要するに、プロジェクトは異なるサーバーにある複数のデータベースとアプリケーションで構成されています。 このプロジェクトの「タスク」は、ストアドプロシージャまたは.Netアプリケーションです。 したがって、「タスク」は特定のデータベースおよび特定のサーバーで実行する必要があります。

キューに関連するすべてのデータは専用サーバーに保存されます。 タスクを実行する必要があるサーバーでは、メタデータのみが保存されます。 このサーバーに関連する手順、機能、およびサービスデータ。 したがって、タスクに関連するデータは、LinkedServerを使用してクエリを受け取ります。
キューに関連するすべてのデータは専用サーバーに保存されます。 タスクを実行する必要があるサーバーでは、メタデータのみが保存されます。 このサーバーに関連する手順、機能、およびサービスデータ。 したがって、タスクに関連するデータは、LinkedServerを使用してクエリを受け取ります。
なぜそう
- 便利。 データがサーバーBに保存されたことをいつでも示すことができます。
- だから、それは私たちの前に実現しました。
以下は、最も一般的な2つの古典的なキュー処理方法です。
- タスクの存在に関する通知をタスクハンドラに送信します。
- タスクのキューをポーリングします。
最初に、プロジェクトは2番目のオプションを実装しました。 タスクの処理の遅延を最小限に抑えるために、アプリケーションは100〜500ミリ秒ごとにキューをポーリングします。
実際、これには何も問題はありませんが、1つだけ例外があります。この実装では、テーブルが再びブロックされます。 クエリでは、ロックされていない行のみを読み取ることができる行ロックを使用することを事前に説明します。
READPAST, ROWLOCK, UPDLOCK
それでは、問題に戻りましょう。 分析で、カウンターの値に気付きました-Active Monitorのバッチ要求/秒 。 キュー内のタスクの数が少ない(約50)この値は、1000のスケールから外れ、CPU負荷が急激に増加しました。
最初の考え:最初のオプションの実装に進む必要があります(タスクハンドラーに通知を送信する)。 このメソッドは、 Service BrokerとSignalRを使用して実装されました。
- Service Brokerは、タスクの外観に関する通知を送信するために使用されました。
- SignalRは、タスクハンドラーに通知を送信するために使用されました。
SignalRを選ぶ理由
