何年も前にPerlからJavaScriptに切り替えた後、Unicodeがサポートされていないために、新しい言語で劣等感がありました。 JavaScriptがこの方向に大きく飛躍してきた間(ES5からES6に切り替えるとき)、ブックマークにいくつかの良い記事が残っています。
すべてのソフトウェア開発者が絶対的かつ積極的にユニコードと文字セットについて知っておくべき絶対的な最低限(言い訳はありません!)
JavaScriptにはUnicodeの問題があります
ECMAScript 6のUnicode対応正規表現
ES6文字列(およびUnicode)の詳細
彼らの最後は、新しい演算子を使用してユニコードを念頭に置いて文字列を文字に分割するためのレシピを提供しました
...
たとえば(Habrovskyパーサーは何らかの理由でこの例をコードで紹介せず、BMPの上の文字を非表示にします):

そして昨日、新しい正規表現の助けを借りて同じことが実現できるかどうか疑問に思いました。 簡単なアイデアが思い浮かびましたが、それは本当でした。
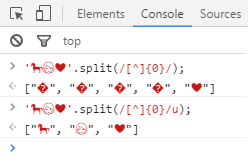
今日、私は突然、昨日がダライラマの誕生日であることに気付きました。 したがって、このメモはその機会のヒーローを称えてJavaScriptでの小さな冗談で完成できるように思えました。
const nothingness = /[^]{0}/; const nothing = ''; console.log(nothing.search(nothingness)); // 0 console.log(nothing.match(nothingness)); // [ '', index: 0, input: '' ] console.log(nothing.split(nothingness)); // [] console.log(nothing.replace(nothingness, nothing)); // '' console.log(nothingness.test(nothing)); // true

PS私は速度で両方の方法を比較しようとしました:
1. Node.js
/******************************************************************************/ 'use strict'; /******************************************************************************/ const str = '\ud83d\udc0e'.repeat(1000); const re = /[^]{0}/u; let symbols; let hrStart; let hrEnd; let i; /******************************************************************************/ hrStart = process.hrtime(); i = 100000; while (i-- > 0) symbols = [...str]; hrEnd = process.hrtime(hrStart); console.log( `${symbols.length} symbols via spread: ${(hrEnd[0] * 1e9 + hrEnd[1]) / 1e9} s` ); /******************************************************************************/ hrStart = process.hrtime(); i = 100000; while (i-- > 0) symbols = str.split(re); hrEnd = process.hrtime(hrStart); console.log( `${symbols.length} symbols via regexp: ${(hrEnd[0] * 1e9 + hrEnd[1]) / 1e9} s` ); /******************************************************************************/
2.ブラウザ
/******************************************************************************/ 'use strict'; /******************************************************************************/ const str = '\ud83d\udc0e'.repeat(1000); const re = /[^]{0}/u; let symbols; let pStart; let i; /******************************************************************************/ pStart = performance.now(); i = 100000; while (i-- > 0) symbols = [...str]; console.log( `${symbols.length} symbols via spread: ${(performance.now() - pStart) / 1e3} s` ); /******************************************************************************/ pStart = performance.now(); i = 100000; while (i-- > 0) symbols = str.split(re); console.log( `${symbols.length} symbols via regexp: ${(performance.now() - pStart) / 1e3} s` ); /******************************************************************************/
Node.js 6.3.0
1000 symbols via spread: 28.284130503 s
1000 symbols via regexp: 14.887705856 s
Google Chrome Canary 54.0.2790.0
1000 symbols via spread: 36.575210000000006 s
1000 symbols via regexp: 15.550919999999998 s
Firefox Nightly 50.0a1
1000 symbols via spread: 20.392635000000002 s
1000 symbols via regexp: 26.935885000000003 s
V8では、正規表現が勝ち(2回以上)、SpiderMonkeyでは、スプレッド演算子が勝ちます(それほどではありません)。
PPS
/[^]{0}/u
代わりに、
new RegExp('', 'u')
使用できます