1から10000までの整数の配列を含むマルチギガバイトのファイルがあります。要素は繰り返しでランダムに配置されます。 並べ替える必要があります。 リソースの制約を考慮してください。
最も怠zyなソート方法は「外部マージソート」を使用することですが、これは非常に困難で長い方法です。 この出版物では、どの方法が私に起こったかをお伝えします-私はそれを共有せざるを得ませんでした。
そのため、1〜10,000であり、同時にリソースが限られているというデータディクショナリに混乱しました。 私は次のことをすることにしました。 まず、手で記述するのではなく、必要な入力ファイルを生成します。 これには、古き良きrndを使用しました。
System.IO.StreamWriter file = new System.IO.StreamWriter(@"C:\1\Nabor.txt", true); // Random rnd = new Random(); this.progressBar1.Maximum = Convert.ToInt32(this.textBox1.Text); // int value; for (int i = 0;i<Convert.ToInt32(this.textBox1.Text);i++) // { value = rnd.Next(0, 10000); file.WriteLine(value); // this.progressBar1.Value++; } file.Close();
次に、ソート自体:
1.配列int [10000]を作成します。 RAMでは、40 MBかかります。 C#で(他の言語でもう少し)。 これをarrayRAMと呼び、ソース配列はarrayINで、出力配列はarrayOUTです。
なぜ10,000ですか? 1〜10,000の範囲のデータディクショナリがあるためです。
2.要素ごとにソースファイルを読み取り(私の場合は1行ずつ)、各レコードで次の操作を行います。
string line; // int[] arr; arr = new int[10000]; // System.IO.StreamReader file2 = new System.IO.StreamReader(@"C:\1\Nabor.txt"); while ((line = file2.ReadLine()) != null) { arr[Convert.ToInt32(line)]++; // } file2.Close();
つまり、 配列INから読み取られた値に等しいインデックスを持つRAM配列の要素で、+ 1を実行します。 その結果、 RAM配列にはarrayINの各要素の繰り返し数が含まれます。
私は明らかに図に描写しようとしました:
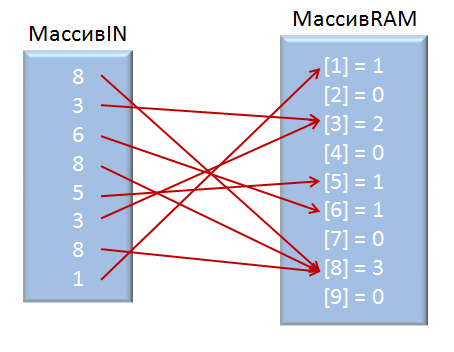
3.そして、 RAMアレイを最後まで実行し、 RAMアレイの要素のすべてのインデックスを繰り返し回数で書き留めます 。
System.IO.StreamWriter file3 = new System.IO.StreamWriter(@"C:\1\Sort.txt", true); int i, j; for (i=0;i<10000;i++) { if (arr[i]>0) // { for (j = 0; j < arr[i]; j++) // , = RAM { file3.WriteLine(i); // , } } } file3.Close();
したがって、100,000,000レコードの575MBファイルは、AMD A10、6GB、SATAのマシンで7.53秒でソートおよび記録されました。 メモリとリソースへの欲望なし。
最後に、型のオーバーフローを避けて 、 このメソッドを慎重に使用する必要があると言いたいです。 つまり、同じデータディクショナリで5,000,000,000の値の配列を取得し、その中のすべての値が同じ数であると仮定すると、intオーバーフローが発生し、プログラムは例外をスローします。
プロジェクト全体は、レイアウトする意味がないと思いますが、希望があれば投稿します。 成功した開発!)