免責事項:投稿には多くのasciiグラフィックがあります。 モバイルデバイスからそれを読まないでください-テキストフォーマットはあなたを失望させます。
今日、私たちはすべてのデータ構造について学びます。
「おお、なんて面白い…」と?
はい、今日で最もジューシーなトピックではありませんが、非常に重要です。 CS101のようなコースを受講するためではなく、プログラミングをよりよく理解するためです。
データ構造を知ることは次のことに役立ちます。
- プログラムの複雑さを管理し、理解しやすくします。
- メモリを効率的に使用する高性能プログラムを作成します。
最初の方が重要だと思います。 適切なデータ構造は、混乱を招くロジックを排除することでコードを劇的に簡素化できます。
2番目のポイントも重要です。 プログラムのパフォーマンスまたはメモリを考慮すると、データ構造の正しい選択は作業に大きく影響します。
データ構造に慣れるために、それらのいくつかを実装します。 心配しないでください、コードは簡潔になります。 実際、さらにコメントがあり、それらの間のコードは1つ、2つ、計算ミスです。
============================================================================ ,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-' ============================================================================
============================================================================ ,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-' ============================================================================
データ構造とは何ですか?
実際、これらはさまざまな問題をより効果的に解決するためにデータを保存および整理する方法です。 データはさまざまな方法で表示できます。 どのようなデータで、どのようなデータを使用するかに応じて、1つのプレゼンテーションが他のプレゼンテーションよりも効果的です。
これが起こる理由を理解するために、まずアルゴリズムについて話しましょう。
/*** ===================================================================== ***\ * * * ,--,--. ,--,--. * * ,----------. | | | | | | _____ * * |`----------'| | | | | | | | | ,------. * * | | | | | | | | ,--. | oo | |`------'| * * | | ,| +-|-+ | | +-|-+ |` | | |_____| | | * * | | ,:==| | |###|======|###| | |====#==#====#=,, | | * * | | || `| +---+ | | +---+ |' ,,=#==#====O=`` ,| | * * | | || | | | | | | ``=#==#====#=====|| | * * `----------' || | | | | | | |__| `| | * * | | ``=| |===`` `--,',--` `--,',--` /||\ `------' * ** \_/ \_/ / / \ \ / / \ \ //||\\ |_| |_| ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * * * ,--,--. ,--,--. * * ,----------. | | | | | | _____ * * |`----------'| | | | | | | | | ,------. * * | | | | | | | | ,--. | oo | |`------'| * * | | ,| +-|-+ | | +-|-+ |` | | |_____| | | * * | | ,:==| | |###|======|###| | |====#==#====#=,, | | * * | | || `| +---+ | | +---+ |' ,,=#==#====O=`` ,| | * * | | || | | | | | | ``=#==#====#=====|| | * * `----------' || | | | | | | |__| `| | * * | | ``=| |===`` `--,',--` `--,',--` /||\ `------' * ** \_/ \_/ / / \ \ / / \ \ //||\\ |_| |_| ** \*** ===================================================================== ***/
アルゴリズム
アルゴリズムとは、実行される一連のアクションのsuchな名前です。
データ構造はアルゴリズムを使用して実装され、アルゴリズムはデータ構造を使用して実装されます。 すべてがデータ構造とアルゴリズムで構成されており、顕微鏡の小さな男性がパンチカードを使って走り、コンピューターを機能させるレベルまでです。 (まあ、はい、Intelはサービスに顕微鏡の人々を持っています。起きてください!)
特定のタスクは、無数の方法で実現されます。 その結果、一般的な問題を解決するために多くの異なるアルゴリズムが発明されました。
たとえば、要素の順序付けられていないセットをソートするには、途方もなく多くのアルゴリズムがあります。
挿入ソート、選択ソート、マージソート、バブルソート、ヒープソート、クイックソート、シェルソート、ティムソート、ブロックソート、ビット単位ソート...
それらのいくつかは他のものよりもはるかに高速です。 他のものはより少ないメモリを消費します。 さらに、他の実装も簡単です。 4つは、データセットに関する仮定に基づいています。
各ソートは、特定のタスクに最適です。 したがって、アルゴリズムを相互に比較する方法を理解するために、まずニーズと基準を決定する必要があります。
アルゴリズムのパフォーマンスを比較するために、平均生産性と最悪の場合のパフォーマンスの大まかな測定値を使用して、「O」という用語が大きく使用されていることを示します。
/*** ===================================================================== ***\ * abd * * ab O(N^2) d * * O(N!) ab O(N log N) dc * * abdc * * abdc O(N) * * abdc * * abdc * * abdc * * ab c O(1) * * eeee ec deeeeeeee * * ba cd * * ba cdfffffff * ** cadf fdfffff O(log N) ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * abd * * ab O(N^2) d * * O(N!) ab O(N log N) dc * * abdc * * abdc O(N) * * abdc * * abdc * * abdc * * ab c O(1) * * eeee ec deeeeeeee * * ba cd * * ba cdfffffff * ** cadf fdfffff O(log N) ** \*** ===================================================================== ***/
ああ大きい
「O」大-相対比較のためのアルゴリズム性能の概算推定方法の指定。
Oh big-コンピュータサイエンスが借用した数学的表記法。転送されるN個のデータの量とアルゴリズムの関係を決定します。
Oラージは、2つの主要な量を特徴付けます。
推定実行時間 -特定のデータセットに対してアルゴリズムが実行する操作の総数。
ボリューム推定は、アルゴリズムが特定のデータセットを処理するために必要なメモリの総量です。
見積もりは互いに独立して行われます。一部のアルゴリズムは、より多くのメモリを使用しながら、他のアルゴリズムよりも少ない操作を実行できます。 要件を定義したら、適切なアルゴリズムを選択できます。
About Bigの一般的な意味は次のとおりです。
, ---------------------------------------------------------------------------- O(1) !! O(log N) ! O(N) . - O(N log N) ... O(N ^ 2) O(2 ^ N) O(N!)
