最近、 ABBYY LSとXeroxはXerox Easy Translator Service(ドキュメントの機械翻訳を取得できるサービス)を開始しました。このため、Xerox ConnectKeyテクノロジーに基づくMFPを使用してドキュメントをスキャンするか、携帯電話のカメラで写真を撮る必要があります。 同じプラットフォームを使用して、プロの翻訳を注文できます。
どのように機能しますか? それを理解しましょう!
機械翻訳

ユーザーは、完成したファイルをWeb経由でスキャン、写真撮影、またはダウンロードします。 ファイルはデータベースに保存され、その後、セグメント(テキストのフラグメントを保存するオブジェクト(原則として、これらは文です)、およびこれらのフラグメントのレイアウトに関する情報)の解析が開始されます。 グラフィック形式のファイルは、以前はABBYY認識サーバーを使用して認識されていました。 認識文書を送信する前に、文書の言語をユーザーに尋ねます。 これは画像なしでも認識できますが、ソースドキュメントの言語を使用すると、画像をより速く、より適切に認識できます。
認識サーバーと統合するプロセスでは、ドキュメントフローの処理パラメーターを選択する必要がありました。結果をエクスポートするためのフォーマット、認識速度/品質比、ドキュメントアセンブリのタイプです。
現在、「old man」ドキュメントをエクスポート形式として使用しています。現時点ではリッチテキストを最も完全に説明し、同時にセグメンテーション中のページ上の要素のレイアウトに関連する多くの問題を解決します(hello、.docx!)。 それでも、.docxへの移行は計画中です。 速度と品質の関係が最も大きな論争を引き起こしました。 一方では、プロセス全体が自動化されており、組版の専門家を引き付ける方法がないため、認識の品質はドキュメントの機械翻訳の最優先事項です。 一方、MT(機械翻訳)の主な利点はその速度です(特に、ユーザーがMFPの近くで印刷された翻訳を待っているシナリオの場合)が、速度には品質を払わなければなりません。 それにもかかわらず、品質を優先して選択が行われました。
ドキュメントのアセンブリタイプによって、ソースドキュメントのどの要素が結果とともにファイルに分類されるかが決まります。 認識結果をプレーンテキストに制限することができます(コンテキストを理解するために重要な非テキスト情報が失われるため、このオプションは私たちには適していません)、このテキストの書式を保存できます(それは重要ですが、重要な非テキスト情報はどうですか?)。 編集可能なコピータイプは、フォーマットされたテキストと非テキストコンテンツを保存しますが、ページをバインドしません。 ページのレイアウトが壊れているように見えます-これはマイナスです。 ただし、翻訳中に単語の長さが大きく異なる場合があるため(たとえば、「friendship」という単語のドイツ語の翻訳が「Freundschaftsbezeigungen」である場合)、ソースファイルのページへのリンクがないため、他のページ要素と「ヒット」するテキストのブロックを回避できます。翻訳のテキストをソーステキストのブロックサイズで入力することはできません。 Exact Copyの最終バージョンでは、フォーマットされたテキストとテキスト以外のコンテンツの両方が保存されます。 出力には、ページレイアウトに関して元のドキュメントにできるだけ近いドキュメントがあります。 このオプションは、ページネーションをサポートする形式(pdf、djvu)の観点からはより堅実に見えますが、翻訳は行き過ぎている可能性があります。 その結果、 編集可能なコピーを選択しました。
ソーステキスト

完全コピーの例

EditableCopyの例

さらに、認識されたファイルはすでに述べたセグメンテーションを通過し、ドキュメントの最初の1000文字を含むセグメントについては、テキストの言語が自動的に検出されます。 ファイルをダウンロードするときにドキュメントの言語を指定するようにユーザーに既に要求したという事実にもかかわらず、APIを使用しているときは、グラフィック形式では言語を設定する必要はなく、テキスト形式のドキュメントを読み込むときには言語の設定はまったく必要ないため、自動検出を実行します。 言語を知っていれば、ドキュメントの統計、つまりページ数、単語数、文字数を計算できます。 その後、サービスはドキュメントセグメントのブロックを機械翻訳API(MT-API)を介して複数のMTエンジンの1つに送信します。 翻訳が完了すると、ドキュメントが収集され、通知がユーザーに送信されます。
機械翻訳の例:
ソース画像

