前の部分はhttps://habrahabr.ru/post/302242/です。
ResNets(Residual Networks)が登場したため、2015年にInception-v3がImagenet Recognition Challangeに勝たなかったという事実に落ち着きました。
一般的なResNetとは何ですか?

免責事項:投稿はclosedcircles.comの編集されたチャットログに基づいて書かれているため、プレゼンテーションスタイルと明確な質問です。
これは、非常に深いネットワークのトレーニングの問題に関するMicrosoft Research Asiaの人々の作業の結果です( http://arxiv.org/abs/1512.03385 )。
VGGのレベルの数を愚かに増加させると、トレーニングセットと検証の両方の精度の点で、彼はますますトレーニングを開始することが知られています。
ある意味で奇妙です-より深いネットワークは、厳密に大きな表現力を持っています。
そして、一般的に言えば、より深いモデルを取得するのは簡単です。これは、より深いモデルよりも悪くなく、愚かにもいくつかのアイデンティティ層、つまり、信号を変更せずに単に渡すレベルを追加します。 ただし、深いモデルは、このような精度まで通常の方法でトレーニングすることはできません。
ここでは、常にアイデンティティよりも悪いことはできないという観察結果があり、ResNetsの主なアイデアがあります。
問題を定式化して、より深いレベルが前のトレーナーとターゲットが与えるものの差を予測するようにします。つまり、彼らは常に重みを0に移動し、信号をスキップします。
したがって、名前-Deep Residual Learning、つまり、過去のレールからの逸脱を予測することを学んでいます。
具体的には、次のようになります。
ネットワークの主要な構成要素は次の設計です。
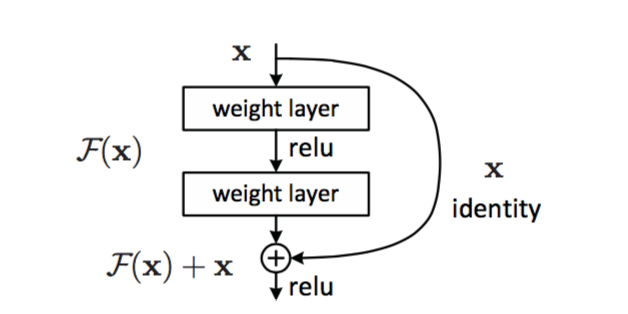
重さのある2つの層(畳み込みの場合がありますが、そうでない場合があります)、およびショートカット接続(これはバカなIDです)。 2つのレールがこのIDに追加された後の結果。 なぜすべてのレベルではなく、すべてのレベルですか? 説明はありませんが、実際には明らかにこのように機能しました。
したがって、特定のレベルのスケールで常に0が存在する場合、クリーンな信号を単にスキップします。
そして今、彼らは最初に34個のレールを備えたバージョンのVGGを構築します。このバージョンでは、そのようなブロックが挿入され、パラメーターの数が増えないようにすべてのレールが小さくなります。
彼はよく訓練され、VGGよりも良い結果を示していることがわかりました!
成功を収める方法は?
モアーレイヤー!!!
より多くのレールを取得するには、それらをより簡単にする必要があります。たとえば、1つおよびより薄い厚さを作成するために、2つの畳み込みの代わりにアイデアがあります。
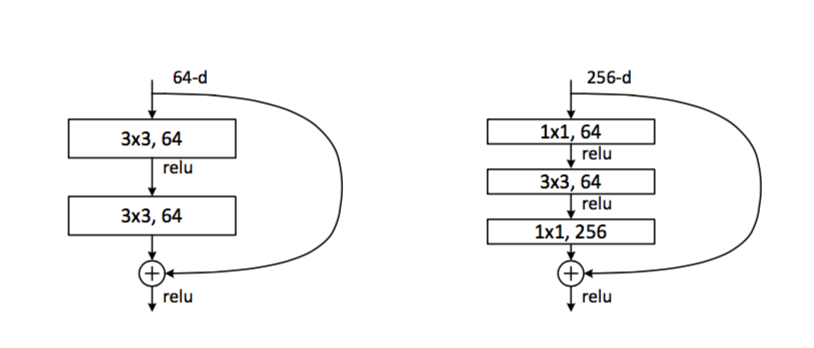
左のようでした。右でやってみましょう。 計算とパラメーターの数が大幅に減少します。
そして、ここで少年たちは悲鳴を上げ始め、101と152(!)レアーのバージョンを訓練し始めます。 さらに、このような非常に深いネットワークでさえ、VGGのシックバージョンよりもパラメーターが少ない。
先に述べたように、アンサンブルの最終結果は、Imagenetで3.57%top5です。
非常に深いネットワークでは勾配の消失の問題が深刻であり、Residualアーキテクチャによりそれを何らかの方法で解決できるという主な考えはありませんでしたか?
