
この記事では、オブジェクトのバイナリ分類と、最も生産的な機械学習パッケージの1つである「R」-「XGboost」(Extreme Gradient Boosting)での実装について説明します。
実際には、イベントの結果を予測したり、データモデルに基づいてバイナリ項で決定を下したりする必要がある場合、予測の対象が2段階の名義変数である問題のクラスにしばしば遭遇します。 たとえば、市場の状況を評価し、目標が特定の商品に特定の時期に投資することが理にかなっているか、買い手がテスト製品を購入するかどうか、借り手がローンを完済するか従業員が近い将来会社を辞めるかを明確に決定することである場合など
一般的なケースでは、 バイナリ分類を使用して、多くの特徴の値から特定のイベントの確率を予測します。 これを行うために、2つの値(0または1)の1つだけをとる、いわゆる従属変数(イベント結果)と多くの独立変数(符号、予測子、または回帰変数とも呼ばれます)が導入されます。
「R」には、同様の問題を解決するための標準関数パッケージの「glm」などのいくつかの線形関数がありますが、ここでは「XGboost」パッケージに実装されたバイナリ分類のより高度なバージョンを検討します。 Kaggleコンペティションの複数の勝者であるこのモデルは、マルチスレッドデータ処理をサポートできるバイナリ決定ツリーの構築に基づいています。 モデルの「勾配ブースティング」ファミリの実装の機能については、こちらをご覧ください。
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3885826/
https://en.wikipedia.org/wiki/Gradient_boosting
テストデータセット(Train)を取得し、衝突時の乗客の生存を予測するためのモデルを作成します。
data(agaricus.train, package='xgboost') data(agaricus.test, package='xgboost') train <- agaricus.train test <- agaricus.test
変換後、マトリックスに多くのゼロが含まれている場合、そのようなデータの配列を最初にスパースマトリックスに変換する必要があります-この形式では、データが占めるスペースがはるかに少なくなるため、データ処理時間が大幅に短縮されます。 最新のバージョン1.2-6には、列ベースでdgCMatrixに変換するための一連の関数が含まれています。
すべての変換後の既に圧縮されたマトリックス(スパースマトリックス)がRAMに収まらない場合、そのような場合、特別なプログラム「Vowpal Wabbit」を使用します。 これは、多くのファイルまたはデータベースから読み取って、任意のサイズのデータセットを処理できる外部プログラムです。 「Vowpal Wabbit」は、Yahoo!による分散コンピューティング向けに開発された並列機械学習向けの最適化プラットフォームです。詳細については、次のリンクを参照してください。
https://habrahabr.ru/company/mlclass/blog/248779/
https://en.wikipedia.org/wiki/Vowpal_Wabbit
スパース行列を使用すると、テキスト変数とその予備変換を使用してモデルを構築できます。
そのため、予測子のマトリックスを作成するには、まず必要なライブラリをロードします。
library(xgboost) library(Matrix) library(DiagrammeR)
マトリックスに変換すると、すべてのカテゴリ変数が転置されます。標準ブースターを使用した関数では、モデルに値が含まれます。 最初に行うことは、「Passenger ID」、「Name」、「Ticket Number」など、一意の値を持つ変数をデータセットから削除することです。 予測される結果が計算されるテストデータセットを使用して同じアクションを実行します。 明確にするために、ローカルファイルからデータをダウンロードし、対応するKaggleデータセットにダウンロードしました。 モデルの場合、次の表の列が必要です。
input.train <- train[, c(3,5,6,7,8,10,11,12)] input.test <- test[, c(2,4,5,6,7,9,10,11)]
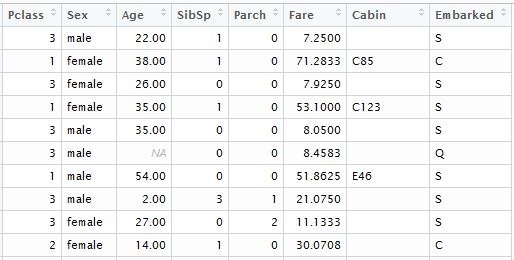
モデルトレーニングの既知の結果のベクトルを個別に形成する
train.lable <- train$Survived
ここで、データ変換を実行して、会計のモデルをトレーニングするときに、統計的に有意な変数が受け入れられるようにする必要があります。 次の変換を実行します。
カテゴリデータを含む変数を数値に置き換えます。 'good'、 'normal'、 'bad'などの順序付けられたカテゴリは0、1、2に置き換えることができることに留意してください。 「性別」や「国名」など、選択性が比較的低い順不同のデータは、変更せずに因子なしのままにすることができます。行列に変換した後、対応する数の列に0と1で転置されます。 数値変数の場合、すべての未割り当て値と欠損値を処理する必要があります。 ここには少なくとも3つのオプションがあります。それらは1、0で置き換えることができます。または、より受け入れられるオプションは、この変数の列の平均値で置き換えることです。
標準ブースター(gbtree)で「XGboost」パッケージを使用する場合、線形ブースター(gblinear)で「glm」や「xgboost」などの他の線形方法とは異なり、変数をスケーリングできません。
パッケージに関する基本情報は、次のリンクにあります。
https://github.com/dmlc/xgboost
https://cran.r-project.org/web/packages/xgboost/xgboost.pdf
コードに戻ると、結果として次の形式のテーブルが得られました。