結果

機械翻訳技術はまだ品質がプロよりもはるかに劣っていますが、文書の一般的な条項を理解する必要がある場合に大量の情報を迅速に翻訳するタスクに対応していることに注意してください。 別の頻度のシナリオは、ソーステキストの関連部分を理解することです。ソーステキストは、より慎重に翻訳できます。 それにもかかわらず、翻訳メモリデータベースを使用して機械翻訳の品質を改善するための措置を講じています。これについては、以下で説明します。
プロの翻訳
ユーザーがより良い翻訳を必要とする場合は、プロの翻訳者に注文することができます。 この場合、ファイルパスはわずかに異なります。
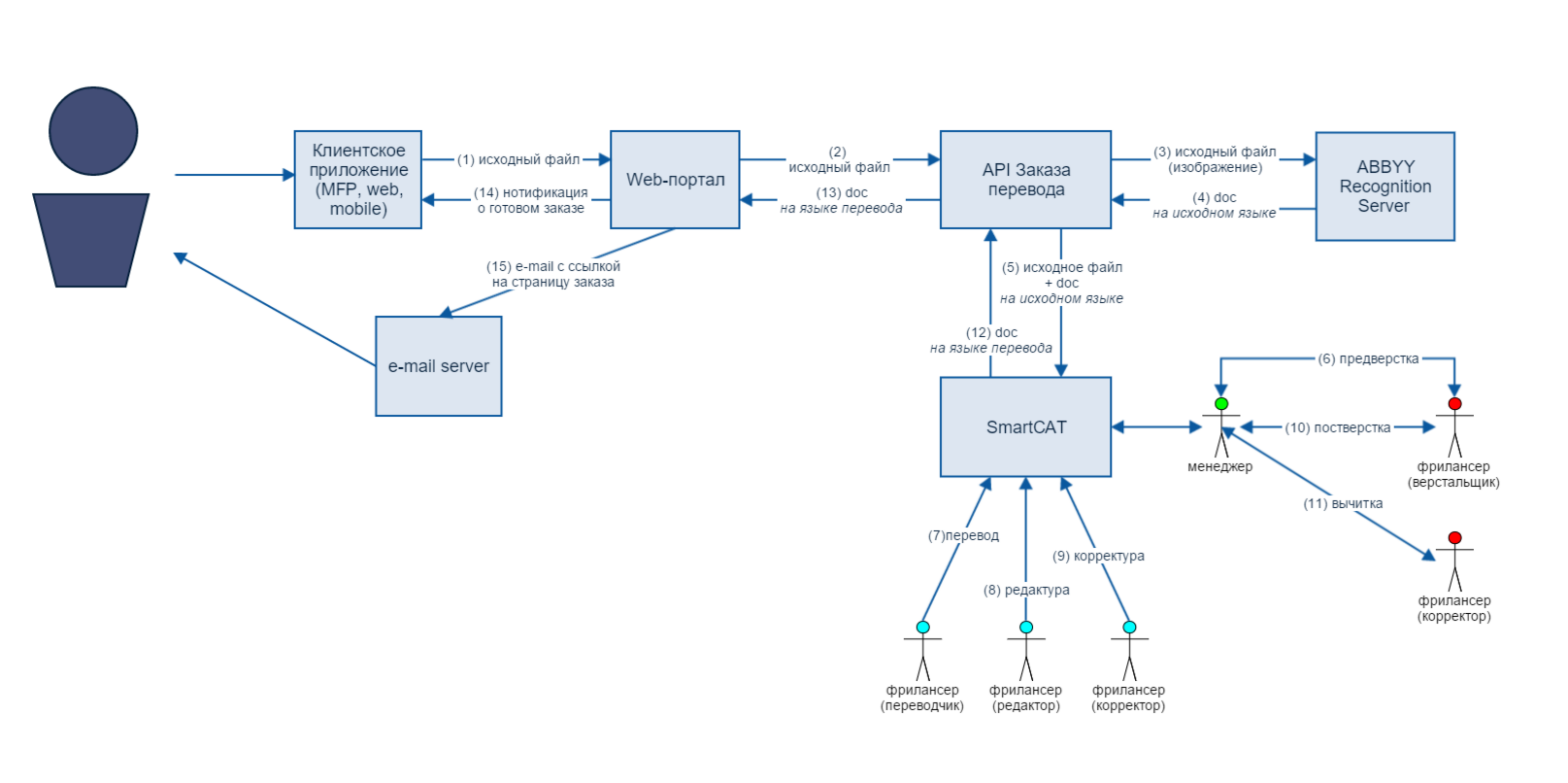
認識サーバーで認識されたテキストは、ソースドキュメントとともに、翻訳プロセスを自動化するためのプラットフォームであるSmartCATに送信されます。 翻訳中にテキスト以外のコンテンツを使用できるように、ソースファイルが必要です。これには、翻訳コンテキストを維持するために重要な情報が含まれている場合があります。 しかし、ドキュメントが翻訳者自身に届く前に、マネージャーは予備的なレイアウトが必要かどうかを確認し、必要に応じてレイアウトの専門家を集めます。 そのときだけ、パフォーマーが指名されます。 エディターで直接、翻訳者は機械翻訳エンジンと翻訳メモリデータベースの両方にアクセスできるため、ドキュメントに費やす時間を削減できます。 翻訳が完了すると、編集され、減算され、マネージャーによって再度チェックされます。 これで翻訳が完了し、ユーザーは電子メールアラートと高度な結果のファイルを受け取ります。
翻訳例:
ソース画像

