現代の世界では、ニューラルネットワークは科学とビジネスのさまざまな分野でますます多くのアプリケーションを見つけています。 さらに、タスクが複雑になるほど、ニューラルネットワークも複雑になります。
複雑なニューラルネットワークのトレーニングには、たった1つの構成で数日から数週間かかる場合があります。 また、特定のタスクに最適な構成を選択するには、数回トレーニングを開始する必要があります。これは、非常に強力なマシンであっても数か月の計算を要することがあります。
ある時点で、2015年に導入されたGoogleのバッチ正規化方法を知り 、顔認識の問題を解決するために、ニューラルネットワークの速度を大幅に改善することができました。
猫の下で詳細を尋ねます。
この記事では、現在関連する2つのタスクを組み合わせてみます-これはコンピュータービジョンと機械学習のタスクです。 ニューラルネットワークのアーキテクチャの設計として、すでに示したように、ニューラルネットワークの学習を加速するためにバッチ正規化が使用されます。 ニューラルネットワークのトレーニング(コンピュータービジョンのフレームワーク内で一般的なCaffeライブラリを使用して作成)は、1万4千人の300万人に基づいて行われました。
私のタスクでは、14,700クラスの分類が必要でした。 ベースは、トレーニングサンプルとテストサンプルの2つの部分に分かれています。 テストサンプルの分類精度は既知です:94.5%。 同時に、420万回のトレーニングが必要でした。これは、NVidia Titan Xビデオカードではほぼ4日間(95時間)です。
最初に、このニューラルネットワークでは、学習を加速するためのいくつかの標準的な方法が使用されました。
- 学習率の増加
- ネットワークパラメータの数を減らす
- 特別な方法で学習プロセスの学習率を変更する
これらの方法はすべてこのネットワークに適用されましたが、それらを適用する機能は無意味になりました。 分類精度が低下し始めました。
この時点で、ニューラルネットワークを高速化する新しい方法であるバッチ正規化を発見しました。 このメソッドの作成者は、 LSVRC2012に基づいた標準のInceptionネットワークでテストし、良好な結果を得ました。
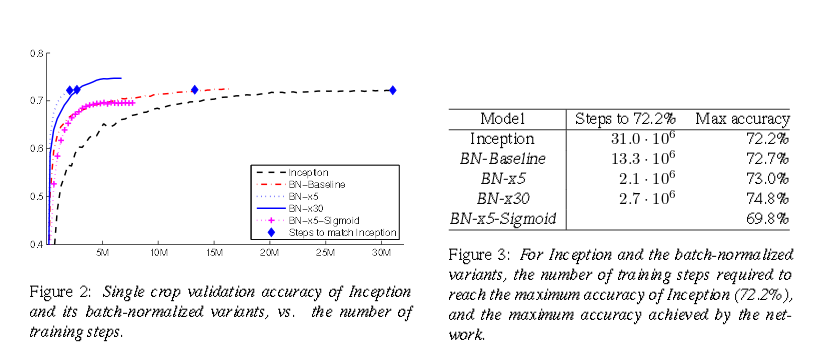
グラフと表から、ネットワークは15倍速く学習し、最終的にはより高い精度を達成したことがわかります。
バッチ正規化とは何ですか?