私たちが話している数字の順序を知るために、これらの値がNに依存するものを見てみましょう。
N = 5 10 20 30 ----------------------------------------------------------------------- O(1) 1 1 1 1 O(log N) 2.3219... 3.3219... 4.3219... 4.9068... O(N) 5 10 20 30 O(N log N) 11.609... 33.219... 84.638... 147.204... O(N ^ 2) 25 100 400 900 O(2 ^ N) 32 1024 1,048,576 1,073,741,824 O(N!) 120 3,628,800 2,432,902,0... 265,252,859,812,191,058,636,308,480,000,000
ご覧のとおり、比較的小さな数字でも* dofiga *余分な作業を行うことができます。
データ構造を使用すると、アクセス、検索、挿入、削除という4つの主要なアクションを実行できます。
データ構造は、一方のアクションでは良いが、もう一方のアクションでは悪いことに注意してください。
------------------------------------------------------------------------ O(1) O(N) O(N) O(N) O(N) O(N) O(1) O(1) O(log N) O(log N) O(log N) O(log N)
または...
------------------------------------------------------------------------
さらに、一部のアクションでは、「平均」パフォーマンスと「最悪の場合」のパフォーマンスが異なります。
理想的なデータ構造は存在しません。 データとその処理方法に基づいて、最適なものを選択します。 適切な選択を行うには、さまざまな一般的なデータ構造を知ることが重要です。
/*** ===================================================================== ***\ * _.-.. * * ,'9 )\)`-.,.--. * * `-.| `. * * \, , \) * * `. )._\ (\ * * |// `-,// * * ]|| //" * ** hjw "" "" ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * _.-.. * * ,'9 )\)`-.,.--. * * `-.| `. * * \, , \) * * `. )._\ (\ * * |// `-,// * * ]|| //" * ** hjw "" "" ** \*** ===================================================================== ***/
記憶
コンピューターのメモリは退屈なものです。 これは、情報が保存される順序付けられたスロットのグループです。 アクセスするには、メモリ内のアドレスを知る必要があります。
メモリフラグメントは次のように表すことができます。
: |1001|0110|1000|0100|0101|1010|0010|0001|1101|1011... : 0 1 2 3 4 5 6 7 8 9 ...
: |1001|0110|1000|0100|0101|1010|0010|0001|1101|1011... : 0 1 2 3 4 5 6 7 8 9 ...
プログラミング言語でなぜそうなのか疑問に思ったら、カウントは0から始まります-メモリはそのように機能するからです。 メモリの最初のフラグメントを読み取るには、0〜1を読み取り、2番目-1〜2を読み取ります。これらのフラグメントのアドレスは、それぞれ0と1です。
もちろん、コンピューターは例に示されているよりも多くのメモリを持っていますが、そのデバイスは考慮されたテンプレートの原理を継続しています。
記憶の広大さは、野生の西のようなものです。 コンピューターで実行される各プログラムは、同じ*物理*データ構造内に保存されます。 メモリの使用は困難な作業であり、メモリを使用して作業するための抽象化のレベルが追加されています。
抽象化には2つの追加の目的があります。
-データをメモリに保存して、効率的かつ/または迅速に作業できるようにします。
-データをメモリに保存して、使いやすくします。
/*** ===================================================================== ***\ * * _______________________ * * ()=(_______________________)=() * * * * | | * * | ~ ~~~~~~~~~~~~~ | * * * * * | | * * * | ~ ~~~~~~~~~~~~~ | * * * | | * * | ~ ~~~~~~~~~~~~~ | * * * * | | * * * |_____________________| * * * * ()=(_______________________)=() * ** ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * * _______________________ * * ()=(_______________________)=() * * * * | | * * | ~ ~~~~~~~~~~~~~ | * * * * * | | * * * | ~ ~~~~~~~~~~~~~ | * * * | | * * | ~ ~~~~~~~~~~~~~ | * * * * | | * * * |_____________________| * * * * ()=(_______________________)=() * ** ** \*** ===================================================================== ***/
リスト
最初に、メモリとデータ構造間の相互作用の複雑さを示すリストを実装します。
リストは、同じ値が何回でも存在できる値の番号付きシーケンスの表現です。
通常のJavaScript配列で表されるメモリの空のブロックから始めましょう。 リストの長さも保存する必要があります。
実際には、「メモリ」には取得および読み取りが可能な長さの値がないため、長さを個別に保存することに注意してください。
class List { constructor() { this.memory = []; this.length = 0; } //... }
最初のステップは、リストからデータを取得することです。 通常のリストを使用すると、必要なアドレスがすでにわかっているため、メモリに非常にすばやくアクセスできます。
リストアクセス操作の複雑さはO(1)-「FUCKLY !!」です。
get(address) { return this.memory[address]; }
リストにはシリアル番号があるため、先頭、中間、末尾に値を挿入できます。
リストの先頭または末尾に値を追加および削除することに焦点を当てます。 これを行うには、4つのメソッドが必要です。
- プッシュ -値を最後に追加します。
- ポップ -末尾から値を削除します。
- シフト解除 -値を先頭に追加します。
- Shift-先頭から値を削除します。
「プッシュ」操作から始めましょう-リストの最後に要素を追加します。
これは、リストに続くアドレスに値を追加するのと同じくらい簡単です。 長さを保存するため、アドレスの計算は簡単です。 値を追加し、長さを増やします。
リストの最後にアイテムを追加-定数O(1)-「FUCKLY !!」
push(value) { this.memory[this.length] = value; this.length++; }
Haberのコメント: poxuは著者に同意せず、リストにアイテムを追加するのが難しくなるメモリ拡張操作があると説明しています。
次に、「pop」メソッドを実装し、リストの最後から要素を削除します。 プッシュと同様に、最後のアドレスから値を削除するだけです。 さて、長さを短くします。
リストの末尾からアイテムを削除する-定数O(1)-「FUCKLY !!」
