
データサイエンティストの間で最も人気のあるプログラミング言語の1つであるRは、オープンソースコミュニティと、従来プロプライエタリ製品の開発者であった民間企業の間で、ますます多くのサポートを得ています。 そのような企業の中にマイクロソフトがあり、その製品/サービスでのR言語のサポートが集中的に増えており、私が注目を集めています。
RとMicrosoft製品を統合するための「機関車」の1つは、Microsoft Azureクラウドプラットフォームです。 さらに、R + Azureバンドルを詳しく見る良い機会がありました。これは、今週末(5月21〜22日)に開催される機械学習ハッカソンです。
ハッカソン-イベント
Rは、プロトタイプの作成、データのマイニング、仮説の迅速なテストに最適です。つまり、
この種の競争に必要なものすべて! 以下では、プロトタイプ作成から完成したモデルのAzure Machine Learningでの発行まで、AzureでRの全機能を使用する方法を示します。
トピック外の動機付け
前のハッカソンと同様(はい、これはマイクロソフトの最初のMLハッカソンではありません)、お気に入りのPython / R / C#で自分でプログラムを作成し、Azure Machine Learningでペンをひねり、同じ考えを持つ人々や専門家とチャットし、十分な睡眠をとらず、無料で飲める機会がありますコーヒーと食べ過ぎのおいしいクッキー。 そして、最もcなものは世界をより良い場所にし、当然の賞品を受け取ります!
0.マイクロソフトはRを愛している
Rとの連携を可能にするマイクロソフト製品/サービスのリストをすぐに決定します。
- Azure HDInsightのMicrosoft R Server / Rサーバー
- データサイエンスVM
- Azure Machine Learning
- SQL Server Rサービス
- Power BI
- Visual StudioのRツール
そして、(ああ、うれしいです!)IaaS / PaaSモデルの下で、Azureで1〜3の製品を利用できます。 それらを順番に検討します。
1. Microsoft R Server(Azure HDInsightの場合)
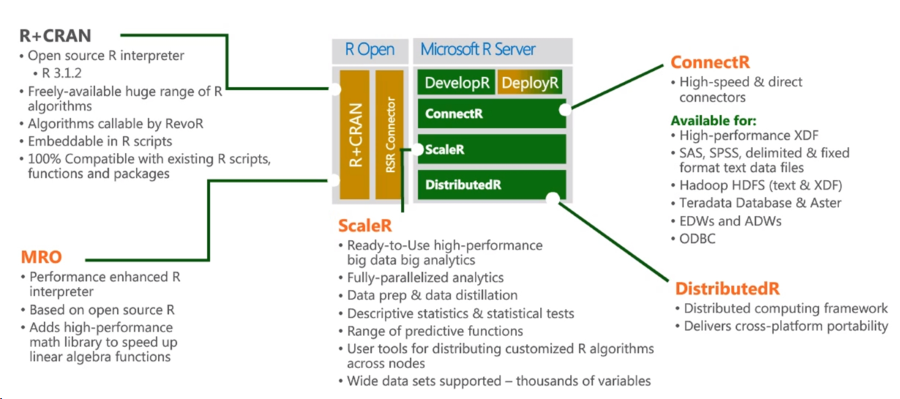
昨年の悪名高いRevolution Analyticsの購入後、Revolution R Open(RRO)およびRevolution R Enterprise(RRE)は、それぞれMicrosoft R Open(MRO)およびMicrosoft R Serverに名前が変更されました。 現在、 Microsoft R Serverは、オープンソース製品と独自のRevolution Analyticsモジュールの両方で構成される、しっかりと構築されたエコシステムです。
出所
R + CRANが中心となり、R言語との既存のパッケージとの互換性と100%の互換性が保証されます。 Rサーバーのもう1つの中心的なコンポーネントはMicrosoft R Openです。MicrosoftR Openは、マトリックスのパフォーマンスインジケーター、数学関数、およびマルチスレッドのサポートが改善されたランタイムです。
ConnectRモジュールを使用すると、Hadoop、Teradata Databaseなどに保存されているデータにアクセスできます。
Azure HDInsight用Rサーバーは、AzureクラウドのSparkクラスターでRスクリプトを直接実行する機能をすべてに追加します。 したがって、データがRスクリプトが実行されるマシンのRAMにローカルに収まらないという問題が解決されます。 指示書が添付されています。