これはいい質問です!
ResNetsの作成者はこの問題を最大限に調査し、勾配の消失の問題は合理的な初期化とバッチ正規化によって十分に解決されているようです。 彼らは下層に落ちるグラデーションの大きさを見て、それは一般的に合理的でフェードしません。
彼らの理論では、より深いメッシュは、トレーニングプロセスで指数関数的に遅く収束するだけであるため、同じコンピューティングリソースで同じ精度を待つ時間はありません。
質問-バックプロパゲーションc IDリンクはどのように機能しますか?
通常の導関数であるユニットを渡します。
それとは別に、フィールドではResNetsのメカニズムの活発な開発と議論があり、レイヤーの結果を算術演算と組み合わせることが良いアイデアであると言われなければなりません。
以下に例を示します。
http://torch.ch/blog/2016/02/04/resnets.html-Facebookの男性は、残りの接続を挿入する方が良い場所を模索しています。
https://arxiv.org/abs/1605.06431-ResNetはネストされたネットワークの巨大な集合体であるという理論。
https://arxiv.org/abs/1605.07146-ResNetsのアイデアを使用して、深いネットワークではなく、非常に広いネットワークをトレーニングします。 ちなみに、CIFAR-10の最高の結果は、価値があります。
https://arxiv.org/abs/1605.07648-純粋な形での残留接続なしで、層の出力間の演算を使用した深いネットワークの構築とトレーニングの試み。
さて、Googleの男性はこの世界を見て働き続けています。
結果はInception-v4およびInception-Resnet( http://arxiv.org/abs/1602.07261 )です
ResNetsに加えて、変更された主なものはTensorFlowの外観です。
この記事によると、TensorFlowの前は、Inceptionモデルは1台のマシンのメモリに収まらず、分散してトレーニングする必要があったため、最適化の可能性が制限されていました。 しかし今、あなたは創造性を抑えることができません。
(私は実際にこれがどのように起こったのか本当に理解していません、ここに推測の議論があります-https : //closedcircles.com/chat?circle=14 & msg= 6207386 )
このフレーズの後、少年たちは建築の変化の原因の説明をやめ、これらの写真でいっぱいの3ページを愚かに投稿します。
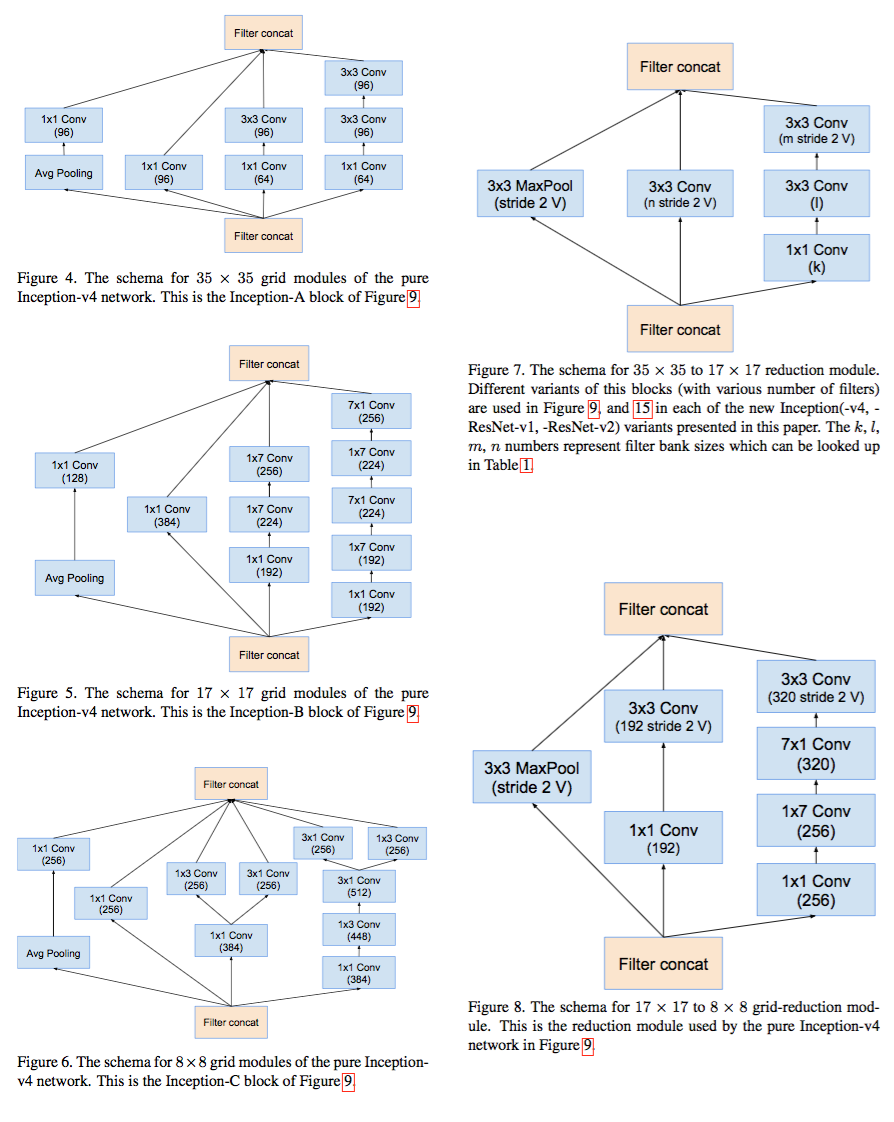
