この記事では、優れたコードの作成と発生する問題について説明します。 明確、宣言的、構成可能、およびテスト可能-これらの用語は、適切なコードを記述する際に使用されます。 問題解決は、しばしば純粋関数と呼ばれます。 しかし、Webアプリケーションを作成する主な理由は、副作用と複雑な非同期ワークフローであり、本質的にはクリーンではありません。 以下では、純粋な機能の利点を維持しながら、副作用や複雑な非同期スレッドの処理をカバーできるアプローチについて説明します。
良いコードを書く
純粋な機能は、優れたコードを書くことの聖杯です。 純粋な関数とは、同じ引数で常に同じ値を返し、目に見える副作用がない関数です。
function add(numA, numB) { return numA + numB }
純粋な関数の便利な機能は、テストしやすいことです。
test.equals(add(2, 2), 4)
構成可能性もその強みです。
test.equals(multiply(add(4, 4), 2), 16)
さらに、宣言的に非常に簡単に使用できます。
const totalPoints = users .map(takePoints) .reduce(sum, 0)
しかし、アプリケーションを見てみましょう。 純粋な関数で実際に表現できるのはどの部分ですか? 伝統的に純粋な機能を実行する値を変換する頻度はどれくらいですか? 私はあなたのコードのほとんどが副作用で動作すると仮定することができます。 ネットワーク要求、DOM操作、Webソケットの使用、ローカルストレージの実行、アプリケーションの状態の変更などを行います。 これはすべて、少なくともインターネット上でのアプリケーション開発について説明しています。
副作用
原則として、同様の場合の副作用について話します:
function getUsers() { return axios.get('/users') .then(response => ({users: response.data})) }
getUsers
関数は、「それ自体の外側」の何かgetUsers
指します。 これはサーバーの応答であるため、戻り値は常に一致するとは限りません。 ただし、この関数を宣言的に使用して、さまざまなチェーンで構成することができます。
doSomething() .then(getUsers) .then(doSomethingElse)
ただし、 axiosは制御できないため、テストは困難です。 axios
を引数として取るように関数を書き直します。
function getUsers(axios) { return axios.get('/users') .then(response => ({users: response.data})) }
テストが簡単になりました:
const users = ['userA', 'userB'] const axiosMock = Promise.resolve({data: users}) getUsers(axiosMock).then(result => { assert.deepEqual(result, {users: users}) })
ただし、 axiosを入力に明示的に渡す必要があるため、関数を異なるチェーンにリンクする際に問題が発生します。
doSomething() // axios .then(getUsers) // .then(doSomethingElse)
副作用で機能する機能には実際に問題があります。
Elm 、 Cycle 、 redux-redux実装などのプロジェクトで人気のあるアドバイス:「アプリケーションの端に副作用をプッシュします。」 これは基本的に、アプリケーションのビジネスロジックがクリーンに保たれることを意味します。 副作用を引き起こす必要があるときはいつでも、それを分けるべきです。 このアプローチの問題は、おそらく読みやすさの改善に役立たないことです。 全体的に複雑なワークフローを表現することはできません。 アプリケーションには、別の副作用などを引き起こす可能性のある、ある副作用の関係を隠す複数の無関係なループがあります。 これは単純なアプリケーションでは問題になりません。複数の追加ループを扱うことはめったにないからです。 しかし、大規模なアプリケーションでは、最終的に多数のサイクルが発生し、それらが相互にどのように関係しているかを理解することは困難です。
これについて、例を挙げて詳しく説明します。
典型的なアプリケーションストリーム
アプリケーションがあるとしましょう。 開始時に、ユーザー情報を取得して、ユーザーがログインしているかどうかを確認します。 次に、タスクのリストを取得します。 それらは他のユーザーに関連付けられています。 したがって、受信したタスクのリストに基づいて、これらのユーザーに関する情報も動的に取得する必要があります。 このワークフローをわかりやすく、宣言的で、構成可能で、テスト可能な方法で記述するために何をしますか?
