
前のパートでは、inceptionV3モデルの最後から2番目のレイヤーからの信号による写真ポートフォリオの分割について説明しました。 このパートでは、キーワードでポートフォリオを分割する方法を説明します。
大規模なポートフォリオのキーワード辞書では、約100,000語に達することがあります。 あなたが額で直接行動する場合、私たちは100,000サインを取得します。 多くのキーワードは他のキーワードに関連付けられているため、特に大量の冗長情報が含まれているため、このような大量の情報をRAMに保存したくありません。 たとえば、「家族」は「子供」という言葉でよく見られます。 したがって、単語埋め込み手法を使用します(辞書のキーワードは、辞書の次元に比べて低い次元のスペースの数値と比較されます)。
ポイントごとの相互情報(PMI)を使用してWordの埋め込みを実装します(セクション3.1。 記事 )。
アルゴリズムの概念を簡単に説明すると、キーワードのPMIマトリックスが計算され、次にマトリックスの特異分解が実行されます
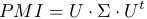 行列が計算されます
行列が計算されます 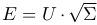 同様の単語が見つかりました。
同様の単語が見つかりました。
キーワードごとに類似した単語を見つけ、類似したグループを除外するためのスクリプト
# coding: utf-8 import pandas as pd import os import json import tqdm import random import pickle from decimal import * import numpy as np from sklearn.preprocessing import normalize from sklearn import metrics, ensemble, neighbors, decomposition, preprocessing, svm from sklearn import cross_validation from scipy.sparse import csr_matrix, lil_matrix from collections import Counter from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer from sklearn.utils.extmath import randomized_svd p_names = [ 'urbancow' ] portfolio_dir = '/home/traineeship/portfolio/' tags_list = list() for name in p_names: rest_info = pd.read_csv(portfolio_dir + name + '/rest_info.csv') for keywords in rest_info['keywords']: s_keywords = str(keywords).replace(',','|||').lower().decode('utf-8') tags_list.append( s_keywords.replace('[','').replace(']','').replace('"','') ) print len(tags_list) vectorizer = CountVectorizer(min_df=0.000, binary=True, tokenizer=lambda doc: doc.split('|||')) X = vectorizer.fit_transform(tags_list) keyword_list = vectorizer.get_feature_names() for i in range(len(keyword_list)): keyword_list[i] = keyword_list[i].strip().rstrip() print len(keyword_list) p = np.asarray(X.mean(axis=0)).ravel() c = Counter() for keywords in tags_list: for k1 in keywords.split('|||'): c.update([(k1, k2) for k2 in keywords.split('|||')]) c_word = Counter() for keywords in tags_list: for w in keywords.split('|||'): c_word[w] += 1 PMI = np.zeros([len(keyword_list), len(keyword_list)]) for i in (range(len(keyword_list))): for j in range(i, len(keyword_list)): joint = c[(keyword_list[i], keyword_list[j])]/float(len(tags_list)) if joint == 0: PMI[i,j] = -1 PMI[j,i] = -1 else: p1 = c_word[keyword_list[i]]/float(len(tags_list)) p2 = c_word[keyword_list[j]]/float(len(tags_list)) PMI[i,j] = np.log(p1*p2)/np.log(joint) - 1 PMI[j,i] = np.log(p1*p2)/np.log(joint) - 1 U, Sigma, VT = randomized_svd(PMI, n_components=2048, random_state=42) E = U.dot(np.diag(np.sqrt(Sigma))) np.save('E_full_k_4096', E) E = normalize(E, axis=1) #define groups of similar words words_groups = [None] * len(keyword_list) for i in range (len(keyword_list)): d = E.dot(E[i]) indexes = np.argsort(d)[::-1] words_group = [None] * 10 idx = 0 for j in indexes[:10]: words_group[idx] = keyword_list[j] idx += 1 words_groups[i] = words_group #remove similar groups for i in range(len(words_groups)): if (words_groups[i] == None): continue for j in range(i + 1, len(words_groups)): if (words_groups[j] == None): continue len_ = len(set(words_groups[i]) & set(words_groups[j])) if (len_ > 5): words_groups[j] = None tmp = list() for i in range(len(words_groups)): if (words_groups[i] == None): continue tmp.append(words_groups[i]) words_groups = tmp np.save('words_groups', words_groups)
兆候を計算するためのスクリプト