そして、建築の構築には多くの自動化が行われていると感じていますが、それらはまだ焼けていません。
一般に、それらには、Residual接続を持たないInception-v4と、同等の数のパラメーターを持っていますが、Residual接続を持っているInception-ResNet-2があります。 1つのモデルのレベルでは、結果は非常に近く、ResNetがわずかに勝ちます。
しかし、1つのv4と3つのResNet-2のアンサンブルは、Imagenetで新しい記録-3.08%を示しています。
過去のマイルストーンを思い出させてください。 Imagenet Recongitionチャレンジで優勝した最初のグリッドは、2012年に15%の誤差でそれを達成しました。2015年末には、合計で3.08%になりました。 平均的な人の結果の合理的な見積もりは、約5%です。 進歩は印象的です。
一般に、インセプションは、ディープラーニングの世界で適用されるR&Dの例です。
最初は、一連の畳み込み層とそれに続くいくつかの完全に接続された層を備えた非常にシンプルなアーキテクチャでしたが、効率のために毎年ますます巨大になっています。 そしておそらく、建築のマイクロソリューションのすべての詳細を理解している人が一人いるでしょう。 または、まだではありません。
すぐには見つからなかったInception-ResNetの完全なアーキテクチャの写真。 誰もそれを描くアイデアを持っていなかったようです。
完全なスキームは7ページの図15にありますが、すべてのレイヤーが完全にペイントされているわけではなく、単にブロックで示されています。 そうでなければ、紙だけに印刷する必要があると思いますが、それはあまり理解しません。
最終ブロックまで完全に正確であることを意味しました。 以前のバージョンでは、そのような写真を投稿しました。
その後、約3倍の幅で写真が撮れます:)
ダダ
残りの部分とは関係のない面白い詳細-パッドなしの畳み込み、つまり畳み込み層を作成し、画像のサイズを各側で2ピクセル縮小します。 実際にバイトを最適化してください!
奇妙なものを比較します。 5つの適切なカテゴリが選択された場合、人間の結果はtop1、コンピューターの結果はtop5です。 komputersのtop1では、結果はまだ2桁の領域にあります...
いいえ、人間もトップ5です。 imagenetのトップ1の男性も、何もすることはありません。
以下に例を示します-
この絵はどのクラスにありますか? たとえば、「馬」と「婦人服」というクラスがあります。
しかし、正しい答えはもちろん「干し草」です。
top1で頑張ってください。
もちろん。 干し草がたくさんあります。 とかろうじて馬を持つ女性!