function loadData() { return (dispatch, getState) => { dispatch({ type: AUTHENTICATING }) axios.get('/user') .then((response) => { if (response.data) { dispatch({ type: AUTHENTICATION_SUCCESS, user: response.data }) dispatch({ type: ASSIGNMENTS_LOADING }) return axios.get('/assignments') .then((response) => { dispatch({ type: ASSIGNMENTS_LOADED_SUCCESS, assignments: response.data }) const missingUsers = response.data.reduce((currentMissingUsers, assignment) => { if (!getState().users[assigment.userId]) { return currentMissingUsers.concat(assignment.userId) } return currentMissingUsers }, []) dispatch({ type: USERS_LOADING, users: users }) return Promise.all( missingUsers.map((userId) => { return axios.get('/users/' + userId) }) ) .then((responses) => { const users = responses.map(response => response.data) dispatch({ type: USERS_LOADED, users: users }) }) }) .catch((error) => { dispatch({ type: ASSIGNMENTS_LOADED_ERROR, error: error.response.data }) }) } else { dispatch({ type: AUTHENTICATION_ERROR }) } }) .catch(() => { dispatch({ type: LOAD_DATA_ERROR }) }) } }
ここではすべてが間違っています。 このコードは、理解できず、宣言的でなく、理解できず、テストできません。 ただし、1つの利点があります。 loadData関数が呼び出されたときに発生するすべてのことは、実行時に、規則正しい方法で1つのファイルで定義されます。
「アプリケーションの端で」副作用を分離すると、ストリームの一部のデモのように見えます。
function loadData() { return (dispatch, getState) => { dispatch({ type: AUTHENTICATING_LOAD_DATA }) } } function loadDataAuthenticated() { return (dispatch, getState) { axios.get('/user') .then((response) => { if (response.data) { dispatch({ type: AUTHENTICATION_SUCCESS, user: response.data }) } else { dispatch({ type: AUTHENTICATION_ERROR }) } }) } } function getAssignments() { return (dispatch, getState) { dispatch({ type: ASSIGNMENTS_LOADING }) axios.get('/assignments') .then((response) => { dispatch({ type: ASSIGNMENTS_LOADED_SUCCESS, assignments: response.data }) }) .catch((error) => { dispatch({ type: ASSIGNMENTS_LOADED_ERROR, error: error.response.data }) }) } }
各部分は、前の例よりも読みやすくなっています。 そして、それらは他のチェーンに入れるのが簡単です。 ただし、断片化が問題になります。 これらの部分が互いにどのように関連しているかを理解することは困難です。なぜなら、どの関数が別の関数の呼び出しにつながるかを見ることができないからです。 ファイル間を移動して、あるアクションをディスパッチすると副作用が発生し、別の副作用を生成する新しいアクションを送信する方法を頭に再作成することを余儀なくされます。
アプリケーションの端に副作用をもたらすことにより、あなたは本当に利点を得ることができます。 ただし、マイナスの効果もあります。フローについて話すのが難しくなります。 もちろん、これについて議論することはできますし、すべきです。 上記の例と推論を通して、私の見解を伝えることができたと思います。
宣言への道
このストリームを次のように記述できると想像してください。
[ dispatch(AUTHENTICATING), authenticateUser, { error: [ dispatch(AUTHENTICATED_ERROR) ], success: [ dispatch(AUTHENTICATED_SUCCESS), dispatch(ASSIGNMENTS_LOADING), getAssignments, { error: [ dispatch(ASSIGNMENTS_LOADED_ERROR) ], success: [ dispatch(ASSIGNMENTS_LOADED_SUCCESS), dispatch(MISSING_USERS_LOADING), getMissingUsers, { error: [ dispatch(MISSING_USERS_LOADED_ERROR) ], success: [ dispatch(MISSING_USERS_LOADED_SUCCESS) ] } ] } ] } ]
これは有効なコードであることに注意してください。これについては、詳細に分析します。 また、ここでは魔法のAPIを使用していません。これらは単なる配列、オブジェクト、関数です。 しかし最も重要なのは、宣言形式のコードを最大限に活用して、複雑なアプリケーションストリームの一貫した読みやすい記述を作成することです。
機能ツリー
関数ツリーを定義(宣言)しました。 前述したように、特別なAPIを使用して定義しませんでした。 これらは、関数ツリー内のツリー...で定義された関数です。 ここで使用される関数はすべて、関数ファクトリー(ディスパッチ)と同様に、他のツリー定義で再利用できます。 これは構成の単純さを示しています。 各関数が他のツリーで構成されるだけではありません。 他のツリーにツリー全体を含めることができます。これにより、構成の面で特に興味深いものになります。
[ dispatch(AUTHENTICATING), authenticateUser, { error: [ dispatch(AUTHENTICATED_ERROR) ], success: [ dispatch(AUTHENTICATED_SUCCESS), ...getAssignments ] } ]
この例では、配列でもある新しいgetAssignmentsツリーを作成しました。 spread演算子を使用して、1つのツリーを別のツリーに構成できます。
testabilityに進む前に、関数ツリーがどのように機能するかを見てみましょう。 実行しましょう!
