array
-複雑で柔軟なハイブリッド。
list
と
linked map
動作を組み合わせ
linked map
。 しかし、PHPは実用的なアプローチを採用しているため、すべてに使用します。理論的な推論ではなく実用的な推論に基づいて、問題を解決するための非常に正確で健全かつ現実的な方法を提供するためです。
array
は、あなたが仕事をすることを可能にしますが、彼らはコンピューターサイエンスの講義でそれについてとても話します。 しかし、残念ながら、複雑さには柔軟性が伴います。
PHPの最新リリースは、コミュニティで多くの興奮を引き起こしました。 新しい機能の使用を開始し、 パフォーマンスが2倍になるまで待ちきれませんでした。 これが発生した理由の1つは、
array
構造が再設計されたことです。 しかし、アレイは依然として「すべてに最適化された」という原則を順守しています。 何にも最適化されていない」、すべてがまだ完璧ではない、改善の機会があります。
SPLデータ構造はどうですか?残念ながら...彼らはひどいです。 PHP7以前は、それらは_some_の利点を提供していましたが、SPLを使用しても実用的な意味をなさないようになりました。
なぜそれらを修正して改善できないのですか?はい、できますが、それらの設計と実装は非常に貧弱なので、より新しい代替品を見つける方が良いと思います。
「SPLデータ構造は恐ろしく設計されています。」
- アンソニー・フェラーラ
はじめに :
php-ds
は、データ構造を追加するPHP7の拡張機能です。 この投稿では、それぞれの動作、パフォーマンス、および利点について簡単に説明します。 また、最後に、予想される質問に対する回答のリストが表示されます。
Github : https : //github.com/php-ds
名前空間:
Ds\
インターフェース:
Collection
、
Sequence
、
Hashable
クラス:
Vector
、
Deque
、
Stack
、
Queue
、
PriorityQueue
、
Map
、
Set
収集
Collection
は、
foreach
、
echo
、
count
、
print_r
、
var_dump
、
serialize
、
json_encode
、および
clone
json_encode
一般的な機能を含む基本的なインターフェースです。
シーケンス
Sequence
は、単一の線形次元に編成された要素の動作を記述します。 一部の言語では、このような構造は
List
と呼ばれます。 一部の機能を除いて、増分キーを使用する
array
似ています:
- 値は常に
[0, 1, 2, …, size - 1]
としてインデックス付けする必要があります - 取得または追加により、連続するすべての値のインデックスが更新されます
- インデックス
[0, size - 1]
からのみ値へのアクセスをサポートします
ユースケース
-
array
をリストとして使用したい場所(キーなし) -
SplDoublyLinkedList
およびSplFixedArray
より効率的な代替手段
ベクトル
Vector
は、値を連続バッファーに結合し、自動的に増減する
Sequence