次に、不足しているすべてのエントリを予測列の算術平均に置き換えます
if (class(inp.column) %in% c('numeric', 'integer')) { inp.table[is.na(inp.column), i] <- mean(inp.column, na.rm=TRUE)
前処理の後、「dgCMatrix」への変換を行います。
sparse.model.matrix(~., inp.table)
予測子の前処理とsparse.model.matrix形式への変換用に別の関数を作成することは理にかなっています。たとえば、「for」ループを持つバリアントを以下に示します。 パフォーマンスを最適化するには、「適用」関数を使用して式をベクトル化します。
spr.matrix.conversion <- function(inp.table) { for (i in 1:ncol(inp.table)) { inp.column <- inp.table [ ,i] if (class(inp.column) == 'character') { inp.table [is.na(inp.column), i] <- 'NA' inp.table [, i] <- as.factor(inp.table [, i]) } else if (class(inp.column) %in% c('numeric', 'integer')) { inp.table [is.na(inp.column), i] <- mean(inp.column, na.rm=TRUE) } } return(sparse.model.matrix(~.,inp.table)) }
次に、関数を使用して、実際のテーブルとテストテーブルをスパース行列に変換します。
sparse.train <- preprocess(train) sparse.test <- preprocess(test)

モデルを作成するには、2つのデータセットが必要です。作成したデータ行列と、バイナリ値(0,1)を持つ実際の結果のベクトルです。
xgboost関数は、最も便利に使用できます。 「XGBoost」は、バイナリ決定ツリーに基づいた標準ブースターを実装しています。
「XGboost」を使用するには、次の3つのパラメーターのいずれかを選択する必要があります:一般パラメーター、ブースターパラメーター、および宛先パラメーター:
•一般的なパラメーター-使用するブースターを決定します(線形または標準)。
残りのブースターオプションは、最初のステップで選択したブースターによって異なります。
•トレーニングタスクのパラメーター-トレーニングの目的とシナリオを決定します
•コマンドラインオプション—「xgboost。」を使用する際のコマンドラインモードの決定に使用されます。
使用する「xgboost」関数の一般的なビュー:
xgboost(data = NULL, label = NULL, missing = NULL, params = list(), nrounds, verbose = 1, print.every.n = 1L, early.stop.round = NULL, maximize = NULL, ...)
「データ」-マトリックス形式のデータ(「マトリックス」、「dgCMatrix」、ローカルデータファイル、または「xgb.DMatrix」。)
「ラベル」は、従属変数のベクトルです。 このフィールドが元のパラメーターテーブルのコンポーネントであった場合、それを処理してマトリックスに変換する前に、関係の推移性を避けるために除外する必要があります。