関数ツリーの実行
ツリー関数の実行方法の圧縮例は次のとおりです。
import FunctionTree from 'function-tree' const execute = new FunctionTree() function foo() {} execute([ foo ])
作成されたFunctionTreeインスタンスは、ツリーを実行できる関数です。 上記の例では、 foo関数が実行されます。 さらに関数を追加すると、それらは順番に実行されます。
function foo() { // } function bar() { // } execute([ foo, bar ])
非同期性
function-tree
はpromiseでfunction-tree
。 関数がpromiseを返す場合、またはasync
を使用して関数を非同期として定義すると、execute関数はpromiseが満たされる(解決する)または拒否されるまで(先に進む前に)待機します。
function foo() { return new Promise(resolve => { setTimeout(resolve, 1000) }) } function bar() { // 1 } execute([ foo, bar ])
多くの場合、非同期コードはより多様な結果をもたらします。 これらの結果を宣言的に定義する方法を理解するために、関数ツリーのコンテキストを調べます 。
コンテキスト
関数function-tree
を使用して実行されるすべての関数は、1つの引数を取ります。 コンテキストは、ツリーで定義された関数が機能する唯一の引数です。 デフォルトでは、コンテキストにはinputとpathの 2つのプロパティがあります 。
入力プロパティには、ツリーの開始時に渡されたペイロードが含まれます。
// function foo({input}) { input.foo // "bar" } execute([ foo ], { foo: 'bar' })
関数が新しいペイロードをツリーの下に転送する場合、現在のペイロードとマージされるオブジェクトを返す必要があります。
function foo({input}) { input.foo // "bar" return { foo2: 'bar2' } } function bar({input}) { input.foo // "bar" input.foo2 // "bar2" } execute([ foo, bar ], { foo: 'bar' })
同期関数か非同期かは問題ではなく、オブジェクトまたはオブジェクトで作成されたプロミスを返すだけです。
// function foo() { return { foo: 'bar' } } // function foo() { return new Promise(resolve => { resolve({ foo: 'bar' }) }) }
実行用のパスを選択するメカニズムの研究に移りましょう。
方法
関数から返された結果により、ツリー内のさらなる実行パスを決定できます。 静的分析のおかげで、コンテキストパスプロパティは、どのパスが実行を継続できるかをすでに知っています。 これは、ツリーで定義されている実行パスのみが使用可能であることを意味します。
function foo({path}) { return path.pathA() } function bar() { // } execute([ foo, { pathA: [ bar ], pathB: [] } ])
