
oosDesignで友達になる
大規模なインターネット企業は、ビッグデータの処理やソーシャルネットワークのグラフの分析などの複雑なタスクに直面することがよくあります。 フレームワークはソリューションに役立ちますが、最初に可能なオプションを分析し、適切なオプションを選択する必要があります。 Technosphere Mail.Ruの研究室では、Mail.Ru Groupプロジェクト(myTarget、Mail.Ru Search、Antispam)の実際の例を使用してこれらの問題を研究しています。 タスクは、純粋に実用的であり、研究コンポーネントを使用することができます。 これらのタスクの1つに基づいて、この記事が登場しました。
Giraphでの最初のプロジェクトの組み立てと立ち上げ中に、Mail.Ruテクノスフィアデータ分析研究所の従業員は多くの問題に直面し、最初のGiraphプロジェクトを構築して立ち上げる方法に関する短いチュートリアルを書くというアイデアに至りました。
この記事では、人気のあるHadoopデータ処理システムのアドオンであるGiraphフレームワーク用に独自のアプリケーションを作成する方法を説明します。
0.ギラフとは
Giraphは、非常に人気のあるHadoop分散データ処理システム上で実行される大規模なグラフ反復フレームワークです。 HadoopとHDFSの推進力がMapReduceとGFS (Google File System)の概念に関するGoogleの記事から来たように、Giraphは2010年に公開されたGoogleのPregelのオープンソースバージョンとして登場しました。 Giraphは、 Facebookなどの大企業がグラフを処理するために使用します。
Giraphの機能は何ですか? その主な「トリック」は、いわゆる頂点中心モデルです。 Apache Giraphを使用したPractical Graph Analyticsで書かれているように:
このモデルでは、開発者がピークの最中にいる必要があり、反復間で他のピークとメッセージを交換できます。 開発中、並列化とスケーリングの問題について考える必要はありません-これがGiraphの目的です。
Giraphグラフの処理は次のとおりです。プロセスはスーパーステップと呼ばれる反復に分割されます。 各スーパーステップで、頂点は必要なプログラムを実行し、必要に応じて他の頂点にメッセージを送信できます。 次の反復で、頂点はメッセージを受信し、プログラムを実行し、メッセージを送信します。すべてのスーパーステップを完了すると、結果のグラフが得られます。
Giraphは、頂点の作成/削除、エッジの作成/削除、グラフの指定または既存のものからの選択、ディスクからの読み込みの制御、および作業中のグラフの一部のディスクへのアンロードを含む、グラフと対話するための多数のオプションをサポートしますなどなど。 詳細については、Apache Giraphを使用した実用的なグラフ分析を参照してください。
1.必要なソフトウェア
まず、Hadoop自体が必要です。 Hadoopを使用してクラスターにアクセスできない場合は、シングルノードバージョンをデプロイできます。 リソースをあまり必要としませんが、ラップトップで静かに動作します。 これには、たとえば、Clouderaと呼ばれるHadoopディストリビューションを使用できます。 Clouderaのインストールマニュアルはこちらにあります 。 この記事では、開発およびテスト中にCloudera 5.5(Hadoop 2.6.0)が使用されました。
GiraphはJavaで実装されています。 プロジェクトをビルドするとき、 Mavenビルドマネージャーが使用されます。 Giraphのソースコードは、 公式Webサイトからダウンロードできます。 Giraph自体のコンパイル手順とそれに付属するサンプルは、 こちらとクイックスタートガイドに記載されています。
EclipseやIntelliJ IDEAなどのすべてのIDEは、プロジェクトでMavenと連携できます。これは、開発中に非常に便利です。 実験ではIntelliJ IDEAを使用しました。
2. Giraphのコンパイル
Giraphソースの内容をコンパイルして、何かを実行してみましょう。 手順で説明したように、Giraphプロジェクトのあるフォルダーで、次のコマンドを実行します。
mvn -Phadoop_2 -fae -DskipTests clean install
そして、すべてが進行するまでしばらく待ちます...収集されたjarファイルはgiraph-examples / targetフォルダーに表示されます。giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependenciesが必要です。瓶。
たとえば、 SimpleShortestPathsComputationを実行してみましょう。 まず、入力データを含むファイルが必要です。 クイックスタートガイドの例をご覧ください。
[0,0,[[1,1],[3,3]]] [1,0,[[0,1],[2,2],[3,1]]] [2,0,[[1,2],[4,4]]] [3,0,[[0,3],[1,1],[4,4]]] [4,0,[[3,4],[2,4]]]
これをtiny_graph.txtに保存し、ローカルフォルダーのHDFSに配置します。
hdfs dfs -put ./tiny_graph.txt ./
このコマンドを使用すると、ファイルはローカルディレクトリに移動します。 これを確認するには、ファイルの内容を表示します。
hdfs dfs -text tiny_graph.txt
さて、すべてがクールです、そして今始めましょう:
hadoop jar \ giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar \ org.apache.giraph.GiraphRunner \ org.apache.giraph.examples.SimpleShortestPathsComputation \ -vif org.apache.giraph.io.formats.JsonLongDoubleFloatDoubleVertexInputFormat \ -vip tiny_graph.txt \ -vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \ -op shortestpaths \ -w 1
ここに何が書かれているか見てみましょう:
-
hadoop jar giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar
コマンドのこの部分はKhadupにjarファイルを実行するよう指示します。 -
org.apache.giraph.GiraphRunner
ランナーの名前。 ここではデフォルトが使用されます。 ラーナーは再定義できます。 そのため、たとえば、起動時に古いデータを削除したり、他の準備アクションを実行したりします。 詳細については、Practical Graph Analytics with Apache Giraphの本を参照してください。 -
org.apache.giraph.examples.SimpleShortestPathsComputation
実行される計算メソッドを含むクラス。 -
-vif
は、頂点を持つ入力ファイルを読み取るクラスを定義します。 このクラスは入力ファイルの形式に応じて選択され、異なる場合があります;必要に応じてオーバーライドすることもできます(Apache Giraphを使用した実用的なグラフ分析を参照)。 標準クラスの説明はここにあります。 -
-vip
頂点の説明を含む入力ファイルへのパス。 -
-vof
作業結果が保存される形式。 必要に応じて、再定義します;標準クラスの説明はこちらをご覧ください 。 -
-op
保存先。 -
-w
ワーカー(グラフを垂直に処理するプロセス)の数。
コンソールに入力することで、起動オプションの詳細を確認できます。
