
Goをプレイするための謙虚なボットを開発しています。 そして、私はロシア語でこのトピックに関する情報が不足していることに心から驚いています。 そのため、この記事で蓄積した知識を共有することにしました。
単純なボットの作成方法について説明します。 移動とヒューリスティックアルゴリズムの検索から始まり、KGSオンラインサーバーでの作成物の公開までの主要な段階について説明します。
コンピュータ郭の簡単な歴史:
1968-アルバート・ゾブリストが書いた囲inでの最初のプログラム
1984-ゴープログラムの最初の選手権
1990年代-プログラムは25〜30ストーンのハンディキャップでプロに負けました
2006-CrazyStoneは、モンテカルロ法を使用してコンピューターオリンピックを受賞しました
2008-MoGoプログラムが19x19ボードで8段のプロのハンディキャップを9ストーンで獲得
2010-ZenがKGSサーバーで3段目を獲得
2013-CrazyStoneは4つのハンディキャップストーンで第9ダンのプロフェッショナルを破りました
2015-AlphaGoが5試合中5試合で欧州チャンピオンを獲得、ハンディキャップなし
2016-AlphaGoはハンディキャップなしでプロのリー・セドルによる一連の試合に勝ちます
1984-ゴープログラムの最初の選手権
1990年代-プログラムは25〜30ストーンのハンディキャップでプロに負けました
2006-CrazyStoneは、モンテカルロ法を使用してコンピューターオリンピックを受賞しました
2008-MoGoプログラムが19x19ボードで8段のプロのハンディキャップを9ストーンで獲得
2010-ZenがKGSサーバーで3段目を獲得
2013-CrazyStoneは4つのハンディキャップストーンで第9ダンのプロフェッショナルを破りました
2015-AlphaGoが5試合中5試合で欧州チャンピオンを獲得、ハンディキャップなし
2016-AlphaGoはハンディキャップなしでプロのリー・セドルによる一連の試合に勝ちます
ほとんどの最新のエンジンエンジンの人工知能の基礎は、モンテカルロ法、またはその実装であるUCTアルゴリズムです。 私はすでにこのアルゴリズムについて詳細に書いています 。 しかし、簡潔かつ公式がなければ、彼の作品は次のように説明できます。
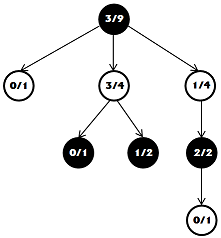
ある段階で検索を停止し、動きの木が写真のように見えることを想像してみましょう。 各ノードには2つの数字があり、最初の数字は勝ったランダムゲームの数で、2番目の数字はそのようなゲームの総数です。
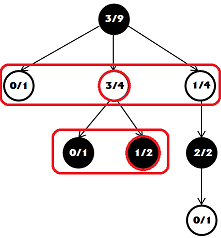
次に、ツリー内で最適な動きを見つける必要があります。 このために、最上位から始めて、各レベルで、勝利と敗北の最高の比率で最も成功した動きを見つけます。
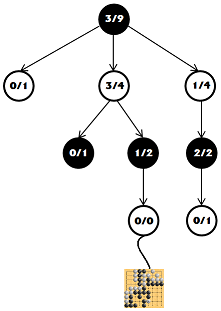
ここで、有効な移動のリストから、いずれかを選択してツリーに追加します。 そして、これらすべての検索が無駄にならないように、このサイトからゲームゲームをプレイしましょう。 ゲームは最後まで続き、その中の動きはランダムに選択されます。
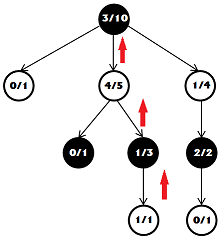
ゲームをプレイした後、ポイントを数えて勝者を決定します。 次に、ツリーに沿って戻り、各ノードにアクセスすると、その値に結果を追加します。 勝者側のノードは勝利数とゲーム数の両方を増やし、敗者はゲーム数だけを増やします。
その後、すべてが最初からやり直され、ゲームの結果を検索、公開、ランダムにプレイし、逆配信します。 そのようなパスは、1ターンあたり1000回ではなく、より多くの場合数万回になります。 したがって、動きのツリーが構築されます。 各レベルの移動選択式のおかげで、ツリーは均等に構築されません。 最高の動きはより深く探求されます。 ゲームの数が多いほど、アルゴリズムの予測はより正確になります。 最後に、ゲーム/訪問が最も多い移動が選択されます。
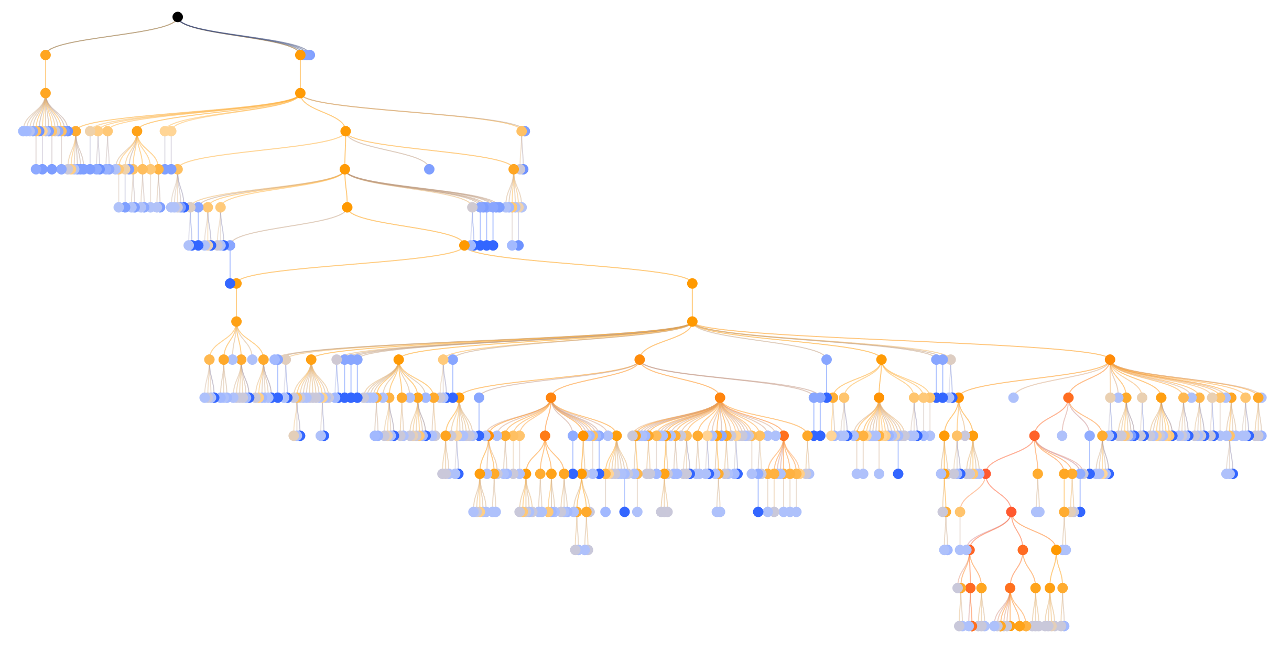
MCTSアルゴリズムのツリーの不均一性
