
今日、ラトビア国立図書館のエディションがどのようにデジタル化されたかを伝えたいと思います。 私たちのブログをフォローすると、おそらく私たちの技術がさまざまな図書館の文学遺産をデジタル化するのにどのように役立つか、そして個々のプロジェクトに関する記事- サハリン図書館 、エジンバラ王立植物園およびハートレー図書館のデジタル化を読んでいるでしょう。 今日は、リガでの様子の物語です。 したがって、1919年に設立された国内最大のラトビア国立図書館には、ユニークなゴシックスペルのラトビア語を含む、450万番目の書籍と文書のコレクションがあります。
16世紀以来、すべてのテキストはゴシック文字で記録され、ラトビア語で最も古い印刷物であることが確認されています:カトリック教の教理カニシヤ(ビリニュス、1585年)と小教理のM. ゴシックフォントは、20世紀までラトビア語を記録するために使用されていました。 最も興味深いのは、ゴシック版の通常のドイツ語(既に馴染みのある)とは異なっていたことです。


当初は、物理的に損傷を受けているか、読者に人気のある資料、または歴史的に重要と見なされる資料を処理することを計画していました。 少なくともデジタル形式で「保存」する必要がありました。 およその作業量は定期刊行物の2.5千ページで、これは出版物自身の約1000冊と本の150万ページに相当します。これは約7000枚です。
デートの歴史
私たちの知り合いの時までに、図書館はすでにABBYY OCRテクノロジーを使用しているデジタル化サービスプロバイダーと既に協力していた。 しかし、スキャンを認識することはできませんでした-問題は、ラトビアのゴシック様式がそのようなシンボルで訓練されていないため、テクノロジーが正しく「見る」ことができないということでした。 その後、ライブラリはABBYYに変わりました。
ゴシック認識
その頃には、 ABBYY FineReader Engineはすでにゴシックフォントをサポートしていましたが、ラトビアのゴシックは類似の有名なドイツのゴシックフォントとは異なっていました。 製品に新しいフォントを教えるために、多くの新しい文字を追加する必要がありました。
ライブラリから画像のパッケージを受け取りました。 これが最初のパッケージの一部の外観です。


このパッケージから画像の一部を取り、それを2つのベースに分割しました。グラフェンをトレーニングするトレーニングベースと、認識精度を検証するテストベースです。 書記素は、シンボルをグラフィカルに表現する特定の方法です。 記号と書記法の関係は非常に複雑です-ヨーロッパ言語では、複数の書記法が1つの書記法に対応できます(ラテン語とキリル文字の小さい「C」と大きい「C」はすべて1つの書記法です)。異なる書体で異なるフォントを示すことができます)。

書記素を追加し、次に分類子を使用して各書記素について(オムニフォン、等高線、ラスターなど、いくつかあります- ここで分類子について詳しく書きました )特徴ベクトルを選択して、この書記素の多くの画像をグループ(クラスター)に分割します、それぞれのすべての画像は可能な限り互いに類似しており、同時に異なるグループの画像は可能な限り類似していませんでした。 したがって、テキスト認識中に遭遇する文字が何らかの書記素であるという基本的な確実性を計算することができます(この書記素の特定のクラスタにある程度確実に属します)。
認識中に同じ画像にいくつかの可能性のあるオプションがある場合、差分ペアがコンパイルされます。 これらは互いに類似している異なるグラフェンのペアであり、したがって混同することができます。 そのようなペアの場合、異なる記号が区別され、それによって区別できます。
それらのいくつかを以下に示します。
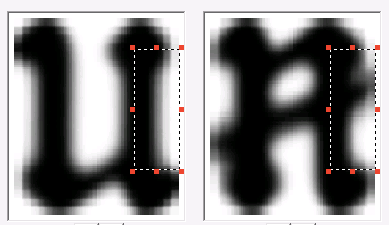
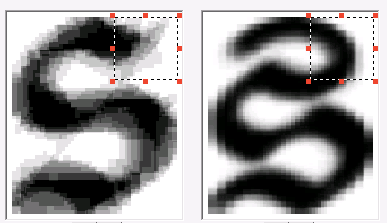
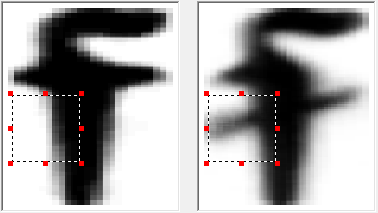
すべての機能が説明され、テストイメージパッケージのプログラムがエラーの5%未満を示した後(95%の精度は、言語を最初の近似としてサポートすると仮定するのに一般に十分です)、フォントを追加する作業は完了したと見なすことができます。 合計で39文字が追加されました。 FineReader Engineのバージョンを新しいフォントで作成し、ライブラリに送信しました。 少し後に、彼らは私たちに別の画像のパッケージを送りました-その中には最初のパッケージにはなかったキャラクターがいました。 そして、それはすべて新たに始まりました-もちろん、新しい入門的なものの量はより小さく、結局は技術が「完成」しなければなりませんでした。
変化は避けられない
最後に、ラトビア語のスペルでゴシックをサポートするFineReader Engineの準備が整いました。 クライアントに送信すると、図書館は以前のデジタル化サービスプロバイダーとの協力を停止したことが判明しました。 私たちにとって、これはSDKを最終製品に埋め込む人がいないことを意味し、本を認識するはずでした。 Engineを最終製品にリメイクする以外に選択肢はありませんでした。その結果、ある日、すべての画像を1つのフォルダーから取得し、特定の形式の認識結果を別のフォルダーに追加するアプリケーションを作成しました。 一方、図書館管理は、図書館ソフトウェアのデジタル化と保守サービスを提供する会社の代替品を探していました。 選択肢はドイツの会社CCSにありました。CCSはすでに当社の製品と技術を使用しています。 既に完成したEngineをゴシックフォントでシステムに簡単に統合して開始するだけで十分でした。
そして、同様の物語で通例であるように、最後に少しの統計。 400万ページの古代の本や現代の出版物を処理するのに1年以上かかりました。 プロジェクトのピーク時には、60人のスキャンおよび検証オペレータが毎日3時間の8時間交代勤務をしなければなりませんでした。
ラトビア国立図書館の書籍のデジタル版は、ウェブサイトwww.periodika.lvにあります。