# coding: utf-8 import pandas as pd import os import json import tqdm import random import pickle import sys from decimal import * import numpy as np from sklearn.preprocessing import normalize from sklearn import metrics, ensemble, neighbors, decomposition, preprocessing, svm from sklearn import cross_validation from scipy.sparse import csr_matrix, lil_matrix from collections import Counter from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer from sklearn.utils.extmath import randomized_svd p_names = [ 'urbancow' ] portfolio_dir = '/home/traineeship/portfolio/' tags_list = list() for name in p_names: rest_info = pd.read_csv(portfolio_dir + name + '/rest_info.csv') for keywords in rest_info['keywords']: s_keywords = str(keywords).replace(',','|||').lower().decode('utf-8') tags_list.append( s_keywords.replace('[','').replace(']','').replace('"','') ) name = p_names[0] print len(tags_list), name vectorizer = CountVectorizer(min_df=0.000, binary=True, tokenizer=lambda doc: doc.split('|||')) X = vectorizer.fit_transform(tags_list) keyword_list = vectorizer.get_feature_names() for i in range(len(keyword_list)): keyword_list[i] = keyword_list[i].strip().rstrip() print len(keyword_list), len(tags_list) E = np.load('E_full_k_4096.npy') E = normalize(E, axis=1) words_groups = np.load('words_groups.npy') print len(words_groups) getcontext().prec = 4 features_name = "gm_id,"+",".join("w%s" %i for i in range(len(words_groups))) + '\n' rest_info = pd.read_csv(portfolio_dir + name + '/rest_info.csv') keywords_csv = open(portfolio_dir + name + '/keywords.csv','w') keywords_csv.write(features_name) no_processed_keywords = rest_info['keywords'] processed_splited_keywords = list() for i in range(len(no_processed_keywords)): no_processed_keywords[i] = no_processed_keywords[i].decode('utf-8') no_processed_keywords[i] = no_processed_keywords[i].lower().replace('[','').replace(']','').replace('"','') splited_keywords = no_processed_keywords[i].split(',') for j in range(len(splited_keywords)): splited_keywords[j] = splited_keywords[j].strip().rstrip() processed_splited_keywords.append(set(splited_keywords)) #count similarity between keywords of image and words_groups[i] for i in range(len(processed_splited_keywords)): words = processed_splited_keywords[i] features = [0] * len(words_groups) for j in range(len(words_groups)): features[j] += Decimal(len(words & set(words_groups[j]))) / Decimal(len(set(words_groups[j]))) str_features = str(rest_info['gm_id'][i])+','+','.join(str(feature) for feature in features) + '\n' keywords_csv.write(str_features)
データの視覚化とディメンション圧縮については、第1部で詳しく説明します。
キーワードでポートフォリオを視覚化するスクリプト
# coding: utf-8 import numpy as np import pandas as pd import sys import matplotlib as mpl mpl.use('Agg') import matplotlib.pyplot as plt import json import os import cv2 from sklearn import manifold, decomposition from matplotlib.offsetbox import OffsetImage, AnnotationBbox from scipy.stats import gaussian_kde import gc p_names = [ 'urbancow' ] def imscatter(x, y, image, ax=None, label=False): label=label==True im = OffsetImage(image) x, y = np.atleast_1d(x, y) artists = [] for x0, y0 in zip(x, y): ab = AnnotationBbox(im, (x0, y0), xycoords='data', frameon=label) artists.append(ax.add_artist(ab)) ax.update_datalim(np.column_stack([x, y])) ax.autoscale() return artists name = p_names[0] portfolio_dir = '/home/traineeship/portfolio/' images_directory = portfolio_dir + name + '/images/' keywords_path = portfolio_dir + name + '/keywords.csv' rest_info = pd.read_csv( portfolio_dir + name + '/rest_info.csv' ) gm_ids = rest_info['gm_id'] keywords_info = pd.read_csv(keywords_path) print len(keywords_info), len(gm_ids) downloads = dict( zip( list( map( str, rest_info['gm_id'] ) ), rest_info['downloads'] ) ) keywords_info.drop('gm_id',inplace=True,axis=1) X = keywords_info.as_matrix() print len(X) y = np.array( [ downloads[str(gm_id)] for gm_id in gm_ids ] ) #downloads count sd_downloads = y.std() mean_downloads = y.mean() X_list = list() y_list = list() gm_ids_list = list() if (len(X) > 5000): batches_count = len(X) / 5000 + 1 index = 0 for i in range(batches_count - 1): if (i < batches_count - 2): X_list.append(X[index:index+5000]) y_list.append(y[index:index+5000]) gm_ids_list.append(gm_ids[index:index+5000]) elif (i == batches_count - 2): if (len(X[index+5000:]) < 1000): X_list.append(X[index:]) y_list.append(y[index:]) gm_ids_list.append(gm_ids[index:]) batches_count -= 1 else: X_list.append(X[index:index+5000]) y_list.append(y[index:index+5000]) gm_ids_list.append(gm_ids[index:index+5000]) index += 5000 X_list.append(X[index:]) y_list.append(y[index:]) gm_ids_list.append(gm_ids[index:]) index += 5000 else: X_list.append(X) y_list.append(y) gm_ids_list.append(gm_ids) print len(X_list), len(X) del X del y del gm_ids del rest_info del keywords_info del downloads gc.collect() for ii in range(len(X_list)): X = X_list[ii] y = y_list[ii] gm_ids = gm_ids_list[ii] #TruncatedSVD due to sparse data X = decomposition.TruncatedSVD(n_components=50).fit_transform(X) X = manifold.TSNE().fit_transform(X) fig, ax = plt.subplots() scale_factor=15 fig.set_size_inches(16*scale_factor, 9*scale_factor, forward=True) for i, gm_id in enumerate( gm_ids ): image_path = images_directory + str(gm_id) + '.jpg' try: image=cv2.imread(image_path) b,g,r = cv2.split(image) # get b,g,r image = cv2.merge([r,g,b]) # switch it to rgb image=cv2.resize(image, (80, 80)) except Exception as ex: size = 80, 80, 3 image = np.zeros(size, dtype=np.uint8) pass x1=X[i, 0] x2=X[i, 1] imscatter(x1, x2, image, ax) ax.plot(x1, x2) for idx in range(4): if (idx == 0): x1=X[y == 0][:,0] x2=X[y == 0][:,1] elif (idx == 1): x1=X[(y > 0) & (y <= mean_downloads + sd_downloads)][:,0] x2=X[(y > 0) & (y <= mean_downloads + sd_downloads)][:,1] elif (idx == 2): x1=X[(y > mean_downloads + sd_downloads) & (y <= mean_downloads + 2 * sd_downloads)][:,0] x2=X[(y > mean_downloads + sd_downloads) & (y <= mean_downloads + 2 * sd_downloads)][:,1] elif (idx == 3): x1=X[y > mean_downloads + 2 * sd_downloads][:,0] x2=X[y > mean_downloads + 2 * sd_downloads][:,1] xy = np.vstack([x1,x2]) kde = gaussian_kde(xy)#simple density estimation z = kde(xy) xmin, xmax = ax.get_xlim() ymin, ymax = ax.get_ylim() xedges = np.linspace(xmin, xmax, 700) yedges = np.linspace(ymin, ymax, 700) xx, yy = np.meshgrid(xedges, yedges) gridpoints = np.array([xx.ravel(), yy.ravel()]) zz = np.reshape(kde(gridpoints), xx.shape) im = ax.imshow(zz, cmap='jet', interpolation='nearest', origin='lower', extent=[xmin, xmax, ymin, ymax]) ax.grid() suffix_name = str(idx) + '_tsne_part'+str(ii)+'.png' fig.savefig('vism/'+name+'/'+name+'_'+ suffix_name, dpi=100, bbox_inches='tight') fig.clf() ax.cla()
パート1の著者のポートフォリオを検討します(2歳以下の写真のみを考慮します;約5000枚の写真)。
次の写真が作成されました。
著者は、キーワードによって次の人気のあるトピックを持っていることが判明しました。
- 上からのストリート写真
- 大勢の人がいる場所(メトロ、...);
- 観光地
- 小学生
- 子供がいるスーパーマーケット内
- カウボーイ; 馬
- パン屋; 公共ケータリングのキッチン
- インディアン
- 自転車屋
- フィールドで
- 風景; 自然(やや売れている)
キーワードで人気がありません:
- 第3世界の国々を旅します。 彼らの習慣、生活
キーワードによってすでに計算された属性を持つ別の著者のPS ポートフォリオ