hadoop jar \ giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar \ org.apache.giraph.GiraphRunner \ org.apache.giraph.examples.SimpleShortestPathsComputation -h
開始後、次のようにして最短経路で結果を読み取ることができます
hdfs dfs -text shortestpaths/*
3.独自のプロジェクトを作成する
次に、無向グラフの頂点の度合いを計算するアプリケーションを作成しましょう。 新しいMavenプロジェクトを作成しています。 これを行う方法は、たとえばここに書かれています 。 プロジェクトのルートはpom.xmlで、次のように入力します。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>ru.simple.giraph.project.org</groupId> <artifactId>simple-giraph-project</artifactId> <version>1.0-SNAPSHOT</version> <repositories> <repository> <id>cloudera</id> <url> https://repository.cloudera.com/artifactory/cloudera-repos/ </url> </repository> </repositories> <properties> <org.apache.hadoop.version>2.6.0-cdh5.5.1</org.apache.hadoop.version> </properties> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <version>2.4</version> <configuration> <finalName>simple-giraph-project</finalName> <descriptor> ${project.basedir}/src/main/assembly/single-jar.xml </descriptor> </configuration> <executions> <execution> <goals> <goal>single</goal> </goals> <phase>package</phase> </execution> </executions> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${org.apache.hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${org.apache.hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.giraph</groupId> <artifactId>giraph-core</artifactId> <version>1.1.0-hadoop2</version> </dependency> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>19.0</version> </dependency> </dependencies> </project>
pomファイルの作成方法とMavenの操作方法については、 こちらの公式ガイドをご覧ください 。 その後、srcで、新しいComputationDegree.javaファイルを作成します。 これは、頂点の度合いを考慮したクラスになります。
/** * This is a simple implementation of vertex degree computation. */ package ru.simple.giraph.project.org; import com.google.common.collect.Iterables; import org.apache.giraph.graph.BasicComputation; import org.apache.giraph.graph.Vertex; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import java.io.IOException; public class ComputeDegree extends BasicComputation<IntWritable, IntWritable, NullWritable, Text> { public void compute(Vertex<IntWritable, IntWritable, NullWritable> vertex, Iterable<Text> iterable) throws IOException { if (getSuperstep() == 0){ sendMessageToAllEdges(vertex, new Text()); } else if (getSuperstep() == 1){ Integer degree = Iterables.size(vertex.getEdges()); vertex.setValue(new IntWritable(degree)); }else{ vertex.voteToHalt(); } } }
次のように機能します。
- 最初のステップでは、各頂点がメッセージを近隣に送信します。
- 各頂点は着信メッセージの数をカウントし、それらを頂点値に保存します。
- すべての頂点は、コンピューティングを停止するよう投票します。
出力には、頂点の値に頂点の次数を格納するグラフがあります。 次のコマンドでコンパイルします。
mvn package -fae -DskipTests clean install
通常、コンパイル後、ターゲットフォルダーが作成されます。このフォルダーにはgiraph-test-fatjar.jarファイルがあります。 このファイルを実行します。 たとえば次のような非常に単純なグラフをご覧ください。
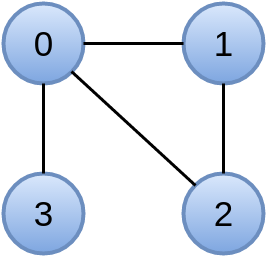
入力データ形式としてorg.apache.giraph.io.formats.IntIntNullTextVertexInputFormatを使用するため、グラフを記述するファイルは次のようになります。
0 0 1 2 3 1 0 0 2 2 0 0 1 3 0 0
example_graph.txtファイルに保存し、HDFSに配置してプログラムを実行します。
hadoop jar ./target/giraph-test-fatjar.jar org.apache.giraph.GiraphRunner \ ru.giraph.test.org.ComputeDegree \ -vif org.apache.giraph.io.formats.IntIntNullTextVertexInputFormat \ -vip example_graph.txt \ -vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \ -op degrees \ -w 1
結果を見てみましょう:
hdfs dfs -text degrees/*
そして、次のようなものが表示されます。
0 3 2 2 1 2 3 1
そのため、この記事ではGiraphのコンパイル方法を学び、独自の小さなアプリケーションを作成しました。 そして、プロジェクト全体はこちらからダウンロードできます 。
次の記事では、制限付きボルツマン機械学習アルゴリズムの例を使用して、Giraphでの作業について説明します。 Giraphセットアップの複雑さを理解し、このシステムがどれほど便利で効率的であるかを評価するために、可能な限りアルゴリズムを高速化しようとします。