このツールはすでにプロジェクトで使用されており、期限が厳しくなったため、たとえばNServiceBusなどの類似のものを実装しませんでした。
私の驚きは、この解決策が役に立たなかったときに限界がないことを知りました。 はい、生産性は向上しましたが、これでは問題は完全には解決しませんでした。 500個を超えるタスクがキューに追加されると、デバッグ用のストレステストが作成されました。
このようなストレステストの作成により、「 悪の根本 」を見つけることが可能になりました。
1つのコマンドで構成される「非常に興味深いクエリ」の存在を示す負荷が大きい場合の、アクティブなクエリとパフォーマンスレポートのリストの分析:
fetch api_cursor0000000000000003
さらに分析した結果、これらはLinkedServerからのクエリであることが明らかになりました。 「このタイプのクエリは、RemoteServer.RemoteDatabase.dbo.RemoteTableからselect * from FieldId = Valueで RemoteServerのリクエスト(fetch api_cursor0000000000000003)を生成しますか?」という質問がすぐに発生しました。
より具体的な例として、サーバー「A」でテーブル「Test」を作成し(テーブル作成コードは記事の付録で利用可能)、サーバー「B」でリクエストを実行します。
select * from dev2.test_db.dbo.test
ここで、 dev2はサーバー「A」です。
このような要求の最初の実行時に、サーバーAのプロファイラーに同様のログが記録されます。
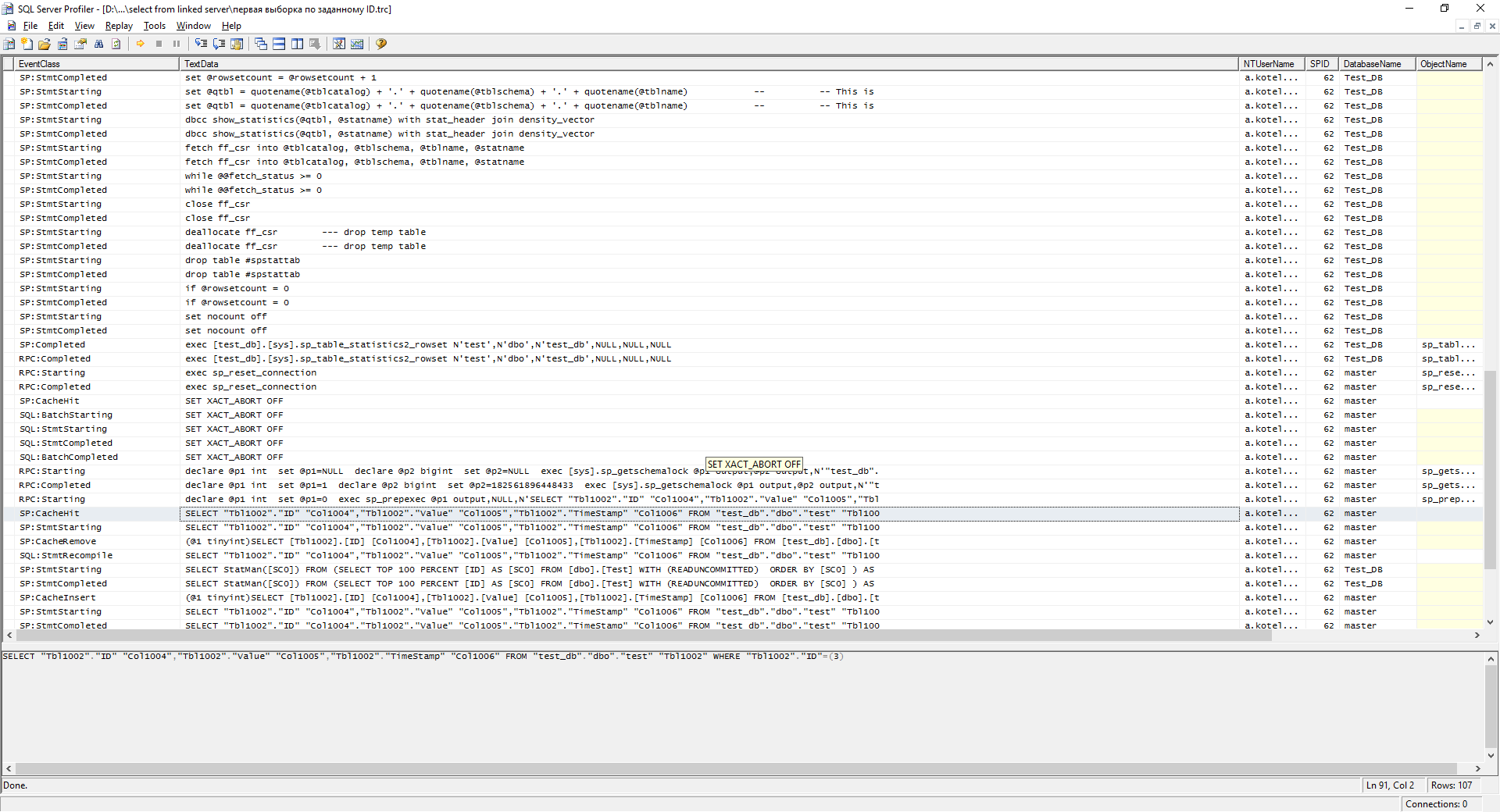
そして、IDでリクエストを実行します。
select * from dev2.test_db.dbo.test where ID = 3

スクリーンショットでわかるように、リクエストプランがキャッシュに追加されました。 このリクエストを2回実行すると、もう少し良くなります。
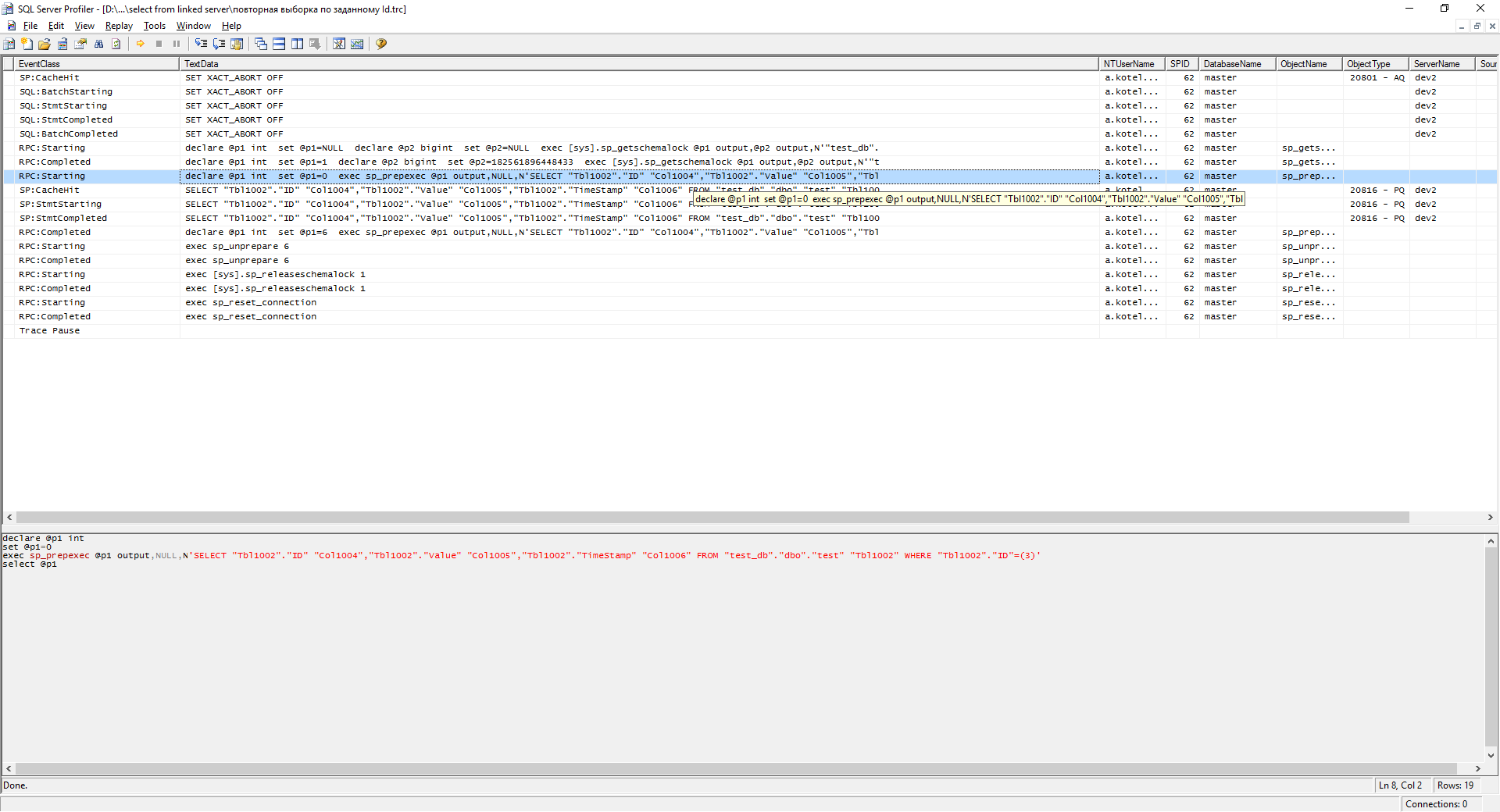
ご覧のとおり、データは既にキャッシュから取得されています。
条件が変更されると、同様のサンプル( 特定のIdの最初のサンプル)が取得されます。 しかし、要点は、多数の異なるリクエストでは、キャッシュが十分ではないということです。 そして、sqlはテーブルに対して大量のクエリを作成し始め、それが「ブレーキ」につながります。 「インデックスについてはどうですか?」と尋ねます。インデックスはありますが、プライマリキー(PK)条件でも、この問題は発生しました。