いくつかの層を持つ古典的なニューラルネットワークを考えます。 各レイヤーには、多くの入力と多くの出力があります。 ネットワークは、エラーの逆伝播の方法、つまりバッチによってトレーニングされます。つまり、トレーニングサンプルのサブセットによってエラーが考慮されます。
標準正規化方法-各kについて、バッチの要素の分布を考慮します。 平均を減算し、サンプルの分散で除算して、0と分散1を中心とする分布を取得します。このような分布により、ネットワークの学習速度が向上します。 すべての番号は同じ順序になります。 ただし、次のように正規化を一般化して、各特性に2つの変数を導入することをお勧めします。

平均分散を取得します。 これらのパラメーターは、逆伝播アルゴリズムの一部になります。
したがって、2 * kパラメーターを持つバッチ正規化レイヤーを取得します。これは、顔認識のために提案されたネットワークのアーキテクチャに追加されます。
50x50ピクセルのサイズの人の顔の白黒画像がタスクに入力されます。 出力では、14000クラスの確率があります。 最大確率を持つクラスは、予測の結果と見なされます。
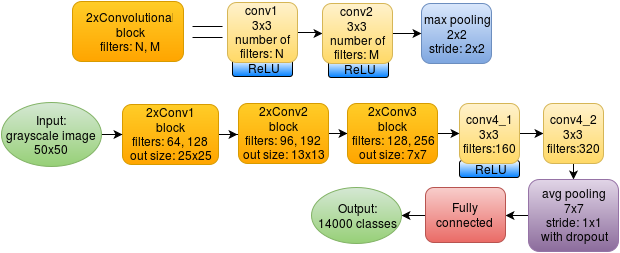
元のネットワークは次のとおりです。
8つのたたみ込み層が使用され、各サイズは3x3です。 各畳み込みの後、ReLUが使用されます:max(x、0)。 2つの畳み込みのブロックの後、セルサイズが2x2の(プールが重複しない)最大プーリングがあります。 最後のプーリング層のセルサイズは7x7で、最大値をとるのではなく値を平均します。 その結果、1x1x320アレイが完成し、完全に接続されたレイヤーに供給されます。
バッチ正規化を使用したネットワークは、もう少し複雑に見えます。
新しいアーキテクチャでは、2つの畳み込みの各ブロックには、それらの間にバッチ正規化レイヤーが含まれています。 また、新しいレイヤーを追加するとグラフィックカードのメモリ消費量が増加するため、2番目のブロックから1つの畳み込みレイヤーを削除する必要がありました。
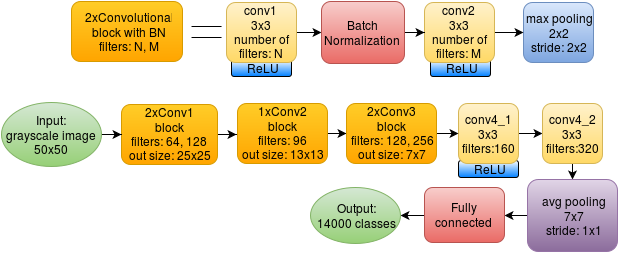
この場合、元の記事のBN著者の使用に関する推奨事項に従ってDropoutを削除しました。
実験評価
主な指標は精度です。正確に分類された画像の数を、テストサンプル内のすべての画像の数で割ります。
バッチ正規化レイヤーを使用してニューラルネットワークを最適化する際の主な困難は、学習率を選択し、ネットワークのトレーニング中に正しく変更することです。 ネットワークをより速く収束させるには、初期学習率を大きくしてから、結果がより正確になるように低下させる必要があります。
学習率を変更するためのいくつかのオプションがテストされています。
| 名 | 変化学習率の式 | 80%の精度で反復 | 収束を完了するための反復 | 最大精度 |
|---|---|---|---|---|
| 元の | 0.01 * 0.1 [ #iter / 150000] | 64000 | 420000 | 94.5% |
| 短いステップ | 0.055 * 0.7 [ #iter / 11000] | 45000 | 180,000 | 86.7% |
| ドロップアウトのない多段階 | 0.055 * 0.7 Nステップ | 45000 | 230,000 | 91.3% |
[x]-整数部
#iter-反復番号
Nsteps-反復で手動で設定されるステップ: 14000、28000、42000、120000 (x4)、160000(x4)、175000、190000、210000