オブジェクトをpathメソッドに渡すことにより、ペイロードを渡すことができます。
function foo({path}) { return path.pathA({foo: 'foo'}) } function bar({input}) { console.log(input.foo) // 'foo' } execute([ foo, { pathA: [ bar ], pathB: [] } ])
パスのメカニズムは何に適していますか? まず第一に、それは本質的に宣言的です。 ifまたはswitchステートメントはありません。 これにより、読みやすさが向上します。
さらに重要なのは、パスがスローエラーを処理しないことです。 多くの場合、ストリームは「エラーが発生した場合、それを実行するかすべてをスローする」と考えられます。 しかし、Webアプリケーションの場合はそうではありません。 さまざまな経路をたどる理由はたくさんあります。 ソリューションは、ユーザーの役割、サーバーから返された応答、アプリケーションの状態、渡された値などに基づいている場合があります。 実際、 function-tree
はエラーをキャッチせず、エラーを起こさず、同様の手法が登場します。 関数を実行するだけで、実行が分岐するパスを返すことができます。
いくつかの小さな隠された機能があります。 たとえば、何も実装せずに関数ツリーを定義できます。 これは、可能なすべての実行パスが事前定義されていることを意味します。 どのケースを処理する必要があるかを考えさせます。 また、発生する可能性のあるシナリオを無視したり忘れたりする可能性を大幅に減らします。
プロバイダー
入力とパスのみでは、複雑なアプリケーションを構築できません。 したがって、 function-tree
プロバイダーの概念に基づいて構築されます 。 実際、 input
とpath
もプロバイダーです。 function-tree
は、いくつかの既製のものが含まれています。 そしてもちろん、自分で作成することもできます。 Reduxを使用するとします。
import FunctionTree from 'function-tree' import ReduxProvider from 'function-tree/providers/Redux' import store from './store' const execute = new FunctionTree([ ReduxProvider(store) ]) export default execute
これで、関数のdispatchおよびgetStateメソッドにアクセスできます。
function doSomething({dispatch, getState}) { dispatch({ type: SOME_CONSTANT }) getState() // {} }
ContextProviderを使用して他のツールを追加できます。
import FunctionTree from 'function-tree' import ReduxProvider from 'function-tree/providers/Redux' import ContextProvider from 'function-tree/providers/Context' import axios from 'axios' import store from './store' const execute = new FunctionTree([ ReduxProvider(store), ContextProvider({ axios }) ]) export default execute
