はじめに
最近KinoPoiskを見て、私は長年にわたって1000以上の評価を残すことができたことを発見し、これらのデータをより詳細に調査することは興味深いと思いました。 活動に年間/毎週の季節性はありますか? 私の評価は、映画検索、IMDb、または映画評論家と相関していますか?
しかし、美しいグラフを分析して構築する前に、データを取得する必要があります。 残念ながら、多くのサービス(およびKinoPoiskも例外ではありません)にはパブリックAPIがないため、袖をまくり、htmlページを解析する必要があります。 この記事で説明したいWebサイトをダウンロードして解析する方法についてです。
この記事の主な目的は、常にWeb Scrappingに対処したいが、手を伸ばすことができなかった、またはどこから始めればよいのかわからなかった人を対象としています。
オフトピック :ちなみに、 内部の新しいキノポイスクは、JSONの形式で評価データを返すクエリを使用するため、別の方法で問題を解決できます。
挑戦する
タスクは、KinoPoiskで視聴した映画に関するデータ(映画の名前(ロシア語、英語)、視聴日時、ユーザーの評価)をアップロードすることです。
実際、作業を2つの段階に分けることができます。
- ステージ1: HTMLページをアップロードして保存する
- ステージ2:詳細分析に便利な形式(csv、json、pandasデータフレームなど)でhtmlを解析します
ツール
httpリクエストを送信するための多くのPythonライブラリ、最も有名なurllib / urllib2およびリクエストがあります。 私の好みでは、 リクエストはより便利で簡潔なので、使用します。
htmlを解析するためのライブラリを選択する必要もあります。少し調べてみると、次のオプションがあります。
- 再
もちろん、正規表現は私たちにとっては便利ですが、私の意見では、それらだけを使用することは筋が通っています。 htmlを解析するためのより便利なツールが発明されたので、それらに移りましょう。 - BeatifulSoup 、 lxml
これらはhtml解析で最も人気のある2つのライブラリであり、どちらを選択するかは個人の好みによって決まります。 さらに、これらのライブラリは密接に関連しています。BeautifulSoupはlxmlを加速用の内部パーサーとして使用し始め、soupparserモジュールがlxmlに追加されました。 これらのライブラリの長所と短所については、ディスカッションで詳しく読むことができます。 アプローチを比較するために、BeautifulSoupとlxml.htmlモジュールのXPathセレクターを使用してデータを解析します。 - スクレイピー
これは単なるライブラリではなく、Webページからデータを取得するためのオープンソースフレームワーク全体です。 非同期クエリ、データ処理にXPathとCSSセレクターを使用する機能、エンコーディングの便利な機能など、多くの便利な機能があります(詳細については、 こちらをご覧ください )。 私のタスクが一度限りのアンロードではなく、生産プロセスである場合、私はそれを選択します。 現在の設定では、これは過剰です。
データの読み込み
最初の試み
データをアップロードしましょう。 始めるには、URLでページを取得し、ローカルファイルに保存してみます。
import requests user_id = 12345 url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/2/#list' % (user_id) # url r = requests.get(url) with open('test.html', 'w') as output_file: output_file.write(r.text.encode('cp1251'))
受信したファイルを開くと、すべてがそれほど単純ではないことがわかります。サイトは私たちのロボットを認識し、データを表示するのに急いではありません。

ブラウザの仕組みを見てみましょう
ただし、ブラウザはサイトから情報を取得するのに優れています。 彼がリクエストを送信する方法を見てみましょう。 これを行うには、ブラウザーの「開発ツール」の「ネットワーク」パネルを使用します(これにはFirebugを使用します)。通常、必要な要求は最長です。
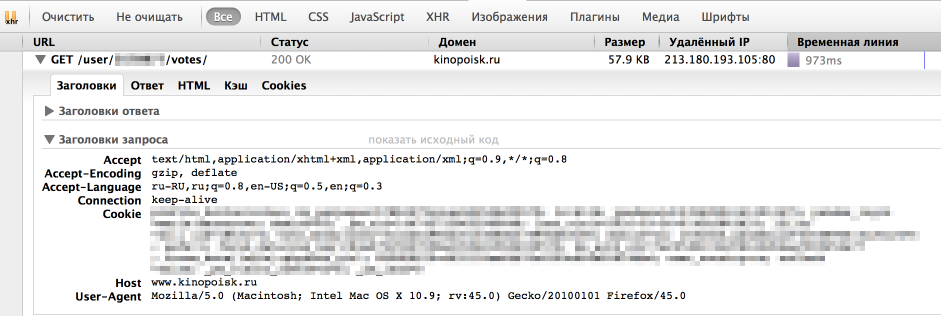
ご覧のとおり、ブラウザーはUserAgent、Cookie、およびいくつかのパラメーターもヘッダーに渡します。 最初に、正しいUserAgentをヘッダーに渡すだけです。
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' } r = requests.get(url, headers = headers)
今回はすべてがうまくいったので、必要なデータが与えられました。 サイトがCookieの正確性をチェックすることもありますが、その場合はリクエストライブラリのセッションが役立ちます。
すべての評価をダウンロードする
これで、評価付きの1ページを保存できます。 しかし、通常、ユーザーには多くの評価があり、すべてのページで繰り返す必要があります。 興味のあるページ番号は、URLに直接渡すのは簡単です。 残っているのは、「評価付きの合計ページ数を理解する方法」という質問だけです。 この問題を次のように解決しました。指定するページ番号が大きすぎる場合、フィルムのあるテーブルのないページを返します。 このようにして、映画の評価(
<div class = "profileFilmsList">
)のブロックがある限り、ページを反復処理できます。

データをダウンロードするための完全なコード
