Rの選択は決してランダムではなく、バランスの取れた分析の結果です。 さまざまな産業や人間活動の分野でプロジェクトを実施した以前の経験は、原則として学際的なジョイントであったため、特別に作成されたツールがないという状況はよく知られており、運用上の決定が必要でした。
選択した機器を評価するための重要なポイントは次のとおりです。
- タスクの主な内容は標準サイクルに短縮されました。データ収集-クリーニングと前処理-さまざまな複雑さの数学的処理-視覚化-外部システムへの制御コマンドの発行。
- 外部とのすべての情報交換は、標準化されたプロトコル(ODBC、REST)およびさまざまな形式のファイルに従って実行されました。 多くの情報はありません(最大、1日あたり数十ギガバイト)、〜70%は構造化された形式で提示され、リアルタイムストリーミング処理は絶対に必要ありません。
- 処理されたデータの高速分析ツールを備えたインタラクティブなWebユーザーインターフェイスが必要です。
- 何かを獲得するための予算=0。実装時間=昨日。 ユーザーの要件は、プロトタイプの最初のデモ後に表示されます。
- 購入したシステムでもオープンソースでも、学習に時間がかかるシステムです。 「直感的な」ユーザーインターフェースを使用する場合でも、左右のステップでは、選択したシステムのアーキテクチャのイデオロギーに深く没頭し、アタッチする必要があります。 そして、残念ながら、しばらくするとこのシステムの制限がブレーキにならないという保証はありません。
システムの研究にすでに時間を費やす必要がある場合は、可能な限り効率的で、可能なアプリケーションの柔軟性と幅を備えたシステムを選択する必要があります。 今後、このようなクラスのタスクについては、これは決勝戦でのRの勝利を支持する決定的な議論でした。 Pythonは2位になりましたが、アクティブなユニバーサルツールであり、今後もそうです。
問題を解決するためのアプローチの評価と比較は、ビジネスの観点から行われました。そのための最重要指標は、最小限のコストで一定期間内に結果を達成することです。 最終的には技術的に劣ったソリューションが排除されたため、最終的なソリューションはビジネス顧客と技術者の両方のニーズを満たすと考えます。
Rフレームワーク
私たちに完全に合った最小セットはR言語、IDEはRStudio 、統合ゲートウェイはDeployR 、クライアントWebアプリケーションサーバーはShinyです。
当然、プログラミング言語であるRは、論理的および数学的に複雑なコンポーネントを作成する能力において、事実上無制限です。 それはすべて、知識の深さ、仕事のスキル、使用するパッケージに依存します。
タスク#1。 材料の光学特性の計算
複雑な層状構造のプロトタイプの形成のために、技術的な生産に必要な多くのパラメータを決定する必要がある場合、古典的な設計および生産タスク。 パラメータを決定するには、非常に重要な量子力学的計算を実行する必要があります。 また、さまざまな組み合わせから、サンプルの初期光学要件のセットを最適に満たすパラメーターのセットを選択します。 解析計算自体に直接、Wolfram Mathematicaパッケージが使用されました。
すべてうまくいきますが、重大な問題がありました-計算の複雑さは非常に時間のかかる長い計算につながりました。 そして、材料の特性を分析するには、まず、計算サイクルの結果として得られたさまざまな波長での物体のスペクトル特性を視覚的に分析する必要がありました。 可能な限り、Wolframソフトウェアの利用可能な計算機とライセンスのセット内の計算部分で最適化を達成することができました-計算を複数のコンピューターに並列化し、4-6時間のパラメータの1つの構成で計算時間を達成しました。
しかし、取得した一連のデータの後処理、スペクトルの視覚化およびインタラクティブな分析を含む第2段階では、Wolfram Mathematicaのみに対処することは非常に困難でした。 1つのスペクトルの準備には約20時間かかり、追加の日常的な手作業が必要でした(間違いを犯す確率!)。 グラフィカルな結果は代表的なものではなく、視覚的に非常に貧弱に読まれました(図を参照)。
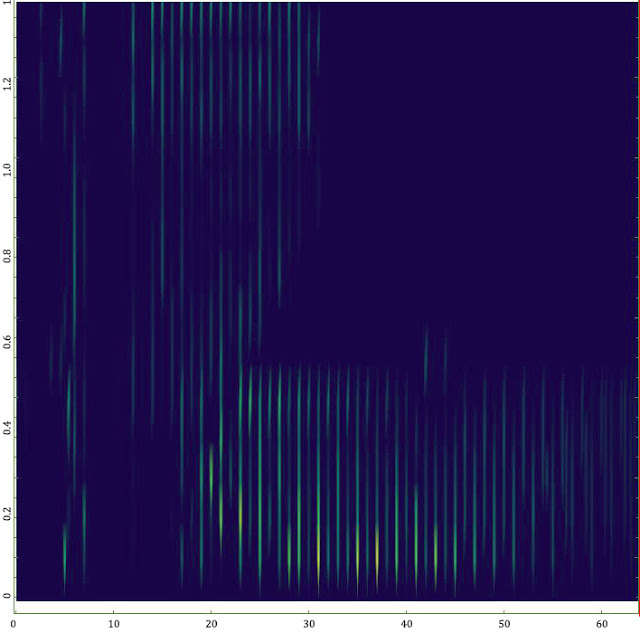
よく知られている機能、マントラ、およびフォーラムの推奨事項の範囲を適用しても、有用な結果は得られませんでした。 Wolfram Mathematicaパッケージに必要なツールが含まれていないことは、特にリリースされたばかりの11番目のバージョンにはこの分野で多くの改善が加えられているため、議論しません。 しかし、問題を解決する時間が限られており、指定された時間までに結果を取得する必要がある状況では、複雑な独自の数学コアの内部原理を透過的に理解することなく、物理的に完全な時間でコードプロファイリングとメモリ最適化を行う時間はありませんでした。 実際問題として、数学パッケージのタスクは、その長所と同様に多少異なります。
したがって、数日のうちに、Rフレームワークにモジュールが作成され、計算されたデータの組み立て、視覚化の処理、および分析の表現が行われました。 分析の結果に基づいて、新しい計算のパラメーターを含むファイルが生成されました。 その結果、20時間からの前処理と視覚化プロセスが5〜7秒に短縮され、3〜4十回の反復中の視覚化が完全に変更され、すべてのアーティストにとって理解可能で明白な次の形式が得られました。
