Pythonプログラマーは通常、エラーで戦うために彼を送るとき何をしますか?
最初に彼は歩sentに登ります。 ここでは、時間、サーバー、エラーメッセージの詳細、トレースバック、および役立つコンテキストを見つけることができます。 次に、このデータが十分でない場合、プログラマーは ボトルで 管理者に。 サーバーをクロールし、ファイルログでこのメッセージを探し、エラーとその前のいくつかのレコードを見つけます。 まれに 調査に役立ちます。
しかし、ログのログloglevel=ERROR
のみで、エラーが非常に急であるため、ローカライズには多数のサーバーで実行されているいくつかの異なるデーモンの動作を一致させる必要がある場合はどうでしょうか?
ソリューションは、ログの集中リポジトリです。 最も単純な場合-syslog(rutubeで展開された5年間、使用されたことがない)、より複雑な目的-ELK 。 率直に言って、消しゴムはクールで、さまざまな分析をすばやくスピンできますが、Kibanaのインターフェイスを見たことはありますか? このことは、WindowsからLinuxのように、コンソールレス/ grepから遠く離れています。 したがって、JavaとNode.jsを使用せず、 sphinxsearchとPythonを使用して自転車を作成することにしました。
一般的に、ELKに対する主な不満は、Kibanaはログナビゲーションツールではないということです。 使用することが完全に不可能というわけではありませんが、grep / lessの代替としては、良くありません。

そのため、「自転車」のほぼ基本的な要件は最小限のレイアウトであり、 永遠にぶら下がっている 「敵」テクノロジーであるLogstashに基づいて構築されています。ElasticSearchも同時にスローされます。
パート1:派遣
ログを保存するには、どこかに送信する必要があります。 同じElasticSearchを直接作成することもできますが、RabbitMQを使用するとさらに楽しくなります。そのため、メッセージブローカーです。 python-logstashに基づいて、適切なRabbitMQのアクセス不能処理とそれにいくつかの「ブートローダー」を「ねじり」 ました 。 logcollectパッケージは、 Celery 、Django、およびネイティブpythonロギングの自動調整をサポートしています。 同時に、ハンドラーがルートロガーに追加され、すべてのログがJSON形式でRabbitMQに送信されます。
はい、ほとんど忘れていました。 例:
from logcollect.boot import default_config default_config( # RabbitMQ URI 'amqp://guest:guest@127.0.0.1/', # - # - activity_identity={'subsystem': 'backend'}, # RabbitMQ routing key. routing_key='site')
パート2、小規模:ルーティング
ログを事前にフィルター処理するために、RabbitMQ機能を使用しました。特定のテンプレートに一致するメッセージのみを処理キューに送信するトピック交換を使用します。 たとえば、「site」プロジェクトのDjango sqlクエリは、ルーティングキーsite.django.db.backends
対応するキューに設定されている場合にのみ処理され、ルーティングキーsite.django.#
を使用してdjangoからすべてのログを「キャッチ」できます。 これにより、保存されたデータの量とログに記録されたメッセージのカバレッジの完全性の間でバランスを取ることができます。
パート3、非同期:保存
当初、 ALCOの文字「A」は「非同期」を意味していましたが、asyncioベースのソリューションの使用は役に立たないことがすぐに明らかになりました。すべてがPythonプロセスによるメッセージのフィルタリング速度によって制限されていました。 これは理解できます:librabbitmqを使用すると、「rabbit」からすぐに大量のメッセージを受信できます。各メッセージを解析し、不要なフィールドを切り取り、無効なフィールドの名前を変更し、一部のフィールドのRedisに新しい値を保存し、タイムスタンプに基づいてsphinxsearchのIDを生成し、INSERTも生成する必要がありますリクエスト。