ゲームの総数に対する勝ったゲームの比率は、各動きで勝つチャンスとして説明できます。 この値の範囲は0〜1です。数値が大きいほど、この特定の動きが彼を勝利に導くと確信しています。 最良の動きに対するこの関係の重要性は、プログラムがパーティー全体で勝つ可能性をどのように評価するかを示しています。
しかし、パーティーの終わりの意味を理解しましょう。 Goでは、誰も最後までゲームをプレイせず、結果が明白になるとゲームは停止します。 マシンにとって、このアプローチは理解不能であり、したがって、プレイヤーは誰もルールを破らずにボード上に石を置くことができなくなるまで、パーティーに行きます。 この場合、その石に囲まれたフィールド(いわゆる目)での移動は禁止されています。 その結果、ゲームの終了時には、フィールドは次のようになります。

スコアリングのために、各プレーヤーに囲まれた無料ポイントと、ボード上の石の数を数えます。 これらは、いわゆる中国のカウント規則です。 使用されているのは中国のカウントシステムであるため、ポイントを失うことなく安全に領土に石を置くことができます。 日本のルールでは、自分の領土に石を置く必要性を判断するのに時間を費やす必要があります。 余分な石はポイントを取ります。
Koルールに言及する価値があります。 Koルールは、前の動きの前にあったボード上のポジションの繰り返しを禁止するルールであることを思い出させてください。
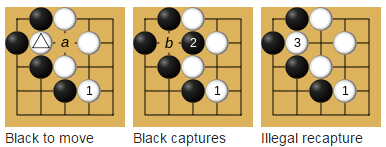
このルールを実装する方法は? 結局、ボード全体を保存し、1万ゲームの各ターンで各フィールドを比較することは、リソースを消費しすぎます。 明らかに、ある種のハッシュ関数を使用する必要があります。 囲go、チェス、その他のゲームでは、Zobristハッシュと呼ばれるアルゴリズムがそのようなタスクに使用されます。 一般に、このアルゴリズムは元々、goを再生するプログラムのために発明されました。 これは、各ボードフィールドおよび各ピース(goの場合は2つのみ)に対して、ランダムな値が生成されるという事実から成ります。 空のフィールドに石を置くと、このフィールドに対応する値と石の色をテーブルから取得し、前の位置のハッシュでXOR演算を実行します。 ストーンがポジションから削除される場合、同じ方法で、テーブルからこのポジションのこのストーンの値でXORハッシュを作成します。
次のようになります。
black_stone = 1 white_stone = 2 … table = zobrist_init(board_size) ... h = h XOR table[i][j]
ここで、hはボードの現在のハッシュ値、iはボード上の位置インデックス、jは形状インデックス(1または2)です。
このハッシュは、すでに訪れた位置の評価に時間を浪費しないように、モンテカルロツリー内の繰り返し位置をカットするためにも使用できます。
また、このKoルールの定義を使用できます。前の動きに置かれた場合、ボードから1つだけの石を削除することはできません。
ここでは、ボードの状態をチェックする代わりに、この条件が満たされていることを確認できます。
多かれ少なかれ意味のあるゲームプログラムには、単純なモンテカルロアルゴリズムと数千のランダムゲームの数ですでに十分です。 ただし、ランダムゲームの精度は、アルゴリズムの精度にも影響します。 それらをランダムでなく、実際のゲームのようにすると、効率を大幅に向上させることができます。 実際、人が行動を起こし、自分の決定のおおよその結果を計算するとき、彼はゲームのコンテキストからの知識を使用します。
ランダムゲームを非ランダムにするために、多くの異なるアプローチが使用されます。 実際、創造性の段階が始まり、未来のAIのゲームのキャラクターが設定されるのはここです。
多くのプログラムは、この目的のためにテンプレートを使用します。 たとえば、MoGoおよびFuego Goは、問題のフィールドが中央にある3x3テンプレートを使用します。 GNUGoでは、テンプレートははるかに多様で複雑です。
例として、次のような3x3テンプレートを見てみましょう。
["XO?", "Oo", "?o?"]
ここで、XとOは色、xとoはそれぞれ「not X」と「not O」です。 -これは任意のフィールド値であり、ドットは空のフィールドを意味します。 このパターンは、ある色の石の切断または異なる色の石の切断に対する保護をシミュレートします。 つまり、両方のプレーヤーに適しています。 中央には、私たちが石を置きたい同じ空のフィールドがあります。
