過去6か月間、おなじみのYandex Search Engine Result Page(SERP) インターフェースは新しいアーキテクチャに移行しており 、非特定機能の開発は非常に高速になり、特定機能の開発は予測可能になりました。 40のフロントエンドプロバイダーの大規模な分散チームにとって、これは大きな成功です。 すべての準備がほぼ完了し、実稼働実験で新しいコードの実行が開始されると、新しいアーキテクチャでのサーバー側のJS標準化が大幅に遅くなることが判明しました。

新しいコードはよりシンプルで論理的に整理されていたため、スローダウンは望ましくないだけでなく、予期しないものでした。 新しいアーキテクチャの「青信号」を得るには、少なくとも古いものより遅くならないようにコードを高速化する必要がありました。
単純な「ピアリング」では問題を解決できませんでした。理解する必要があり、プロファイルする必要がありました。 これがどのように行われたかを調べるために読んでください。
私たちのキッチン
SERPはBEMで記述されています。 サーバー側テンプレートはJSで記述され、2つの部分で構成されます。
- バックエンドデータをBEMJSONページ(ブロック、要素、および修飾子のツリー)に変換するコードはPRIVテンプレートです。
- BEMJSONをHTMLに変換するコードはBEMHTMLテンプレートです。
2番目の部分については触れませんでした。最初の部分ではアーキテクチャが置き換えられました。
現在、PRIVテンプレートでは、デスクトップ、タブレット、電話の3つのプラットフォーム用にBEMJSONが生成されています。 減速は最初の2つのプラットフォームにのみ影響しました。
PRIVコードは、グローバルスコープ内の多数の関数です。 関数はBEMによって命名され、異なるファイルにあり、アセンブリプロセス中に1つのファイルにアセンブルされます。
例:
// - blocks['my-block'] = function(arg1, arg2) { /* ... */ } // - – // - blocks['my-block__elem'] = function(arg1, arg2) { /* ... */ }
以前は、ブロック関数は同等であり、どの階層にも含まれていませんでした。 いくつかのブロックは低レベルで実際にBEMJSONを生成しましたが、他のブロックは高レベルでした-それらはブロックをレベルが低いと呼びました。
新しいアーキテクチャでは、ブロックには固定インターフェイスを持つ役割があります。 ブロックは抽象レベルに統合され始め、生データを処理して最終的なBEMJSONを生成するためのパイプラインが形成されました。
始める前に
クイック検索の結果、ユニバーサルJSコードプロファイラーは存在せず、トピック自体はあまりカバーされていませんでした。 外出先で方法を理解する必要があり、同時にそれらについて自分の意見を形成する必要がありました。
サーバー側のJSコードのプロファイリング、単純なメソッドから複雑なメソッドへのソートについて説明します。 注:Node.JS 4.2.2でのみ作業しました。
