
だから、私の経験について少し:
1)一般に、私はPHPプログラマーであり、Pythonで初めて書いてTシャツを獲得したロシアのAIカップ2015に参加することによってのみ、Pythonについてほとんど知りません。
2)職場では、scikit-learnを使用して、テキストの調性を決定する1つの問題を解決しました。
3)Yandexのcoursera.orgで機械学習のコースを開始しました。
ここで、Pythonと機械学習の私の経験が終わります。
競争の始まり
挑戦する
異なるマトリックスサイズおよび他のシステムとハードウェアパラメーターを持つ他のコンピューターシステムでこの問題がどれだけ解決されているかがわかっている場合、コンピューターシステムでサイズmxkとkxnの2つのマトリックスが乗算される秒数を予測するようコンピューターに教える必要があります。
問題のパラメーター(m、k、n)およびアルゴリズムと計算時間が実行されたコンピューティングシステムの特性など、個別の計算実験を説明する一連の機能が提供されます。 そして、時間を予測する必要があるテストサンプル。
問題を解決するための品質基準として、最小の平均相対誤差が1秒以上動作する実装に使用されます。

問題のパラメーター(m、k、n)およびアルゴリズムと計算時間が実行されたコンピューティングシステムの特性など、個別の計算実験を説明する一連の機能が提供されます。 そして、時間を予測する必要があるテストサンプル。
問題を解決するための品質基準として、最小の平均相対誤差が1秒以上動作する実装に使用されます。
私は自分でpython3とノートブックをインストールし、 チュートリアルの記事からパンダを扱い始めました。 データをダウンロードし、ランダムフォレストにフィードすると、出力が〜0.133になりました
この問題の解決についての考えはすべて終わりました。
主題研究および追加情報の収集
私はタスクに戻り、「 A。A.シドネフ、V。P.ゲルゲルの仕事から問題のアイデアを得た 」という行にしがみついています。 実際、この本はそのような問題を解決する方法を説明しています。 確かに、私はこのアイデアを実装する方法を理解していませんでしたが、興味深いスケジュールを見ました:
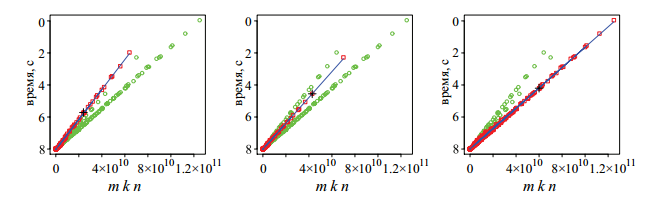
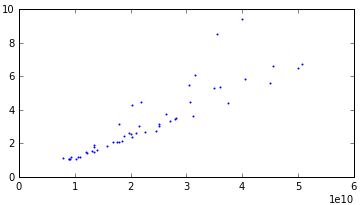
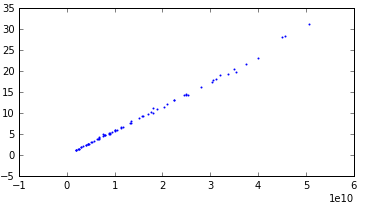
うーん、しかし、実際には、行列のサイズへの時間の依存性は線形であるはずで、私は考えて、これが私たちのデータでどうなるかを見ることにしました。 すべての例を特性でグループ化すると、92個のグループしかないことがわかりました。 実際に各オプションのグラフを作成したところ、半分が小さな外れ値と線形関係にあることがわかりました。 そして、残りの半分も直線的な関係を示しましたが、強い分散がありました。 グラフはたくさんあるので、3つの例を挙げます
分散あり:
線形:
非常に強い分散:
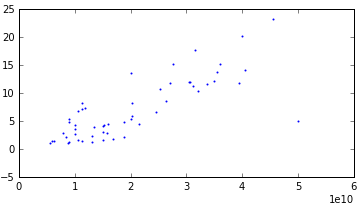
最後のスケジュールは、相互検証で不十分な結果を示したため、別のグループとして選択されました。 私はこの場合に特別なことをすることにしました(しかし、最終的には特別なことは何もしませんでした)。
データを操作する
実際には、各グループの線形回帰を作成し、約0.076を得ました。 ここで、問題を解決する鍵を見つけたと思い、グラフィックスに適応し始めました。 scikit-learnにあるほとんどすべての回帰モデルを試してみました(はい、知識がありません。したがって、科学的な突っ込みの方法で問題を解決しました)。結果はあまり改善しませんでした。
多項式も導入しました。 すべてのグループを実行し、GridSearchCVを使用して、各グループに最適なパラメーターを検索しました。 一部のグループでは、思い通りに曲がらないことに気付きました。 データの操作を開始しました。 最初に、メモリデータ(memtRFC、memFreq、memType)が欠落している行があることに気付きました。 論理的な推論だけを使用して、このデータを復元しました。 たとえば、memtRFCが「DDR-SDRAM PC3200」および「DDR-SDRAM PC-3200」に等しいデータがありました。 明らかに、これは同じことです。
これによりグループの数が減ることを期待していましたが、それではうまくいきませんでした。 さらに、彼は排出ガスを扱うようになりました。 良いことには、放射を自動的に検出するメソッドを記述する必要がありますが、私はすべてを自分の手で行いました。 彼はすべてのグループのグラフを描き、異常値を視覚的に決定し、これらのポイントを除外しました。
相互検証
結局のところ、テストで0.064、実際には0.073の結果が表示されるという問題に遭遇しました。 どうやら再訓練。 fitメソッドとpredictメソッドを使用してクラスラッパーを作成しました。その中で、データをグループに分割し、各グループのモデルをトレーニングし、各グループで同じことを予測しました。 これにより、相互検証を使用できました。 実際、その後のテストの結果とダウンロードしたデータは常に非常に近いものでした。