です。 これは最も効率的なシーケンシャルデータ構造です。要素のインデックスはバッファ内のインデックスの直接的な反映であり、ベクトルを増やしてもパフォーマンスには影響しません。
強み
- 非常に低いメモリ消費
- 非常に高速な反復
-
get
、set
、push
、およびpop
複雑度はO(1)
欠点
-
insert
、remove
、shift
、およびunshift
複雑度はO(n)
Photoshopの一番の構造はベクターでした。
- ショーン・ペアレント 、 CppCon 2015
Deque (二重接続キュー)
Deque
(「デッキ」と発音)は、一連の値を連続バッファーに結合したもので、自動的に増減します。 名前は、 両端キューの一般的な略語です。
Ds\Queue
内で使用されます。
2つのポインターを使用して、頭と尾を追跡します。 ポインターがあると、他の要素を移動してスペースを解放することなく、バッファーの終わりと始まりを変更できます。 これにより、
shift
と
shift
unshift
非常に高速になり、
Vector
でさえ競合できなくなります。
インデックスによって値にアクセスするには、バッファー内の対応する位置を計算する必要があります:
((head + position) % capacity)
。
強み
- 非常に低いメモリ消費
-
get
、set
、push
、pop
、shift
、およびunshift
複雑度はO(1)
欠点
-
insert
、remove
はO(n)
複雑さを持ちます - バッファー容量には2の
2ⁿ
(2ⁿ
)が必要です
次のベンチマークは、
push
2ⁿ乱数操作に使用される合計経過時間とメモリを示しています。
array
、
Ds\Vector
および
Ds\Deque
迅速に
SplDoublyLinkedList
しますが、
SplDoublyLinkedList
は結果を2倍以上安定して表示します。
SplDoublyLinkedList
は各値にメモリを
SplDoublyLinkedList
割り当てるため、メモリの予想される増加が発生します。
array
および
Ds\Deque
、その実装において、メモリを部分的に割り当てて2要素の十分なボリュームを維持します。
Ds\Vector
の成長因子は1.5であり、これによりメモリ割り当て数が増加しますが、一般的には消費量が少なくなります。
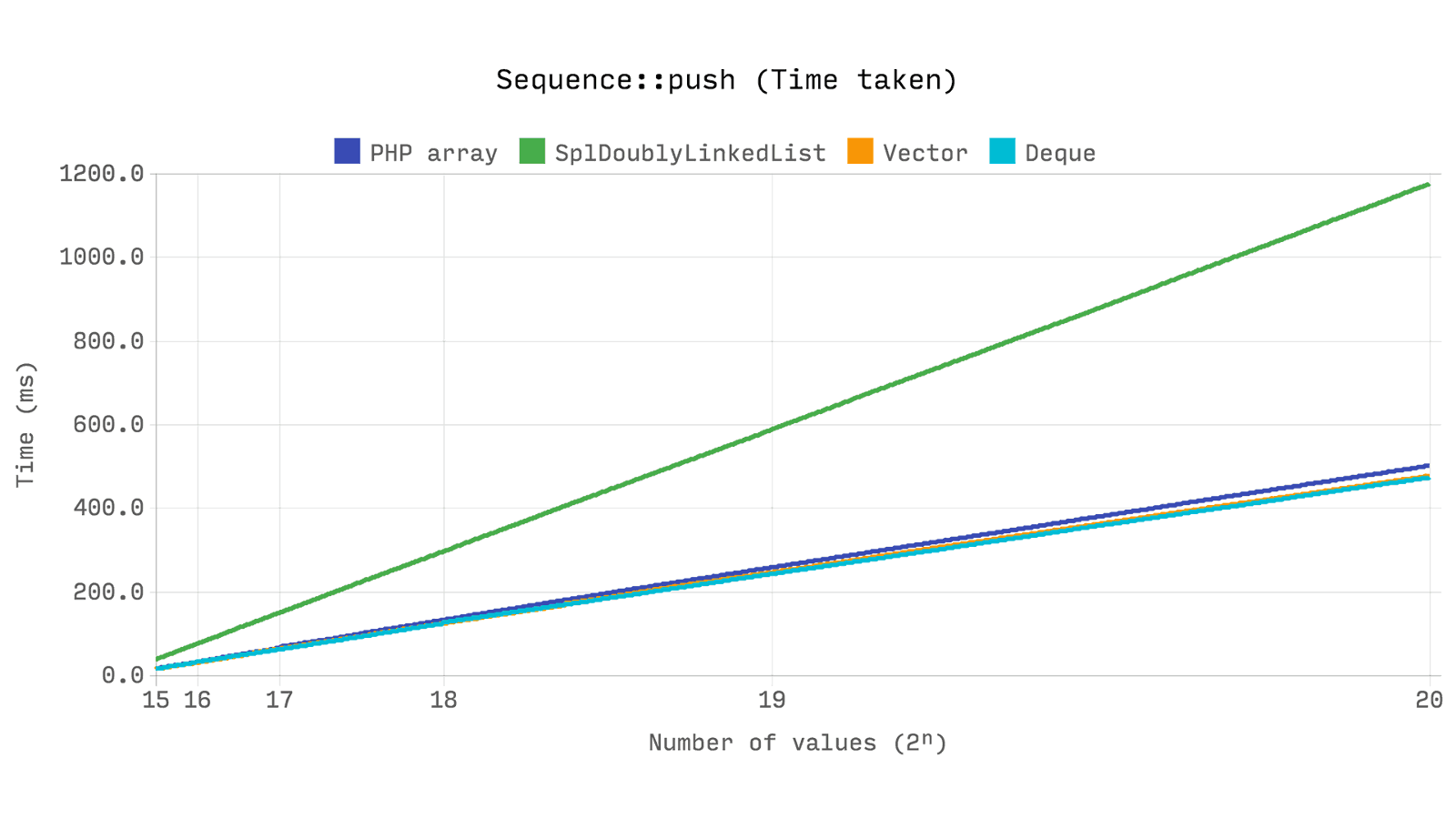
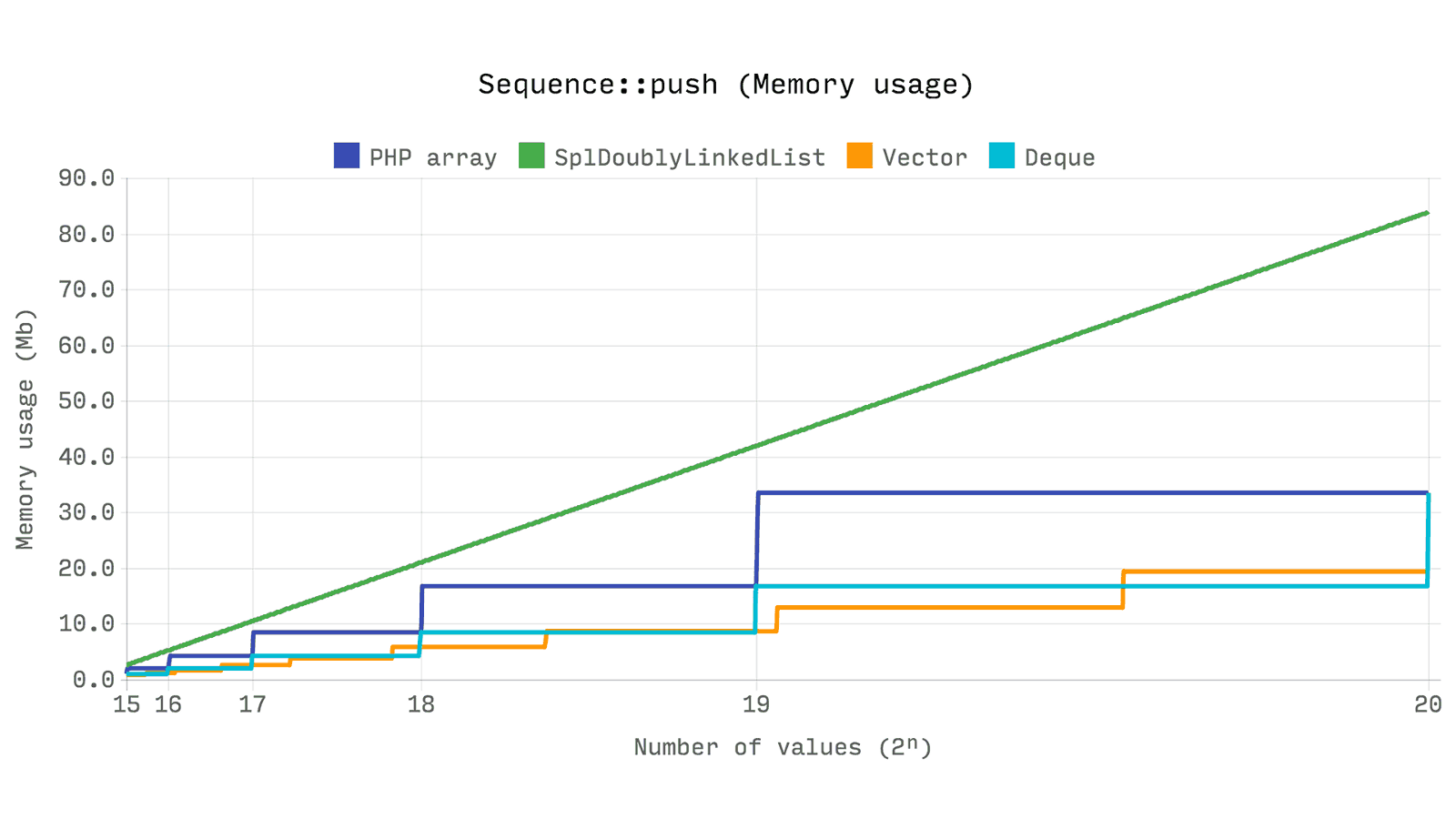
次のベンチマークは、2ⁿの値のシーケンスで単一の要素のシフトを解除するのにかかる時間を示しています。 値の設定に必要な時間は考慮されません。
グラフは、
array_unshift
複雑さが
O(n)
あることを示しています。サンプルサイズが2倍になると、
unshift
必要な時間
unshift
ます。 これは、範囲
[1, size - 1]
各数値メトリックを更新する必要があるためです。
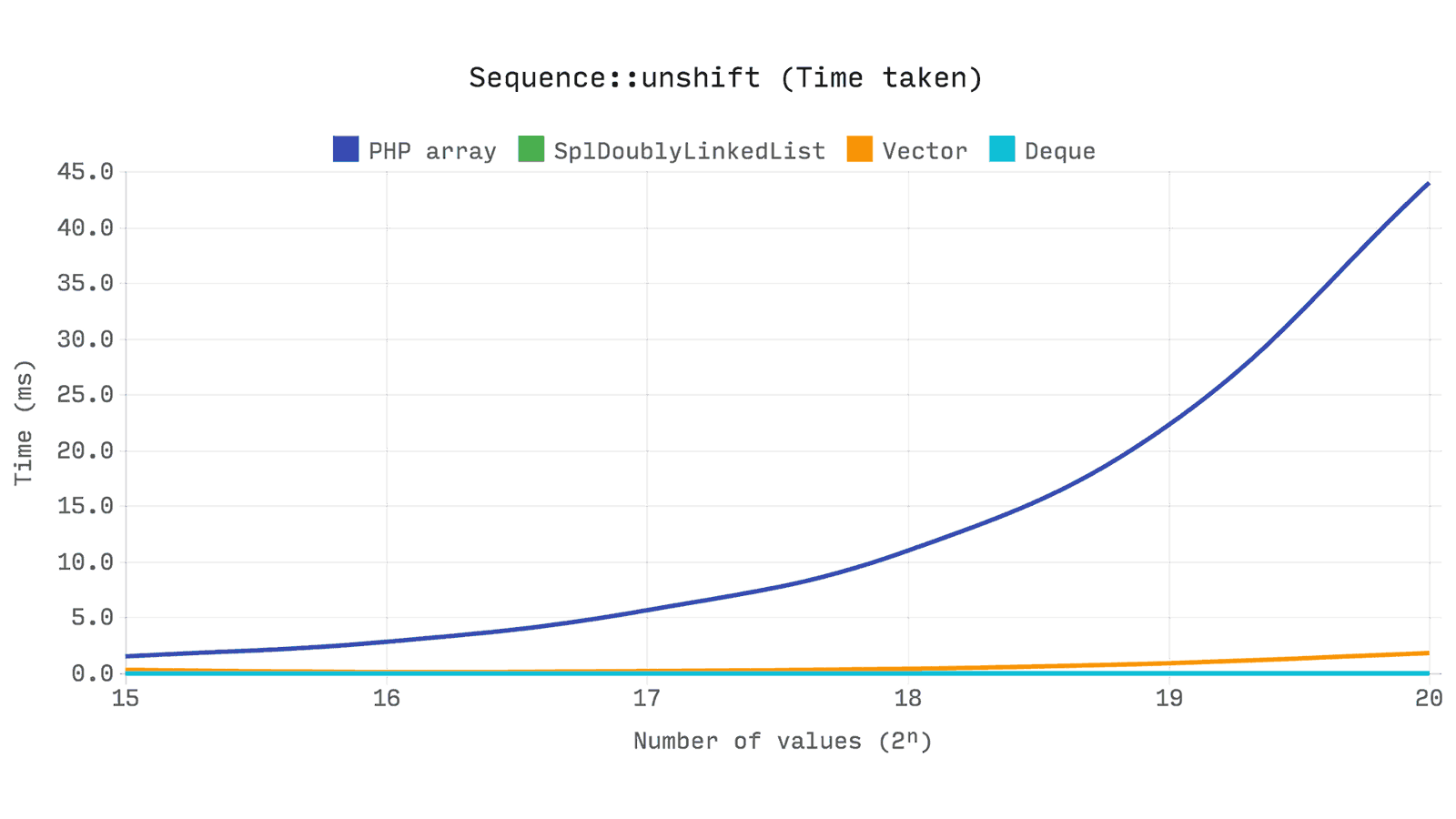
しかし、
Ds\Vector::unshift
O(n)
でもあるので、なぜそんなに速いのですか?