GUIアプローチ。 クロム
最も単純で一見明らかなツールは、Chromiumブラウザーに組み込まれたプロファイラーで、 ノードインスペクターモジュールを使用して使用できます 。
プロファイラーの結果として、収集された結果の3つのビューを取得します。
- トップダウン
- ボトムアップ;
- チャート。
3つすべては、実行されたコードの完全な呼び出しツリーを表示するさまざまな方法です。 前者の場合、ツリーは上から下、2番目の場合-下から上、3番目の場合-例を見てみましょう。
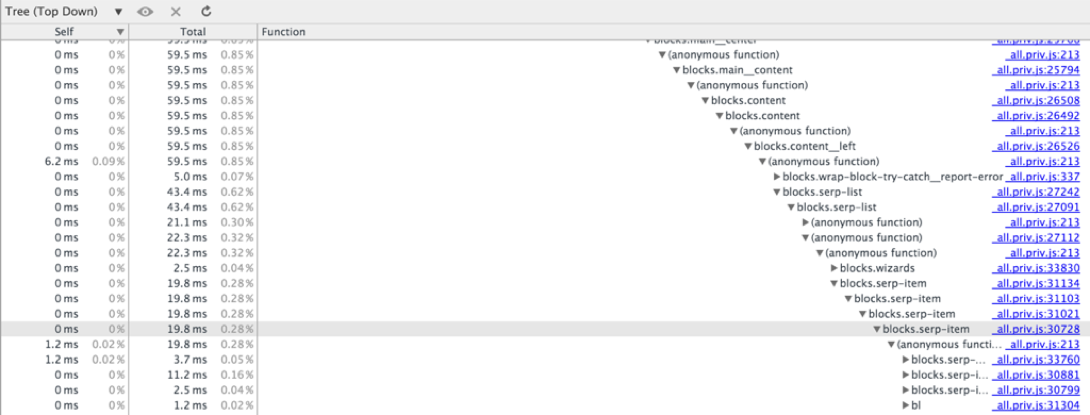
↑ トップダウンでは、コールスタックの浅い深さにある関数呼び出しのみの実行時間を追跡できます。 問題は、水平スクロールの欠如です。 この例では、ツリーの高さが182で、深さ37のコールに到達できましたが、残りは画面の右端の後ろに隠れたままでした。
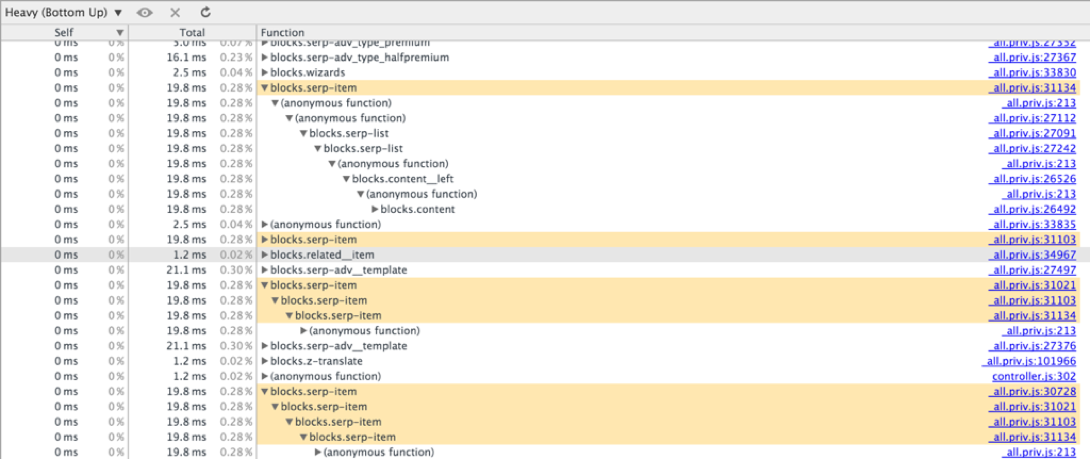
↑「どこからでも」ツリーの表示を開始できるため、 ボトムアップでは水平スクロールは不要です。 関数Fを呼び出して開始した場合、ツリーを登って関数Gを呼び出し、画面の端で休憩します。Gが別に呼び出され、移動を続けます。 幸いなことに、関数名による検索があります。 しかし、ここでは、合計実行時間が特定の定数よりも短いことが判明した関数は表示されません。
ボトムアップで関数を見つけることができなかった場合、実行時間は非常に短いか、コンパイル中にインライン化されました。
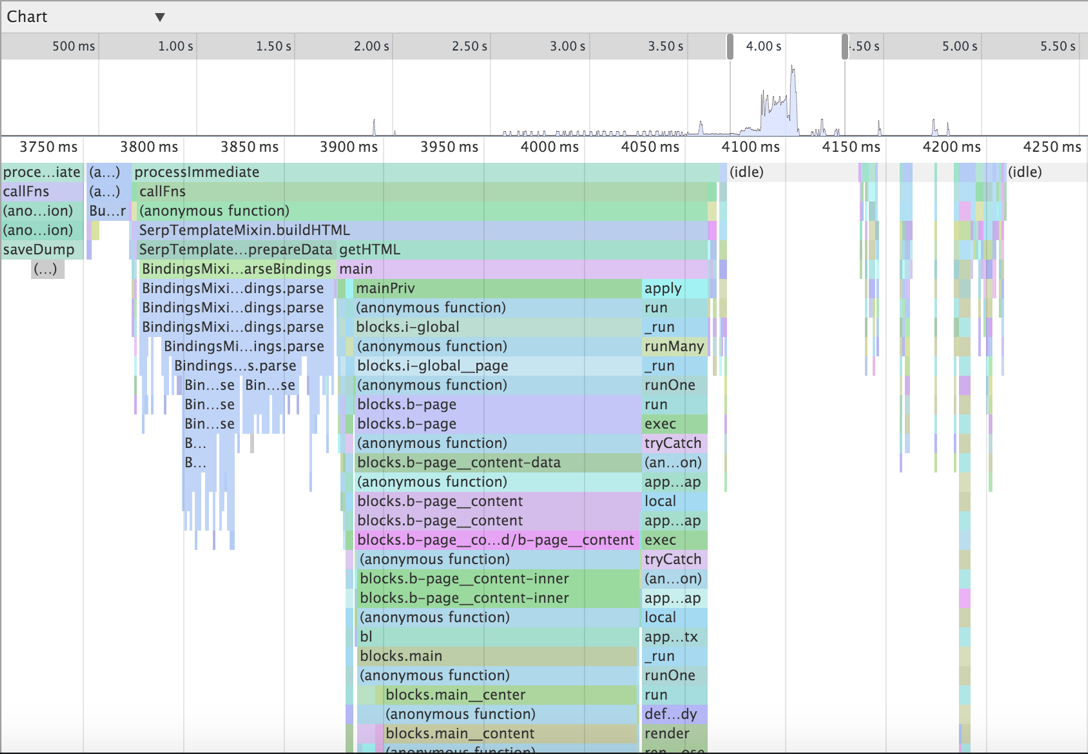
↑ チャートは、時間軸に関連付けられたコールツリーを描画します。スケールと水平スクロールのみを変更できます。 ここでは、深さ32で呼び出しが表示され、残りは画面の下端を超えています。
GUIアプローチ。 ウェブストーム
GUIプロファイラーのオプションはChromiumとノードインスペクターだけではありません。たとえば、WebStormは同様の機能を提供します。
実行->構成の編集...-> Node.js構成-> V8プロファイリングタブ
呼び出しツリーを表示するには、4つの方法があります。
- トップコール
- フレームチャート;
- ボトムアップ;
- トップダウン。
ここで、実行時間によってフィルタリング機能のしきい値を制御できることに注意してください(まったくフィルタリングできません)。
このケースのトップコールは、共有ライブラリ(bin / node、libsystem_kernel、libsystem_malloc、libsystem_c、libstdc ++)のランタイムのみを示しました。
フレームチャートはChromiumのチャートに似ていますが、理解できないだけで役に立たないようです。 少なくともいくつかの課題とそのネストを識別するために、写真を拡大することはできませんでした。
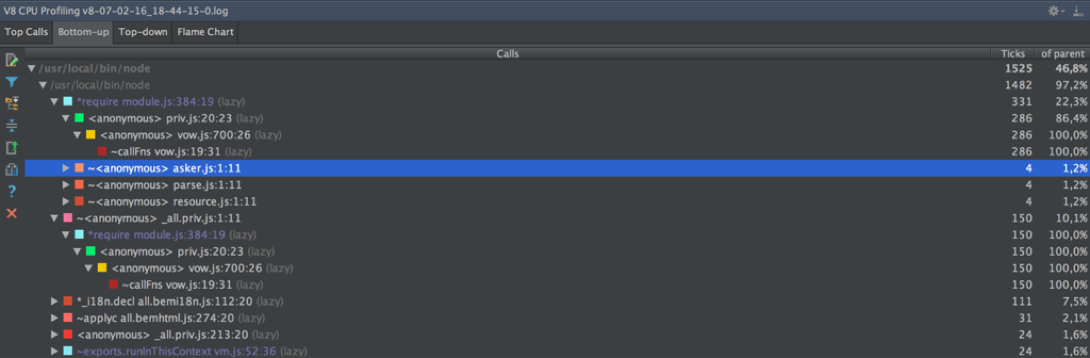
↑ ボトムアップはChromiumの同様のモードに似ていますが、ここでは検索が行われず、構造がわずかに異なります。 関数名で検索せずにこれを使用することは不可能です。