次のようになりました。
class MyModel: def __init__(self): pass def fit(self, X, Y): # x, , def predict(self, X): # x, , def get_params(self, deep=False): return {}
今、cross_validation.cross_val_scoreの助けを借りて、定性的にアプローチをテストできました。
問題の条件を超えたデータを操作することで、別の小さな利益が得られました。 条件により、Yを1より小さくすることはできません。 統計を確認した後、最小Y = 1.000085であり、私の予測では1未満の結果が得られたことがわかりました。それほど多くはありませんでした。 入力してこの問題を解決しました。 結果の式は次のとおりです。
time_new = 1 + pow(time_predict/2,2)/10
ある時点で、抽象的な問題を解決するだけでなく、特定の問題を解決する必要がある、つまり時間予測の精度ではなく、エラーを最小限に抑える必要があることに気付きました。 これは、スクリプトのリアルタイムが10秒で、2つのミスを犯した場合、エラーは| 10-8 | / 10 = 0.2であることを意味します。 そして、時間が実際に2秒で、0.1のミスを犯した場合、| 2-0.1 | / 2 = 0.95です。
違いは明らかです。 これに気づき、何らかの理由でこれがすぐには起こらなかったため、短時間で精度を上げることにしました。 彼の線形重量回帰に追加されました。 選択方法を使用して、次の式1 / pow(Y、3.1)を取得しました。 つまり、時間が長いほどその重要性は低くなります。 これに放出抵抗モデルを追加して、私は最終的に4つのモデルの束を得ました
LinearRegression() # TheilSenRegressor() Pipeline([('poly', PolynomialFeatures()), ('linear', TheilSenRegressor())]) # GreadSearchCV
実際、これらのモデルの平均値は0.057でした。 その後、14位にジャンプし、その後20にまでロールダウンしました。
最良のパラメーターを選択し、モデルとその組み合わせを変更し、偽のポイントを追加することで、何らかの方法で結果を改善する試みは成功しませんでした。
フィニッシュライン
明らかに線形のグループでは、結果は優れていたため、強い分散を持つデータを扱う必要がありました。 予測に分散を追加することにしました。このため、明確に線形ではないすべてのグループでExtraTreesRegressorをトレーニングし、モデルに従って36個の最も重要なパラメーターを取りました。 ループ内で、これらの36個のパラメーターのみからのデータに基づいて相互検証を行うスクリプトを作成しました。そのたびに1つのパラメーターを除外しました。 したがって、どのパラメーターがなくても最良の結果が得られるのを見ました。 品質の改善が止まるまで、この繰り返しを繰り返しました。 はい、最初の反復で除外されたパラメーターが5番目の反復で増加する可能性があるため、これは正しいアプローチではありません。 良いことには、すべてのオプションをチェックする必要がありましたが、これは長すぎたため、品質が数パーセント向上し、結果に満足しました。
さらに、非線形グループの場合、別のモデルが追加されましたが、特別な条件があります。 ExtraTreesRegressorによって予測された時間が、線形モデルによって予測された平均時間よりも短い場合、それらの間の平均を取りましたが、それよりも長い場合、線形モデルによって予測された時間のみを取りました。 (リアルタイムがより高ければ、エラーはより少ないので、より小さな方向でミスをする方が良いです)。
これで私は8位になり、そこから再び10位に落ちました。 結果をどうにかして改善しようとする私の残りの試みも実を結ばなかった。 すべてのテスト結果を再集計すると、9位でした。 TOP 10の最後とそこに含まれていない場合、ポイントの差は約0.0002です。 これは非常に小さく、このターンでの運の重要性を示しています。
まとめ
それで、私が自分のためにした結論:
- 常に相互検証を使用します。
- エラーを最小限に抑えるようにしてください。
- データ(外れ値、またはデータの不足)を処理する必要があります。
賞品
賞品が少なく、すでに10か所であったことは良いことです。これにより、賞品の場所に絞ることができました。 彼はハードドライブのためにメールオフィスに行き、イリヤが私に会い( sat2707 )、賞品を渡し、ジュースを1杯飲んで、展望台を見せました。 彼らはまた、大きな賞品を伴う新しいコンテストが計画されていることを私に保証したので、私たちは待つでしょう。
私はすべてを持っています、ありがとう、みんなに幸運を!