学習プロセスを示すグラフ:ニューラルネットワークのトレーニングの反復回数に応じたテストサンプルの精度:

元のネットワークは420,000回の反復で収束しますが、すべての時間の学習率は150,000回目の反復と300,000回目の反復で2回しか変化しません。 このアプローチは元のネットワークの作者によって提案されたもので、このネットワークでの私の実験はこのアプローチが最適であることを示しました。
ただし、バッチ正規化レイヤーが存在する場合、このアプローチでは結果が悪くなります(long_stepチャート)。 したがって、私の考えは-初期段階で、学習率をスムーズに変更してから、数回ジャンプします(multistep_no_dropoutグラフ)。 チャートshort_stepは、学習率のスムーズな変化が悪化することを示しています。 実際、ここでは記事の推奨事項に依存し、元のアプローチにそれらを適用しようとします。
実験の結果、私はトレーニングをスピードアップすることが可能であるという結論に達しましたが、いずれにしても、精度は少し悪くなります。 顔認識タスクは、Inceptionの記事( Inception-v3 、 Inception-v4 )で検討されているタスクと比較できます:記事の著者は、異なるアーキテクチャの分類結果を比較しましたが、結局、Inception-BNは、バッチ正規化を使用しないInceptionの新しいバージョンよりも劣っています。 私たちの問題では、同じ問題が発生します。 しかし、タスクが許容可能な精度をできるだけ早く取得することである場合、BNは役立ちます。80%の精度を達成するために、元のネットワークの1.4倍の時間がかかります(65000に対して45000の反復)。 これは、たとえば、新しいネットワークの設計やパラメーターの選択に使用できます。
ソフトウェア実装
すでに書いたように、Caffeは私の仕事で使用されています-ディープラーニングのための便利なツールです。 すべてがC ++およびCUDAで実装されているため、コンピューターリソースの最適な使用が保証されます。 これは、このタスクに特に当てはまります。 プログラムが最適に書かれていなければ、ネットワークのアーキテクチャを変更して学習を加速しても意味がありません。
Caffeはモジュール式です-任意のニューラルネットワーク層を接続できます。 バッチ正規化レイヤーの場合、3つの実装が見つかりました。
これらの実装を簡単に比較するために、標準のCifar10ベースを取り、NVidia GeForce 740M(2GB)グラフィックスカード、Intel®Core(TM)プロセッサー(4コア)i5-4200U CPU @ 1.60GHzおよび4GB RAMを使用して、すべてをLinux x64オペレーティングシステムでテストしました。
標準カフェ、tkのカフェウィンドウからの組み込み実装。 Linuxでテスト済み。
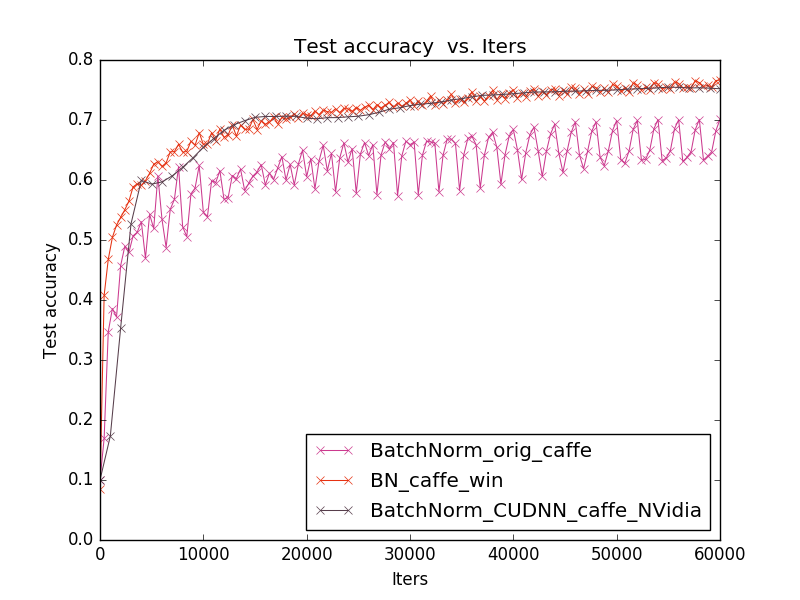
グラフは、1番目の実装が2番目と3番目の精度よりも劣っていることを示しています。さらに、1番目と2番目の場合、予測の精度は反復から反復まで段階的に変化します(最初の場合、ジャンプははるかに強くなります)。 したがって、顔認識タスクでは、より安定した新しいものとして選択されたのは(NVidiaからの)3番目の実装でした。
バッチ正規化レイヤーを追加することによるニューラルネットワークのこれらの変更は、許容可能な精度(80%)を達成するのに要する時間が1.4倍少ないことを示しています。