array
は、キーとハッシュとともに各値を
bucket
に保存することに注意してください。 したがって、インデックスが数値の場合、各要素をチェックしてハッシュを更新する必要があります。 実際、
array_unshift
はこれに新しい配列を割り当て、すべての値がコピーされると古い配列を置き換えます。
ベクトルでは、値のインデックスはバッファ内のインデックスの直接表示なので、[1、サイズ-1]の範囲の各値を1ポジション分右に移動するだけです。 これは、1つの
memmove
操作で実行されます。
Ds\Deque
および
SplDoublyLinkedList
は非常に高速です。これは、値の
SplDoublyLinkedList
の時間がサンプルサイズの影響を受けないため
unshift
。 その複雑さは
O(1)
ます。
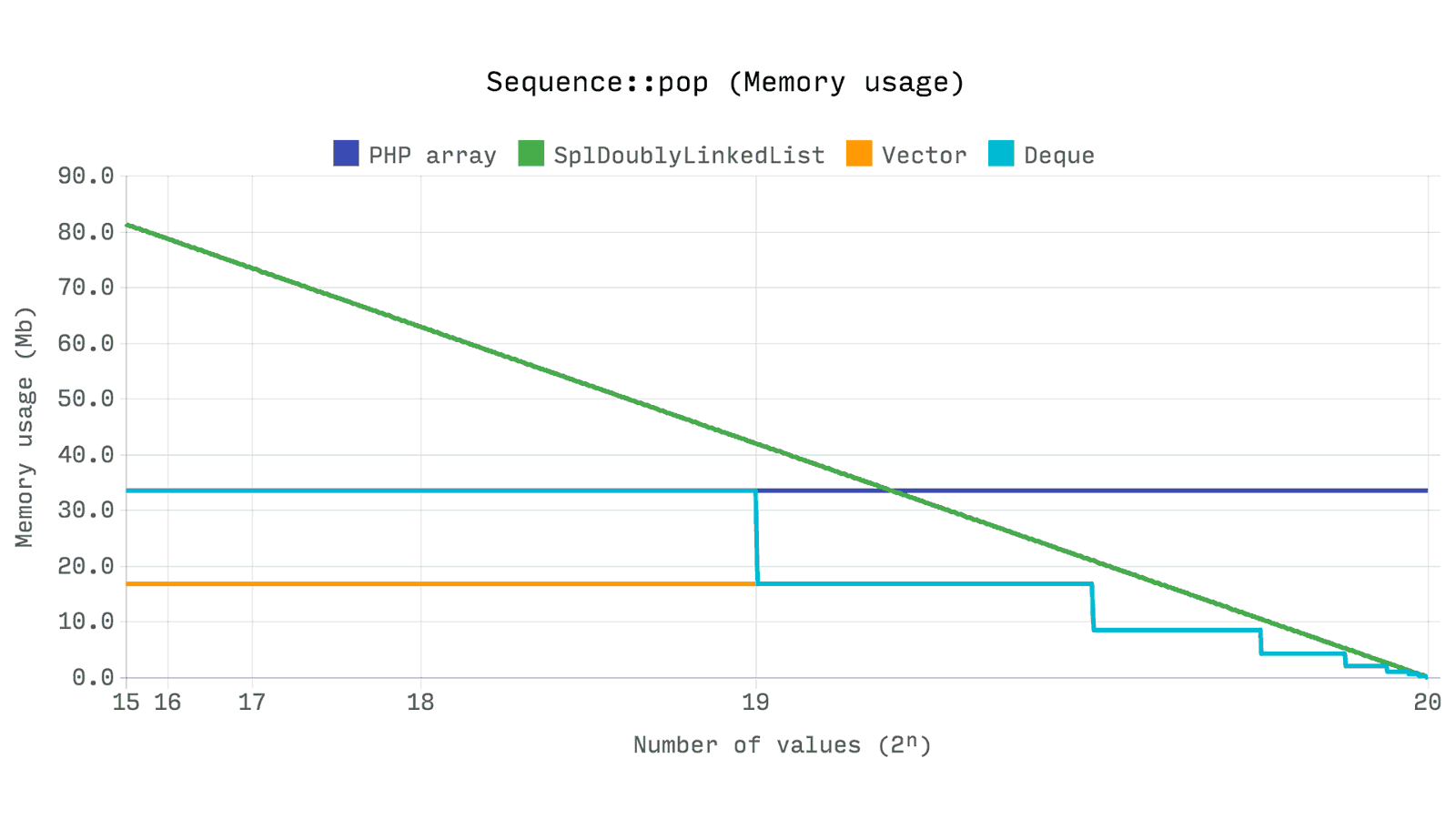
次のテストでは、2インチの
pop
操作に使用されるメモリ量を示します。 つまり、2ⁿからゼロにサイズ変更する場合
ここで興味深いのは、サイズが大幅に縮小された場合でも、
array
常に割り当てられたメモリを保持することです。
Ds\Vector
および
Ds\Deque
は、サイズが現在の潜在能力の4分の1を下回ると
Ds\Deque
割り当てられたリソースを
Ds\Deque
できます。
SplDoublyLinkedList
は、サンプルから削除するたびにメモリを解放するため、直線的な減少を観察できます。
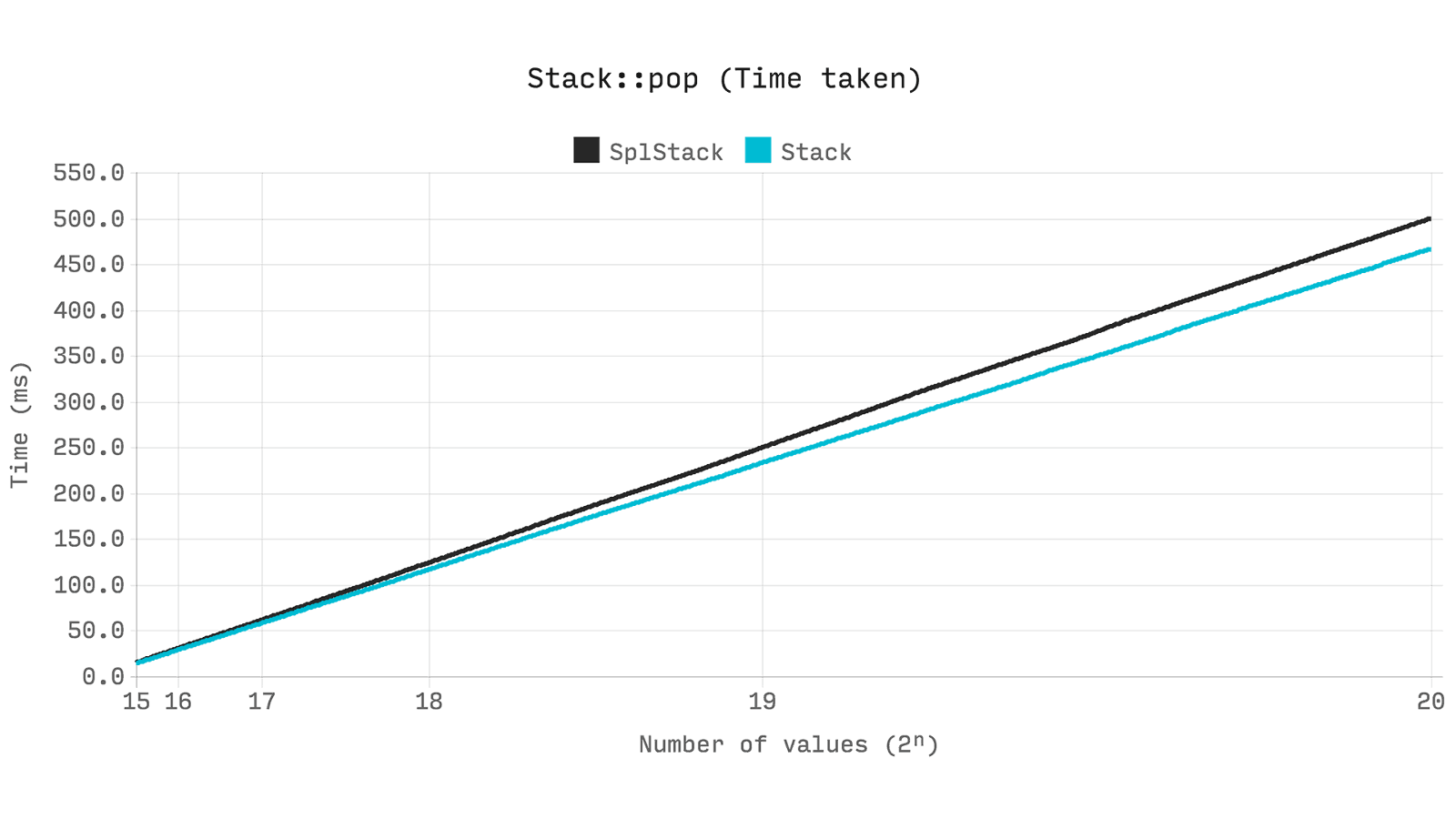
スタック
スタックは、構造の最上位の値のみにアクセスできる「後入れ先出し」または「LIFO(後入れ先出し)」の原則に基づいて編成されたコレクションです。 あなたはそれを動的能力を持つ武器屋と考えることができます。
Ds\Stack
は、内部で
Ds\Vector
使用します。
SplStack
継承するため、パフォーマンスは、以前のテストで
Ds\Vector
と
SplDoublyLinkedList
を比較した場合と同等になります。 2ⁿの
pop
操作を実行し、2ⁿからゼロにサイズ変更するのに必要な時間を見てみましょう。