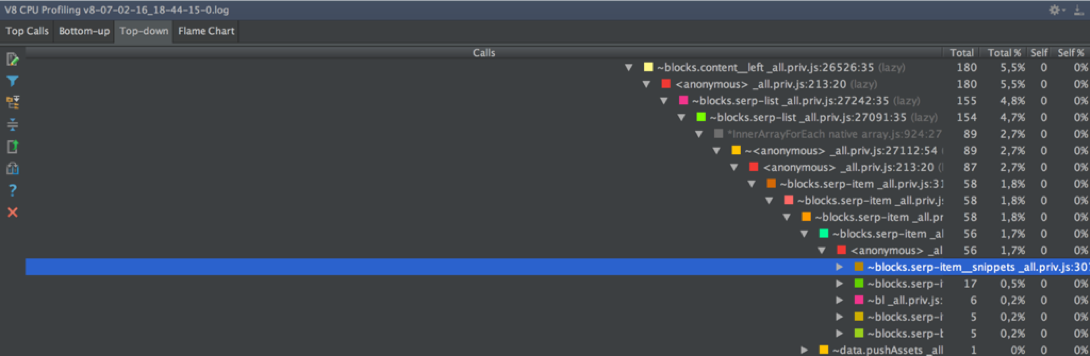
↑ トップダウンでは、同様の状況でChromiumと同様に水平スクロールが行われません。 ネストの37番目のレベルより下で実行された機能を確認することはできません。 ここでスタックはより詳細であり、JS呼び出しだけでなく、言語の内臓(ArrayForEach、InnerArrayForEach、Module._compile、Module._loadなど)も含まれています。
GUI出力
考慮されているGUIプロファイリングの方法の中で、最も便利なのは、ノードインスペクタとChromiumを介してデータを収集し、呼び出しの完全な検索ツリーのボトムアップ表現の形式でデータを分析することです。
コールツリーの高さが30以下の場合、他の方法とソリューションを便利に使用できます。
ただし、これらのメソッドはすべて、サーバーコードのプロファイリングには適していません。 ノードインスペクターを起動し、CPUプロファイルの記録を有効にし、いくつかの要求を行い、データの分析を開始するだけでは不十分です。 特徴的なクエリの代表的なサンプルと、機能を完了するのにかかった合計時間だけでなく、他の指標(平均時間、中央値、さまざまな百分位数)も必要です。 制御された実験が必要です。
プロファイリング理論
プロファイリングには、計装とサンプリングプロファイリングの2つの基本的なアプローチがあります。
インスツルメンテーションプロファイリング中に、プロファイルされたコードを変更し、すべての関数呼び出しのログ記録を追加します。 このメソッドは、詳細ではあるがわずかに歪んだ情報を収集します。これは、最終的にプロファイルされるのはソースコードではなく、ロギングされた修正されたソースコードであるためです。
サンプリングプロファイリング中、プロファイルされたコードは変更されませんが、実行中のシステムは定期的に実行を一時停止し、コールスタックの現在のスナップショットを記録します。 この方法の本質は、例を使用して後で検討します。
ガイド付き実験1
計装アプローチ
すべてのコードが関数のセットである場合、このアプローチは非常に有機的に実装されています。 すべてが2つのステップで行われます。
process.hrtimeを使用してナノ秒単位で時間を記録するヘルパー(ミリ秒の日付では不十分です):
function nano() { var time = process.hrtime(); return time[0] * 1e9 + time[1]; }
元の関数を起動し、実行時間を記録するラッパー:
function __profileWrap__(name, callback, args) { var startTime = nano(), result = callback.apply(ctx, args), time = nano() - startTime; logStream.write(name + ',' + time + '\n'); return result; }