Googleはこれについて何と言っていますか? そして、多くのことですが、意味がありません:
- その要求は、統計を使用できるように、sysadmin、db_owner、db_ddladminのいずれかのロールに属するユーザーから実行する必要があります。
- LinkedServerが正しく構成されていません。
より賢明な答えは、3つの記事でのみ見つかりました。
私の知る限り、LinkedServerからデータを受信するために常にプルテクノロジーが使用されるようにLinkedServerを構成することはできません。 それはすべて、リクエストを処理している場所に依存します。
時間がなくなり、私たちを救うことができる唯一の解決策は、動的SQLのクエリの一部を書き換えることでした。 つまり データが保存されているサーバーでリクエストを実行します。
LinkedServerでデータを操作するには、いくつかの方法があります。
- リクエストでは、データソース(リモートサーバー)を直接指定します。 この実装には、いくつかの欠点があります。
- 低い生産性;
- 大量のデータを返します。
select * from RemoteServer.RemoteDatabase.dbo.RemoteTable where Id = @Id
- OPENQUERYを使用します。 いくつかの理由で不適:
- リモートサーバーの名前をパラメーターとして指定することはできません。
- リクエストにパラメーターを渡します。
- また、 ダイナミックT-SQLで説明されている問題と、それがどのように役立つかについても説明します。
select * from OPENQUERY(RemoteServer, 'select * from RemoteDatabase.dbo.RemoteTable').
リンクは、次のクエリのサンプルログです。 これらの要求はサーバー「B」で実行され、サーバー「A」からのログは次のとおりです。
select * from OPENQUERY(dev2, 'select * from test_db.dbo.test') where id = 26
select * from OPENQUERY(dev2, 'select * from test_db.dbo.test where ID = 26')
- リモートサーバーで要求を実行します。 OPENQUERYと同様:
