臨床文書アーキテクチャ(CDA)とは何ですか?別の投稿-habrahabr.ru/post/255879でも簡単に説明しました
CDAの「完全な」説明には、ページボリューム300の書籍全体が必要であり、既存の書籍の1つは「 The CDA Book 」と呼ばれます。 したがって、この標準のすべての機能について説明する方法はありません。
Clinical Document ArchitectureはHL7v3標準の20ドメインの1つであることを思い出させてください。 v3に精通しており、ほとんどの読者がそれが何であるかを少し知っていることを望んでいるなら、このバージョンではすべてのアーティファクトがHL7参照情報モデル (RIM)に基づいていることがわかります。
さらに説明を明確にするために、HL7v3でモデルがどのように構築されるかを見てみましょう。 次のようなRIMから始めます。
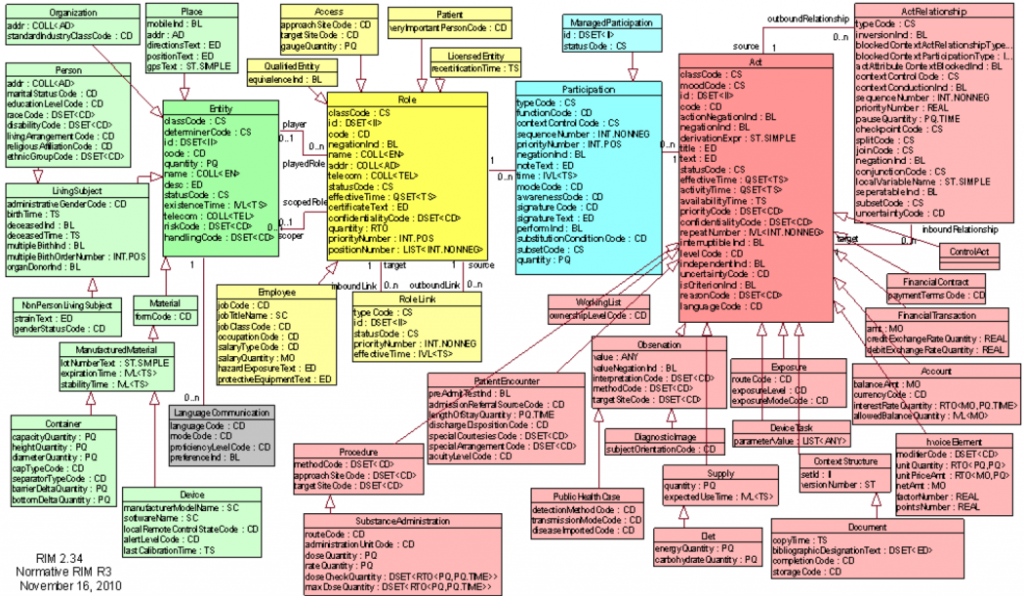
RIMがEntity 、 Role 、 Participation、およびActの 4つの基本クラスと、関係を記述するための2つの追加クラス: Role LinkおよびAct Relationshipに基づいていることに気付くのは難しくありません。 少なくとも一度ソフトウェア開発に出会った人のための「クラス」の概念は、おそらくRIMのオブジェクト指向構造を示唆しており、これはほぼ間違いないでしょう。 なぜなら、RIMはOOPの継承の基本原則に従っているためです。 標準は明示的に次のように述べています:
- 汎化 -下位クラスに親クラスのすべてのプロパティが含まれる場合。
- 特殊化 —後継クラスは、親の機能の一部をオーバーライドし、さらに特殊化するための追加のプロパティも定義します。
しかし、さらなる矛盾が始まります。 HL7v3は必要なメッセージを取得するために、 洗練プロセスを使用します。これにより、 ドメインの複数のドメインメッセージ情報モデル (D-MIM)と、それぞれの洗練されたメッセージ情報モデル (R-MIM)のセットが作成されます。 R-MIMの同じルールに従って、最終的な階層メッセージ記述 (HMD)が取得され、そこからメッセージが作成されます。
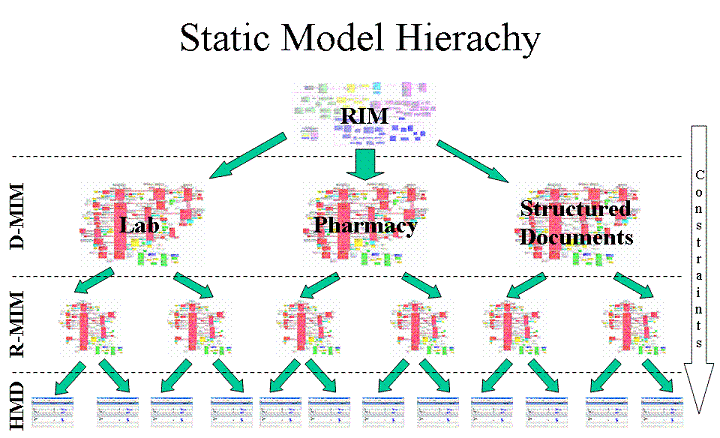
洗練プロセスは、 制約プロセスとローカリゼーションプロセスに基づいています 。 名前が示すように、制限プロセスはクラスのさらなる拡張または再定義を意味しません。逆に、子孫クラスは親クラスのプロパティのすべてまたは一部を含むことができますが、それ以上はできません。 ローカリゼーションプロセスでは、一部のモデルがビジネス要件に完全に準拠しておらず、補足する必要があると想定しています。 このような追加は、将来的に拡張機能(拡張機能)の形で実装されることが最も多く、モデルの一部になる可能性があります。 拡張機能が必要な場合は、ビジネスプロセスを誤って解釈している可能性が高いと聞くのが一般的です。
HL7v3モデルの実装プロセスについて少し理解したので、CDA、つまりCDA R-MIMに戻り、ドキュメントの本文を説明する部分に戻りましょう。
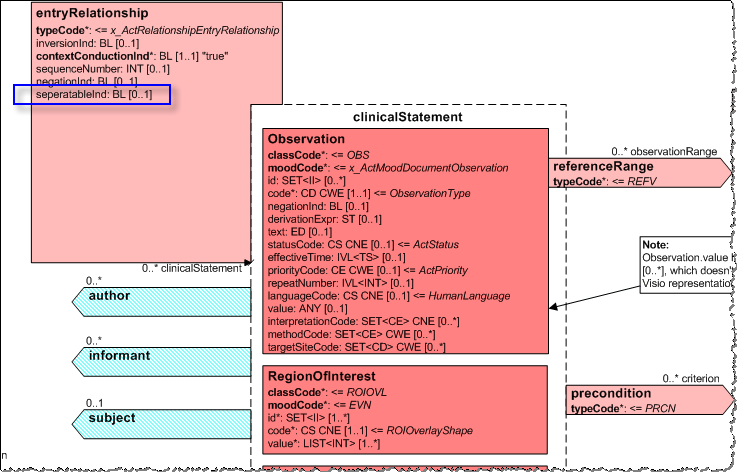