実際にラッピングコード:
Object.keys(blocks).forEach(function(funcName) { var base = blocks[funcName]; if (typeof base === 'function') { blocks[funcName] = function() { return __profileWrap__(funcName, base, arguments); }; } });
すべてがシンプルです。
しかし、そのような実装では、再帰呼び出しは正しく処理されませんでした。 たとえば、この間接再帰の場合:
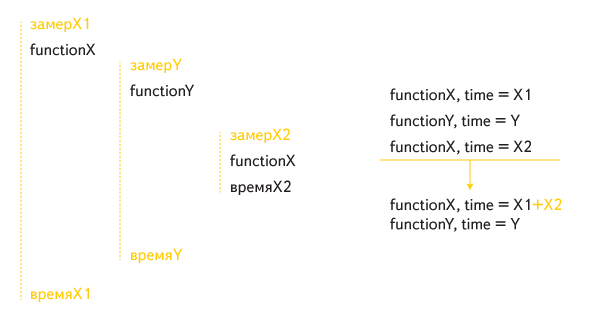
関数Xの合計実行時間には、内部呼び出しが2回含まれています。1回は外部呼び出しの時間の一部として、2回目は個別に実行されます。
再帰呼び出しを正しく処理するには、編集が必要です。
function __profileWrap__(name, callback, args) { if (called[name]) return callback.apply(ctx, args); called[name] = true; // var startTime = nano(), result = callback.apply(ctx, args), time = nano() - startTime; delete called[name]; logStream.write(name + ',' + time + '\n'); return result; }
さらに、マーカーのログにエントリをプロファイルコードに追加しました。これは、1つのリクエストの処理の終了を意味します。 マーカーは、ログエントリと特定のクエリを比較して、関心のあるさまざまなメトリックを読み取るのに役立ちます。
たとえば、関数のランタイムの中央値を計算するためにログを処理するには、次のコードが必要です。
var requests = [], currentRequest = {}; function getMedians() { var funcTime = {}; requests.forEach(function(request) { Object.keys(request).forEach(function(funcName) { // (funcTime[funcName] = funcTime[funcName] || []).push(request[funcName]); }); }); Object.keys(funcTime).forEach(function(funcName) { var arr = funcTime[funcName], value; // while (arr.length < requests.length) arr.push(0); // value = median(arr); if (value > 0) { // funcTime[funcName] = value; } else { // delete