実際、そのようなテンプレートはそれほど必要ありません。 ゲームが実際のゲームに似ているのに十分なのはたったの12個です。 テンプレートは、FuegoやMoGoなどのプログラムを説明している出版物またはそのコードに記載されています。
多くのランダムなゲームでプロセッサ時間を節約するために、テンプレートは最後の動きの近くにのみ適用されます。 これはGoの機能とよく一致しています。Goの機能では、通常、相手の動きに応じて動きが設定されます。
他のヒューリスティックもテンプレートと組み合わせて使用されます。 ここでは、空想の飛行を制限することはできず、独自の何かを思い付くことができます。 Pachi、KGS 2dで使用されるヒューリスティックの例を次に示します。
- Nakadeは、グループを殺すための一般的な手法です。 相手が2つの目を作成できないように、グループ内で移動が行われます。 プログラムはそのような状況を監視し、重要なポイントに石を置きます。

- 最後の動きで敵が彼のグループをアタリに入れた場合(グループが死亡する前に1動き)、それをキャプチャします。
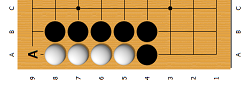
- 最後の動きの相手がグループの呼吸ポイントの数を2に減らした場合、グループをアタリに入れようとします。 私たちのグループがそのような状況にあるとわかった場合、私たちは敵の隣のグループを逃れるか、アタリに入れようとしています。
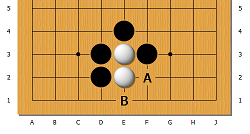
ランダムゲームの各ヒューリスティックは、テンプレートと同様に、ボード全体ではなく、その一部のみに適用されます。 これらはすべて一緒に使用することも、順番に使用することもできます。 リソースを節約するには、2番目のオプションの方が適しています。
ツリー内の検索中、モンテカルロアルゴリズムの場合、すべての動きは等しくなります。 それぞれの新しいノードの値はゼロです。 プログラムは、いくつかのランダムなゲームをプレイするまで、これらの動きのどれが良いか悪いかを理解しません。 初期段階で明らかに役に立たないか悪い動きの考慮を断ち切るため、あるいは明らかに良い動きを優先するために、発見的機能も検索中に使用されます。
ここでは、ランダムゲーム中と同じ機能を使用できますが、ボード全体にのみ適用されます。 ランダムロットに含まれていない追加のヒューリスティックを使用できます。
たとえば、問題の移動がボードの1行目または2行目にあり、周囲に石が1つもない場合、この移動には負の優先順位を割り当てる必要があります。 同じ条件下で石を3行目に配置したい場合は、この移動に肯定的な優先順位を割り当てます。 この動きは、アルゴリズムにより詳細に考慮される必要があります。
移動を促進するには、ゲームの数と勝ちの数に優先順位の値を追加する必要があります。
good_node.games = GOOD_MOVE_PRIOR; good_node.wins = GOOD_MOVE_PRIOR;
逆の効果のために、値はゲーム数にのみ追加されます:
bad_node.games = BAD_MOVE_PRIOR; bad_node.wins = 0;
したがって、アルゴリズムの適切な位置は、より有望に見えます。なぜなら、彼は多くの勝利を収めているからです。 優先順位が負の場合、すべてがまったく逆になります。アルゴリズムにとっては、ほとんどのランダムゲームで負けるのは負けです。

ポイントC7付近の石を確認します。 都市ブロックの距離メトリックが使用されます。
それで、エンジンの準備ができていて、それをテストしたいとしましょう。 グラフィカルインターフェイスを接続したり、オンラインでプレイしたりする場合は、一般に認識されているgoプログラムの標準であるGo Text Protocol(GTP)を使用する必要があります。 これを使用して、作成したものをグラフィカルインターフェイスに接続したり、KGSサーバーで実行したりできます。
プロトコルの実装は非常に簡単です。いくつかのコマンドを理解するようにボットに教える必要があります。
- list_commands-サポートされているコマンドのリストをボットに要求します。結果は、各コマンドの後に行末文字を含むリストになります。
- ボードサイズn-ゲームがサイズnのボードでプレイされることをプログラムに伝えます