キュー
キューは、要素へのアクセスのパラダイム「先着順」 (「FIFO」、「先入れ先出し」 )を持つデータ型です。 このコレクションを使用すると、追加された順序で要素にアクセスできます。 その名前はそれ自体を物語っています。店のレジで並んでいる人々の列として構造を想像してください。
Ds\Queue
は、
Ds\Deque
使用します。
SplQueue
から継承されるため、パフォーマンスは、前のベンチマークで示した
Ds\Deque
と
SplDoublyLinkedList
を比較することと同等です。
PriorityQueue (プライオリティキュー)
プライオリティキューは、シンプルキューに非常によく似ています。 アイテムは指定された優先度でキューに入れられ、最も優先度の高い値が常に最前面になります。 優先度キューの直接列挙は非常に破壊的であり、
pop
操作の順次呼び出しであり、これは非常に高価な操作です。
優先度キューの実装はmax-heapを使用します 。
「先着順」の原則は、同じ優先度の値に対して維持されるため、同じ優先度の値のグループは通常のキューと見なすことができます。
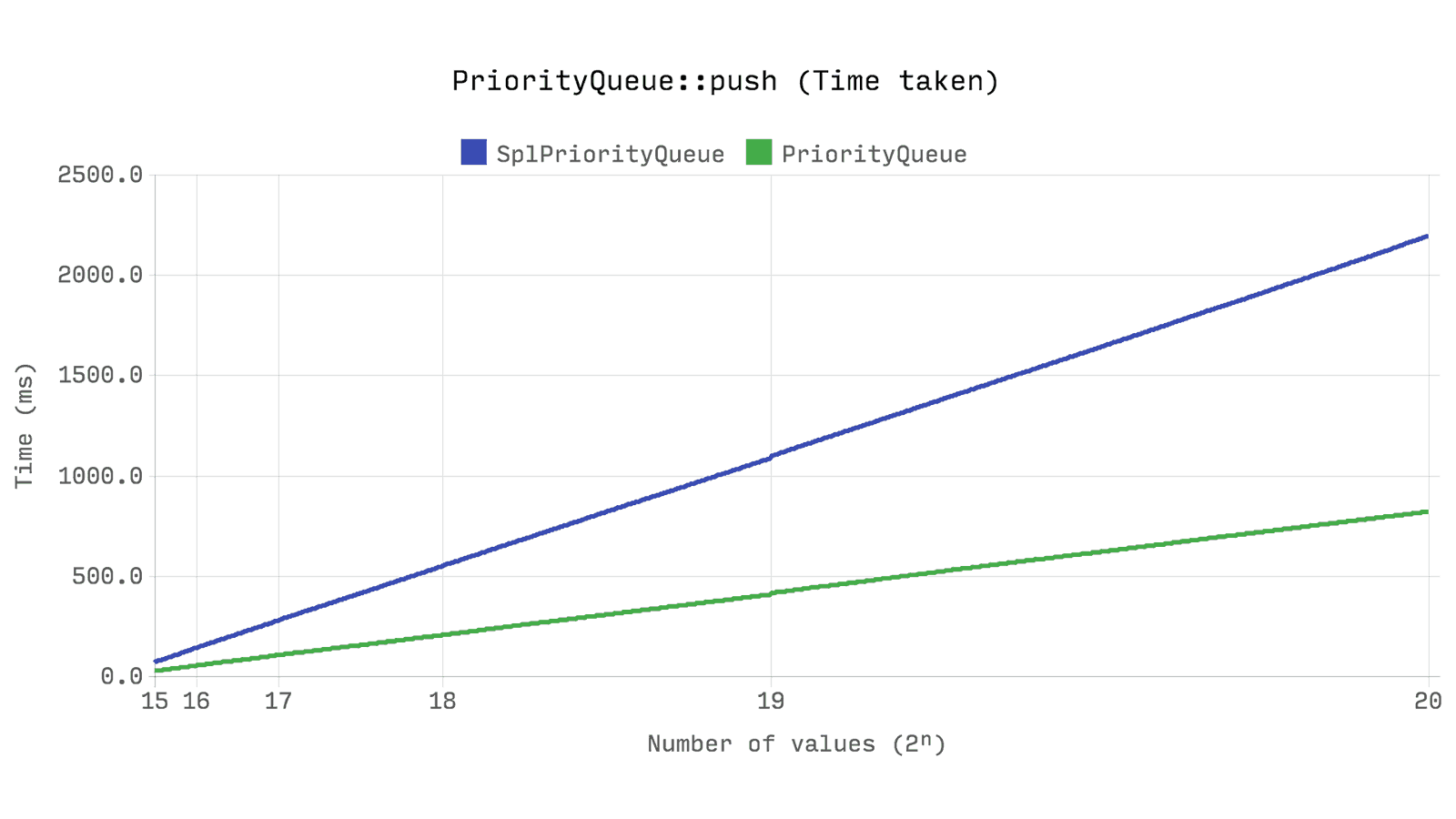
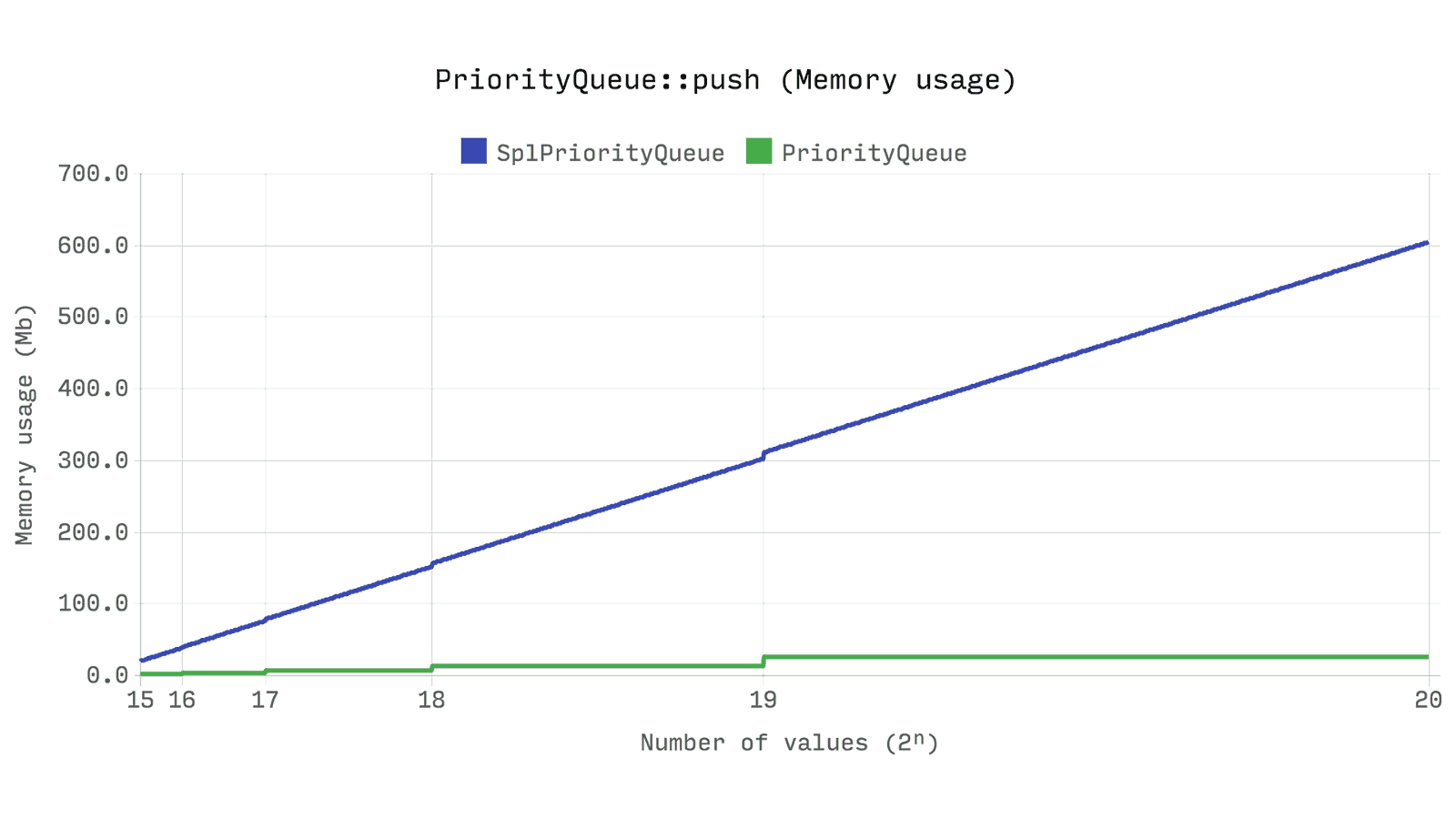
パフォーマンスはどうですか? 次のベンチマークは、キュー内のランダムな優先度で
push
2ⁿ乱数操作に必要な時間とメモリを示しています。 各テストに同じ乱数が使用されます。
Queue
テストはランダムな優先度も生成しますが、使用されません。
これはおそらくすべてのベンチマークの中で最も重要です。
Ds\PriorityQueue
は
SplPriorityQueue
2倍以上の速度であり、メモリの5%しか使用しません。これは20倍の効率的なメモリソリューションです。
しかし、どのように?
SplPriorityQueue
が同様の内部構造を使用している場合、どうしてこのような大きな違い
SplPriorityQueue
でしょうか? すべては、値が優先度とどのようにペアリングされるかにかかっています。
SplPriorityQueue
