用可能な96個のコアすべてを使用しているにもかかわらず、アプリケーションが非効率的に実行し、短時間でしかロードしないことがわかります。

CPU使用率
フローのビジー状態を見ると、フローの負荷が均衡していないことがわかります。

不均衡な負荷
そのため、各「月」の終わりにあるメインスレッド(マスター)が計算を実行し、他のスレッドは現時点では何の役にも立ちません。
次に、コードを分析した後、その最適化を処理します。
最適化番号1。 MPIとOpenMPの共有
基本実装に存在するOpenMPストリームの大規模なセットを取り除くために、標準の「マスタースレーブ」アプローチを使用し、アプリケーションに別のレベルの並列処理を追加しました。 つまり、並列に実行されるMPIプロセスは、それぞれが特定の数のOpenMPスレッドを含んでおり、個別の反復で計算を担当します。 これで、文字列とオブジェクトにメモリを割り当てることに関連する負荷がMPIプロセス全体に分散されます。 このようなACOアルゴリズムのハイブリッドMPI-OpenMP実装を以下のフローチャートに示します。

最適化された実装番号1
VTuneアンプで得たものをテストしましょう
VTune Amplifier XEを使用した最適化されたアルゴリズム実装の分析
基本バージョンと同じ方法論を使用して、アプリケーションの最適化バージョンを調査しています。 次の図は、Top Hotspotsレポートを示しています。これは、プログラムが文字列のメモリ割り当て操作に費やす時間が少なくなったことを示しています。

トップホットスポットレポート
そして、ベース(左)と最適化されたバージョンのプログラムでのプロセッサ使用率のヒストグラムです。

CPU使用率のヒストグラム
これが、ストリームの読み込みの外観です。 以前よりもはるかにバランスが取れていることがわかります。

負荷分散
次の図では、使用可能な96個のコアがすべて完全にロードされていることがわかります。
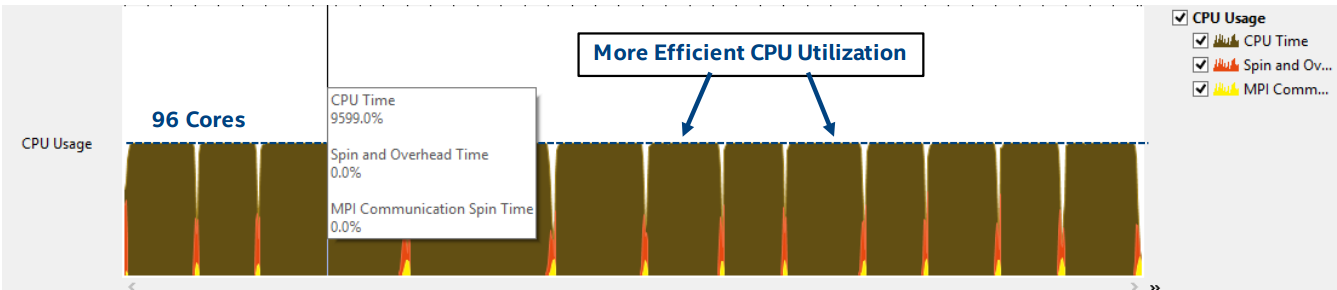
CPU使用率
残念ながら、OpenMPストリームで待機するのに時間がかかりすぎており、最適なソリューションを見つけたMPIプロセスが結果ファイルを更新するためにメインプロセスにデータを送信するとき、MPIデータを交換します。 これは、システムがMPI通信操作で過負荷になるという事実によるものと想定しました。
MPIは分散メモリインターフェイスを使用し、各プロセスは個別のメモリプールで動作します。 その結果、1つのプロセスによるオブジェクトとデータ構造の変更は別のプロセスには見えませんが、同時にMPIの送受信メカニズムを使用してプロセス間のデータを送信する必要があります。 同じことが、現在の「月」に見つかった最適なソリューションのメインプロセスへの転送にも当てはまります。
見つかったグローバルソリューションは、複雑なC ++オブジェクトです。これは、派生クラスの多数のオブジェクト、データを含むスマートポインター、およびSTLテンプレートのその他のオブジェクトで構成されています。 MPI通信操作はデフォルトで複雑なC ++オブジェクトの交換をサポートしていないため、送信および受信メカニズムを使用するにはシリアル化が必要です。その間、オブジェクトは送信前にバイトストリームに変換され、受信後、ストリームは再びオブジェクトに変換されます。
シリアル化によって作成される負荷は一定です。 実行中のMPIプロセスの数に関係なく、多くても「月」に1回発生します(または、メインプロセスのランク0がグローバルとして認識される最適なソリューションを見つけた場合はまったく発生しません)。 これは、複数のコアでのプログラム実行への移行中にMPI通信操作を最小限に抑えるために非常に重要です。
上の図では、追加の負荷が黄色(MPI通信操作)および赤色(スタンバイおよび過負荷)で強調表示されています。
最適化結果No. 1
プログラムのハイブリッドMPI-OpenMPバージョンは、MPIプロセスとOpenMPスレッド間のロードバランシングに関して、はるかに優れた結果を示しました。 また、Intel Xeon E7-8890プロセッサを搭載したシステムで使用可能な多数のコアをはるかに効率的に使用することも実証しました。 基本バージョンと比較して、現在のバージョンのプログラムのテスト結果は次のようになります。
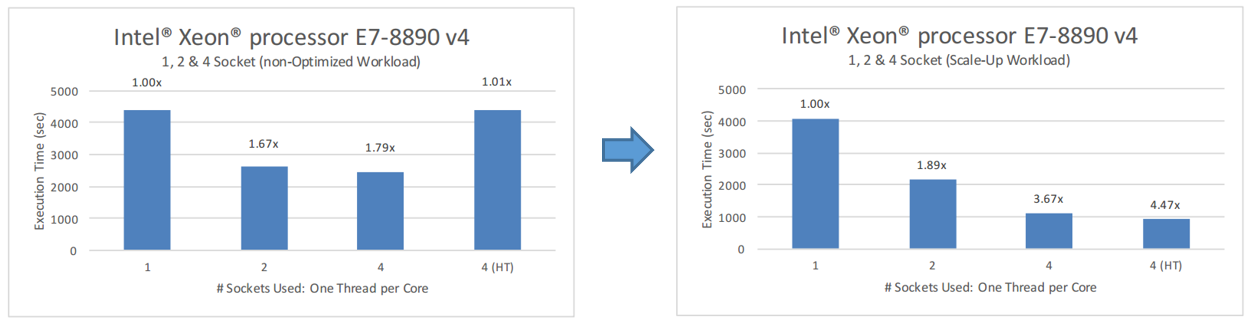
プログラムの基本バージョンと最適化バージョンの結果の比較
ここでは、利用可能なコアの数が増えると、プログラムのスケーラビリティが大幅に向上することがわかります。 パフォーマンスの向上は、ハイパースレッディングが有効な場合にも見られます。
良好な結果を達成しましたが、最適化作業はまだ完了していません。 インテルTBBライブラリーを使用して、コードのパフォーマンスをさらに向上させます。
最適化番号2。 Intel TBBアプリケーション
ハイブリッドMPI-OpenMPアプリケーション実装のコードの最もロードされたセクションを調べたところ、文字列を操作するための実行時間のかなりの割合が依然として標準ライブラリにかかっていることがわかりました。 Intel TBBの動的メモリ割り当てライブラリを使用すると状況が改善されるかどうかを確認することにしました。 このライブラリは、STLの標準std:アロケータークラスに似たいくつかのメモリ割り当てパターンを提供し、scalable_allocatorおよびcache_aligned_allocatorも含みます。 これらのパターンは、並行プログラミング問題の2つの重要なグループの解決に役立ちます。
最初のグループはスケーリングの問題です。 それらは、メモリ割り当てメカニズムが単一の共有プールを競うこともあるという事実が原因で発生します。さらに、最初のシリアルデバイスデバイスでは、一度に1つのスレッドのみがメモリを割り当てることができます。
問題の2番目のグループは、リソースへの共有アクセスに関連しています。 たとえば、2つのスレッドが同じキャッシュラインの異なるワードにアクセスしようとする状況が考えられます。 プロセッサキャッシュ間の情報交換の最小単位はラインであるため、各ラインが異なるワードで動作する場合でも、プロセッサ間で送信されます。 キャッシュラインの移動には数百クロックサイクルかかることがあるため、偽共有はパフォーマンスを低下させる可能性があります。
Intel TBBとの連携機能
インテルTBBがアプリケーションに適しているかどうかを確認する最も簡単な方法の1つは、標準の動的メモリ割り当て関数をインテルTBBライブラリlibtbbmalloc_proxy.so.2の関数に置き換えることです。 これを行うには、プログラムが環境変数LB_PRELOADを使用して起動するときに(実行可能ファイルを変更せずに)ライブラリをロードするか、実行可能ファイルをライブラリに関連付けます。
: -ltbbmalloc_proxy LD_PRELOAD $ export LD_PRELOAD=libtbbmalloc_proxy.so.2
最適化結果No. 2
標準のメモリ割り当てメカニズムを使用するときに発生する最も重要なスケーリング問題を解決するため、Intel TBBの動的メモリ割り当てライブラリは、アプリケーションのハイブリッドMPI-OpenMPバージョンと比較して6%のパフォーマンスを追加します。