ほとんどの場合、 DebuggerProviderを使用します。 Google Chromeの拡張機能と組み合わせて、現在の作業をデバッグできます。 上記の例にデバッガープロバイダーを追加します。
import FunctionTree from 'function-tree' import DebuggerProvider from 'function-tree/providers/Debugger' import ReduxProvider from 'function-tree/providers/Redux' import ContextProvider from 'function-tree/providers/Context' import axios from 'axios' import store from './store' const execute = new FunctionTree([ DebuggerProvider(), ReduxProvider(store), ContextProvider({ axios }) ]) export default execute
これにより、これらのツリーがアプリケーションで実行されるときに発生するすべてを確認できます。 デバッガープロバイダーは、コンテキストに配置するすべてを自動的にラップして追跡します。
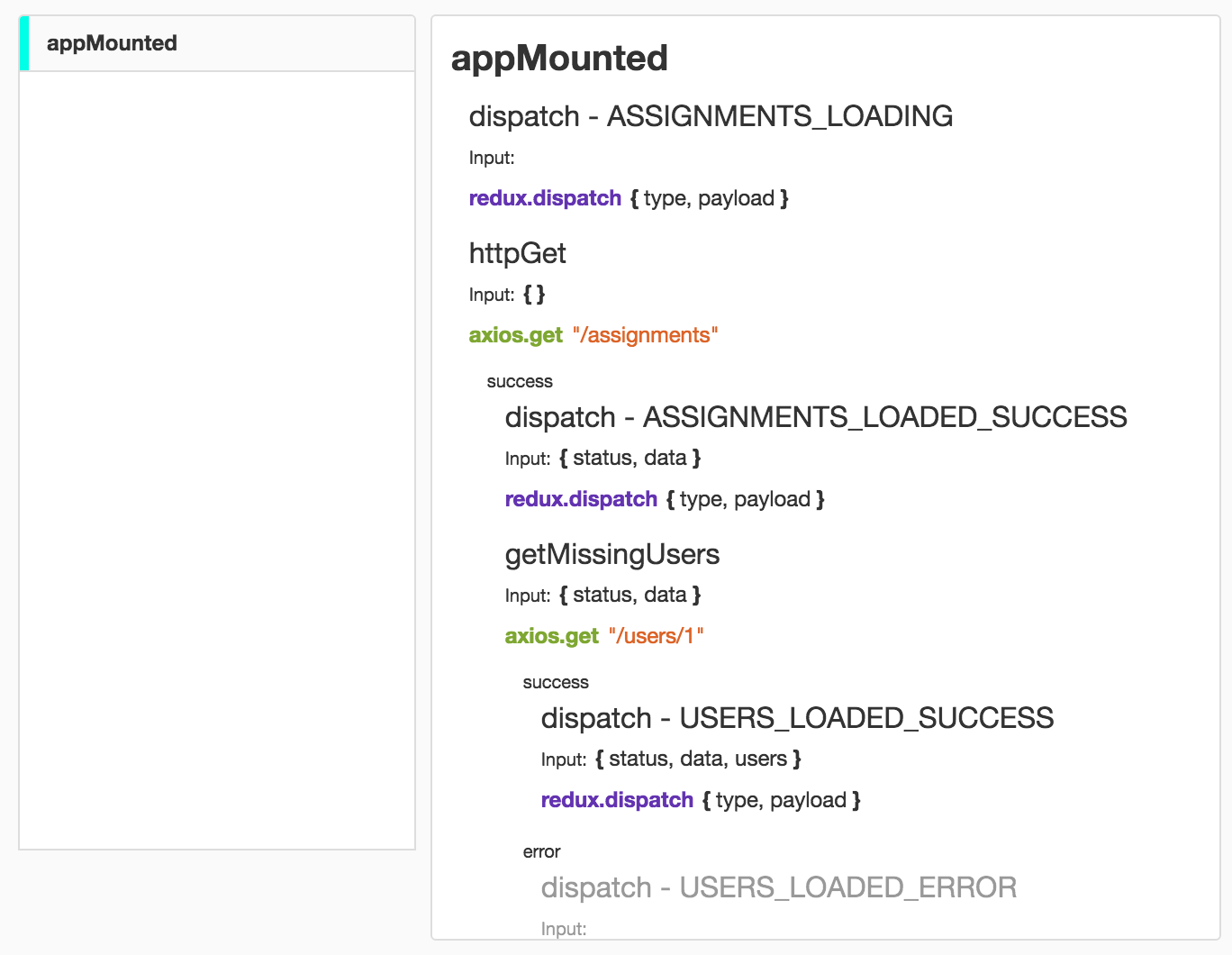
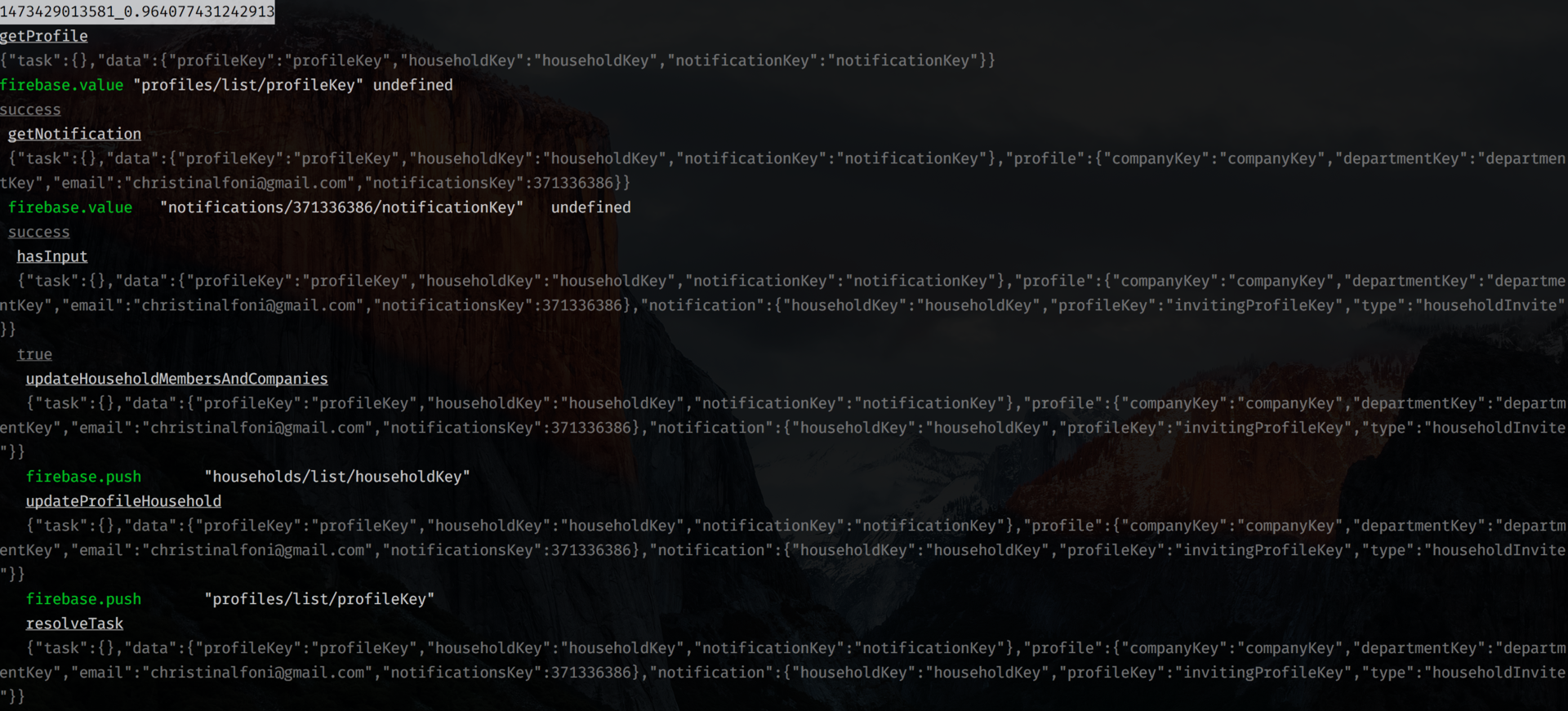
サーバー側でfunction-tree
を使用することにした場合、 NodeDebuggerProviderを接続できます。
テスタビリティ
しかし、最も可能性が高いのは、機能ツリーをチェックする機能です。 結局のところ、これは非常に簡単です。 ツリー内の個々の関数をテストするには、特別に準備されたコンテキストでそれらを呼び出すだけです。 副作用機能のテストを検討してください。
function setData({window, input}) { window.app.data = input.result }
const context = { input: {result: 'foo'}, window: { app: {}} } setData(context) test.deepEqual(context.window, {app: {data: 'foo'}})
非同期関数のテスト
多くのテストライブラリでは、グローバルな依存関係のスタブを作成できます。 ただし、 function-tree
はコンテキスト引数で使用可能なもののみを使用するため、 function-tree
でこれを行う理由はありません。 たとえば、 axiosを使用してデータを取得する次の関数は、次のようにテストできます。
function getData({axios, path}) { return axios.get('/data') .then(response => path.success({data: response.data})) .catch(error => path.error({error: error.response.data})) }
const context = { axios: { get: Promise.resolve({ data: {foo: 'bar'} }) } } getData(context) .then((result) => { test.equal(result.path, 'success') test.deepEqual(result.payload, {data: {foo: 'bar'}}) })