を使用すると、変数として使用するために任意のタイプの値を使用できます。これにより、各ペアの優先順位が32バイトであるという事実につながります 。
Ds\PriorityQueue
は整数の優先
Ds\PriorityQueue
のみをサポートするため、各ペアに24バイトが割り当てられます 。 しかし、これはまだ結果を説明するのに十分な違いではありません。
SplPriorityQueue::insert
ソースコードを見ると、値と優先順位のペアを格納する ために配列が初期化されていることが
SplPriorityQueue::insert
ます。
なぜなら 配列の最小容量は8
zval + HashTable + 8 * (Bucket + hash) + 2 * zend_string + (8 + 16) byte string payloads
、各ペア
zval + HashTable + 8 * (Bucket + hash) + 2 * zend_string + (8 + 16) byte string payloads
=
16 + 56 + 36 * 8 + 2 * 24 + 8 + 16
が実際に割り当てられます
16 + 56 + 36 * 8 + 2 * 24 + 8 + 16
= 432バイト (64ビット)。
「それで...なぜアレイなの?」
SplPriorityQueue
は同じ内部
SplMaxHeap
構造を使用します。これには、値が
zval
タイプである必要があります。 次のように、
zval
ペアを作成する明白な(しかし非効率的な)方法
zval
自体は
array
として使用されます。
ハッシュ可能
オブジェクトをキーとして使用できるようにするインターフェイス。 これは、
handle:
基づいてハッシュ内のオブジェクトを決定する
spl_object_hash
の代替です
handle:
これは、比較時に等しいと見なされる2つのオブジェクトが等しいハッシュを持たないことを意味します。 それらは同じインスタンスではありません。
Hashable
は、2つのメソッド、
hash
と
equals
のみを導入します。 Java、
hashCode
および
equals
、またはPython
___hash___
および