pop() { // — . if (this.length === 0) return; // , , . var lastAddress = this.length - 1; var value = this.memory[lastAddress]; delete this.memory[lastAddress]; this.length--; // , . return value; }
「プッシュ」および「ポップ」はリストの最後で機能し、一般的には単純な操作です。これらはリストの残りの部分には影響しないからです。
リストの先頭を操作し、「unshift」と「shift」の操作を行ったときに何が起こるか見てみましょう。
リストの先頭に新しい要素を追加するには、後続のすべての値を1つずつシフトすることにより、この値のスペースを解放する必要があります。
[a, b, c, d, e] 0 1 2 3 4 ⬊ ⬊ ⬊ ⬊ ⬊ 1 2 3 4 5 [x, a, b, c, d, e]
[a, b, c, d, e] 0 1 2 3 4 ⬊ ⬊ ⬊ ⬊ ⬊ 1 2 3 4 5 [x, a, b, c, d, e]
このようなシフトを行うには、各要素を調べて、前の要素をその場所に配置する必要があります。
リストの各要素を通過する必要があるため、次のようにします。
リストの一番上にアイテムを追加すると、O(N)-「NORMAS」と直線的になります。
unshift(value) { // C , . var previous = value; // ... for (var address = 0; address < this.length; address++) { // «current» «previous», // «current» . var current = this.memory[address]; this.memory[address] = previous; previous = current; } // . this.memory[this.length] = previous; this.length++; }
リストを反対方向にシフトする関数-シフトを記述することは残っています。
最初の値を削除してから、リストの各要素を前のアドレスに移動します。
[x, a, b, c, d, e] 1 2 3 4 5 ⬋ ⬋ ⬋ ⬋ ⬋ 0 1 2 3 4 [a, b, c, d, e]
[x, a, b, c, d, e] 1 2 3 4 5 ⬋ ⬋ ⬋ ⬋ ⬋ 0 1 2 3 4 [a, b, c, d, e]
リストの一番上からアイテムを削除する-線形O(N)-「NORMAS」。
shift() { // — . if (this.length === 0) return; var value = this.memory[0]; // , for (var address = 0; address < this.length - 1; address++) { // . this.memory[address] = this.memory[address + 1]; } // , . delete this.memory[this.length - 1]; this.length--; return value; }
リストは、最後にあるアイテムにすばやくアクセスして作業するという素晴らしい仕事をします。 ただし、見たように、メモリアドレスを手動で処理する必要があるため、最初または途中の要素についてはあまり良くありません。
要素のアドレスを知らなくても値を追加、アクセス、削除するための異なるデータ構造とそのメソッドを見てみましょう。
/*** ===================================================================== ***\ * ((\ * * ( _ ,-_ \ \ * * ) / \/ \ \ \ \ * * ( /)| \/\ \ \| | .'---------------------'. * * `~()_______)___)\ \ \ \ \ | .' '. * * |)\ ) `' | | | .'-----------------------------'. * * / /, | '...............................' * * ejm | | / \ _____________________ / * * \ / | |_) (_| | * * \ / | | | | * * ) / | | | | * ** / / (___) (___) ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * ((\ * * ( _ ,-_ \ \ * * ) / \/ \ \ \ \ * * ( /)| \/\ \ \| | .'---------------------'. * * `~()_______)___)\ \ \ \ \ | .' '. * * |)\ ) `' | | | .'-----------------------------'. * * / /, | '...............................' * * ejm | | / \ _____________________ / * * \ / | |_) (_| | * * \ / | | | | * * ) / | | | | * ** / / (___) (___) ** \*** ===================================================================== ***/
ハッシュテーブル
ハッシュテーブルは、順序付けられていないデータ構造です。 インデックスの代わりに、「キー」と「値」を使用して、キーごとにメモリアドレスを計算します。
意味は、キーが「ハッシュ」されており、メモリを効果的に操作できるようにすることです-値の追加、受信、変更、削除。
var hashTable = new HashTable(); hashTable.set('myKey', 'myValue'); hashTable.get('myKey'); // >> 'myValue'
繰り返しますが、メモリを表す通常のJavaScript配列を使用します。
class HashTable { constructor() { this.memory = []; } // ... }
キーと値のペアをハッシュテーブルからメモリに保存するには、キーをアドレスに変換する必要があります。 このハッシュ操作。
キーを入力として受け入れ、このキーに対応する一意の番号に変換します。
hashKey("abc") => 96354 hashKey("xyz") => 119193
このような操作には注意が必要です。 キーが大きすぎる場合、メモリ内の存在しないアドレスにマップされます。
したがって、ハッシュ関数はキーのサイズを制限する必要があります。 使用可能なメモリアドレスの数を無制限の値に制限します。
ハッシュテーブルの実装はすべてこの問題に直面しています。
ただし、作業の構造のみを検討するため、衝突は発生しないものとします。
hashKey関数を定義しましょう。
内部ロジックには入らないでください。入力として文字列を受け取り、(ほとんどの場合)一意のアドレスを返すと信じてください。これは他の関数で使用します。
hashKey(key) { var hash = 0; for (var index = 0; index < key.length; index++) { // ---. var code = key.charCodeAt(index); hash = ((hash << 5) - hash) + code | 0; } return hash; }
ここで、キーごとに値を受け取るget関数を定義します。
ハッシュテーブルから値を読み取ることの難しさは、定数O(1)-「FUCKLY !!」です。
get(key) { // . var address = this.hashKey(key); // , . return this.memory[address]; }
データを受信する前に、まずデータを追加しておくといいでしょう。 set関数はこれに役立ちます。
ハッシュテーブルに値を設定する難しさは、定数O(1)-「FUCKLY !!」です。