ツリー全体のテスト
ここではさらに興味深いものになります。 関数を個別にテストしたのと同じ方法で、ツリー全体をテストできます。
単純なツリーを想像してみましょう。
[ getData, { success: [ setData ], error: [ setError ] } ]
これらの関数は、 axios
を使用してデータを取得し、 window
オブジェクトのプロパティに保存します。 コンテキストに渡すスタブを持つ新しいランタイム関数を作成して、ツリーをテストします。 次に、ツリーを開始し、完了後に変更を確認します。
const FunctionTree = require('function-tree') const ContextProvider = require('function-tree/providers/Context') const loadData = require('../src/trees/loadData') const context = { window: {app: {}}, axios: { get: Promise.resolve({data: {foo: 'bar'}}) } } const execute = new FunctionTree([ ContextProvider(context) ]) execute(loadData, () => { test.deepEquals(context.window, {app: {data: 'foo'}}) })
どのライブラリを使用してもかまいません。 ライブラリをツリーコンテキストに配置しながら、関数ツリーを簡単にテストできます。
工場
ツリーは機能しているため、開発を高速化するファクトリを作成できます。 Reduxの例で、 ディスパッチファクトリの使用を見てきました。 次のように宣言されました。
function dispatchFactory(type) { function dispatchFunction({input, dispatch}) { dispatch({ type, payload: input }) } // `displayName` , // . dispatchFunction.displayName = `dispatch - ${type}` return dispatchFunction } export default dispatchFactory
アプリケーションのファクトリを作成して、すべての特定の関数を作成しないようにします。 単一の状態ツリーであるbaobabを使用して、アプリケーションの状態を保存するとします。
function setFactory(path, value) { function set({baobab}) { baobab.set(path.split('.'), value) } return set } export default set
このファクトリを使用すると、ツリーで状態の変更を直接表現できます。
[ set('foo', 'bar'), set('admin.isLoading', true) ]
ファクトリを使用して 、アプリケーション用に独自のDSLを構築できます。 一部の工場は非常に一般化されているため、それらをfunction-tree
一部にすることにしました。
debounce
debounce