import requests # establishing session s = requests.Session() s.headers.update({ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' }) def load_user_data(user_id, page, session): url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/%d/#list' % (user_id, page) request = session.get(url) return request.text def contain_movies_data(text): soup = BeautifulSoup(text) film_list = soup.find('div', {'class': 'profileFilmsList'}) return film_list is not None # loading files page = 1 while True: data = load_user_data(user_id, page, s) if contain_movies_data(data): with open('./page_%d.html' % (page), 'w') as output_file: output_file.write(data.encode('cp1251')) page += 1 else: break
解析
XPathについて少し
XPathは、xmlおよびxhtmlドキュメントのクエリ言語です。 lxmlライブラリー( documentation )を操作するときは、XPathセレクターを使用します。 XPathを扱う小さな例を考えてみましょう
from lxml import html test = ''' <html> <body> <div class="first_level"> <h2 align='center'>one</h2> <h2 align='left'>two</h2> </div> <h2>another tag</h2> </body> </html> ''' tree = html.fromstring(test) tree.xpath('//h2') # h2 tree.xpath('//h2[@align]') # h2 align tree.xpath('//h2[@align="center"]') # h2 align "center" div_node = tree.xpath('//div')[0] # div div_node.xpath('.//h2') # h2 , div
W3Schoolsで XPath構文の詳細を読むこともできます。
タスクに戻る
次に、htmlからデータを取得するために直接渡します。 最も簡単な方法は、ブラウザのInspect Element機能を使用して、htmlページがどのように配置されるかを理解することです。 この場合、すべてが非常に単純です。評価付きのテーブル全体が
<div class = "profileFilmsList">
囲まれています。 このノードを選択:
from bs4 import BeautifulSoup from lxml import html # Beautiful Soup soup = BeautifulSoup(text) film_list = soup.find('div', {'class': 'profileFilmsList'}) # lxml tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0]
各ムービーは、
<div class = "item">
または
<div class = "item even">
として表されます。 映画のロシア語の名前と映画のページへのリンクを引き出す方法を検討してください(テキストと属性の値を取得する方法も学習します)。
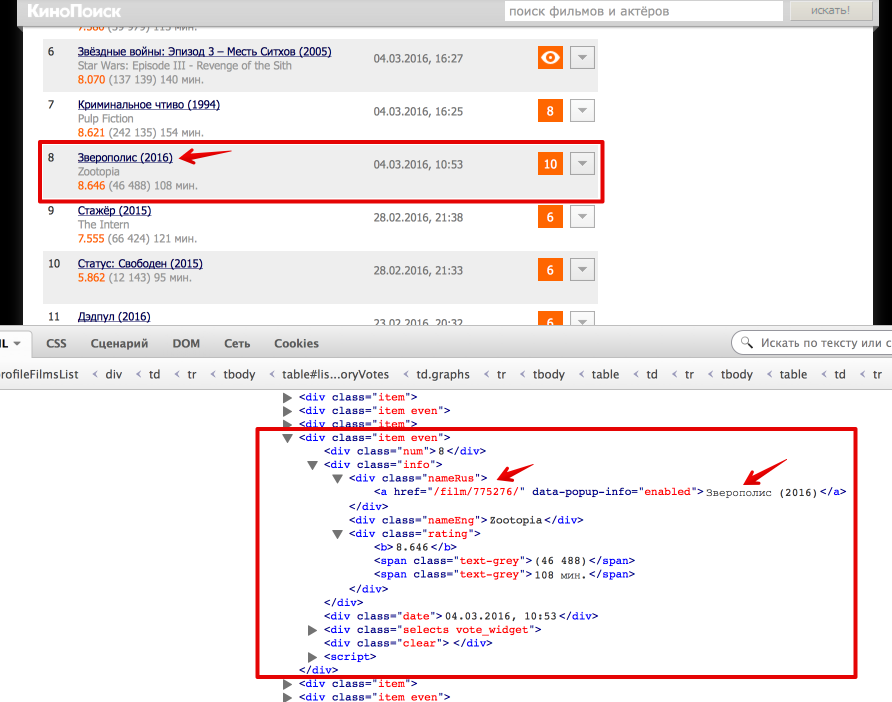
# Beatiful Soup movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href') movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text # lxml movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0] movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0]
デバッグのための別の小さなヒント:BeautifulSoupで選択したノード内でそれを簡単に印刷し、
tostring()
モジュールの
tostring()
関数を使用できることを確認します。
# BeatifulSoup print item #lxml from lxml import etree print etree.tostring(item_lxml)
catの下でhtmlファイルを解析するための完全なコード