set(key, value) { // . var address = this.hashKey(key); // . this.memory[address] = value; }
最後に、ハッシュテーブルから値を削除する方法が必要です。 ハッシュテーブルから値を削除する難しさは、定数O(1)-「FUCKLY !!」です。
remove(key) { // , , . var address = this.hashKey(key); // , . if (this.memory[address]) { delete this.memory[address]; } }
============================================================================ ,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-' ============================================================================
============================================================================ ,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-' ============================================================================
ここで、メモリの直接的な操作を停止します。後続のすべてのデータ構造は、他のデータ構造を介して実装されます。
新しい構造は、次の2つのことに焦点を当てています。
- アプリケーションの機能に基づいてデータを整理する
- 抽象実装の詳細
このようなデータ構造の目的は、さまざまなタイプのプログラムで使用する情報を整理することです。 より複雑なロジックを表現するための言語を提供します。 同時に、実装の詳細が抽象化されます。 実装を変更して、より高速にすることができます。
/*** ===================================================================== ***\ * _ . - - -- .. _ * * |||| .-' /```\ `'-_ /| * * |||| ( /`` \___/ ```\ ) | | * * \__/ |`"-//..__ __..\\-"`| | | * * || |`"||...__`````__...||"`| | | * * || |`"||...__`````__...||"`| \ | * * || _,.--|`"||...__`````__...||"`|--.,_ || * * || .'` |`"||...__`````__...||"`| `'. || * * || '. `/ |...__`````__...| \ .' || * * || `'-..__ `` ````` `` __..-'` || * * `""---,,,_______,,,---""` * ** ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * _ . - - -- .. _ * * |||| .-' /```\ `'-_ /| * * |||| ( /`` \___/ ```\ ) | | * * \__/ |`"-//..__ __..\\-"`| | | * * || |`"||...__`````__...||"`| | | * * || |`"||...__`````__...||"`| \ | * * || _,.--|`"||...__`````__...||"`|--.,_ || * * || .'` |`"||...__`````__...||"`| `'. || * * || '. `/ |...__`````__...| \ .' || * * || `'-..__ `` ````` `` __..-'` || * * `""---,,,_______,,,---""` * ** ** \*** ===================================================================== ***/
スタック
スタックはリストのようなものです。 これらも順序付けられていますが、アクションに制限があります。リストの末尾からのみ値を追加および削除できます。 前に見たように、メモリに直接アクセスすると、これは非常に迅速に発生します。
ただし、他のデータ構造を介してスタックを実装して、追加の機能を取得できます。
スタックを使用する最も一般的な例は、スタックにアイテムを追加するプロセスと、アイテムを最後から削除するプロセスがあり、最近追加したアイテムに優先順位を付けることです。
再びJavaScript配列が必要になりますが、今回はメモリを象徴するのではなく、上記で実装したようなリストを象徴します。
class Stack { constructor() { this.list = []; this.length = 0; } // ... }
リストメソッドと機能的に同じ2つのメソッド、「プッシュ」と「ポップ」を実装する必要があります。
プッシュは、アイテムをスタックの一番上に追加します。
push(value) { this.length++; this.list.push(value); }
ポップは上部からアイテムを削除します。
pop() { // — . if (this.length === 0) return; // . this.length--; return this.list.pop(); }
さらに、peek関数を追加して、スタックの一番上にある要素を削除せずに表示します。 ご注意 Translator:peek-見てみましょう。
peek() { // , . return this.list[this.length - 1]; }
/*** ===================================================================== ***\ * /:""| ,@@@@@@. * * |: oo|_ ,@@@@@`oo * * C _) @@@@C _) * * ) / "@@@@ '= * * /`\\ ```)/ * * || | | /`\\ * * || | | || | \ * * ||_| | || | / * * \( ) | ||_| | * * |~~~`-`~~~| |))) | * * (_) | | (_) |~~~/ (_) * * | |`""....__ __....""`| |`""...._|| / __....""`| | * * | |`""....__`````__....""`| |`""....__`````__....""`| | * * | | | ||``` | | ||`|`` | | * * | | |_||__ | | ||_|__ | | * * ,| |, jgs (____)) ,| |, ((;:;:) ,| |, * ** `---` `---` `---` ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * /:""| ,@@@@@@. * * |: oo|_ ,@@@@@`oo * * C _) @@@@C _) * * ) / "@@@@ '= * * /`\\ ```)/ * * || | | /`\\ * * || | | || | \ * * ||_| | || | / * * \( ) | ||_| | * * |~~~`-`~~~| |))) | * * (_) | | (_) |~~~/ (_) * * | |`""....__ __....""`| |`""...._|| / __....""`| | * * | |`""....__`````__....""`| |`""....__`````__....""`| | * * | | | ||``` | | ||`|`` | | * * | | |_||__ | | ||_|__ | | * * ,| |, jgs (____)) ,| |, ((;:;:) ,| |, * ** `---` `---` `---` ** \*** ===================================================================== ***/