GUIはShiny RStudioに基づいて構築されました。高レベルの統合データ処理および視覚化、ストリーミング値の要素および関数型プログラミング、R上のコンテンツコードが100行未満に収まるパッケージを使用しているためです。
技術的な観点からのみ見ると、タスクは小さいように見えるかもしれません。 ビッグデータも機械学習も統計もありません。 メソッドは使用されません。
ビジネスの観点から見ると、アプリケーションの効果は印象的で重要です。 一時的な厳しい圧力の状態で、作業は時間通りに完了しました。 同時に、従業員の時間を除いてこれにお金は使われませんでした。従業員の時間は何らかの形で給与計算にすでに含まれています。
タスク#2。 異常および予測偏差のデータソースの監視
問題のステートメントは、データを収集し、問題について責任者に通知するための、あらゆる監視のタスクにとって非常にシンプルで古典的です。 そして、もちろん、すべてを使いやすいWebユーザーインターフェイスで表示します。 Excelでの古典的な手動処理は、人件費が一定であり、非常に遅く、ミスがあり、単純なモデルを使用してデータを詳しく調べて分析が行われたため、その関連性が失われています。
また、作業を非常に複雑にするいくつかのニュアンスがありました。
- ソースは、GitHub、ローカルファイル、JSON REST API応答など、非常に異質でした。
- ソース内のタイムスタンプはランダムな順序で送信される可能性があり、データはすでに「クローズ」された期間(バッチで到着する)に到達する可能性があります。
- 欠落データ、さまざまなデータ形式、不規則な時系列、元のデータの代わりに集約メトリックを取得(たとえば、値ではなく移動平均)。
- これは1回限りの計算ではなく、継続的な24時間365日のプロセスです。
主要なタスクはデータ処理と予測分析であったため、問題を解決するためにR言語が選択され、継続的な運用を確保するために、クラシックバージョンであるRスクリプトをスケジュールどおりに実行できます。 しかし、私たちは別のよりエレガントな方法を採用しました。
要件に応じて、WebベースのGUIを提供する必要がありました。 作成するために、Shiny Serverを使用しました。 また、Shinyアプリケーションの詳細は、リアクティブ(イベントに反応)であり、起動時にアプリケーションインスタンスがアクティブなままであるというものです。 そして、ここで古典的なWindows APIアプリケーションのマントラを思い出します。
WHILE(GETMESSAGE(&MSG, NULL, 0, 0) > 0) { TRANSLATEMESSAGE(&MSG); DISPATCHMESSAGE(&MSG); }
これが答えです。 アプリケーション自体がスケジューラとして機能します。 タイマーハンドラーを停止し、リアクティブデータ構造のイベント駆動型再カウントとグラフィック要素の無効化を使用します。 例外処理とロギングを追加します。 データ収集、処理、数学アルゴリズム、外部へのアップロード、外部アクチュエーターの起動、GUI、インタラクティブな視覚化など、すべてがR言語とRStudio環境のフレームワーク内に実装されています。 また、オブジェクトのプロファイリングと分析のために開発された機能により、実行時間と使用されるメモリ量の観点からプログラムを最適化できます。
合成データのGUIプロトタイプは1.5週間以内に現れました。 最終的なポータルである24時間年中無休の安定した作業が1.5か月間完了しました。 特別な必要はありませんが、必要に応じて、数回クリックするだけで、REST APIを使用してDeployRツールを使用してすべての分析をモバイルアプリケーションに提供できます。
おわりに
2014年に、R言語は、限られた構造化データセットに対して複雑な数学アルゴリズムを使用して計算を実行するためのツールとしてのみ使用しました。
2016年に、Rエコシステムを使用してデータ処理を自動化するローカルで複雑なタスクを解決することに成功し、2016構成のRツールにはこれらの問題を解決するために必要なすべてのプロパティがあると確信できます。
データおよびインタラクティブな視覚化ツールを操作するためのRパッケージの集中的な開発、Microsoftの商用ブランチRの買収により、今後2〜3年でエコシステムRの機能が何度も成長すると信じるあらゆる理由が得られます。 特に、PowerBIの積極的な開発とSQL Serever 2016へのRの組み込み、Rとの緊密な統合のための主要な視覚化システム(ロシアで最も人気のあるQlikとTableau)による必須サポート、クラスターコンピューティングのサポート、エンタープライズエディションでのビッグデータプラットフォームの操作、およびその他の興味深い取り組みビジネスタスクにおけるRエコシステムの大きな可能性を示します。
しかし、さらに数年間奇跡を待つのは意味がありません。 すでに、袖をまくり上げて、Rでビジネスタスクの自動化を試みることができます。Rは、どの企業でも12を超える場合があります。 会社のためのお金の節約が保証され、パフォーマーのためのファンと挑戦が広場で提供されます。
前の投稿: 「ITシステムの古典的統合の代替としてのデータサイエンスツール」
次の投稿: 「ビジネスタスクを自動化するための紳士のRパッケージセット」