ファクトリを使用すると、指定した時間実行を継続できます。 同じツリーの新しい実行が機能する場合、既存の実行は破棄されたパスに沿って進みます。 指定された時間内に新しい操作がない場合、後者は受け入れられたパスに沿って進みます。 通常、このアプローチは、入力時に検索するときに使用されます。
import debounce from 'function-tree/factories/debounce' export default [ updateSearchQuery, debounce(500), { accepted: [ getData, { success: [ setData, ], error: [ setError ] } ], discarded: [] } ]
RxjsとPromiseチェーンとの違いは何ですか?
RxjsとPromisesの両方が実行制御を制御します。 しかし、それらのどれも実行の方法の宣言的な条件付き定義を持っていません。 スレッドをスパンするか 、 ifを記述して式を切り替える か 、エラーをスローする必要があります。 上記の例では、 success
とerror
実行パスを関数と同様に宣言success
に分離できました。 これにより、読みやすさが向上します。 しかし、これらのパスは絶対に任意です。 例:
[ withUserRole, { admin: [], superuser: [], user: [] } ]
パスはエラー処理とは関係ありません。 function-tree
使用すると、現在のパスの実行を停止する唯一の方法であるエラーをスローするpromiseやRxjsとは異なり、実行の任意のステップでパスを選択できます。
Rxjsとpromiseは、値の変換に基づいています。 これは、前の値の結果として渡された値のみが次の関数で使用できることを意味します。 これは、本当に値を変換する必要がある場合に効果的です。 しかし、アプリケーションのイベントはそうではありません。 それらは副作用を処理し、1つ以上の実行パスに沿って進みます。 これがfunction-tree
主な違いfunction-tree
。
どこで申請できますか?
関数ツリーは、複雑な非同期チェーンの副作用を処理するアプリケーションを作成する場合に役立ちます。 アプリケーションロジックを「レゴ」ブロックに「強制」することの利点とそのテスト容易性は、非常に重要な議論になり得ます。 これにより基本的に、より読みやすくサポートされたコードを書くことができます。
このプロジェクトはGithubのリポジトリにあり、Google Chromeのデバッガー拡張機能はChrome Web Storeにあります。 リポジトリ内のサンプルアプリケーションを必ずチェックアウトしてください。
function-tree
プロジェクトのソースはcerebralです。 Cerebralでのシグナルの実装は、 function-tree
上の独自の表現による抽象化と考えることができfunction-tree
。 現在、Cerebralは独自の実装を使用していますが、Cerebral 2.0では、 function-tree
がシグナルファクトリの基盤として使用されます。 アレクセイ・グリアに、大脳信号のアイデアを処理し、磨き上げてくれたことに感謝し、それが独立した一般的なアプローチの創造につながりました。
以下のコメントで、このアプローチについてどう思うか教えてください。 この記事で説明した問題を解決するための他のパターンや方法へのリンクがある場合は、共有してください。 読んでくれてありがとう!