- komi 6.5-チームは、Komiが6.5ポイントで使用されていると言います
- clear_board-サイズnの新しい空のボードを作成します
- genmove w-白の動きを生成するエンジンへの要求(黒の場合はbになります)
- play b A1-プレイヤーが段落A1に黒い石を置いたことを意味します
各コマンドに対するボットの応答は、「=」記号で始まる必要があります。 この記号は、プログラムがコマンドを理解し、次のコマンドを待っていることも意味します。 コマンドが不明な場合は、疑問符が表示されます。
例として、実際のゲームでメッセージを伝えましょう。
list_commands = boardsize list_commands name play clear_board komi quit genmove boardsize 9 = komi 6.5 = clear_board = play b E5 = genmove w = d4
この例では、ゲームは9x9ボードで行われ、人はポイントE5で黒をプレイし、プログラムはポイントd4に答えます。 ボード上のアイテムの座標には、記号部分とアルファベット部分があることに注意してください。 これは、いわゆるチェス表記のセルの命名です。
DragoなどのGTPプロトコルをサポートするグラフィックプログラムでエンジンを使用できるようになりました。
KGSサーバーでボットを実行する場合は、 kgsGTP中間プログラムを使用する必要があります。
実行するには、次のコマンドを入力します。
java -jar kgsGtp.jar kgsgtp.ini
ここで、kgsgtp.iniは設定ファイルです。 サンプルファイル:
名前 = login_bot
パスワード =パスワード
room = Computer Go //ボットが入室する部屋の名前
mode = custom //動作モード、kgsGtpマニュアルの詳細
game Notes = "こんにちは、私はここで知っています" // Welcome Line
rules.boardSize = 9 //ボットがプレーしているボードのサイズ
undo = f //「後方に移動」コマンドをサポート
エンジン =パス/ to /プログラム
相手 =相手ログイン
対戦相手のオプションが指定されている場合、プログラムは指定された人とのみプレイできます。 これはボットのデバッグに便利です。
もちろん、GoをプレイするためにAIで使用されるのはこれだけではありません。 記事の外では、All-Moves-As-FirstおよびRAVE、Common Fate Graph、畳み込みニューラルネットワークなどの興味深いものが残っていました。 しかし、この資料を始めるには十分です。 ソースのリストには、多くの追加情報があります。
ソースのリスト
senseis.xmp.net/?ComputerGo
hal.inria.fr/inria-00117266v3/document
users.soe.ucsc.edu/~glin/docs/Fuego_Fall09Report.pdf
pasky.or.cz/go/pachi-tr.pdf
pdfs.semanticscholar.org/87b8/9babfa66c3bc33ad579e59e65321fb4b6d48.pdf
github.com/pasky/michi
www.cs.cmu.edu/afs/cs/user/mjs/ftp/thesis-program/2008/abstracts/lowEA.pdf
arxiv.org/pdf/1412.6564v2.pdf
hal.inria.fr/inria-00117266v3/document
users.soe.ucsc.edu/~glin/docs/Fuego_Fall09Report.pdf
pasky.or.cz/go/pachi-tr.pdf
pdfs.semanticscholar.org/87b8/9babfa66c3bc33ad579e59e65321fb4b6d48.pdf
github.com/pasky/michi
www.cs.cmu.edu/afs/cs/user/mjs/ftp/thesis-program/2008/abstracts/lowEA.pdf
arxiv.org/pdf/1412.6564v2.pdf
私のボット: