趣味が1つあります。車輪の再発明が本当に好きです。
今日、そのような自転車の発明についてお話ししたいと思います。
データの配列の並べ替えは、最初の年からはほど遠いタスクです。 それは私たちを工科大学の最初のコースから、特に幸運な人たちに、そして学校のベンチから私たちを悩ませます。 通常、これらの方法は、「バブル」、「分割」、「高速」、「挿入」などでソートされます。

たとえば、ある大手IT会社で、「バブル」ソート方法の同様の実装が教えられました。 この方法は、経験豊富なプログラマーがどこでも使用していました。
だから、比較なしのソート方法(ビット単位、ブロックなど)にほとんど注意が払われないのはなぜだろうといつも思っていました。 実際、このようなメソッドは高速アルゴリズムのクラスに属し、O(N)で実行され、読み取りと置換の数、および正常に選択されたデータを線形時間で実行できます。 もちろん、これらのメソッドは実際には何も比較しないため、一部の抽象オブジェクトのソートにはあまり適していませんが、値から何らかの放電を行います(必要に応じてオブジェクトをソートすることもできます)。 ただし、実際には、ほとんどの並べ替えタスクは、通常のプリミティブの配列(文字列、数値、ビットフィールドなど)の順序になります。比較のほとんどはバイト単位です。
たとえば、ポケットソートの方法について説明する場合、Wikipediaでは、多数の不明瞭な要素や要素の内容からバスケット番号を取得できないという機能ではうまく機能しないと主張しています。 このアルゴリズムでは、ソートされたデータの性質を知る必要があります。 また、ポケットを整理することも追加で必要になり、プロセッサの時間とメモリが消費されます。 ただし、すべての欠点にもかかわらず、理論的にはアルゴリズムの実行時間は線形になる傾向があります。 どういうわけかこれらの欠点を解決し、線形ランタイムを達成することは可能ですか?
そこで、O(N)の読み取りと置換の数、および実行時間が線形に近い「ソート」アルゴリズムに注目します。
このアルゴリズムは、ソースデータを所定の場所に並べ替え、追加のメモリを使用しません。 言い換えれば、O(N)でソートし、読み取り、移動、およびメモリーの数O(1)にします。
ソート方法は、ポケットソート方法に基づいています。 特定の実装について説明する場合、要素のより効率的な比較のために、ポケットバイト数は256に選択されます。反復(パス)の数は、1要素のバイト単位の長さに依存します。 つまり 順列の総数はO(N * K)に等しくなります。Kは1つの要素の長さ(バイト数)です。
並べ替えには、特別なバッファ「ポケット」を使用する必要があります。 これは長さ256の配列で、各要素にはポケットのサイズとポケットの境界への参照が含まれます。これは、元の配列のポケットの最初の要素へのポインタです。 最初に、バッファはゼロで初期化されます。
したがって、各i番目の反復のソートアルゴリズムは4つのステージで構成されます。
第一段階。 ポケットサイズカウント
最初の段階で、ポケットの寸法が計算されます。 バッファーを使用します。ここでは、各ポケットの要素数のカウンターが保持されます。 すべての要素を調べて、i番目のバイトの値を取得し、対応するポケットのカウンターをインクリメントします。
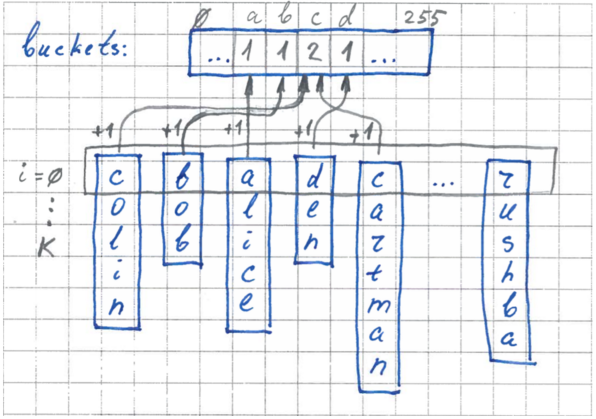
2段階。 境界
これで、各ポケットの寸法がわかったので、各ポケットの元の配列の境界を明確に設定できます。 バッファを調べて境界を設定します-各ポケットの要素へのポインタを設定します。

3段階。 再配置
2番目のパスでは、元の配列の要素を再配置して、各要素がその場所、つまりポケットに収まるようにします。
置換アルゴリズムは次のとおりです。
- 配列のすべての要素を順番に調べます。 現在の要素について、i番目のバイトを取得します。
- 現在の要素がその場所(ポケット内)にある場合は、すべて問題ありません。次の要素に進みます。
- 要素がその場所にない場合-対応するポケットがさらに配置されている場合、この遠いポケットに配置されている要素で要素を再配置します。 適切なポケットのある適切な要素に出会うまで、この手順を繰り返します。 交換を行うたびに、現在の要素をポケットに入れて再分析しません。 したがって、順列の数がNを超えることはありません。
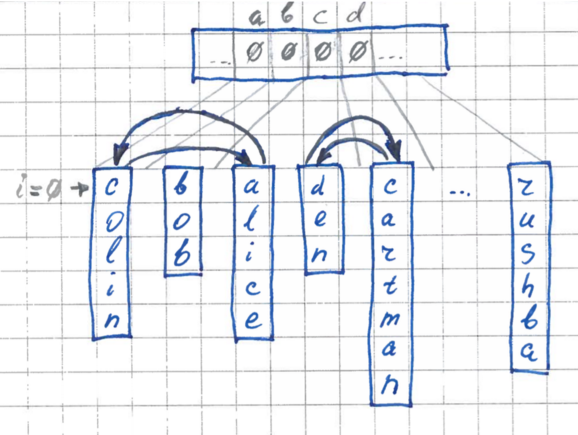
各順列中に、対応するポケットのバッファー内のカウンターがデクリメントされ、実行が終了すると、バッファーは再びゼロで満たされ、他の反復で使用できるようになります。
順列の数はN-要素の数を超えないため、順列プロセスは、最初の段階と同様に、理論的には線形時間で実行されます。
第4ステージ。 再帰降下
そして最後の段階。 次に、形成された各ポケット内の要素を再帰的にソートします。 内部の繰り返しごとに、現在のポケットの境界を知るだけで済みます。 追加のメモリを使用しないため(現在のポケットの長さに関する情報はありません)、内部反復に進む前に、要素を再度調べて、現在のポケットの長さを計算します。

必要に応じて、アルゴリズムをさらに最適化し、ポケットの長さに関する情報を削除しないことで、これを回避できます。 ただし、これには追加のメモリを使用する必要があります。 特に、O(log(K)* M)、ここでMはポケットの数(この場合は常に256)、Kは1つの要素の長さ(バイト)です。
このアルゴリズムの特徴は、最初のパス(ステップ1)で、最初と最後の空でないポケット(ポインターpBucketLow、pBucketHigh)の数がさらに記憶されることです。 将来的には、これにより2番目と3番目の段階で時間を節約できます。 このような最適化では、ほとんどのデータが特定の範囲のデータに集中しており、多くの場合、いくつかの境界が定義されていると想定しています。 たとえば、文字列データは多くの場合、文字AZで始まります。 番号(IDなど)も通常、ある範囲に制限されます。
下部と上部の空でないポケットの数が一致する場合、追加の最適化を行うこともできます(pBucketLow == pBucketHigh)。 これは、i番目のレベルのすべての要素が同じバイトを持ち、すべての要素が1つのポケットに入ることを示唆しています。 この場合、すぐに反復を中断して(ステップ2、3、4をスキップ)、次のステップに進むことができます。
アルゴリズムは、別のかなり一般的な最適化も使用します。 反復を開始する前に、要素の数が少ない場合(特に8未満)、非常に単純な並べ替え(バブル並べ替えなど)を実行することが最適です。
実装
Cでの上記のアルゴリズムの実装は、github: github.com/denisskin/cflashsortで利用できます。
データを並べ替えるには、パラメーターとしてget_byte(void *、int)関数(要素のi番目のバイトを取得する関数)へのポインターを受け取るflash_sort関数を使用する必要があります。
たとえば、行をソートします。
// sort array of strings char *names[10] = { "Hunter", "Isaac", "Christopher", "Bob", "Faith", "Alice", "Gabriel", "Denis", "****", "Ethan", }; static const char* get_char(const void *value, unsigned pos) { return *((char*)value + pos)? (char*)value + pos : NULL; } flashsort((void**)names, 10, get_char);
厳密に指定された長さのデータをソートするためのflashsort_const関数もあります。
たとえば、数字:
// sort integer values int nums[10] = {9, 6, 7, 0, 3, 1, 3, 2, 5, 8}; flashsort_const(nums, 10, sizeof(int), sizeof(int));
同じ関数を使用して、構造体の配列をキーでソートできます。
例:
// sort key-value array by key typedef struct { int key; char *value; } KeyValue; KeyValue names[10] = { {8, "Hunter"}, {9, "Isaac"}, {3, "Christopher"}, {2, "Bob"}, {6, "Faith"}, {1, "Alice"}, {7, "Gabriel"}, {4, "Denis"}, {0, "none"}, {5, "Ethan"}, }; flashsort_const(names, 10, sizeof(KeyValue), sizeof(names->key));
flashsort_const関数は 、明白な理由で、その対応物-特別なマクロを使用して宣言された関数よりも少し遅くなります。 この場合、要素の順列と要素のi番目のバイトの取得ははるかに高速になります。
たとえば、次のようにマクロを使用して数値を並べ替えるための関数を宣言できます。
// define function flashsort_int by macro #define FLASH_SORT_NAME flashsort_int #define FLASH_SORT_TYPE int #include "src/flashsort_macro.h" int A[10] = {9, 6, 7, 0, 3, 1, 3, 2, 5, 8}; flashsort_int(A, 10);
ベンチマーク
ベンチマークは、比較のためにqsortソートが追加されている同じリポジトリにもあります。
cd benchmarks gcc ../src/*.c benchmarks.c -o benchmarks.o && ./benchmarks.o
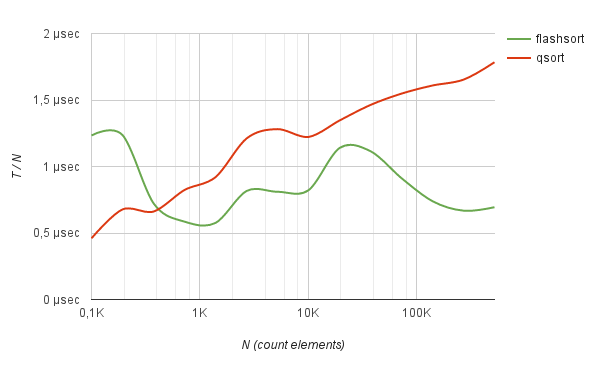
その結果、 flash_sortメソッドは 、ランダムに分散されたデータを処理する際にqsortと比較して優れたパフォーマンスを発揮します。 たとえば、500Kの整数の配列の並べ替えは、クイック並べ替えよりも2.5倍高速です。 ベンチマークからわかるように、平均ソート時間をNで割った値は、要素の数が増えても実際には変化しません。
整数のベンチマークソート
------------------------------------------------------------------------------------------- Count Flash-sort | Quick-sort | elements Total time | Total time | N Tf Tf / N | Tq Tq / N | Δ ------------------------------------------------------------------------------------------- 100 0.000012 sec 1.225 µs | 0.000004 sec 0.428 µs | -65.10 % 194 0.000016 sec 0.814 µs | 0.000009 sec 0.439 µs | -46.04 % 374 0.000026 sec 0.690 µs | 0.000023 sec 0.604 µs | -12.40 % 724 0.000043 sec 0.592 µs | 0.000058 sec 0.795 µs | +34.29 % 1398 0.000099 sec 0.707 µs | 0.000155 sec 1.112 µs | +57.28 % 2702 0.000204 sec 0.753 µs | 0.000300 sec 1.111 µs | +47.44 % 5220 0.000410 sec 0.786 µs | 0.000620 sec 1.187 µs | +51.02 % 10085 0.000845 sec 0.838 µs | 0.001254 sec 1.243 µs | +48.41 % 19483 0.002205 sec 1.132 µs | 0.002672 sec 1.372 µs | +21.21 % 37640 0.004242 sec 1.127 µs | 0.005436 sec 1.444 µs | +28.15 % 72716 0.006886 sec 0.947 µs | 0.011171 sec 1.536 µs | +62.23 % 140479 0.011156 sec 0.794 µs | 0.022899 sec 1.630 µs | +105.26% 271388 0.018773 sec 0.692 µs | 0.045749 sec 1.686 µs | +143.70% 524288 0.037429 sec 0.714 µs | 0.093858 sec 1.790 µs | +150.76%
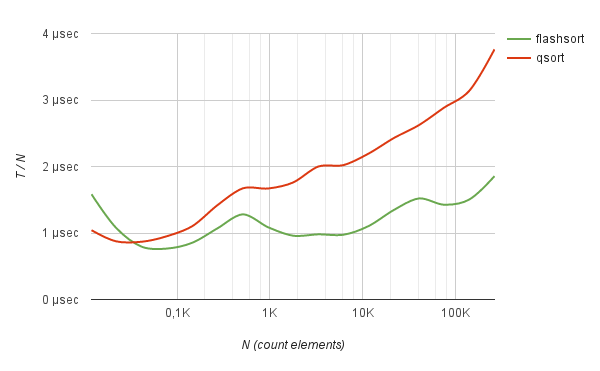
特定の長さのランダムな文字列を並べ替えると、同様の結果が得られます。 たとえば、base64でエンコードされたランダムハッシュのリスト。
ベンチマークbase64ハッシュのソート
--------------------------------------------------------------------------------------------- Count Flash-sort | Quick-sort | elements Total time | Total time | N Tf Tf / N | Tq Tq / N | Δ --------------------------------------------------------------------------------------------- 147 0.000009 sec 0.609 µs | 0.000010 sec 0.694 µs | +13.97 % 274 0.000025 sec 0.918 µs | 0.000027 sec 0.991 µs | +7.95 % 512 0.000053 sec 1.036 µs | 0.000061 sec 1.195 µs | +15.37 % 955 0.000098 sec 1.024 µs | 0.000135 sec 1.416 µs | +38.32 % 1782 0.000164 sec 0.921 µs | 0.000279 sec 1.566 µs | +70.04 % 3326 0.000315 sec 0.947 µs | 0.000581 sec 1.745 µs | +84.31 % 6208 0.000629 sec 1.013 µs | 0.001210 sec 1.949 µs | +92.39 % 11585 0.001325 sec 1.144 µs | 0.002378 sec 2.053 µs | +79.50 % 21618 0.002904 sec 1.343 µs | 0.004712 sec 2.180 µs | +62.26 % 40342 0.006132 sec 1.520 µs | 0.009752 sec 2.417 µs | +59.03 % 75281 0.010780 sec 1.432 µs | 0.019778 sec 2.627 µs | +83.47 % 140479 0.023484 sec 1.672 µs | 0.043534 sec 3.099 µs | +85.37 % 262144 0.044967 sec 1.715 µs | 0.082878 sec 3.162 µs | +84.31 %
ただし、この方法は明確な利点なしに機能します。ランダムに混在する英語の単語を並べ替えるときは、クイックソートよりも少し高速です。
英語の単語のベンチマークソート
--------------------------------------------------------------------------------------------- Count Flash-sort | Quick-sort | elements Total time | Total time | N Tf Tf / N | Tq Tq / N | Δ --------------------------------------------------------------------------------------------- 140 0.000016 sec 1.166 µs | 0.000014 sec 0.993 µs | -14.85 % 261 0.000030 sec 1.168 µs | 0.000029 sec 1.114 µs | -4.59 % 485 0.000055 sec 1.139 µs | 0.000061 sec 1.259 µs | +10.59 % 901 0.000141 sec 1.565 µs | 0.000158 sec 1.750 µs | +11.82 % 1673 0.000269 sec 1.608 µs | 0.000315 sec 1.884 µs | +17.17 % 3106 0.000536 sec 1.726 µs | 0.000655 sec 2.110 µs | +22.27 % 5766 0.001013 sec 1.756 µs | 0.001263 sec 2.191 µs | +24.76 % 10703 0.002007 sec 1.875 µs | 0.002525 sec 2.359 µs | +25.85 % 19868 0.004152 sec 2.090 µs | 0.005150 sec 2.592 µs | +24.04 % 36880 0.008459 sec 2.294 µs | 0.010266 sec 2.784 µs | +21.36 % 68458 0.017460 sec 2.550 µs | 0.021423 sec 3.129 µs | +22.70 % 127076 0.035615 sec 2.803 µs | 0.041683 sec 3.280 µs | +17.04 % 235885 0.075747 sec 3.211 µs | 0.086523 sec 3.668 µs | +14.23 %
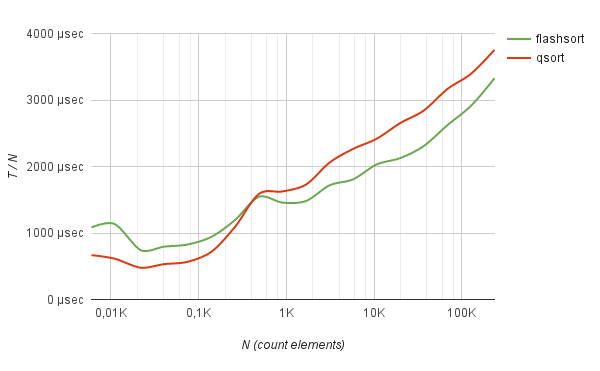
良くない方法は、頻繁に繰り返されるデータを操作することで現れます。 たとえば、フラッシュソートを使用して50万個のIPアドレスのログ(実際の生活から取得)を並べ替えると、クイックソートの5倍の速度で動作します。
ベンチマークIPアドレスログのソート
--------------------------------------------------------------------------------------------- Count Flash-sort | Quick-sort | elements Total time | Total time | N Tf Tf / N | Tq Tq / N | Δ --------------------------------------------------------------------------------------------- 107 0.000010 sec 0.953 µs | 0.000011 sec 1.056 µs | +10.78 % 208 0.000013 sec 0.639 µs | 0.000010 sec 0.480 µs | -25.00 % 407 0.000024 sec 0.584 µs | 0.000033 sec 0.812 µs | +39.01 % 793 0.000039 sec 0.493 µs | 0.000073 sec 0.915 µs | +85.61 % 1547 0.000080 sec 0.517 µs | 0.000211 sec 1.367 µs | +164.15% 3016 0.000169 sec 0.560 µs | 0.000512 sec 1.697 µs | +202.80% 5881 0.000308 sec 0.523 µs | 0.000962 sec 1.636 µs | +212.67% 11466 0.000548 sec 0.478 µs | 0.001812 sec 1.581 µs | +230.48% 22354 0.001034 sec 0.463 µs | 0.004191 sec 1.875 µs | +305.26% 43584 0.002109 sec 0.484 µs | 0.008693 sec 1.994 µs | +312.26% 84974 0.004411 sec 0.519 µs | 0.016003 sec 1.883 µs | +262.81% 165670 0.008837 sec 0.533 µs | 0.037358 sec 2.255 µs | +322.75% 323000 0.016046 sec 0.497 µs | 0.081251 sec 2.516 µs | +406.36% 629739 0.030895 sec 0.491 µs | 0.164283 sec 2.609 µs | +431.75%
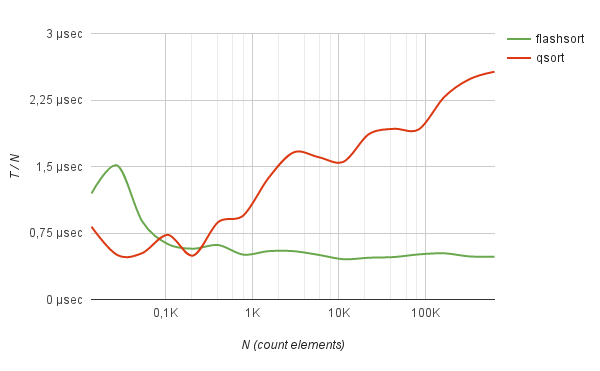
さらに、このようなデータでは、並べ替え時間は、並べ替えられるアイテムの数から厳密に直線的に増加します。
結論として
ここで紹介するソート方法は常に厳密にO(N)の読み取りと置換を行うという事実にもかかわらず、すべての場合のすべてのデータ型について、アルゴリズムが線形時間で機能すると予想するのは単純です。 実際には、作業の速度がソートされるデータの性質に依存することは明らかです。
一般的な場合のアルゴリズムの実行は、要素の順列の段階でメモリのランダムセクションにアクセスする必要がある場合にのみ、非線形時間で発生します。
ただし、ここで説明する方法を最適化する余地はまだあると思います。 たとえば、アルゴリズムの最初の段階では、バスケットに入る要素の数をカウントすることに加えて、より複雑な統計を保持し、それに基づいて、バスケット内の要素を並べ替えるためのさまざまな方法を選択することができます。 最終的には、メモリまたはディスク上のデータの特定の物理表現の最適化だけでなく、さまざまな並べ替え方法のアプローチを組み合わせたハイブリッドアルゴリズムを開発することも、最終的な解決策になると確信しています。
ただし、これらの問題は記事の範囲を超えており、その目的は、「比較ではなく」ソート方法の可能性を純粋な形で示すことだけでした。 いずれにせよ、データの並べ替えの問題を終わらせるのは時期尚早だと思います。