結果

これはすべて内部でどのように機能しますか? いい質問です!
ケーキは嘘ではありません!

パフケーキが好きですか? 私たちは大好きで、アプリケーションのインフラストラクチャはそのようなケーキとして表すことができます:

各ピースは、特定の機能、たとえばFileManagement-ファイル管理を実装するdllアセンブリで構成されています。 ライブラリは、コントラクト、Web API、データストレージ、タスク処理などのレイヤーにも分割されます。 分離中に、CQRSの原則が実装されました。これは、メソッドが何らかのアクションを実行するコマンドか、同時にではなくデータを返すクエリのいずれかでなければならないコマンドクエリ責任分離です。 言い換えれば、質問をすることで答えを変えるべきではありません( wiki )。
契約
コントラクトアセンブリには、アプリケーションモジュールがやり取りするインターフェイス、および説明した機能が動作するコマンドとリクエストが格納されます。 これらのアセンブリは、同じ機能セットの他のレイヤー(たとえば、ファイル管理はFileManagement.ApiとFileManagement.Processing)およびその他の機能(順序管理ではファイル管理を使用します)によって使用されます。
Web API
ここではすべてが簡単です-コンシューマーによって呼び出されたAPIメソッドは、コマンド、リクエスト、またはそれらの組み合わせの実行を開始し、ユーザーに結果を提供します。
データ保存
データストレージ。 アセンブリは、特定のタイプのコマンドおよびリクエストの実行をサブスクライブし、データの変更または読み取りを実行します。 これらの目的のためにMongoDBを使用しますが、データの操作はコマンドとクエリを介して実行されるため、残りの(データストレージではなく)アセンブリはデータベースのドキュメントの本質のみを推測できます。
タスク処理
長時間の操作を実行します。 データストレージアセンブリと同様に、このアセンブリは特定のコマンドの呼び出しをサブスクライブしますが、そのようなコマンドの処理の開始のリアルタイムはスケジューラーによって規制されます。 このようなコマンドはタスクと呼ばれます。 ファイルをセグメントに解析することは、そのようなタスクの1つです。
プロジェクト全体のツリーは次のようになります。

このようにレイヤーと機能を分離することで、
そして、再び会うまで、今日はこれですべてです。