キュー
次に、キューを作成します-スタックを補完する構造です。 違いは、キューの要素が最後からではなく、最初から削除されることです。 最初に古い要素、次に新しい要素。
すでに述べたように、機能は制限されているため、キューの実装はさまざまです。 良い方法は、リンクリストを使用することです。これについては後で説明します。
そして再び、私たちはJavaScript配列からの助けを求めています! キューの場合、再びメモリではなくリストと見なします。
class Queue { constructor() { this.list = []; this.length = 0; } // ... }
スタックと同様に、キューにアイテムを追加および削除するための2つの関数を定義します。
最初は「エンキュー」です-リストの最後にアイテムを追加します。
enqueue(value) { this.length++; this.list.push(value); }
さらに-「デキュー」。 アイテムはリストの最後からではなく、最初から削除されます。
dequeue() { // — . if (this.length === 0) return; // shift . this.length--; return this.list.shift(); }
スタックのように、「ピーク」関数を宣言します。これにより、キューの先頭で値を削除せずに取得できます。
peek() { return this.list[0]; }
リストはキューの実装に使用されているため、シフト方式の線形パフォーマンスを継承することに注意することが重要です(つまり、O(N)-“ NORMAS。”)。
後で説明するように、リンクリストを使用すると、より高速なキューを実装できます。
============================================================================ ,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-' ============================================================================
============================================================================ ,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-' ============================================================================
これからは、値が相互に参照するデータ構造を使用します。
+- -------------------------------------+ | +- A ------------+ +- B ------------+ | | | : 1 | | : 2 | | | | : ( B) | | : ( A) | | | +------------------------+ +------------------------+ | +--------------------------------------------------------+
データ構造の要素は、それ自体が意味と追加情報を含むミニ構造になります-親構造の他の要素へのリンク。
今、あなたは私が意味することを理解するでしょう。
/*** ===================================================================== ***\ * * * | RICK ASTLEY'S NEVER GONNA... * * | +-+ * * | +-+ |-| [^] - GIVE YOU UP * * | |^| |-| +-+ [-] - LET YOU DOWN * * | |^| |-| +-+ |*| [/] - RUN AROUND AND DESERT YOU * * | |^| |-| +-+ |\| |*| [\] - MAKE YOU CRY * * | |^| |-| |/| |\| +-+ |*| [.] - SAY GOODBYE * * | |^| |-| |/| |\| |.| |*| [*] - TELL A LIE AND HURT YOU * * | |^| |-| |/| |\| |.| |*| * * +-------------------------------- * ** ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * * * | RICK ASTLEY'S NEVER GONNA... * * | +-+ * * | +-+ |-| [^] - GIVE YOU UP * * | |^| |-| +-+ [-] - LET YOU DOWN * * | |^| |-| +-+ |*| [/] - RUN AROUND AND DESERT YOU * * | |^| |-| +-+ |\| |*| [\] - MAKE YOU CRY * * | |^| |-| |/| |\| +-+ |*| [.] - SAY GOODBYE * * | |^| |-| |/| |\| |.| |*| [*] - TELL A LIE AND HURT YOU * * | |^| |-| |/| |\| |.| |*| * * +-------------------------------- * ** ** \*** ===================================================================== ***/
カウント
実際、グラフはアスキーグラフを見たときに思っていたものとはまったく異なります。
グラフは次のような構造
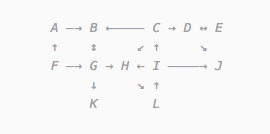
です。線で接続された多くの「頂点」(A、B、C、D、...)があります。
これらのピークは次のように表すことができます。
Node { value: ..., lines: [(Node), (Node), ...] }
そして、グラフ全体は次のようになります。
Graph { nodes: [ Node {...}, Node {...}, ... ] }
JavaScript配列を持つ頂点のリストを想像してください。配列は、意図的に頂点を順序付けるためではなく、頂点を格納する場所として使用されます。
class Graph { constructor() { this.nodes = []; } // ... }
グラフに値を追加して、線のない頂点を作成しましょう。
addNode(value) { this.nodes.push({ value: value, lines: [] }); }
次に、グラフ内の頂点を探す方法が必要です。通常、グラフの上部に別のデータ構造を作成して、検索を高速化します。
しかし、この場合、すべての頂点を調べて、対応する値を見つけます。この方法は遅いですが動作します。
find(value) { return this.nodes.find(function(node) { return node.value === value; }); }
これで、一方から他方に「線」を描くことで2つの頂点を接続できます(翻訳者のメモ:グラフアーク)。
addLine(startValue, endValue) { // . var startNode = this.find(startValue); var endNode = this.find(endValue); // , . if (!startNode || !endNode) { throw new Error(' '); } // startNode endNode. startNode.lines.push(endNode); }
結果のグラフは次のように使用できます。
var graph = new Graph(); graph.addNode(1); graph.addNode(2); graph.addLine(1, 2); var two = graph.find(1).lines[0];
このような小さなタスクにはあまりにも多くの作業が行われているようですが、これは強力なパターンです。
