良い一日。
しかし、すべてのハッシュテーブルが同等に役立つわけではないことをご存知ですか? それでは、1つの悪いハッシュテーブルがすべてのパフォーマンスをどのように食べ、眉をひそめなかったかについて話しましょう。 そして、このテーブルのハッシュを修正すると、コードがほぼ10倍高速化されました。
もちろん、トピックによると-記事ではDelphiについて説明しますが、Delphiの開発者ではない場合でも、カットを確認し、ソースコードの記事を読んだ後、使用するテーブルのハッシュを確認することをお勧めします。 そして、Delphi開発者に標準のTDictionaryを完全に放棄することを勧めます。
1.ハッシュテーブルはどうですか。
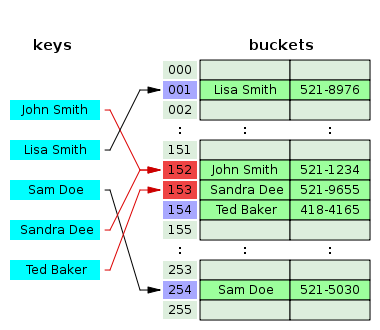
ハッシュテーブルがどのように配置されているか、および線形プロービングが何であるかをよく知っている場合、2番目の部分に安全に進むことができます。内部のハッシュテーブルは基本的に配列です。 このような配列の要素は、一般にバケットと呼ばれます 。 ハッシュテーブルの中心的な場所の1つは、ハッシュ関数です。 一般に、ハッシュ関数は、あるセットを固定サイズセットの別のセットにマップする関数です。 また、関数ハッシュのタスクは、固定セットで均一に分散された結果を提供することです。 ウィキペディアでハッシュ関数の詳細を読むことができますが、そこで止まりません。
そこで、たとえば10バケットの配列を準備しました。 これで、配列に値を追加する準備ができました。 キーからハッシュを取得します。 たとえば、ハッシュは32ビット整数Mであることが判明しました。 どのバケットに値を書き込むかを決定するために、除算の残り: Index:= M mod 10を取得します。 そしてバケット[Index]:= NewKeyValuePairに入れます。
遅かれ早かれ、いくつかの値が既にバケット[インデックス]にあるという事実に直面するでしょう。 そして、それについて何かする必要があります。 これは衝突解決と呼ばれます。 いくつかの衝突解決手法があります。 主なものは次のとおりです。
個別のチェーンまたはクローズドアドレッシング
最も単純な場合、このメソッドはこれを表します。 各バケットは、リンクリストのヘッドへのリンクです。 衝突が発生した場合、リンクリストに別の要素を追加するだけです。 リストが複数の線形リンクリストに縮退するのを防ぐために、 負荷係数などを導入します。 つまり、1つのバケットの要素数が特定の数( 負荷係数 )を超えると、バケットの新しい配列が作成され、古い要素がすべて新しい要素にプッシュされます。 この手順は再ハッシュと呼ばれます。
このアプローチの欠点は、<key、value>の各ペアに対して、リンクリストに追加する必要があるオブジェクトを作成することです。
このアプローチは改善できます。 たとえば、バケットの代わりに<key、value> +リンクリストの先頭へのリンクのペアを保存する場合。 負荷係数を1または0.75に設定することにより、リンクリストアイテムの作成を事実上回避できます。 また、配列であるバケットは、プロセッサキャッシュに配置された非常に友好的です。 ps現時点では、これが競合を解決する最良の方法だと思います。
オープンアドレッシング
このメソッドの場合、すべてのバケットがあります。これは配列<key、value>であり、ハッシュテーブルのすべての要素はバケットsに格納されます。 バケットごとに1つのアイテム。 このようなハッシュテーブルに要素を挿入しようとする試みは、 probeと呼ばれます。 最もよく知られているサンプルメソッドは次のとおりです。 線形プローブ、二次プローブ、二重ハッシュ 。
リニアプローブの仕組みを見てみましょう。
ここでは、バケットがすでに別の要素で占められている状況にあります。