ClinicalStatementで選択するすべてのクラスは、 Actクラスを継承します。 たとえば、特定の観察クラスの場合、主な説明は「 ユニバーサルドメイン -> 臨床ドキュメントアーキテクチャ」セクションでは見つかりませんが(ここでも意味はありますが、このクラスの使用に関する追加機能について学習します)、「 基礎」 ->「 参照情報モデル」 -> クラス -> 観察 。

entryRelationshipについても同様です。 Clinical Document Architectureドメイン自体の説明のみを使用する場合、「 CDAはさまざまなリンクおよび参照シナリオを識別およびモデル化した 」こと、およびentryRelationship.inversionIndおよびentryRelationship.contextConductionIndを使用する機能を理解 できます。
ただし、ご覧のとおり 、 entryRelationshipは親クラスであるActRelationshipから他の属性を継承します。 ActRelationship.seperatableIndを含みます 。これは、デフォルトで「true」であり、「 ソースActがターゲットActとは独立して解釈されることを示すために使用されます」 ターゲット法から分離されている場合、ソース法の内容を証明する著者の希望と意欲を示します。 「(ソースHL7 NE)
したがって、CDAセクションテンプレートがentryRelationshipを使用して臨床状態を説明する可能性が最も高い場合、たとえば、アレルギー反応のタイプ-アレルギー剤-アレルゲン-発現の程度、 ActRelationship.seperatableInd =デフォルトではtrue 、その後継承法により、説明は互いに独立しています。 つまり、アレルゲンはドキュメント内に単独で存在し、誰とも接続されておらず、誰も定義していません。 「顕在化の程度」と同様に、どの条件が不明確で、それ自体に何が存在するかは不明です。
目標が「 (観察の内部クラスの)ターゲットが(行為の外部クラスの)ソース行為の知識なしで単独で立つことができない場合、このクラス属性は「false 」に設定する必要があります 。」 (ソース「The CDA Book」、括弧内に追加)
つまり すべての添付ファイルが元々それらに置かれていた意味を持っているように、それぞれの場合、明示的な形式でentryRelationship.seperatableInd = falseがなければなりません。
ただし、実際のCDA文書またはCDA文書テンプレートでこの属性を使用する少なくとも1つの例を見つけることはほとんどできません。
どうする?
永遠の質問。 ほとんどありません。 HL7がモデルまたはHL7v3 Normative Editionの次のバージョンのいずれかの説明を修正するまで待機します。この属性はデフォルトでfalseになります。
または、XMLスキーマPOCD_MT000040.EntryRelationshipでこのような修正を行うことができます。
または、デフォルトでこの属性が常にfalseであることを示す1行を仕様に追加します。
更新:誰かがマイナスであることを嬉しく思います。 しかし、あなたがマイナスであるという事実から、これは、CDA適合性テストに関連する他の多くの問題と同様に、消えません。
Update2:また、C-CDA R2.1では、XMLスキーマで次のように表されるCD.qualifier要素を使用する必要がある場合があります(SHALL)。
<xs:要素名= "修飾子"タイプ= "CR" minOccurs = "0" maxOccurs = "0" />