複雑なプログラムの透明性を維持するためによく使用されます。これは、データ自体に対する操作ではなく、データ間の関係を最適化することで実現されます。グラフ内の1つの頂点を選択すると、それに関連付けられている要素を非常に簡単に見つけることができます。
グラフは多くのことを表すことができます。ユーザーとその友人、node_modulesフォルダーの800個の依存関係、さらにはインターネット自体も、相互にリンクされたWebページリンクのグラフです。
/*** ===================================================================== ***\ * _______________________ * * ()=(_______________________)=() ,-----------------,_ * * | | ," ", * * | ~ ~~~~~~~~~~~~~ | ,' ,---------------, `, * * | ,----------------------------, ,----------- * * | ~ ~~~~~~~~ | | | * * | `----------------------------' `----------- * * | ~ ~~~~~~~~~~~~~ | `, `----------------' ,' * * | | `, ,' * * |_____________________| `------------------' * * ()=(_______________________)=() * ** ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * _______________________ * * ()=(_______________________)=() ,-----------------,_ * * | | ," ", * * | ~ ~~~~~~~~~~~~~ | ,' ,---------------, `, * * | ,----------------------------, ,----------- * * | ~ ~~~~~~~~ | | | * * | `----------------------------' `----------- * * | ~ ~~~~~~~~~~~~~ | `, `----------------' ,' * * | | `, ,' * * |_____________________| `------------------' * * ()=(_______________________)=() * ** ** \*** ===================================================================== ***/
リンクリスト
グラフのような構造がデータの順序付きリストを最適化する方法を見てみましょう。
リンクリストは、他の構造の実装によく使用される一般的なデータ構造です。リンクリストの利点は、アイテムを先頭、中間、末尾に追加する効率です。
リンクリストは基本的にグラフに似ています。他の頂点を指す頂点を操作します。これらは次のように配置されています。
1 -> 2 -> 3 -> 4 -> 5
1 -> 2 -> 3 -> 4 -> 5
この構造をJSONとして表すと、次のような結果が得られます。
{ value: 1, next: { value: 2, next: { value: 3, next: {...} } } }
グラフとは異なり、リンクリストには単一の頂点があり、そこから内部チェーンが始まります。これは、「ヘッド」、ヘッド要素、またはリンクリストの最初の要素と呼ばれます。
リストの長さも追跡します。
class LinkedList { constructor() { this.head = null; this.length = 0; } // ... }
まず、このポジションの値を取得する方法が必要です。
通常のリストとは異なり、目的の位置にジャンプすることはできません。代わりに、個々の頂点を通過する必要があります。
get(position) { // , . if (position >= this.length) { throw new Error(' '); } // . var current = this.head; // node.next, // . for (var index = 0; index < position; index++) { current = current.next; } // . return current; }
ここで、選択した位置に頂点を追加する方法が必要です。
値と位置を取得するaddメソッドを作成します。
add(value, position) { // , . var node = { value: value, next: null }; // , . // «next» // . if (position === 0) { node.next = this.head; this.head = node; // , // current previous. } else { // . var prev = this.get(position - 1); var current = prev.next; // , «next» // current, // «next» previous — . node.next = current; prev.next = node; } // . this.length++; }
最後に必要な方法はremoveです。位置によって頂点を見つけて、チェーンから外します。
remove(position) { // , head // . if (position === 0) { this.head = this.head.next; // // , . } else { var prev = this.get(position - 1); prev.next = prev.next.next; } // . this.length--; }
============================================================================ ,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-' ============================================================================
============================================================================ ,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-' ============================================================================
残りの2つのデータ構造は、「ツリー」ファミリーに属します。
人生のように、多くの異なるツリーのようなデータ構造があります。
ご注意翻訳者:まあ、いや、いや、...
バイナリツリー:
AAツリー、AVLツリー、バイナリ検索ツリー、バイナリツリー、デカルトツリー、左の子/右の兄弟ツリー、順序統計ツリー、パゴダ、...
Bツリー:
Bツリー、B +ツリー、B *ツリー、Bシャープツリー、ダンスツリー、2〜3ツリー、...
ヒープ:
ヒープ、バイナリヒープ、弱いヒープ、2項ヒープ、フィボナッチヒープ、レオナルドヒープ、2〜3ヒープ、ソフトヒープ、ペアリングヒープ、レフトヒープ、トレープ、...
ツリー:
トライ、基数ツリー、サフィックスツリー、サフィックスアレイ、FMインデックス、Bトライ、...
マルチウェイツリー:
三元ツリー、K-aryツリー、およびORツリーa、b)-tree、Link / Cut Tree、...
スペース分割ツリー:
セグメントツリー、インターバルツリー、レンジツリー、ビン、Kdツリー、クアッドツリー、オクトリー、Zオーダー、UBツリー、Rツリー、Xツリー、メトリックツリー、カバーツリー、...
アプリケーション固有のツリー:
抽象構文ツリー、解析ツリー、デシジョンツリー、ミニマックスツリー、...
あなたが期待していなかったのは、今日樹木学を勉強するということです...そしてこれはすべての木ではありません。彼らに迷惑をかけないようにしましょう。それらのほとんどはまったく意味がありません。人々が何らかの形で候補者の学位を擁護し、このために何かを証明することが必要でした。
ツリーはグラフまたはリンクリストに似ていますが、「単方向」であるという違いがあります。これは、循環リンクがそれらの中に存在できないことを意味します。

木のてっぺんを一周できたら...おめでとうございます、しかしこれは木ではありません。
ツリーは多くのタスクで使用されます。これらは、検索またはソートを最適化するために使用されます。彼らはプログラムをより良く組織することができます。作業しやすいプレゼンテーションを作成できます。
/*** ===================================================================== ***\ * ccee88oo \ | / * * C8O8O8Q8PoOb o8oo '-.;;;.-, ooooO8O8QOb o8bDbo * * dOB69QO8PdUOpugoO9bD -==;;;;;==-aadOB69QO8PdUOpugoO9bD * * CgggbU8OU qOp qOdoUOdcb .-';;;'-. CgggOU ddqOp qOdoUOdcb * * 6OuU /pu gcoUodpP / | \ jgs ooSec cdac pdadfoof * * \\\// /douUP ' \\\d\\\dp/pddoo * * \\\//// \\ \\//// * * |||/\ \\/// * * |||\/ |||| * * ||||| /||| * ** .............//||||\.......................//|||\\..................... ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * ccee88oo \ | / * * C8O8O8Q8PoOb o8oo '-.;;;.-, ooooO8O8QOb o8bDbo * * dOB69QO8PdUOpugoO9bD -==;;;;;==-aadOB69QO8PdUOpugoO9bD * * CgggbU8OU qOp qOdoUOdcb .-';;;'-. CgggOU ddqOp qOdoUOdcb * * 6OuU /pu gcoUodpP / | \ jgs ooSec cdac pdadfoof * * \\\// /douUP ' \\\d\\\dp/pddoo * * \\\//// \\ \\//// * * |||/\ \\/// * * |||\/ |||| * * ||||| /||| * ** .............//||||\.......................//|||\\..................... ** \*** ===================================================================== ***/
木々
簡単なツリー構造から始めましょう。特別なルールはありません。次のようになります。
Tree { root: { value: 1, children: [{ value: 2, children: [...] }, { value: 3, children: [...] }] } }
ツリーは、ツリーの「ルート」という単一の親で始まる必要があります。
class Tree { constructor() { this.root = null; } // ... }
ツリーをトラバースし、各頂点で特定の関数を呼び出す方法が必要です。
traverse(callback) { // walk, // . function walk(node) { // callback . callback(node); // walk . node.children.forEach(walk); } // . walk(this.root); }
次に、ツリーに頂点を追加する方法が必要です。
add(value, parentValue) { var newNode = { value: value, children: [] }; // , . if (this.root === null) { this.root = newNode; return; } // , // parentValue // . this.traverse(function(node) { if (node.value === parentValue) { node.children.push(newNode); } }); }
この単純なツリーは、表示されたデータがそれに類似している場合にのみ役立つ可能性があります。
ただし、追加のルールがある場合、ツリーはさまざまなタスクを実行できます。
/*** ===================================================================== ***\ * 0 0 1 0 1 0 0 1 0 1 1 1 0 1 ,@@@@@@@@@@@@@@, 0 0 1 0 1 0 0 1 0 1 1 1 0 * * 0 1 0 1 0 1 0 1 1 0 1 1 0 @@` '@@ 0 1 0 1 0 1 1 0 1 0 1 0 * * 1 1 0 0 0 1 0 0 1 1 1 0 @@` 8O8PoOb o8o '@@ 0 0 1 0 0 1 0 0 1 1 1 * * 0 0 1 1 0 1 0 1 0 0 0 @@ dOB69QO8PdUgoO9bD @@ 1 0 1 1 0 1 0 1 0 0 * * ===================== @@ CgbU8OU qOp qOdOdcb @@ 0 1 1 0 1 0 1 0 1 0 * * @@ 6OU /pu gcoUpP @@ 1 0 1 1 0 1 0 0 1 1 * * ===================== @@ \\// /doP @@ 0 1 1 0 0 1 0 0 1 0 * * 1 1 0 0 1 1 0 1 1 0 0 @@ \\// @@ 1 0 1 0 0 1 1 0 1 1 * * 0 1 1 0 1 0 1 1 0 1 1 0 @@, ||| ,@@ 0 1 1 0 1 1 0 0 1 0 1 * * 1 0 1 0 1 1 0 0 1 0 0 1 0 @@, //|\ ,@@ 0 1 0 1 0 1 1 0 0 1 1 0 * ** 1 0 1 0 0 1 1 0 1 0 1 0 1 `@@@@@@@@@@@@@@' 0 1 1 1 0 0 1 0 1 0 1 1 ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * 0 0 1 0 1 0 0 1 0 1 1 1 0 1 ,@@@@@@@@@@@@@@, 0 0 1 0 1 0 0 1 0 1 1 1 0 * * 0 1 0 1 0 1 0 1 1 0 1 1 0 @@` '@@ 0 1 0 1 0 1 1 0 1 0 1 0 * * 1 1 0 0 0 1 0 0 1 1 1 0 @@` 8O8PoOb o8o '@@ 0 0 1 0 0 1 0 0 1 1 1 * * 0 0 1 1 0 1 0 1 0 0 0 @@ dOB69QO8PdUgoO9bD @@ 1 0 1 1 0 1 0 1 0 0 * * ===================== @@ CgbU8OU qOp qOdOdcb @@ 0 1 1 0 1 0 1 0 1 0 * * @@ 6OU /pu gcoUpP @@ 1 0 1 1 0 1 0 0 1 1 * * ===================== @@ \\// /doP @@ 0 1 1 0 0 1 0 0 1 0 * * 1 1 0 0 1 1 0 1 1 0 0 @@ \\// @@ 1 0 1 0 0 1 1 0 1 1 * * 0 1 1 0 1 0 1 1 0 1 1 0 @@, ||| ,@@ 0 1 1 0 1 1 0 0 1 0 1 * * 1 0 1 0 1 1 0 0 1 0 0 1 0 @@, //|\ ,@@ 0 1 0 1 0 1 1 0 0 1 1 0 * ** 1 0 1 0 0 1 1 0 1 0 1 0 1 `@@@@@@@@@@@@@@' 0 1 1 1 0 0 1 0 1 0 1 1 ** \*** ===================================================================== ***/
バイナリ検索ツリー
バイナリ検索ツリーは、ツリーの一般的な形式です。ソートされた順序を維持しながら、値を効率的に読み取り、検索、挿入、削除できます。
一連の数字があると想像してください。
1 2 3 4 5 6 7
1 2 3 4 5 6 7
中心からツリーに展開します。
4 / \ 2 6 / \ / \ 1 3 5 7 -^--^--^--^--^--^--^- 1 2 3 4 5 6 7
4 / \ 2 6 / \ / \ 1 3 5 7 -^--^--^--^--^--^--^- 1 2 3 4 5 6 7
次に、バイナリツリーの仕組みの例を示します。各頂点には2つの子孫があります。
- 左側のものは親頂点の値よりも小さいです。
- 右側の値は、親の頂点の値よりも大きくなっています。
注:これが機能するには、ツリー内のすべての値が一意である必要があります。
これにより、値を検索するときにツリートラバーサルが非常に効果的になります。たとえば、ツリーで5番を見つけようとします。
(4) <--- 5 > 4, . / \ 2 (6) <--- 5 < 6, . / \ / \ 1 3 (5) 7 <--- 5!
