ハイパフォーマンスコンピューティング(HPC、ハイパフォーマンスコンピューティング)、スーパーコンピューター、または1つまたは2つのマルチコアプロセッサ上に構築されたシステム-これらは並列計算です。 アルゴリズムを、同時に処理できるブロックに分割できる場合、並列環境で効率的に実行できることを意味します。 ただし、これが重要であるだけでなく、プロセッサで使用可能なメモリの個々のタイプのレベルでデータを操作する機能などを考慮して、コードの最適化を忘れないでください。 特に、キャッシュメモリを使用した効率的な作業について話します。

すべてが等しい場合、キャッシュ機能を最もよく考慮する並列化アルゴリズムは、他のアルゴリズムよりも高速に実行されます。 そして、当然、コンピューティング速度について話すと、命令およびプロセッサアーキテクチャのレベルで特定のプラットフォームの機能を最も完全に使用するコードが役立ちます。 そのようなコードを準備するための特別なソフトウェアパッケージがあります。 それらの1つはYASKです。
YASKとは
YASKまたはYet Another Stencil Kernelは、スクリーン印刷を使用するアプリケーションを開発するための一連のツールであり、HPCコンピューティングコアの研究と設計およびその最適化を促進するように設計されています。 YASKは、ベクトル畳み込み、ループをブロックに分割してキャッシュの使用率を上げる、メモリ内のデータの配置を制御する、ループの構造を調整する、計算波のブロックを一時的に分割するなどの手法を採用しています。
YASKには、通常のC ++ステンシルプログラムをSIMDに最適化されたコードに変換する専用のトランスレーターが含まれています。
ここでは、Intel Xeon PhiおよびIntel Xeonプロセッサのコアのチューニングについて説明します。 つまり、このような設定により、Xeon PhiのコードをIntel Xeonの2.8倍まで高速に動作させることができます。
Intel Xeon Phiのパフォーマンス上の利点は、メモリサブシステムの帯域幅が広く、512ビットのSIMD命令に起因している可能性があります。
スクリーンコンピューティングについて
高性能コンピューティングの非常に重要な領域は、時間と空間のデータ値を操作するためのスクリーンコンピューティングの使用です。 たとえば、典型的な3次元反復ステレオタイプヤコビアルゴリズムのコアは、3次元グリッド内のポイントをバイパスする次の擬似コードで示すことができます。
for t = 1 to T do for i = 1 to Dx do for j = 1 to Dy do for k = 1 to Dz do u(t + 1, i, j, k) ← S(t, i, j, k) end for end for end for end for
ここで、Tは時間パラメーターのステップ数、Dx、Dy、およびDzは問題空間の次元、S(t、i、j、k)はスクリーン関数です。
非常に単純な1次元および2次元の画面計算の場合、最新のコンパイラーは多くの場合、データアクセスパターンを認識し、生成されたコードを最適化して、ベクターレジスターの機能を活用し、キャッシュラインの長さを考慮することができます。 しかし、共有メモリを使用するいくつかのコアを備えた最新のプロセッサで実行される予定のより複雑な計算では、ほとんどのコンパイラは最適なコードを生成するタスクに対処できません。
YASKは、ベクトルコンボリューションやループ構造最適化など、通常のコンパイラー最適化後に得られるコードよりも生産的なコードにつながる可能性がある、メモリ内のデータを分散するさまざまな方法をプログラマーが実験できるツールです。 現在、YASKは単一のOpenMP計算ノード内での最適化に重点を置いています。
典型的なYASKモデルは次のようになります。
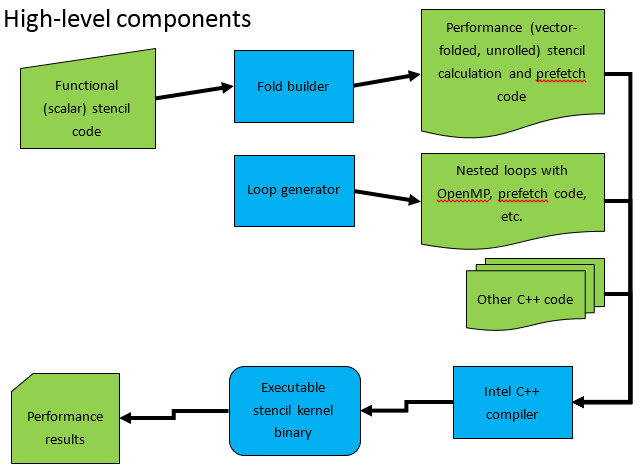
YASKとの仕事のハイレベルモデル
はじめに
YASKの使用に関する完全なガイドは、YASKのWebサイトにあります。 ここでは、Intel Xeon PhiおよびIntel XeonでのYASKジョブの構築と実行について説明しますが、まず、このツールキットで使用されるいくつかの最適化方法について説明します。
多次元ベクトル化
多次元ベクトル化、またはベクトルの畳み込みは、ベクトルレジスタをデータブロックで埋めるプロセスですが、ブロックは必ずしもソースデータ内で従う順序で配置されるとは限りません。 これは、データとキャッシュコンテンツの再利用を最適化するために必要です。 以下は、多次元ベクトル化とスクリーンコンピューティングでのその応用についてさらに学ぶことができる資料です。 ベクトルの手動畳み込みは、エラーを伴う難しい作業です。 一方、YASKは、操作の順次実行を提供する標準コードを新しいコードに変換するソフトウェアツールを提供します。これにより、コンパイル後に、より高速で効率的な計算が可能になります。
ループ構造の微調整
ベクトルの畳み込みと組み合わせて、ループ実行に複数のスレッドを使用すると、計算パフォーマンスがさらに向上します。 プログラマーがOpenMPツールを使用してループの構造を実験できるようにするYASKは、コードを最適化する別の方法、ループ最適化を提供します。