しかし、後で、「非同期」はまだ私たちに関するものであることが判明しました。CPU時間をより効率的に使用するために、pythonとsphinxsearchの間の往復INSERT要求は、Pythonのネイティブキューを介して同期され、別のスレッドで実行されます。
新しい列がデータベースに保存され、その後、列の表示と保存に関する多くの設定が利用可能になります。
- たとえば、レベル名でフィルタリングするためにlaリストフィルターを表示します。
- たとえば、セロリtask_idのように、別個のフィールドとしてインデックスを作成します。
- メッセージコンテキストモード-トレースバックの表示に非常に役立ちます。
- インデックス作成および列のリストからの例外。
パート4、フロントエンド
技術的な観点から言うと、特別なことは何もありません(bootstrap + Backbone.js + django + rest_framework)。そのため、スクリーンショットをいくつか紹介します。

ログは、日付、リストの特定の列の値、任意の値でフィルタリングしたり、メッセージ自体で全文検索を実行したりできます。 さらに、オプションで、見つかったフルテキスト検索に隣接するレコードを表示できます(hi、less)。
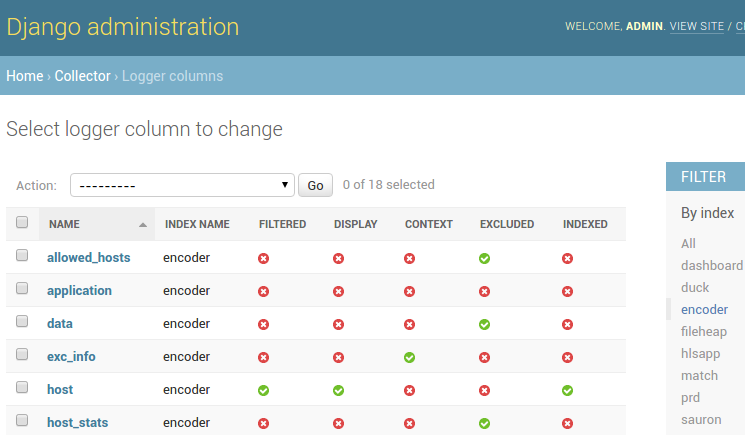
列の表示は、routing_keyインデックスまたはデータ保存期間の設定と同様に、管理パネルで構成されます。
パフォーマンスノート
残念ながら、超高速のページ読み込みはまだ自慢できません。sphinxsearchは、属性によるフィルタリングがインデックス全体のフルスキャンを必要とするように配置されているため、全文検索のみが迅速に機能します(grepを考慮)。 しかし、彼はメガバイトです! しかし、私たちはあきらめず、ハードフィルタリングのパフォーマンスを試しています。
たとえば、主キーはタイムスタンプに基づいて特別に生成されます。 sphinxsearchは、IDの範囲でデータを「すばやく」すくい取ることができます。 特定のインデックスサイズから始めて、個々の列にインデックスを付けることでパフォーマンスが向上します。カーディナリティが低いにもかかわらず、フルテキストインデックスが使用されているため、リクエスト処理にはjson属性によるフィルタリングの場合に1分あたり約20秒かかります。 リクエストは、リクエストされた日付の範囲に対応する分散インデックスも示します。したがって、「昨日」のログが必要な場合、月全体のデータは読み込まれません。
sphinxsearchブログのこの記事の時間以降、RT-indexに挿入する速度が大幅に増加しました:RabbitMQキューからレコードを受信して処理する際に、1000レコードの挿入で8000行/秒に(嘘をついていないかのように)管理したスタッフPythonプロセス。 また、alcoは各インデックスのレコードを複数のスレッドに挿入できますが、マシン上でsphinxsearchの完全なシャーディングまでは成長していません。本番環境ではあまり重要なログがなく、クリティカルになります。
設定で小さな焦点
注意深い読者は、(c)sphinxsearchの構成が明らかに静的ではないことに気付くでしょう;-)一般に、これは秘密ではなく、ドキュメントには、sphinx.confが「shebang」が先頭にあれば実行可能ファイルである可能性が高いと書かれています。 configスクリプトはpythonで記述されており、httpからalco管理パネルに移動し、djangoテンプレートエンジンによって生成されたsphinx構成をstdoutに出力し、同時に欠落しているディレクトリを作成し、未使用のインデックスを削除します。
私たちの「バイク」に興味がある人は、 githubで alcoの詳細を読むことができます。 Sphinxsearch、RabbitMQ、MySQL、Redisで十分です。 もちろん、バグレポートとプルリクエストを喜んで受けます。