(4) <--- 5 > 4, . / \ 2 (6) <--- 5 < 6, . / \ / \ 1 3 (5) 7 <--- 5!
5に到達するために必要なチェックは3回だけでした。ツリーが1000個の要素で構成されている場合、パスは次のようになります。
500 -> 250 -> 125 -> 62 -> 31 -> 15 -> 7 -> 3 -> 4 -> 5
500 -> 250 -> 125 -> 62 -> 31 -> 15 -> 7 -> 3 -> 4 -> 5
1000個のアイテムにつき10個のチェックのみ!
バイナリ検索ツリーのもう1つの重要な機能は、リンクリストとの類似性です。値を追加または削除するときに、すぐ周囲の要素を更新するだけで済みます。
前のセクションと同様に、まずバイナリ検索ツリーの「ルート」を設定する必要があります。
class BinarySearchTree { constructor() { this.root = null; } // ... }
値がツリーにあるかどうかを確認するには、ツリーを検索する必要があります。
contains(value) { // . var current = this.root; // , , . // , null, . while (current) { // value current.value, . if (value > current.value) { current = current.right; // value current.value, . } else if (value < current.value) { current = current.left; // true. } else { return true; } } // , false. return false; }
ツリーに要素を追加するには、追加された値よりも大きいか小さいかに応じて、左右の頂点を飛び越えて、以前と同じトラバーサルを行う必要があります。
ただし、nullに等しい左または右の頂点に到達したので、
この位置に頂点を追加します。
add(value) { // . var node = { value: value, left: null, right: null }; // , — . if (this.root === null) { this.root = node; return; } // . var current = this.root; // , // , . while (true) { // value current.value, . if (value > current.value) { // , . if (!current.right) { current.right = node; break; } // . current = current.right; // value current.value, . } else if (value < current.value) { // , . if (!current.left) { current.left = node; break; } // . current = current.left; // , // , . } else { break; } } }
/*** ===================================================================== ***\ * .''. * * .''. *''* :_\/_: . * * :_\/_: . .:.*_\/_* : /\ : .'.:.'. * * .''.: /\ : _\(/_ ':'* /\ * : '..'. -=:o:=- * * :_\/_:'.:::. /)\*''* .|.* '.\'/.'_\(/_'.':'.' * * : /\ : ::::: '*_\/_* | | -= o =- /)\ ' * * * '..' ':::' * /\ * |'| .'/.\'. '._____ * * * __*..* | | : |. |' .---"| * * _* .-' '-. | | .--'| || | _| | * * .-'| _.| | || '-__ | | | || | * * |' | |. | || | | | | || | * * _____________| '-' ' "" '-' '-.' '` |____________ * ** jgs~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ** \*** ===================================================================== ***/
/*** ===================================================================== ***\ * .''. * * .''. *''* :_\/_: . * * :_\/_: . .:.*_\/_* : /\ : .'.:.'. * * .''.: /\ : _\(/_ ':'* /\ * : '..'. -=:o:=- * * :_\/_:'.:::. /)\*''* .|.* '.\'/.'_\(/_'.':'.' * * : /\ : ::::: '*_\/_* | | -= o =- /)\ ' * * * '..' ':::' * /\ * |'| .'/.\'. '._____ * * * __*..* | | : |. |' .---"| * * _* .-' '-. | | .--'| || | _| | * * .-'| _.| | || '-__ | | | || | * * |' | |. | || | | | | || | * * _____________| '-' ' "" '-' '-.' '` |____________ * ** jgs~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ** \*** ===================================================================== ***/
終わり
十分な知識が得られれば幸いです。気に入った場合
は、リポジトリに星を付けてTwitterでフォローしてください。
また、他の記事「The Super Tiny Compiler」を読むこともできますgithub.com/thejameskyle/the-super-tiny-compiler
// ... module.exports = { List: List, HashTable: HashTable, Stack: Stack, Queue: Queue, Graph: Graph, LinkedList: LinkedList, Tree: Tree, BinarySearchTree: BinarySearchTree };
また、この記事はgithubで読むことができます。
翻訳:aalexeev、リビジョン:iamo0、Chursina Chaika。