def read_file(filename): with open(filename) as input_file: text = input_file.read() return text def parse_user_datafile_bs(filename): results = [] text = read_file(filename) soup = BeautifulSoup(text) film_list = film_list = soup.find('div', {'class': 'profileFilmsList'}) items = film_list.find_all('div', {'class': ['item', 'item even']}) for item in items: # getting movie_id movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href') movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text movie_id = re.findall('\d+', movie_link)[0] # getting english name name_eng = item.find('div', {'class': 'nameEng'}).text #getting watch time watch_datetime = item.find('div', {'class': 'date'}).text date_watched, time_watched = re.match('(\d{2}\.\d{2}\.\d{4}), (\d{2}:\d{2})', watch_datetime).groups() # getting user rating user_rating = item.find('div', {'class': 'vote'}).text if user_rating: user_rating = int(user_rating) results.append({ 'movie_id': movie_id, 'name_eng': name_eng, 'date_watched': date_watched, 'time_watched': time_watched, 'user_rating': user_rating, 'movie_desc': movie_desc }) return results def parse_user_datafile_lxml(filename): results = [] text = read_file(filename) tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0] items_lxml = film_list_lxml.xpath('//div[@class = "item even" or @class = "item"]') for item_lxml in items_lxml: # getting movie id movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0] movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0] movie_id = re.findall('\d+', movie_link)[0] # getting english name name_eng = item_lxml.xpath('.//div[@class = "nameEng"]/text()')[0] # getting watch time watch_datetime = item_lxml.xpath('.//div[@class = "date"]/text()')[0] date_watched, time_watched = re.match('(\d{2}\.\d{2}\.\d{4}), (\d{2}:\d{2})', watch_datetime).groups() # getting user rating user_rating = item_lxml.xpath('.//div[@class = "vote"]/text()') if user_rating: user_rating = int(user_rating[0]) results.append({ 'movie_id': movie_id, 'name_eng': name_eng, 'date_watched': date_watched, 'time_watched': time_watched, 'user_rating': user_rating, 'movie_desc': movie_desc }) return results
まとめ
その結果、Webサイトの解析方法を学び、Requests、BeautifulSoup、およびlxmlライブラリに精通し、KinoPoiskで視聴した映画のさらなる分析に適したデータも取得しました。

完全なプロジェクトコードはgithubにあります。
UPD
コメントに記載されているように、次のトピックはWeb Scrappingのコンテキストで役立つ場合があります。
- 認証:多くの場合、サイトからデータを取得するには認証を行う必要があります。最も単純な場合は、単にHTTP Basic Auth:ログインとパスワードです。 ここで、リクエストライブラリが再び役立ちます 。 さらに、oauth2は広く普及しています。Pythonでoauth2を使用する方法は、 stackoverflowで読むことができます。 また、 コメントには、Webフォームでの認証方法に関するTerrasの例があります。
- コントロール:サイトには、追加のWebフォーム(ドロップダウンリスト、チェックボックスなど)がある場合もあります。 それらを使用するためのアルゴリズムはほぼ同じです。ブラウザーが送信するものを見て、データと同じパラメーターをPOST要求( Requests 、 stackoverflow )に送信します。 また、 米国運輸省のウェブサイトを廃棄し、ウェブフォームデータを送信する例について詳しく説明している、Udacityの「データラングリング」コースの2番目のレッスンをご覧になることをお勧めします。