__eq__
では、他の多くの言語がこれをネイティブにサポートします。 PHPに同様の動作を追加するRFCがいくつかありましたが、どれも受け入れられませんでした。
格納されているオブジェクトのキーが
Hashable
を実装していない場合、すべての構造は
spl_object_hash
を返します。
Hashable
データ
Hashable
:
Map
および
Set
。
マップ(連想配列)
Map
は、類似したコンテキストの
array
とほぼ同一のキーと値のペアの順次コレクションです。 キーはどのタイプでもかまいませんが、唯一の条件は一意性です。 キーを再度追加すると、値が置き換えられます。
array
同様、挿入順序は保持されます。
強み
- パフォーマンスとメモリ効率は
array
ほぼ同じです - ダウンサイズ時に自動的にメモリを解放します
- キーと値は、オブジェクトを含む任意のタイプにすることができます
-
Hashable
インターフェースを実装するオブジェクトの処理をサポートします -
put
、get
、remove
、containsKey
複雑度はO(1)
欠点
- オブジェクトキーがある場合、
array
に変換できません - インデックス(位置)で値にアクセスする方法はありません
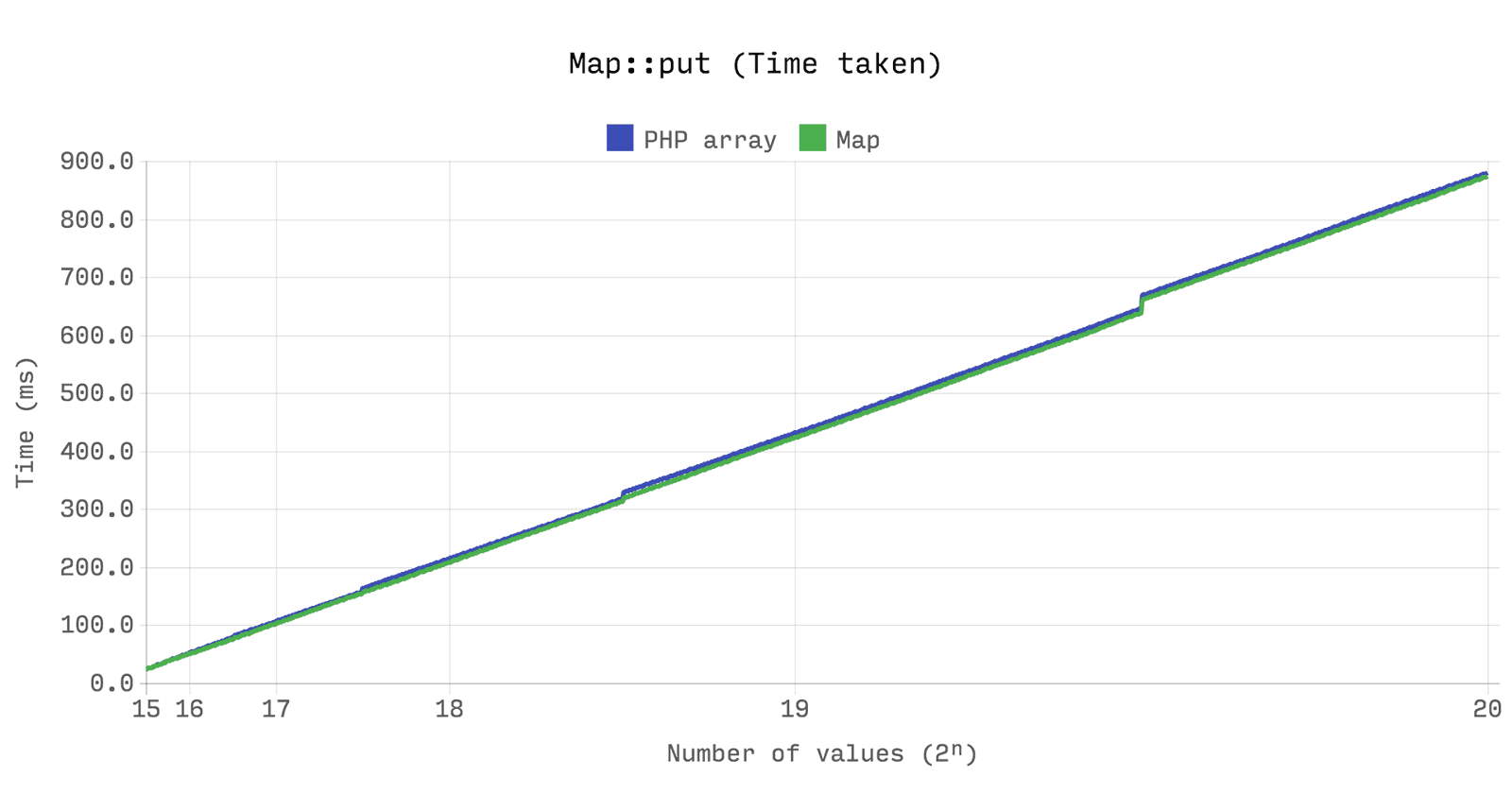
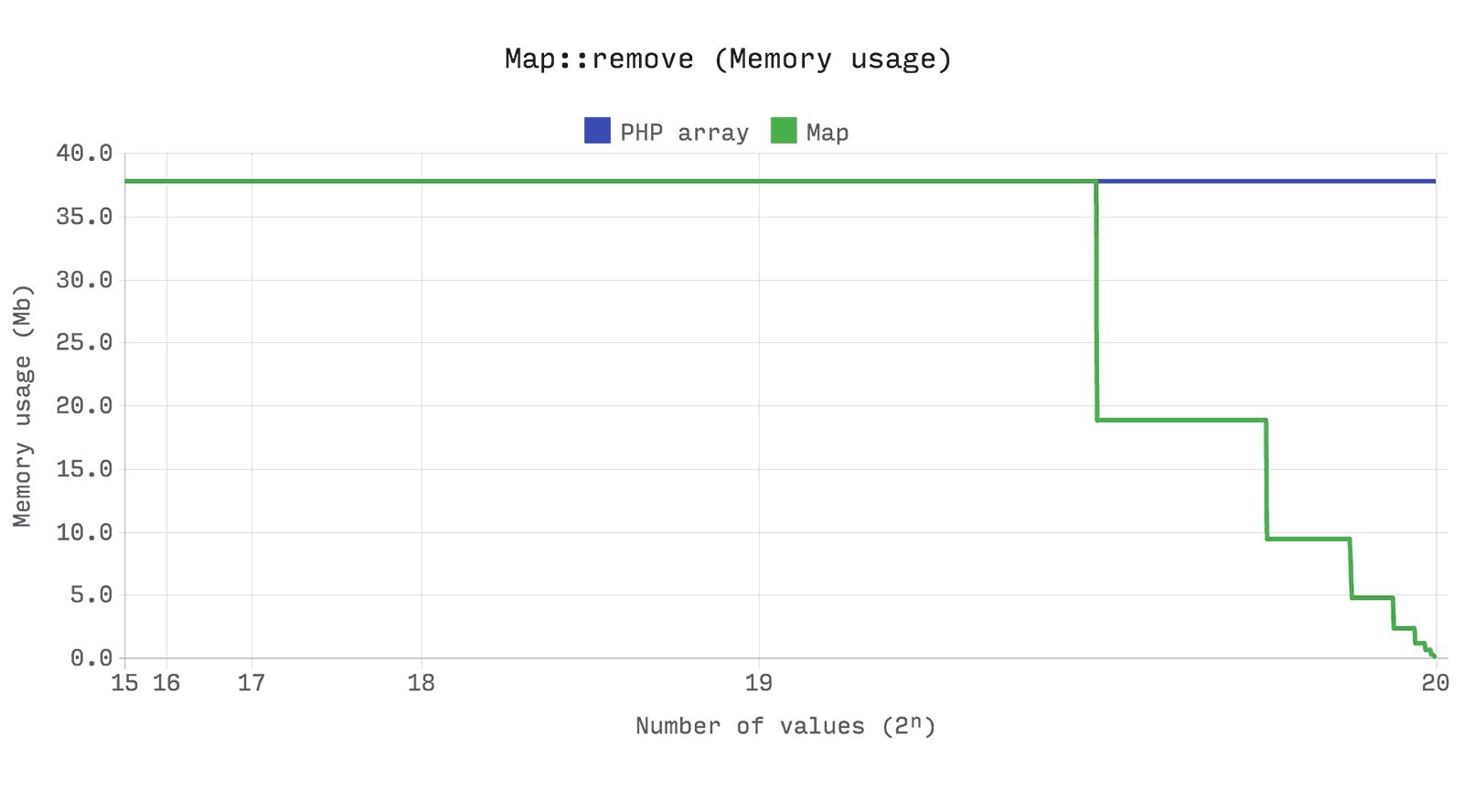
次のベンチマークは、
array
と
Ds\Map
のパフォーマンスとメモリ効率
Ds\Map
同じであることを示しています。 ただし、
Ds\Map
がサイズが潜在能力の4分の1を下回ると、
array
は常に割り当てられたメモリを保持します。
セット(多数)
Set
- 一意の値のコレクション。 チュートリアルでは、
Set
構造では、実装で特に指定されていない限り、値は順序付けられていないことがわかります。 Javaを例にとると、
java.util.Set
は
HashSet
と
TreeSet
2つの主要な実装を備えたインターフェースです。
HashSet
は
add
と
remove
に
O(1)
複雑さを提供し、
TreeSet