「nrounds」–最終モデルで構築された決定木の数。
「客観的」-このパラメーターを通じて、タスクとモデルトレーニングの割り当てを転送します。 ロジスティック回帰の場合、2つのオプションがあります。
"reg:logistic"-連続評価が0〜1のロジスティック回帰。
「バイナリ:ロジスティック」は、バイナリ予測値を使用したロジスティック回帰です。 このパラメーターでは、0から1への遷移に特定のしきい値を設定できます。デフォルトでは、この値は0.5です。
モデルのパラメーター化の詳細については、このリンクをご覧ください。
http://xgboost/parameter.md%20at%20master%20·%20dmlc/xgboost%20·%20GitHub
それでは、「XGBoost」モデルの作成とトレーニングを始めましょう。
set.seed(1) xgb.model <- xgboost(data=sparse.train, label=train$Survived, nrounds=100, objective='reg:logistic')
必要に応じて、xgb.model.dt.tree(model = xgb)関数を使用してツリー構造を抽出できます。 次に、標準関数「予測」を使用して予測ベクトルを作成します。
prediction <- predict(xgb.model, sparse.test)
最後に、読み取り可能な形式でデータを保存します
solution <- data.frame(prediction = round(prediction, digits = 0), test) write.csv(solution, 'solution.csv', row.names=FALSE, quote=FALSE)
予測結果のベクトルを追加すると、次の形式のテーブルが取得されます。

少し戻って、作成したモデル自体を簡単に見てみましょう。 決定木を表示するには、関数「xgb.model.dt.tree」および「xgb.plot.tree」を使用できます。 したがって、最後の関数は、モデル適合係数を持つ選択されたツリーのリストを提供します。

関数xgb.plot.treeを使用すると、ツリーのグラフィカル表現も表示されますが、現在のバージョンでは、この関数で実装される最良の方法とはほど遠いため、ほとんど役に立たないことに注意してください。 したがって、明確にするために、標準のTrainデータモデルに基づいて基本決定ツリーを手動で再現する必要がありました。
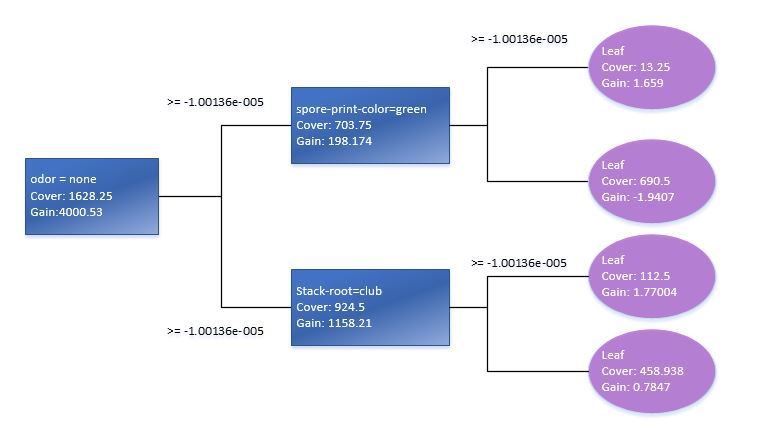
モデル内の変数の統計的有意性を確認すると、XGBモデルをトレーニングするための予測子マトリックスを最適化する方法がわかります。 パラメータの重要度の集計テーブルを渡すxgb.plot.importance関数を使用するのが最適です。
importance_frame <- xgb.importance(sparse.train@Dimnames[[2]], model = xgb) xgb.plot.importance(importance_frame)

そこで、標準ブースターを備えた「xgboost」関数のパッケージに基づいたロジスティック回帰の可能な実装の1つを検討しました。 現時点では、機械学習モデルの最も高度なグループとして「XGboost」パッケージを使用することをお勧めします。 現在、「XGboost」ロジックに基づく予測モデルは、金融および市場の予測、マーケティング、およびその他の多くの応用分析および機械知能分野で広く使用されています。