一般的に、タスクはテキストの大きな配列からいくつかのエンティティを抽出することでした。 一方では、名前付きエンティティを抽出する従来のタスクとそれほど大きな問題ではありません。 しかし、エンティティの定義は通常のものとは異なり、テキストはかなり具体的であり、問題の解決期限は2週間でした。
入力データ
当時、ロシア語で名前付きエンティティのマークされたアクセス可能なケースはまったくありませんでした。 そして、もしそうなら、それらはまさにそれらのエンティティではないでしょう。 またはまったく間違ったエンティティ。 同様の解決策はありましたが、悪い(たとえば、「1年の仕事の後、裏表紙が壊れた」という文の「裏表紙」などの組織が見つかった)か非常に良いが、必要ではなかったことを強調しました(要件がありました)これらのエンティティの境界に関してどのエンティティを区別する必要があるか)。
はじめに
データには個別にラベルを付ける必要がありました。 トレーニングサンプルは、提供された特定のテキストから作成されました。 1週間かけて、1.5人の採掘者の努力により、必要なエンティティへの約9,000の参照を含む112,000ワードのサンプルをマークアウトすることができました。 検証サンプルでいくつかの分類子をトレーニングした後、次の結果を得ました。
| 方法 | F1 |
| CRF(基本機能セット) | 67.5 |
| エルマン双方向多層ネットワーク
| 68.5 |
| 双方向LSTM
| 74.5 |
内容が単純なエンティティの場合、これはあまり良くありません;同等のタスクでは、専門システムはしばしば90-94地域でF1を発行します(公開された作品による)。 ただし、100万を超える単語形式のサンプルでは、属性を慎重に選択する必要があります。
予備的な結果では、LSTMモデルは広いマージンで最高の結果を示しました。 しかし、私はそれを使用したくありませんでした。比較的遅いので、大量のテキストをリアルタイムで処理することは採算が取れません。 ラベルの付いたサンプルを受け取って、予備的な結果が出るまでに、1週間が残っていました。
1日目。 正則化
小さなサンプルのニューラルネットワークの主な問題は、再トレーニングです。 古典的には、適切なネットワークサイズを選択するか、特別な正則化方法を使用して、これに対処できます。
定数とドロップアウトのサイズを変更して、異なるレイヤーでサイズ設定、最大ノルム正則化を試みました。 私たちは赤目、頭痛、そして利益の数パーセントを得ました。
| 方法 | F1 |
| ネットワークサイズを最適化する
| 69.3 |
| 最大ノルム
| 71.1 |
| ドロップアウト
| 69.0 |
ドロップアウトは事実上私たちを助けませんでした。ネットワークはよりゆっくりと学習し、結果はあまり良くありません。 最大ノルムとネットワークのサイズ変更が最適であることが証明されました。 しかし、成長は、月に関して望ましい値と、やることができるすべてのものに対して、小さいです。
2日目。 整流線形
記事では、RelUアクティベーション機能の使用を推奨しています。 結果を改善することが書かれています。 RelUは、x> 0の場合、x else 0の場合、単純な関数です。
何も改善されていません。 それらを使用した最適化はまったく収束しないか、結果がひどいです。 理由を解明しようとして一日を過ごしました。 わからない。
3日目。 LSTMのようなモンスター
LSTMのように見せることはできますか? 少し考えた後、想像力がデザインを促しました(図1)。 繰り返しレイヤーの前に、1つのフィードフォワードレイヤーが追加され(ネットワークに入力する情報を入力する必要があります)、その上に出力を制御するための別の構造があります。
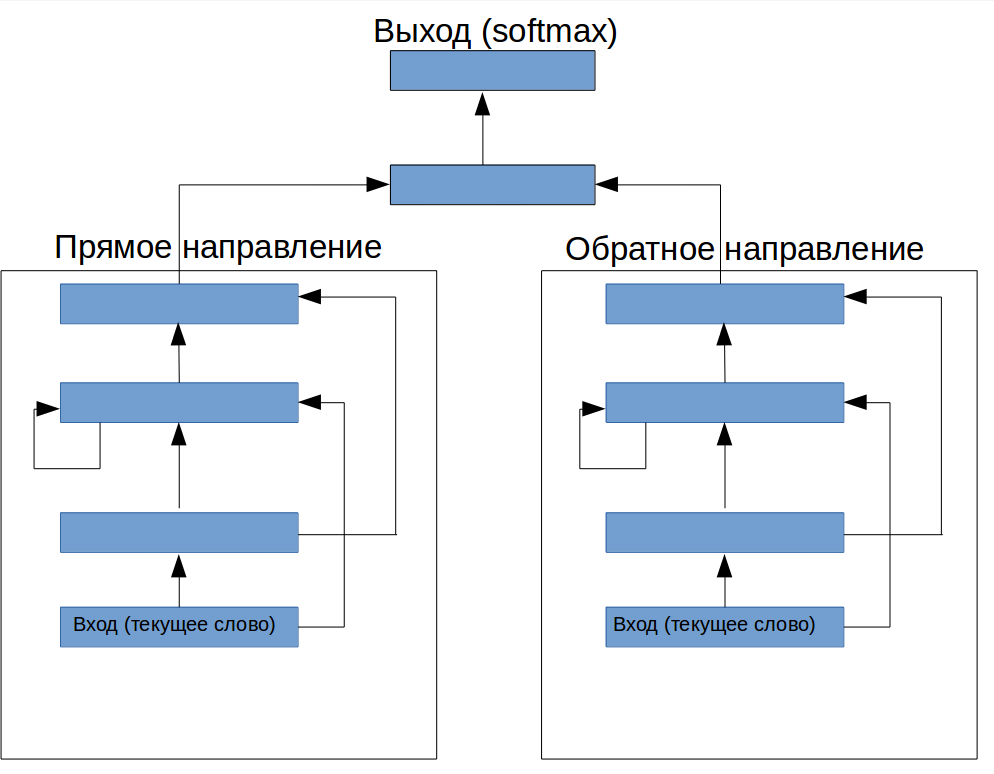
図1.テキストから用語を抽出する特別なニューラルネットワークのアーキテクチャ
奇妙なことに、適切なパラメータの選択により、この設計ではF1が72.2に増加しましたが、これは完全に架空のアーキテクチャにとっては悪くありません。
4日目。 RelUリターン
頑固さから、「モンスター」でRelUを試しました。 RelUがリカレントレイヤーにのみインストールされている場合、最適化は収束しないだけでなく、F1 73.8であることが判明しました。 そのような奇跡はどこから来たのでしょうか?