はソートされたデータセットを提供しますが、
add
と
remove
複雑さは
O(log n)
増加し
O(log n)
。
Set
は、同じく
array
基づいて、
Map
と同じ内部構造を使用します。 これは、必要に応じて
Set
を
O(n * log(n))
でソートできることを意味します。それ以外の場合は、
Map
および
array
と同じくらい簡単です。
強み
-
add
、remove
、およびcontains
はO(1)
複雑さがあります -
Hashable
インターフェースを実装するオブジェクトの処理をサポートします - 任意のタイプの値をサポートします (
SplObjectStorage
はオブジェクトのみをサポートします)。 - ビットごとの論理演算(
intersection
、difference
、union
、exclusive or
)と同等
欠点
-
push
、pop
、insert
、shift
またはunshift
サポートしていません - インデックス付けまで削除された値がある場合、
get
はO(n)
複雑さを持ち、そうでない場合はO(1)
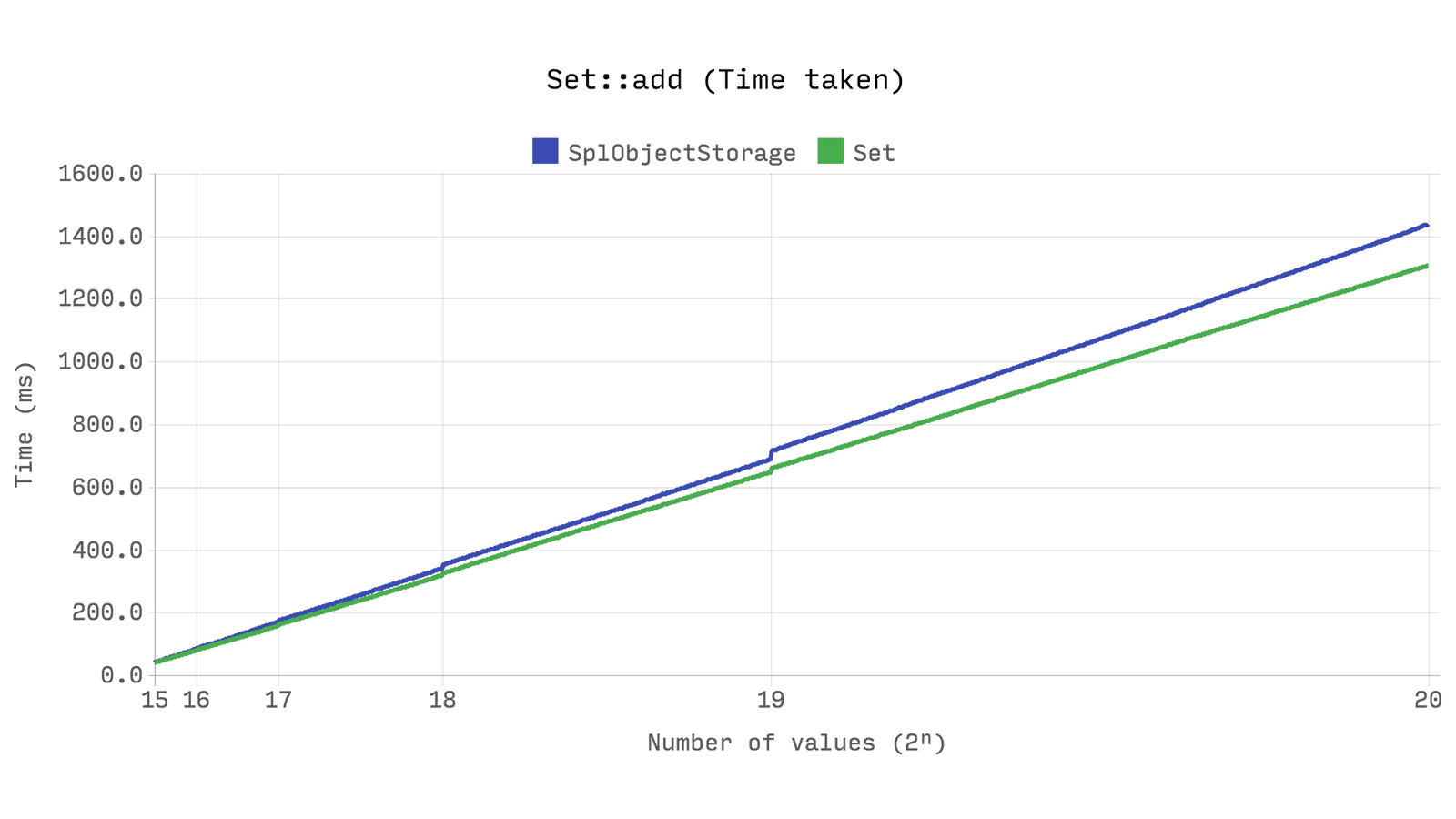
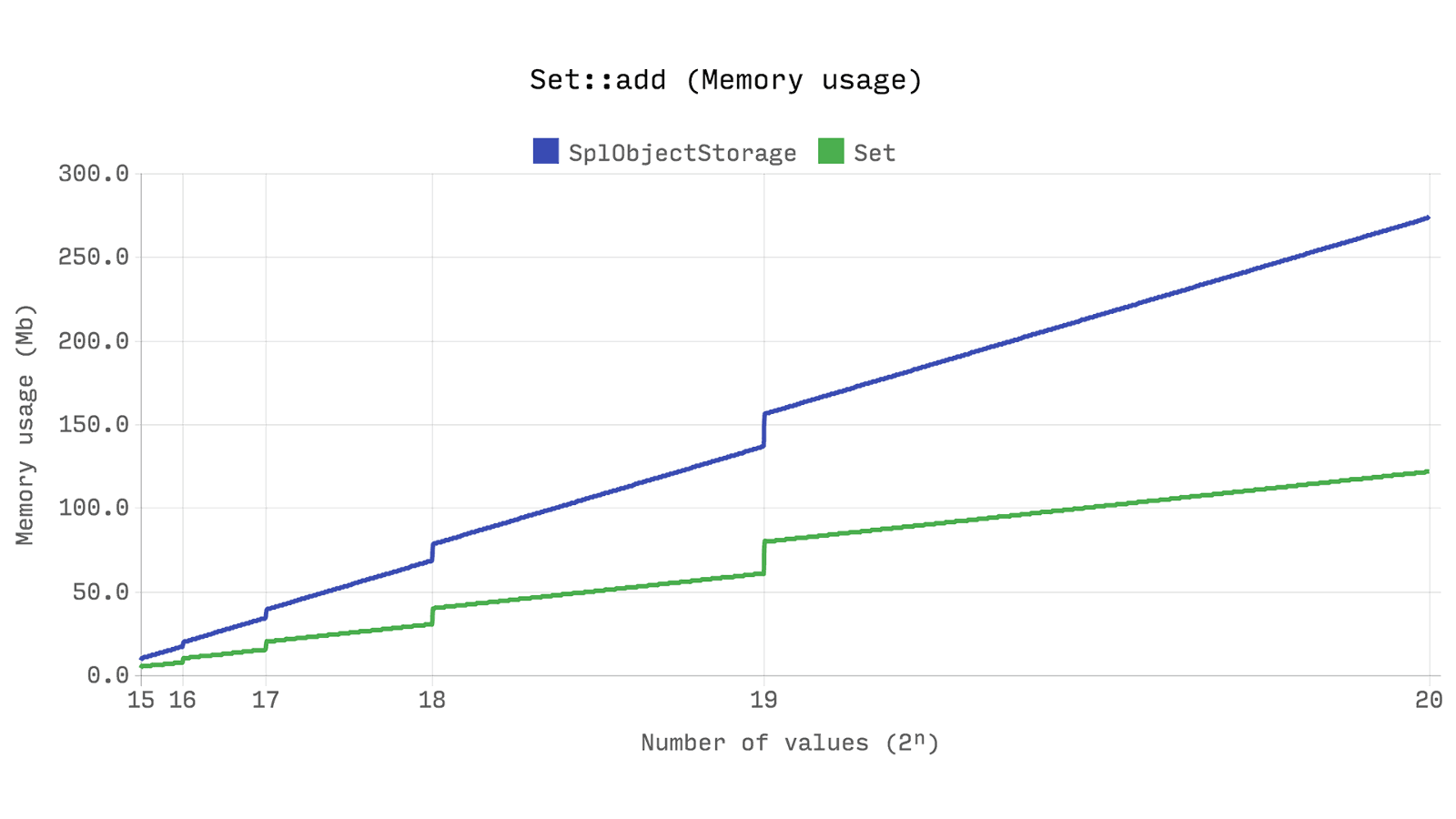
次のベンチマークは、stdClassの2つの新しいインスタンスを追加するのにかかる時間を示しています。
Ds\Set
SplObjectStorage
よりもわずかに高速で
SplObjectStorage
、使用するメモリが約半分少ないことを示しています。
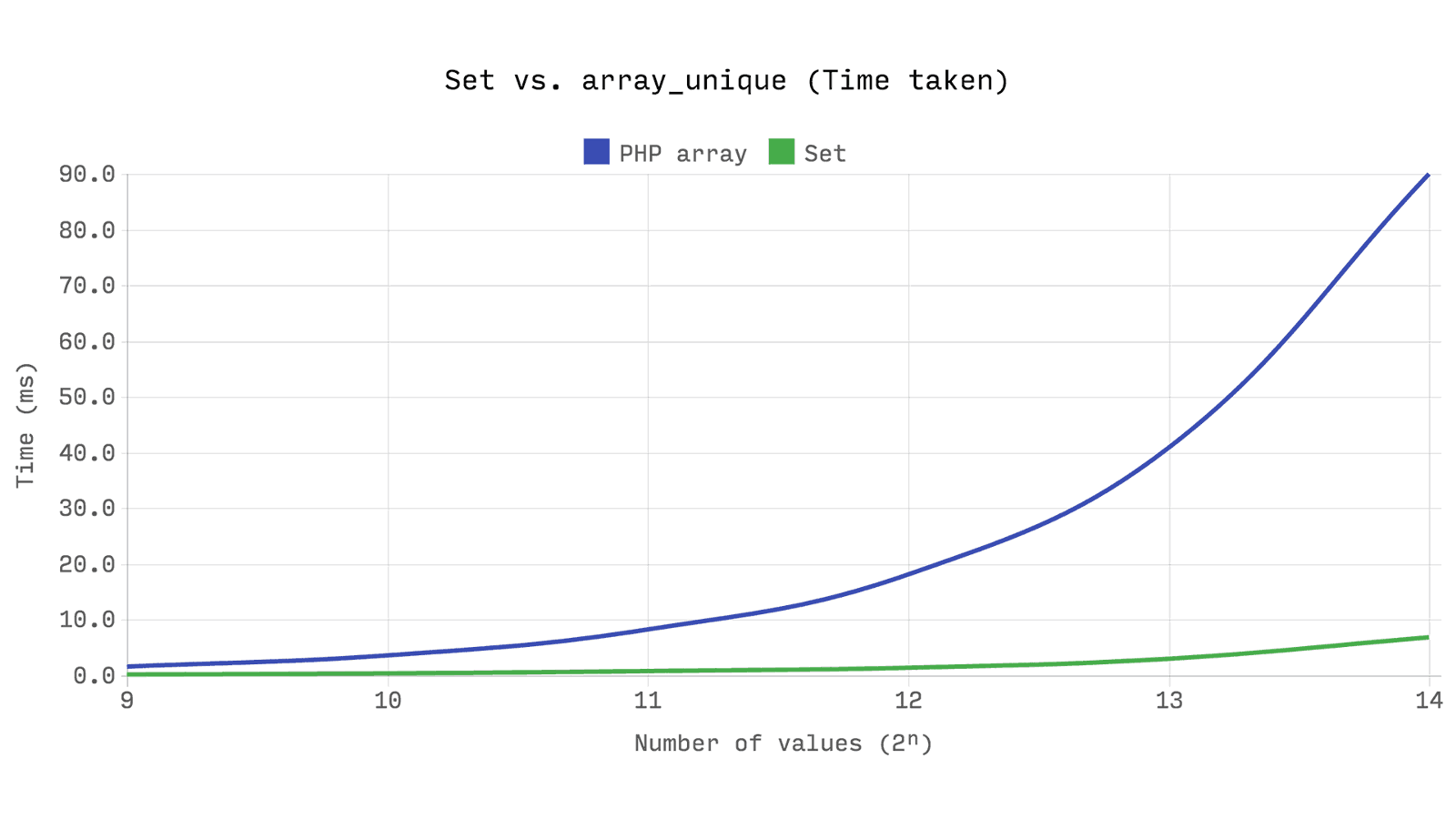
一意の値を持つ配列を作成する一般的な方法は
array_unique
、一意の値のみを含む新しい
array
を作成します。 ただし、配列の値にはインデックスが付けられていないことに
in_array
は複雑度
O(n)
線形検索です。
array_unique
は、キーを除く値でのみ機能します。配列の値の各チェックは線形検索であり、時間の
O(n²)
とメモリ消費の
O(n)
の合計の複雑さを提供します。
予想される質問と意見への回答
テストはありますか?