次に、バケットに1つ追加して、次の要素に要素を配置します。

もう一度同じバケツにぶつかりましたか? 次に、3つの要素をステップオーバーする必要があります。

しかし、それはまったく失敗しました。

最後の例によれば、この方法を有効にするには、多くの空きバケットがあることが必要であることがはっきりとわかります。また、挿入された要素が特定の領域でスタックしないことが非常に重要であり、ハッシュ関数に高い要件が課されます。
失敗したハッシュ関数をバイパスする試みは、二次探査と二重ハッシュです。 二次探査の本質は、次のプローブが1、2、4、8などを通過することです。 要素。 ダブルハッシュの本質は、ハッシュ関数を使用して次のプローブのホップサイズが選択されることです。 最初のものとは異なるか、または同じですが、ハッシュは、先ほど入れようとしたバケットインデックスから取得されます。
しかし、オープンアドレス指定で最も重要なことは、1回の衝突なしで10,000個の要素を埋めたとしても、10001を追加すると、すでに存在する10,000個の要素すべてを並べ替えることになるということです。 そして最悪なことは、後で10001番に変更するためにこの10001番を入れた場合、10,000個前の値を再度整理する必要があることです。
前述から別の不快なことがあります。 オープンアドレッシングの場合、充填順序が重要です。 ハッシュ関数がどれほど優れていても、すべてが充填順序を台無しにする可能性があります。 最後のケースを見てみましょう、私たちは運が悪いです。 すべての要素は1回の衝突なしで埋められましたが、最後の要素は衝突があったため、多数のバケットが列挙されました:
しかし、最初にこの単一の要素を配置するとどうなりますか:

競合があり、バケットは1つしかありませんでした。
そして、彼らは隣人を置くでしょう:

再び1つのバケットを整理します。
そして次の隣人:

合計すると、追加により各要素につき1つの衝突のみが発生します。 また、追加中のソートされたバケットの総数は同じままですが、通常はよりバランスが取れるようになります。 そして今、任意の要素にアクセスするとき、バケットで2つのチェックを行います。
2.それでは、TDictionaryでのリニアプローブを使用したDelphiの何が問題になっていますか?
結局、良いハッシュ関数を使ったそのような「失敗した」順序を取得することは困難です、あなたは言いますか? そして、大きな間違いを犯します。
TDictionaryのすべての要素を取得するには、バケットの配列を調べて、占有されているセルの要素を収集する必要があります。 ここでの主な問題は、シーケンスが保持されることです! 別のTDictionaryを作成し、そこにデータをスローするだけで、次の要素が成長する前に最後の要素で多数の衝突が発生します。
状況を再現する最も簡単なコード:
Hash1 := TDictionary<Integer, Integer>.Create(); Hash2 := TDictionary<Integer, Integer>.Create(); for i := 0 to 1280000 do // TDictionary Hash1.Add(i, i); for i in Hash1.Keys do // - , ! Hash2.Add(i, i);
TDictionaryでは、バケットアレイ内の空きセルが25%未満の場合にのみ再ハッシュが発生します(しきい値の成長= 75%)。 容量の増加は常に2回発生します。 大きな辞書に記入されたバケットは次のとおりです。