それを理解しましょう。 LSTMがうまく機能するのはなぜですか? これは通常、情報をより長く記憶できるため、より多くのコンテキストを「見る」ことができるという事実によって説明されます。 原則として、適切な学習アルゴリズムを使用すると、通常のRNNでも長いコンテキストを記憶するようにトレーニングできます。 しかし、シーケンスを入力ワードベクトルでマークアップするという問題に関して、通常のRNNはまず現在の期間と直近のコンテキストで依存関係を探し、トレーニングがこのコンテキストの意味のある分析の可能性に到達する前にそれらを再トレーニングします。 エルマンの通常のRNNでは、ネットワークの再トレーニング能力を大幅に高めることなく「メモリ容量」を構築することはできません。
新しいアーキテクチャの写真を見ると、ここに情報を保存するモジュールと「決定的な」モジュールがレイアウトされていることがわかります。 同時に、メモリモジュール自体は複雑な仮説を立てる機会を奪われているため、再トレーニングに大きく貢献することを恐れずに組み立てることができます。 これにより、特定のタスクの現在のウィンドウのメモリと情報の相対的な重要度を制御できました。
5日目。 対角要素
[1]で説明されている考え方に従って、他のニューロンを除くすべての再帰接続を再発層から除外し、各ニューロンの入力にそれ自体の以前の状態のみを残しました。 さらに、最上層も再帰的であることを追加しました(図2)。 これにより、F1 74.8が得られました。このタスクでは、LSTMを使用して最初に得られた結果よりも優れた結果が得られました。
6日目。 サンプルサイズ
1週間ずっとデータのラベル付けを続けていたため、この日、新しいダブルサイズのサンプルの使用に切り替えました。これにより、(新しい一連のハイパーパラメーターの選択後)F1 83.7を取得できました。 入手が容易な場合は、より大きなサンプルほど優れたものはありません。 確かに、タグ付きデータの量を2倍にすることは、通常、まったく簡単ではありません。 結果は次のとおりです。
| 方法 | F1 |
| CRF(基本機能セット) | 76.1 |
| エルマン双方向多層ネットワーク
| 77.8 |
| 双方向LSTM
| 83.2 |
| 私たちの建築
| 83.7 |
結論と類似体との比較
エンティティ自体と境界の定義が異なるため、認識システムを上記のWeb-APIの同様の実装と適切に比較することはできません。 私たちは小さなテストサンプルでいくつかの非常に大まかな分析を行い、すべてのシステムを同じ基盤にしようとしました。 バイナリオーバーラップメトリックを使用して、特別なルールに従って結果を手動で分析する必要がありました(システムが境界の不一致の問題を除去する場合、エンティティの定義が考慮されます。これにより、境界の不一致の問題が除去されます)。 起こったことは次のとおりです。
| 方法 | F1 |
| 私たちのシステム | 76.1 |
| アナログ#1
| 77.8 |
| アナログ#2
| 83.2 |
アナログ#2はこのメトリックでわずかな利点しかなく、アナログ#1はさらに悪いことが判明しました。 どちらのソリューションも、お客様から提供された説明を使用してタスクでテストすると、結果の質が低下します。
上記から、2つの結論を導き出しました。
1.名前付きエンティティを抽出するための明確に定義された解決済みのタスクでさえ、既製のシステムを使用できないサブオプションがあります。
2.ニューラルネットワークを使用すると、より複雑な開発とほぼ同じ品質範囲の特殊なソリューションをすばやく作成できます。
文学
1. T.ミコロフ、A。ジョウリン、S。チョプラ、M。マチュー、M。ランザート。 でより長い記憶を学ぶ
リカレントニューラルネットワーク