funcTime[funcName]; } }); return funcTime; } function writeResults() { var funcMedians = getMedians(); // // : < > <> < > console.log( Object .keys(funcMedians) .sort(function(funcNameA, funcNameB) { return funcMedians[funcNameB] - funcMedians[funcNameA]; }) .map(function(funcName) { return funcName + '\t' + nano2milli(funcMedians[funcName]); }) .join('\n'); ); } function processLine(parsedLine, isItLast) { if (parsedLine.isMarker) { requests.push(currentRequest); currentRequest = {}; } else { // GET- currentRequest[parsedLine.funcName] = (currentRequest[parsedLine.funcName] || 0) + parsedLine.time; } if (isItLast) writeResults(); } // processLine(...)
数千のリクエストでサーバーを起動すると、ブロックが特定されたため、すべてが遅くなりました。 しかし、私はそこでやめたくありませんでした-結果は別のアプローチで確認する必要がありました。
ガイド付き実験No. 2への途中。
箱から出してサンプリング
Node.JSは、この種のプロファイリングをすぐにサポートすることが知られています。 必要なパラメーターでアプリケーションを実行するだけで十分であり、データは指定されたファイルに収集されます。
node --prof —logfile=v8.log my_app.js
man node
-より多くの興味深いオプションが含まれています。
ログは次のようになります。

マルチスレッドコードをプロファイリングするときに、「スタック」行を受け取ったため、ロギングは同期されないことにすぐに注意してください。 これを発見したため、プロジェクトのテスト期間中、PRIVコードのマルチスレッド作業を整理するレイヤーを無効にしました。
ログの読み方の質問に対する答えを見つける過程で、 node-tick-processorモジュールを見つけることができました。 このモジュールはログを解析し、実行済みプログラムの呼び出しの既によく知られている完全なツリーをボトムアップとトップダウンの 2つの形式でコンソールに出力します。各関数の実行時間のみがミリ秒ではなくティックで考慮されます。
tick-processorアルゴリズムの詳細を知り、質問に答えたいと思いました。
- 呼び出しツリーはどのように構築されますか?
- ticksはどういう意味ですか?
- ミリ秒ではなくティックするのはなぜですか?