- 名前はプロシージャのコンパイルの段階で指定されるため、サーバー名をパラメータとして指定することはできません。
- また、 ダイナミックT-SQLで説明されている問題と、それがどのように役立つかについても説明します。
exec ('select * from RemoteDatabase.dbo.RemoteTable') at RemoteServer
リンクは、次のクエリのサンプルログを提供します。
exec ('select * from test_db.dbo.test') at dev2
exec ('select * from test_db.dbo.test where Id = 30') at dev2
- sp_executesqlを実行することにより、リモートサーバーでリクエストを実行することは引き続き可能です。
DECLARE @C_SP_CMD nvarchar(50) = QUOTENAME(@RemoteServer) + N'.'+@RemoteDatabase +N'.sys.sp_executesql' DECLARE @C_SQL_CMD nvarchar(4000) = 'select * from dbo.RemoteTable' EXEC @C_SP_CMD @C_SQL_CMD
sp_executesqlを使用したクエリ実行ログの例は、リンクから入手できます。
- sp_executesql / client.trcでの完全フェッチ
- sp_executesql /完全なサーバー側フェッチ.trc
- sp.executesql / client.trcでのID選択
- sp.executesql / server.trcでのID選択
4番目の方法を使用して問題を解決しました。
以下は、sp_executesqlを使用する前と後のメインキューベースがあるサーバー上の着信および発信トラフィックのグラフです。 データベースのサイズは200〜300Mbです。
sp_executesqlを使用する前の、サーバーでの数日間の着信および発信トラフィック 
sp_executesqlの使用開始後の着信および発信トラフィック 
発信ピークは、バックアップをNFSにコピーしています。
結論はそれ自体を示唆しています。最初は、MS MSの「MS SQLリンクサーバー」を操作するためのドライバーは、データソースサーバーでリクエストを実行できません。 したがって、同僚は、パフォーマンスの問題の少なくとも一部を解決するために、データソースでそれらを実行してみましょう。
記事のファイル 。