Azure HDInsight自体は、オンデマンドでHadoop / Sparkクラスターを提供するクラウドサービスです。 これはサービスであるため、管理タスクはクラスターのデプロイと削除のみです。 それだけです! クラスター構成、更新プログラムのインストール、アクセスの構成などに費やされる時間の1秒ではありません。
8ノードのHadoopクラスター(HDI 3.3)の作成/削除 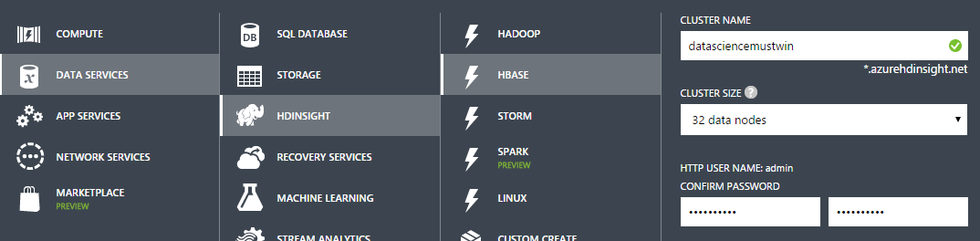
Sparkクラスターを作成するには、3つのボタン(上の画像)を選択するか、次の簡単なPowerShellスクリプト[ source ]を実行する必要があります。
Sparkクラスターを作成するには、3つのボタン(上の画像)を選択するか、次の簡単なPowerShellスクリプト[ source ]を実行する必要があります。
Login-AzureRmAccount # Set these variables $clusterName = $containerName # As a best practice, have the same name for the cluster and container $clusterNodes = 8 # The number of nodes in the HDInsight cluster $credentials = Get-Credential -Message "Enter Cluster user credentials" -UserName "admin" $sshCredentials = Get-Credential -Message "Enter SSH user credentials" # The location of the HDInsight cluster. It must be in the same data center as the Storage account. $location = Get-AzureRmStorageAccount -ResourceGroupName $resourceGroupName ` -StorageAccountName $storageAccountName | %{$_.Location} # Create a new HDInsight cluster New-AzureRmHDInsightCluster -ClusterName $clusterName ` -ResourceGroupName $resourceGroupName -HttpCredential $credentials ` -Location $location -DefaultStorageAccountName "$storageAccountName.blob.core.windows.net" ` -DefaultStorageAccountKey $storageAccountKey -DefaultStorageContainer $containerName ` -ClusterSizeInNodes $clusterNodes -ClusterType Hadoop ` -OSType Linux -Version "3.3" -SshCredential $sshCredentials
クラスターを削除するには、1つのボタンと1つの確認をクリックするか、PowerShellスクリプトの次の行を実行します。
Remove-AzureRmHDInsightCluster -ClusterName <Cluster Name>
2.データサイエンスVM
突然必要になった場合:32x CPU、448Gb RAM、〜0.5 TB SSD、プリインストールおよび構成済み:
- Microsoft R Server Developer Edition、
- Anaconda Pythonディストリビューション、
- PythonおよびR用のJupyterノートブック、
- PythonおよびRツールを備えたVisual Studio Community Edition、
- Power BIデスクトップ、
- SQL Server Expressエディション。
R、Python、C#で記述し、SQLを使用する場合。 そして彼らは、xgboost、Vowpal Wabbit、CNTK(Microsoft Researchのオープンソースの深層学習ライブラリ)に悩まされないことを決定しました。 次に、Data Science Virtual Machineが必要です。上記のすべての製品はプリインストールされており、すぐに使用できます。 展開は簡単ですが、 指示があります。
3. Azure Machine Learning
Azure Machine Learning (Azure ML)は、機械学習タスクを実行するためのクラウドサービスです。 ほぼ間違いなく、Azure MLが、Azureクラウドでモデルをトレーニングする場合に使用する中心的なサービスになります。
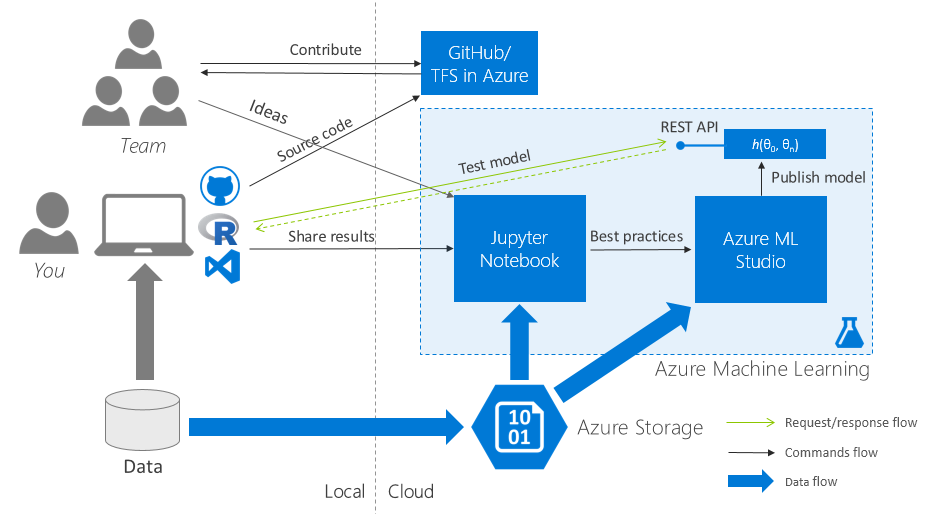
Azure MLについての詳細なストーリーは、特にこの記事の目標の一部ではありません。特に、 データサイエンティスト向けAzure ML、Azure MLの ベストプラクティストレーニングモデルなど 、サービスが十分に記述されているためです。 次のタスクに焦点を当てます。 ローカルコンピューターからAzure ML StudioにRスクリプトを最も簡単に転送するチーム作業の編成。
3.1。 初期要件
これには、次のフリーソフトウェア製品が必要です。
- 保守派の場合:R(実行時)、Rスタジオ(IDE)。
- 民主党の場合:R(ランタイム)、Microsoft R Open(ランタイム)、Visual Studio Community 2015(IDE)、R Tools for Visual Studio(IDE拡張機能)。
Azureで作業するには、アクティブなMicrosoft Azureサブスクリプションが必要です。
3.2。 はじめに:すべてのコラボレーション
Azure MLの1つのワークスペース
Azure MLのワークスペースチーム全体に対して1つ(!)を作成し、すべてのチームメンバー間で共有します。
まったく1つのコードリポジトリ
GitHubに1つのクラウドチームプロジェクト (AzureのTFS)/リポジトリを作成し、チーム全体で共有します。
1つのハッカソンタスクに取り組んでいるチームの一部が1つのリポジトリにコミットし、ブランチに機能をコミットし、マスターにブランチを作成していることは明らかだと思います。一般に、コードに関する通常のチーム作業が進行中です。
すべての1つの初期データセット
Azure ML Studio (Web IDE)に移動し、[データセット]タブに移動して、初期データセットをクラウドにアップロードします。 データアクセスコードを生成し、チームに送信します。
これが、Azure ML Studioのデータロードインターフェイスの外観です。
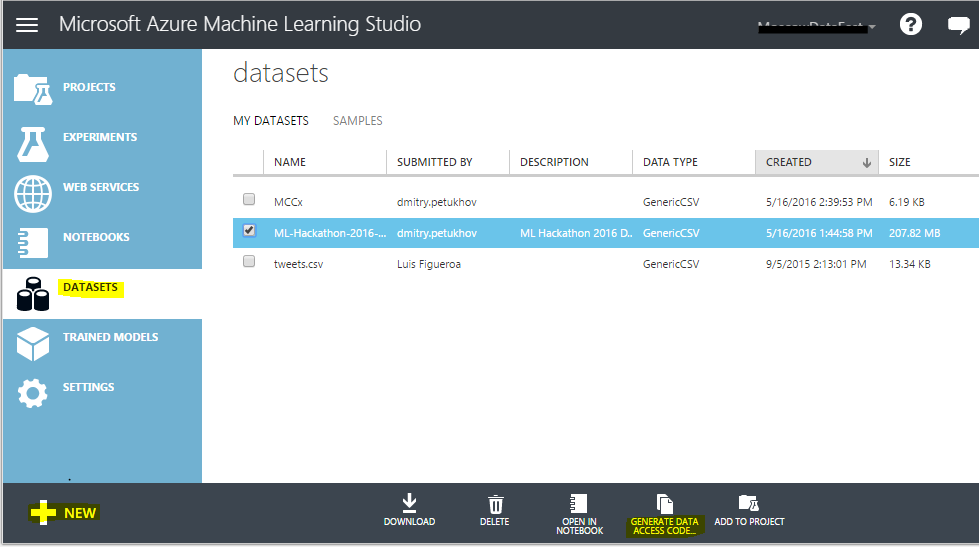
リスト1.データをロードするRスクリプト
library("AzureML")
ws <- workspace(
id = "<workspace_id>",
auth = "<auth_token>",
api_endpoint = "https://europewest.studioapi.azureml.net")
data.raw <- download.datasets(
dataset = ws,
name = "ML-Hackathon-2016-dataset")
3.3。 Jupyter Notebook:クラウドでRスクリプトを実行し、結果を視覚化する
日付の後、Azure MLのコードとプロジェクトがチーム全体で共有されました。次に、調査の視覚的な結果を共有する方法を学習します。
従来、このタスクでは、データサイエンスコミュニティはJupyter Notebookを使用します。これは、開発者がコード(R、Python)、実行結果(グラフィックスを含む)、リッチテキストそれへの説明。
Azure MLでJupyterノートブックを作成します。
- 参加者ドキュメントごとに個別のJupyterノートブックを作成します。
- Azure MLから単一の共有初期データセットを入力します(リスト1のコード)。 このコードは、ローカルのR Studioから起動したときにも機能するため、Jupyterノートブック用に新しいものを記述する必要はありません。RStudioからコードを取得してコピーするだけです。
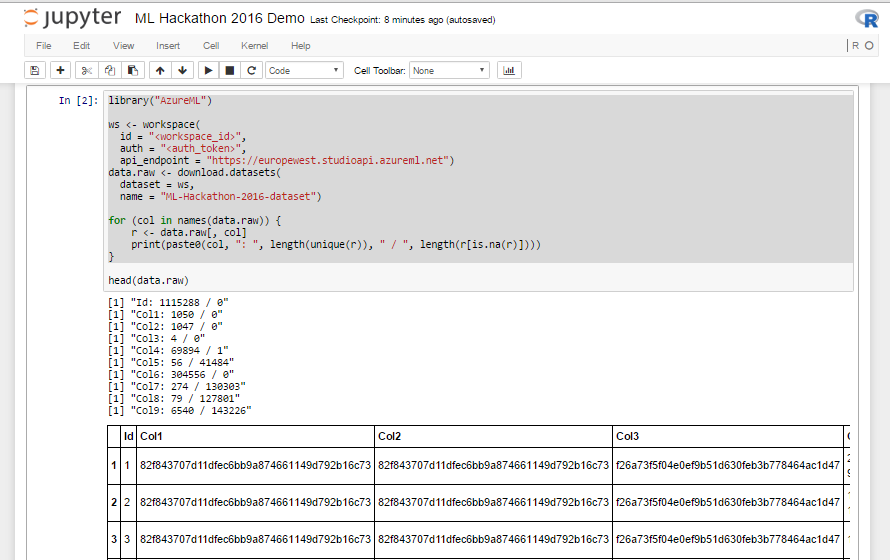
- Jupyter Notebookドキュメントへのリンクをチームと共有し、
急ぐJupyter Notebookで直接補足します。
その結果、各ハッカソンタスクについて、いくつかのJupyter Notebookドキュメントを取得する必要があります。
- Rスクリプトとその実行結果を含む;
- チーム全体が空想し、考えた。
- フルフローで:データのロードから機械学習アルゴリズムの適用結果まで。
これは私にとってどのように見えるかです:
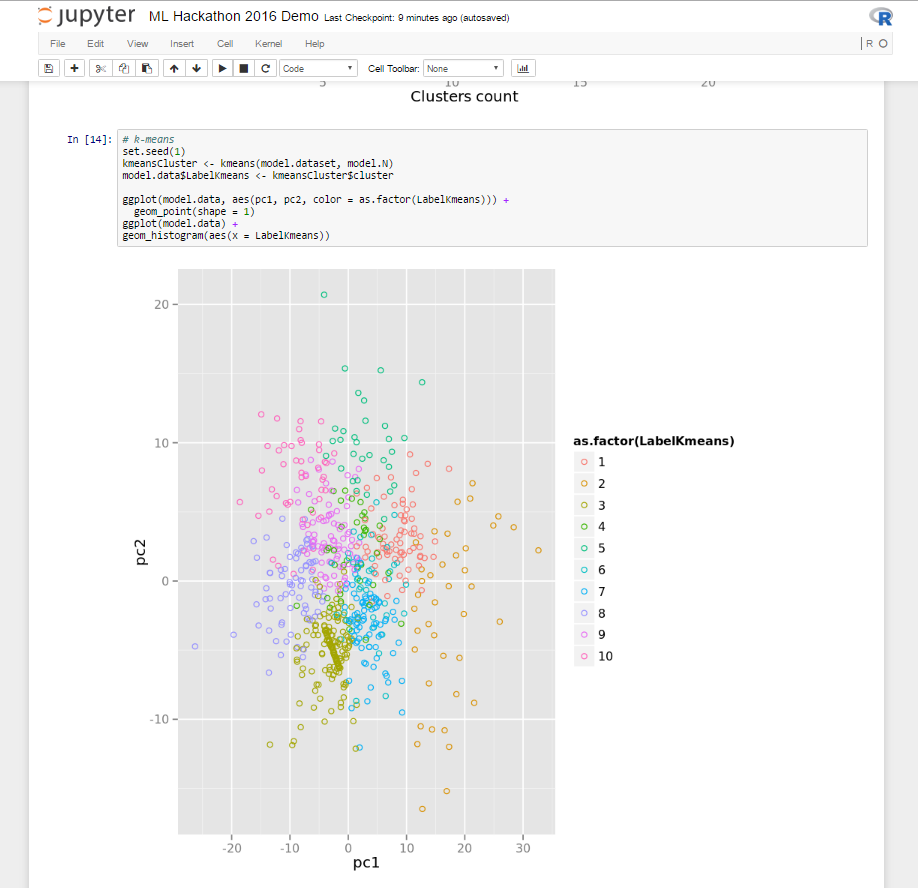
3.4。 試作から生産まで
この段階では、許容可能な結果が得られ、これらの研究に対応するいくつかの研究があります。
- GitHub / Team Projectの場合:Rスクリプト付きブランチ。
- Jupyter Notebookで:何が起こったのかをチームで議論した結果を含む少しのドキュメント。
次のステップは、Azure ML Studio(タブ「実験」)で実験を作成し、次にAzureML実験を作成することです。
この時点で、RコードをAzureML実験に移植するときは、次のベストプラクティスに従う必要があります。
モジュール:
- 可能であれば、組み込みの「Execute R script」モジュールをRコードを実行するためのコンテナーとして使用しないでください:バージョン管理サポートがありません(モジュール内で行われたコード変更はロールバックできません)、Rコードと一緒にモジュールを別の実験で再利用することはできません
- Azure MLでカスタムRパッケージ(カスタムRモジュール)をアップロードする機能を使用します(以下のダウンロードプロセスについて)。 カスタムRモジュールには一意の名前、モジュールの説明があり、さまざまなAzureML実験の一部としてモジュールを再利用できます。
Rスクリプト:
- Rモジュール内のRスクリプトを、単一のエントリポイントを持つ一連の関数として整理します。
- 組み込みのAzure ML Studioモジュールを使用して再現することが不可能/困難な機能のみをRコードの形式でAzure MLに転送します。
- モジュールのRコードは、次の制限付きで実行されます。永続ストレージおよびネットワーク接続へのアクセスはありません。
上記のルールに従って、RコードをAzureML実験に転送します。 2つのファイルで構成されるzipアーカイブが必要です。
- クラウドに転送しようとしているコードを含む.Rファイル。
データの外れ値の検索/フィルタリングの例PreprocessingData <- function(dataset1, dataset2, swap = F, color = "red") {
# do something
# ...
# detecting outliners
range <- GetOutlinersRange(dataset1$TransAmount)
ds <- dataset1[dataset1$TransAmount >= range[["Lower"]] &
dataset1$TransAmount < range[["Upper"]], ]
return(ds)
}
# outlines detection for normal distributed values
GetOutlinersRange <- function(values, na.rm = F) {
# interquartile range: IQ = Q3 - Q1
Q1 = quantile(values, probs = c(0.25), na.rm = na.rm)
Q3 = quantile(values, probs = c(0.75), na.rm = na.rm)
IQ = Q3 - Q1
# outliners interval: [Q1 - 1.5IQR, Q3 + 1.5IQR]
range <- c(Q1 - 1.5*IQ, Q3 + 1.5*IQ)
names(range) <- c("Lower", "Upper")
return(range)
}
- R関数の定義/メタデータを含むxmlファイル。
例(引数セクションは例の幅広さのためだけです)<Module name="Preprocessing dataset">
<Owner>Dmitry Petukhov</Owner>
<Description>Preprocessing dataset for ML Hackathon Demo.</Description>
<!-- Specify the base language, script file and R function to use for this module. -->
<Language name="R" entryPoint="PreprocessingData " sourceFile="PreprocessingData.R" />
<!-- Define module input and output ports -->
<Ports>
<Input id="dataset1" name="Dataset 1" type="DataTable">
<Description>Transactions Log</Description>
</Input>
<Input id="dataset2" name="Dataset 2" type="DataTable">
<Description>MCC List</Description>
</Input>
<Output id="dataset" name="Dataset" type="DataTable">
<Description>Processed dataset</Description>
</Output>
<Output id="deviceOutput" name="View Port" type="Visualization">
<Description>View the R console graphics device output.</Description>
</Output>
</Ports>
<!-- Define module parameters -->
<Arguments>
<Arg id="swap" name="Swap" type="bool" >
<Description>Swap input datasets.</Description>
</Arg>
<Arg id="color" name="Color" type="DropDown">
<Properties default="red">
<Item id="red" name="Red Value"/>
<Item id="green" name="Green Value"/>
<Item id="blue" name="Blue Value"/>
</Properties>
<Description>Select a color.</Description>
</Arg>
</Arguments>
</Module>
結果のアーカイブをAzure ML Studioからダウンロードします。 そして、スクリプトが機能し、モデルをトレーニングしたことを確認しながら、実験を実行します。
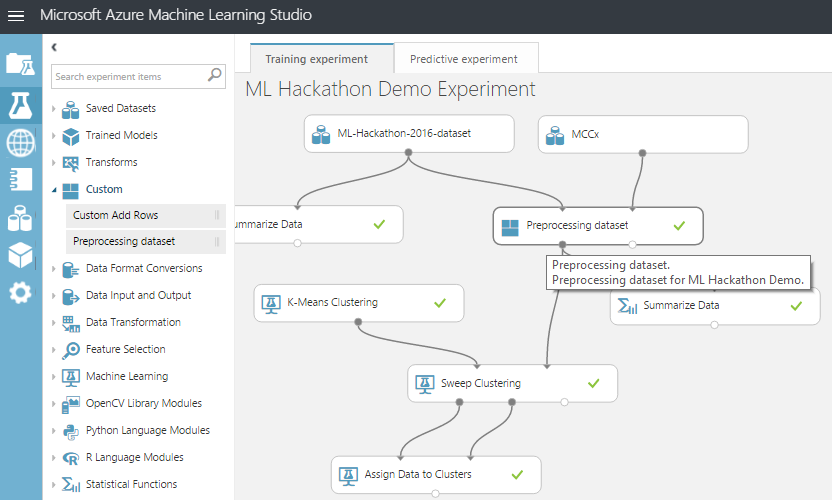
これで、既存のモジュールを改善し、新しいモジュールをロードし、それらの間の競争を手配することができます-一般に、カプセル化とモジュール構造の利点を使用します。
おわりに
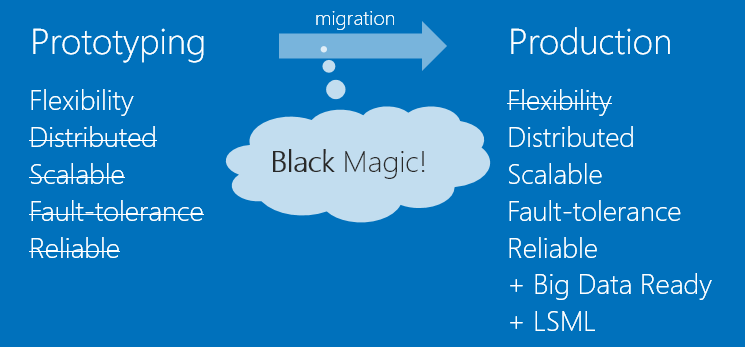
私の意見では、Rはプロトタイピングに非常に効果的であり、これからさまざまなタイプのデータサイエンスハッカソンで実証されています。 同時に、プロトタイプと製品の間には、スケーラビリティ、可用性、信頼性などの乗り越えられないギャップがあります。
Azure Toolkit for Rを使用すると、Rの柔軟性と、Azure MLが提供する信頼性とその他の利点との間で、長期にわたってバランスを取ることができます。
その他...
Azure Machine Learningハッカソン (最初に説明しました)にアクセスして、自分ですべて試して、専門家や志を同じくする人々とチャットしてください
さらに、オフラインでのコミュニケーションがほとんどない人のために、ハッカソン参加者が質問をしたり、お互いに経験を共有したり、ハッカソンがMLソリューションについて話し合ったり、専門の連絡先を維持し続けることができる、 温かいチューブスラックチャットに招待します 。
Habréの個人的なメッセージや、私のブログで見つけた連絡先をたるみに誘ってくれませんか(リンクは付けません-Habréのプロフィールで見つけるのは難しくありません)。