ティックプロセッサのソースファイルはv8 / toolsのファイルであることがすぐにわかりました。
ログ解析は次のように行われます。
ログはcsvファイルで、各行はパラメーター付きのコマンドです。 主なチームは次のとおりです。
- コードフラグメントをアドレスにバインドするコマンド(共有ライブラリ、コード作成、コード移動)。
- スタックスナップショットに対応するtickコマンド(ティック頻度は、ノードオプション—cpu_profiler_sampling_interval、デフォルトで設定されます
1ミリ秒100ミリ秒)。
コードフラグメントは、Cコードのフラグメント(静的または共有)、またはJSコードのフラグメント(動的)のいずれかです。 すべてのフラグメントは、それぞれ3つのsplaytree構造に格納されます。
目盛りは次のように配置されます。
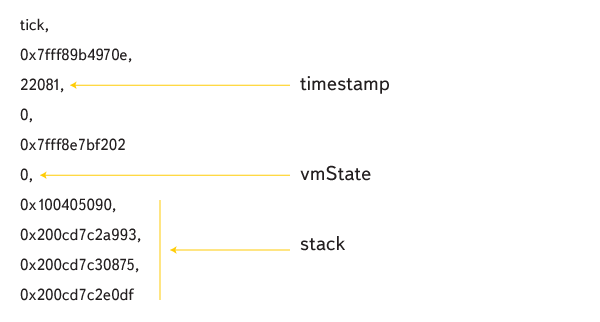
タイムスタンプはティック時間に対応し、 vmState-仮想マシンの状態(0-JS実行)、次にアドレスのスタック。 splaytree構造を使用して、スタック上の関数名が復元されます。
このようにして得られたすべてのスタックは、完全な呼び出しツリーを構成するために一緒に接着されます。
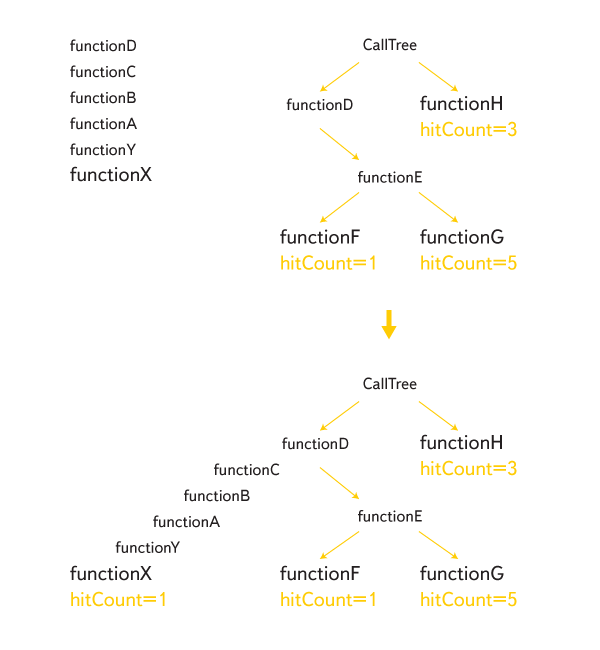
各コールシートには、「この方法で関数が呼び出された回数」という意味のhitCount値が割り当てられます。 プロファイリングが完了すると、すべての内部ノードのヒットカウントが下から上に計算されます。 取得される値は、tick-processorが出力に表示するティックです。
目盛りをミリ秒に変換する明白でありながら粗雑な方法があります。
hitTime = (maxTimestamp - minTimestamp) / (timestamps.length - 1)
blockTime = hitCount * hitTime
実際のティック間の時間は同じではなく、Tの間とT + 1ミリ秒の間に関数Fの内側にいたという事実は、関数が2ミリ秒実行したことを意味しません。 おそらく、これらの時間の間に完全に異なる機能が実行され、そのようなプロファイリング方法は「気付かない」でしょう。 ただし、Chromiumでランタイムが考慮される方法-https://code.google.com/p/chromium/codesearch#chromium/src/third_party/WebKit/Source/devtools/front_end/sdk/CPUProfileDataModel.js&sq=package:クロム&タイプ= cs&l = 31
いずれにせよ、計装方法の結果を確認するために、別のプロファイリング方法が必要でした。
ガイド付き実験番号2。
サンプリングアプローチ
幸いなことに、次のように機能するv8-profilerモジュールを見つけたので、長い間node-tick-processorを詳しく調べる必要はありませんでした。
var profiler = require('v8-profiler'); profiler.startProfiling('profilingSession'); doSomeWork(); console.log(profiler.stopProfiling('profilingSession'));
同時に、次のタイプのオブジェクトがコンソールに出力されます。

v8-profilerを使用する場合のプロファイルコードは次のようになります。
var hitTime; function checkoutTime(node) { var hits = node.hitCount || 0; node.children.forEach(function(childNode) { hits += checkoutTime(childNode); }); logStream.write(node.functionName + ',' + (hits * hitTime) + '\n'); return hits; } function getTime(profile) { var timestamps = profile.timestamps, lastTimestampIndex = timestamps.length - 1; // , hitTime = 1000 * (timestamps[lastTimestampIndex] - timestamps[0]) / lastTimestampIndex; checkoutTime(profile.head); }