ループを設定するには、主に3つのアプローチがあります。
- 「ランク」-タスクはOpenMPの領域に分割されます。
- 「領域」-OpenMPエリアはキャッシュブロックに分割されます。
- 「ブロック」-キャッシュブロック内のベクトルクラスターごとに通路が作成されます。
コンピューティングパフォーマンスの研究
ここでは、Intel XeonおよびIntel Xeon PhiプロセッサでYASKコアを組み立てて起動する2つの例を見ていきます。
Intel Xeonシステムは、ターボモードが有効なデュアルソケットIntel Xeon E5-2697 v4 2.3 GHzプロセッサを使用します。 ソケットごとに18個のコアがあり、システムには合計36個のコアがあります(72スレッド、HTモードが有効)。 テストプラットフォームには、128 GBのDDR4メモリ(2400 MHz)が搭載され、Red Hat Enterprise Linux Server 7.2を実行しています。
Intel Xeon Phiシステムは、Intel Xeon Phi 7250プロセッサ(68コア、272スレッド)を使用します。 コア周波数は1400 MHz、プロセッサー補助システムの周波数は1700 MHzです。 16 GBのMCDRAM、7.2 GT / sがあります(フラットモードが使用されます)。 システムには96 GBのDDR4メモリ(2400 MHz)があり、クアッドクラスターモードが使用されます。 BIOSバージョン-86B.0010.R00、インストール済みOS-Red Hat Enterprise Linux Server 6.7。
以下で説明するコード、アセンブリ、および起動手順は、ここからダウンロードできます 。
AWP-ODCタスク
YASKに含まれるコンピューティングステンシルコアの1つはawp-odcです。 ここでは、ノードの二重システムを持つグリッドが使用され、カーネルは、弾性理論の3次元動的方程式の近似解に使用される有限差分法を実装します。 このコアを使用するアプリケーションは、地震の影響をモデル化するため、危険な構造物の設計に役立ちます。 タスクスペースは、1024 * 384 * 768のグリッドノードで構成されます。 Intel Xeon Phi 7250プロセッサを使用してこの問題を解決すると、Intel Xeon E5-2697 v4プロセッサと比較して最大2.8倍のパフォーマンス向上が得られます。
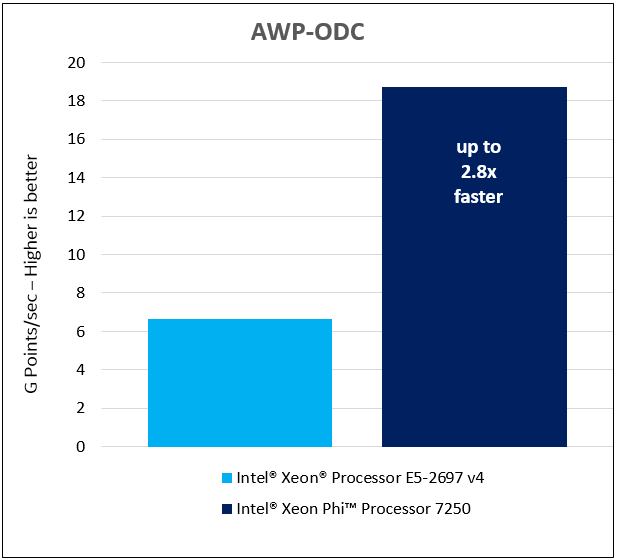
AWP-ODCテスト結果
このテストの実行方法は次のとおりです。
Intel Xeonシステムでは、次のコマンドを実行する必要があります。
make stencil=awp arch=hsw cluster=x=2,y=2,z=2 fold=y=8 omp_schedule=guided mpi=1 ./stencil-run.sh -arch hsw -ranks 2 -bx 74 -by 192 -bz 20 -pz 2 -dx 512 -dy 384 -dz 768
Intel Xeon Phiシステムでは、これは次のように行われます。
make stencil=awp arch=knl INNER_BLOCK_LOOP_OPTS='prefetch(L1,L2)' ./stencil-run.sh -arch knl -bx 128 -by 32 -bz 32 -dx 1024 -dy 384 -dz 768
ISO3DFDタスク
YASKに含まれる別のステンシルコアはiso3dfdです。 空間での16次の離散化と時間での2次の離散化の音響等方性波動方程式の解を扱います。 同様の計算は、地震会社が油田やガス田を検索するために使用する地震イメージングアプリケーションで使用されます。 タスクスペースは、1536 * 1024 * 768のグリッドノードで構成されます。 Intel Xeon Phi 7250プロセッサをこのタスクに適用すると、Intel Xeon E5-2697 v4と比較してパフォーマンスが最大2.6倍向上します。

ISO3DFDタスクのテスト結果
これがこのテストの実施方法です。
Intel Xeonベースのシステムは、次のコマンドを使用します。
make stencil=iso3dfd arch=hsw mpi=1 ./stencil-run.sh -arch hsw -ranks 2 -bx 256 -by 64 -bz 64 -dx 768 -dy 1024 -dz 768
Intel Xeon Phiを搭載したプラットフォームでは、次のコマンドシーケンスが使用されます。
make stencil=iso3dfd arch=knl ./stencil-run.sh -arch knl -bx 192 -by 96 -bz 96 -dx 1536 -dy 1024 -dz 768
まとめ
高性能コンピューティングは、いくつかの要素を組み合わせることで最高の結果を達成できる分野です。 それらの中には、アルゴリズムの正しい選択、それらの最適化、計算のための強力な最新プラットフォームの使用があります。
YASKツールキットとIntel Xeon Phi 7250プロセッサは、複雑な実用的な問題を迅速に解決するために必要なすべてを科学とビジネスに提供できます。