Intel TBBによるパフォーマンスの改善
最適化番号3。 MPIプロセスとOpenMPストリームの最適な組み合わせを見つける
この段階で、同じ負荷でMPIプロセスとOpenMPスレッドのさまざまな組み合わせのパフォーマンスへの影響を調査することにしました。 この実験では、192個の利用可能なすべての論理コアを使用しました。つまり、4つのプロセッサーが関与し、ハイパースレッディングテクノロジーが有効になりました。 テスト中に、MPIプロセスとOpenMPストリームの最適な比率が見つかりました。 つまり、それぞれが3つのOpenMPストリームを実行する64のMPIプロセスを使用して最良の結果が得られました。

MPIプロセスとOpenMPストリームのさまざまな組み合わせのパフォーマンス比較。
まとめ
antアルゴリズムの基本的な並列実装の研究により、文字列とオブジェクトコンストラクターのメモリ割り当てメカニズムに関連するスケーリングの問題を特定することができました。
最適化の最初の段階では、MPIとOpenMPを使用したハイブリッドアプローチの使用により、プロセッサリソースの使用効率が向上し、生産性が大幅に向上しました。 ただし、プログラムはメモリの割り当てに多くの時間を費やしました。
第二段階では、Intel TBBの動的メモリ割り当て用ライブラリのおかげで、生産性をさらに6%向上させることができました。
パフォーマンス改善の第3段階では、プログラムでは64個のMPIプロセスの組み合わせが最適であり、それぞれが3つのOpenMPストリームを実行することがわかりました。 同時に、コードは192のすべての論理コアでうまく機能します。 最終的な最適化結果は次のとおりです。

最適化結果
その結果、すべての改善の後、プログラムは基本バージョンより5.3倍速くなりました。 これは価値のある結果であり、研究とコードの最適化に費やす価値があると考えています。