インストルメンテーションと同様に、再帰を適切に処理するには編集が必要です。
function stackAlreadyHas(node, name) { return node && (node.functionName === name || stackAlreadyHas(node.parent, name)); } function checkoutTime(node) { var name = node.functionName, hits = node.hitCount || 0; node.children.forEach(function(childNode) { // childNode.parent = name; hits += checkoutTime(childNode); }); // if (!stackAlreadyHas(node.parent, name)) { logStream.write(name + ',' + (hits * hitTime) + '\n'); } return hits; }
ガイド付き実験。 結果
serp-itemブロックの実行時間の中央値は、1つの検索結果に対応するメインブロックです(ページには10のそのような結果が含まれています)。
| 方法 | デスクトップ | タブレット |
|---|---|---|
| 計装 | 38.4ミリ秒 | 35.9ミリ秒 |
| サンプリング | 25.3ミリ秒 | 25.0ミリ秒 |
方法の根本的な違いにより、絶対値は異なると予想されました。
次のステップでは、小さな最適化を使用して、プロファイリングロジックが計測メソッドに与える影響を最小限に抑えることを試みました。 サンプリング方法では、ティック間の時間を短縮しました(setSamplingIntervalメソッド)。 写真は変更されていません。 ツリーのルートに近い呼び出しは同様のインジケーターを取得しましたが、呼び出しがルートから離れるほど、それらはより異なっていました。
結論
より深い呼び出しは、何度も呼び出される関数に対応します。 それらの場合、測定誤差はメソッド誤差と呼び出し回数の積に等しいため、全体像に対する小さな変化は変化しません。
サンプリング方法はしばしばパフォーマンスを過小評価すると想定できます。 計装方法は、建設の性能を過大評価します。 おそらく、低い呼び出しツリーでコードをプロファイリングする場合、両方のメソッドは同様の結果を表示しますが、一般的な場合、これは予期されるべきではありません。
絶対的な結果の違いにもかかわらず、特定のブロックの相対値は近いことが判明しました。 どちらの方法も、同じ「ブレーキ」ブロックのリストを示しました。 「ガイド付き実験」は、PRIVコードをプロファイリングするための「ツール」として設計されました。
一般的な最適化サイクルは次のようになりました。
- ツールを実行します。
- コードのパフォーマンスが必要なレベルに達した場合、終了します。
- ブレーキ機能ブロックを見つけます。
- 機能ブロックを最適化します。
- 最初に。
その結果、多くのブロックを最適化し、更新されたコードは古い実装に比べて速度が低下しなくなりました。
serp-itemの現在の数値は次のとおりです(思い出すと、検索結果のページ全体のインジケータは10倍することで得られます)。
| 方法 | デスクトップ | タブレット |
|---|---|---|
| 計装 | 35.1ミリ秒(-3.3) | 34.8ミリ秒(-1.1) |
| サンプリング | 24.9ミリ秒(-0.4) | 24.8ミリ秒(-0.2) |
結論の代わりに
厳密に言えば、単純なケースがありました-単純なフラット関数のプロファイリングです。 オブジェクトと継承または非同期コードを使用してコードをプロファイリングする場合、依存関係を理解し、プログラムの合計実行時間に対する個々の部分の寄与について結論を出すことははるかに困難です。
より複雑なコードをプロファイルするタスクがある場合は、適切なソリューションがあります。これについては、ここで間違いなく説明します。