これらの要素を小さなテーブルに追加しようとすると、次のように考えることができます。 大きなテーブルを2つの部分に分割します。 最初の部分は完全に同じです。

次に、後半(緑)の要素を追加する必要があります。

後半を追加すると、衝突の数がどのように増加するか確認してください。 また、リハッシュがまだ遠く、テーブルが十分に大きい場合、大きなオーバーヘッドが発生する可能性があります。
新しい要素を追加するときの衝突の数を数えましょう。 これを行うために、TDictionaryのソースコードをコピーし、衝突を返すコールバックメソッドをいくつか追加しました。 結果はグラフに表示されます。
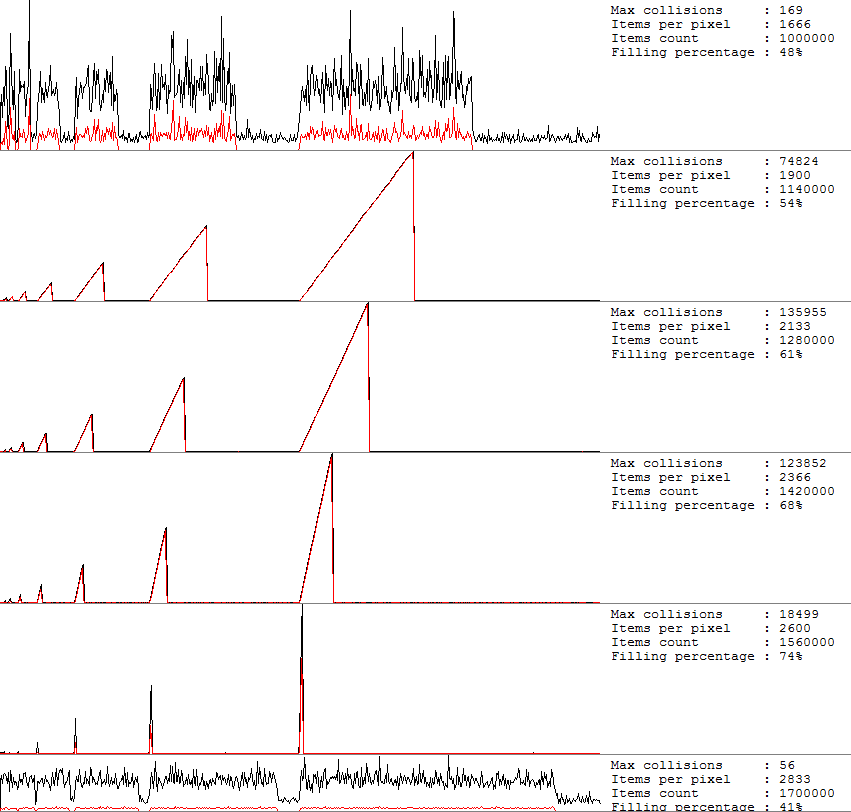
ハッシュテーブルに値を入力し、その値を入力すると、衝突の数を測定し、新しいN値ごとにX軸に沿って新しいピクセルが表示されます。 横軸はテーブルの塗りつぶしを示し、縦軸は衝突回数を示します。 各グラフの右側には値があります。
- 最大衝突 -X軸に沿った1ピクセル内の衝突の最大数。
- Items per pixel -X軸に沿ったグラフのピクセルあたりの要素の数。
- アイテム数 -ハッシュテーブル内のアイテムの総数
- 充填率 -テーブル内のバケットの数に対する要素の数の比率。
黒い線は、ピクセル内の衝突の最大数です。 赤は、ピクセル内の衝突の算術平均です。
最初のチャートでは、48%を埋めると、すべてが正常です。 衝突の最大数は169です。50%を超えると、最悪の事態が始まります。 そのため、61%で最大の喜びが得られます。 要素あたりの衝突数は13万に達することがあります! など、最大75%。 75%の後、成長が起こり、充填率が減少します。
それぞれが衝突の塊で見た-上の写真で示したものとは何も違う。 「のこぎり」は、リハッシュと衝突の急激な低下で終わります。
偶然、あなたはそのようなのこぎりの頂点にいるかもしれません、そして、最後に追加された要素で作業する試みは強いブレーキを伴います。
これを修正する方法は? さて、最も明白なオプションは、成長しきい値を50%に設定することです。 つまり ハッシュテーブルの空きセルは少なくとも50%でなければなりません。 このしきい値を変更すると、次のグラフが表示されます。
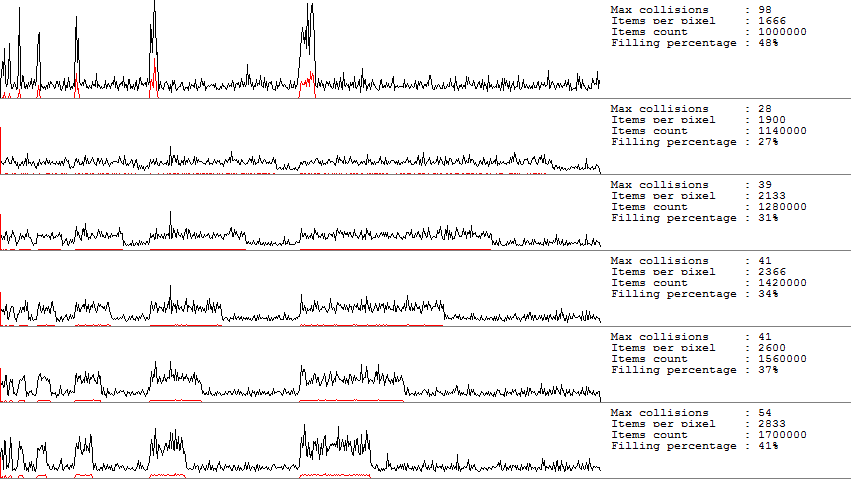
同じ量のデータで。 追加のメモリを犠牲にして、プロセッサ時間を「獲得」しました。 ここでの問題は、GrowThresholdフィールドに外部からアクセスできないことです。 失敗したシーケンスを回避することもできます。 データをテーブルに配置する前に手動でシャッフル/ソートしますが、これは非常に高価であるか、異なるハッシュ関数で異なるテーブルを作成します。 多くのハッシュ関数(Murmur2、BobJenkinsハッシュなど)により、Seed / InitialValueを設定できます。 ただし、これらの値をランダムに選択することもお勧めしません。 ほとんどの場合、素数はシードとして適していますが、特定のハッシュ関数についてはマニュアルを読むことをお勧めします。
最後に、私のアドバイス-ハッシュテーブルの普遍的な方法としてオープンアドレス指定を使用しないでください。 バケット<キー、構想> +負荷係数が約0.75のリンクリストの先頭へのポインターを使用したセパレートチェーンに注意する方が良いと思います。
psこの落とし穴を探すのに数日費やしました。 状況は、大量のデータをプロファイルするのが困難であるという事実と、%TD人口への依存により、ブレーキが不定期に定期的に消えるという事実により複雑になりました。 あなたの注意に感謝し、あなたがそれにつまずかないことを願っています。 ;)
upd 2016年11月 24日Rustでは、彼らは同じレーキを踏んだ: accidentallyquadratic.tumblr.com/post/153545455987/rust-hash-iteration-reinsertion
upd2 2017年1月31日またSwiftでも: lemire.me/blog/2017/01/30/maps-and-sets-can-have-quadratic-time-performance