約2600のテストになりました 。 一部のテストは冗長である可能性がありますが、まったくチェックしないよりも、間接的に同じことを2回テストしたいです。
ドキュメント? APIリファレンス?
このドキュメントの執筆時点では、完全なドキュメントはまだありませんが、最初の安定版リリースと共に表示されます。
ただし、 十分に文書化されたスタブファイルがいくつかあります 。
ベンチマークの配置を確認できますか? それらについて何かありますか?
すべてのベンチマークは、 2015 Macbook Proの
PHP 7.0.3
標準ビルドで実行されました。 結果は、バージョンとプラットフォームによって異なる場合があります。
Stack
、 Queue
、 Set
およびMap
インターフェイスが使用されないのはなぜですか?
代替の実装が必要だとは思わない。 3つのインターフェイスと7つのクラスは、プラグマティズムと専門化のバランスが取れています。
いつVector
代わりにDeque
を使用する必要がありますか?
shift
および
unshift
を使用しないことが確実にわかっている場合は、
Vector
使用します。 便利なタイピングのために、
Sequence
タイプとしてヒントを指定できます。
すべてのクラスが終了するのはなぜですか?
php-ds
APIの設計では、 「継承を介した構成」が適用されます。
SPL構造は、継承の誤用の良い例です。 たとえば、
SplStack
は
SplStack
拡張し
SplDoublyLinkedList
。これは、インデックス、
shift
、および
shift
SplDoublyLinkedList
によるランダムアクセスをサポートするため、
SplStack
はStackではありません。
Javaコレクションフレームワークには、継承によってあいまいさが生じる興味深いケースもいくつかあります。
ArrayDeque
は、要素を追加するための3つのメソッド、
add
、
addLast
、および
push
ます。 これは悪くない、なぜなら
ArrayDeque
は、
Deque
と
Queue
実装します。これは、
addLast
と
push
同時に存在することを説明しています。 ただし、同じことを一度に行う3つの方法はすべて、混乱と矛盾を引き起こします。
古い
java.util.Stack
拡張したため、「
Deque
インターフェースとその実装により、より完全で一貫したLIFO操作のセットが提供されます」が、
Deque
は
addFirst
と
remove(x)
メソッドが含まれています。 APIによる
stack
構造の一部である。
これらの構造がばらばらのメソッドを持っているからといって、これができないというわけではありません。
実際、これは公平なポイントですが、データ構造の構築には合成がより適していると考えています。
array
ように、それらは自給自足することを目的としています。
array
から継承することはできません。実際のデータを保存するためだけに使用して、独自のAPIを開発する必要があります。
継承はまた、内部実装において不必要な困難を引き起こします。
グローバル名前空間にds
クラスが必要なのはなぜですか?
代替構文を提供します。

リンクリストがないのはなぜですか?
LinkedList
クラスは実際に最初に登場し、良いスタートのように思えました。 しかし、結局、私は彼がどんな状況でも
Vector
や
Deque
に対抗できないことに気付いたとき、それを削除することにしました。 可能なサポートの2つの主な理由はオーバーヘッド分配とリンク局所性です 。
リンクリストでは、値が追加または削除されるたびに、構造要素(ノード)の予約メモリを追加または削除します。 ノードには、前のノードと次のノードを参照するための2つのポインターが含まれています(二重リンクリストの場合)。
Vector
と
Deque
両方の構造体は、事前にメモリバッファを割り当てるため、これを頻繁に行う必要はありません。 また、前の値と後の値を知るために追加のポインターを必要としないため、オーバーヘッドが削減されます。
リンクリストはより少ないメモリを使用しますか バッファーがありませんか?
コレクションが非常に小さい場合のみ。
Vector
のメモリ量の上限は、
(1.5 * (size - 1)) * zval
バイト、少なくとも* 10 * zval *です。 二重にリンクされたリストでは、
(size * (zval + 8 + 8))
が使用されます。 したがって、リンクリストは、サイズが6要素未満の場合にのみ、
Vector
よりも少ないメモリを使用します。
さて...リンクリストはより多くのメモリを使用しますが、なぜ遅いのですか?
リンクリストノードの空間的局所性は不十分です 。 これは、メモリ内のノードの物理的な場所が、隣接するノードから遠く離れている可能性があることを意味します。 したがって、リンクリストの繰り返しは、プロセッサキャッシュを使用する代わりにメモリからジャンプします。
Vector
と
Deque
大きな利点:要素は物理的に隣り合っています。
»構造におけるデータの非連続性は、すべてのパフォーマンスの悪の根源です。 具体的には、リンクリストに「いいえ」と言ってください。
「リンクされたリストを使用するよりも、現代のマイクロプロセッサのすべての利点を殺すためにできることから、ほとんど有害なものはありません。」
-チャンドラー・カルース( CppCon 2014 )
PHPはWeb開発用の言語です-パフォーマンスは重要ではありません。
パフォーマンスは最優先事項ではありません 。コードは、一貫性があり、保守可能で、信頼性が高く、予測可能で、安全で、理解しやすいものでなければなりません。しかし、これはパフォーマンスが「重要ではない」という意味ではありません。
資産のサイズを縮小し、フレームワークの比較分析を行い、意味のないマイクロ最適化を考え出すために、多くの時間を費やしています。
- 印刷とエコー、どちらが速いですか?
- PHP Ternary Operator:高速かどうか?
- PHPベンチマーク:レコードをまっすぐに設定する
- Single Quotes Performance Mythの反証
しかし、最終的に、PHP7が何らかの理由でもたらす生産性の2倍の増加は、皆を興奮させました。誰にとっても、これはPHP5から移行する主な利点の1つです。
効率的なコードにより、サーバーの負荷が軽減されます。APIとWebページの応答時間を短縮し、開発ツールの作業時間を短縮します。高いパフォーマンスが重要ですが、コードサポートは依然として最前線にあります。
ディスカッション:Twitter、Reddit、Room 11
ソースコード:github.com/php-ds
ベンチマーク: github.com/php-ds/benchmarks