 Randolph Geistは、Oracleデータベースのパフォーマンスに関連するエラーの修正を専門としています。 彼は、SQLコード実行およびOracle最適化テクノロジーの分析の分野で、世界最高の専門家の一人です。 彼は、Oracle Database Administrator(OCP DBA)バージョン8i、9i、および10gの認定を受けています。
Randolph Geistは、Oracleデータベースのパフォーマンスに関連するエラーの修正を専門としています。 彼は、SQLコード実行およびOracle最適化テクノロジーの分析の分野で、世界最高の専門家の一人です。 彼は、Oracle Database Administrator(OCP DBA)バージョン8i、9i、および10gの認定を受けています。
以下は、シングルインスタンスモードで多数のコアを備えた大規模サーバーでOracleを実行しているお客様にのみ適用されます (この特定の問題はRAC環境では再現しません。理由については以下の説明を参照してください)。
そのような顧客には、Exadata Xn-8サーバーを使用するクライアントの1人が含まれます。たとえば、ノードあたり120コア/ 240プロセッサのX4-8(ただし、ノードあたり64コア/ 128プロセッサの古いモデルや小さいモデルでも再生されます)
最近、基本的なアプリケーションを書き直すことにしました。 このコードの一部は、多くの場合同時に、異なるデータセットに対して同じ操作を実行しました。 これは、多くのセッションで並列クエリ実行が使用されるという事実につながりました。 このコードのリクエストの多くは、パラレル実行を最適な方法で使用していません。非常に短い期間のリクエストではパラレル実行が使用され、結果として1秒あたり数回のパラレル実行が開始されました。 このような写真はAWRレポートで見ることができ、平均して、1時間ごとにいくつかの並列実行ツリーが起動されたことを示しています。

本番システムから受け取ったデータと負荷で新しいコードがテストされたとき、最初にそのような大きなノード(シングルインスタンスモードで動作)のプロセッサのプロファイルは次のようになりました。 ただし、コンピューターは他のプロセスによって読み込まれませんでした。
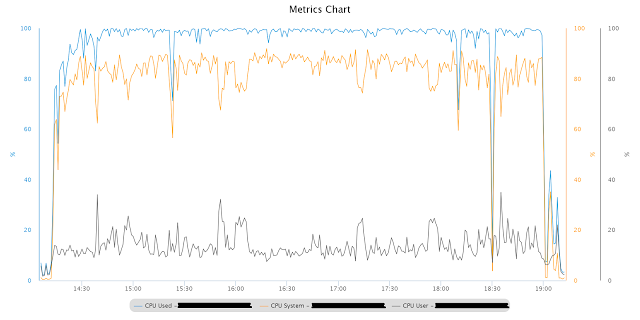
図からわかるように、ノードプロセッサは完全にロードされており、ほとんどの場合、カーネル/システムモードです。 AWRレポートは、大量の非定型PX待機イベントを示しました。
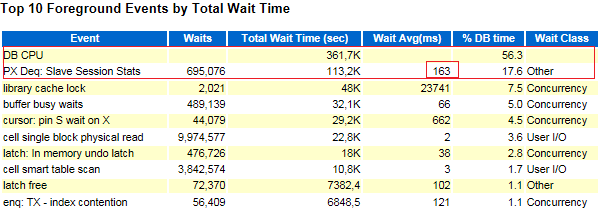
「PX Deq:Slave Session Stats」イベントは、完了時にスレーブノードのセッション統計をPXコーディネーターに送信することについて話しているので、それほど時間はかかりません。 明らかに、このDominion PXの相互作用が大幅に遅くなりました(これは、パラレル実行を過度に使用した場合にのみ確認できます)。
さらに、スローモーションのように、多数の結合を実行し、多数のデータ再配布をもたらす、並列実行を伴うより複雑なクエリの一部が発生しました。 実行時間のほぼ100%がCPUにかかっていましたが、アクティブセッション履歴は、時間のほぼ90%が再配布操作に関係していることを示しています。
SQL statement execution ASH Summary ----------------------------------------------- | | | |PX SEND/RECEIVE|PX SEND/RECEIVE| PERCENTAGE_CPU| PERCENT| CPU PERCENT| --------------|---------------|---------------| 98| 86| 87|
アイドル時間中に同じマシンで同じ実行計画と同じデータを使用して同じリクエストを実行すると、パフォーマンスがほぼ20倍になり、再配布に費やされた時間は40%未満になりました。
SQL statement execution ASH Summary ----------------------------------------------- | | | |PX SEND/RECEIVE|PX SEND/RECEIVE| PERCENTAGE_CPU| PERCENT| CPU PERCENT| --------------|---------------|---------------| 96| 38| 37|
どうやら、これらの要求は、Oracleではなく外部(オペレーティングシステムのレベル)で行われ、カーネルモードでプロセッサ時間として現れる競合のようなものでした。 ミューテックスをスピンするときに、以前のバージョンのOracleでも同様のことが観察されました。
パラレル実行の過剰な使用を減らすと、CPU時間は大幅に減少しました。 しかし、カーネル/システムモードでの大量のプロセッサ時間は依然として不明でした。
したがって、主な質問:オペレーティングシステムのカーネルで正確に何がこの時間を費やしたかです。 それに対する答えは、追加の手がかりを見つけるのに役立つかもしれません。
分析
そのような実行中にノードでperf topを実行すると、次のプロファイルが生成されました。
PerfTop: 129074 irqs/sec kernel:76.4% exact: 0.0% [1000Hz cycles], (all, 128 CPUs) ------------------------------------------------------------------------------------------------------------------- samples pcnt function DSO _______ _____ ________________________ ___________________________________________________________ 1889395.00 67.8% __ticket_spin_lock /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 27746.00 1.0% ktime_get /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 24622.00 0.9% weighted_cpuload /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 23169.00 0.8% find_busiest_group /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 17243.00 0.6% pfrfd1_init_locals /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 16961.00 0.6% sxorchk /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 15434.00 0.6% kafger /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 11531.00 0.4% try_atomic_semop /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 11006.00 0.4% __intel_new_memcpy /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 10557.00 0.4% kaf_typed_stuff /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 10380.00 0.4% idle_cpu /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 9977.00 0.4% kxfqfprFastPackRow /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 9070.00 0.3% pfrinstr_INHFA1 /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 8905.00 0.3% kcbgtcr /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 8757.00 0.3% ktime_get_update_offsets /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 8641.00 0.3% kgxSharedExamine /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 7487.00 0.3% update_queue /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 7233.00 0.3% kxhrPack /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 6809.00 0.2% rworofprFastUnpackRow /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 6581.00 0.2% ksliwat /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 6242.00 0.2% kdiss_fetch /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 6126.00 0.2% audit_filter_syscall /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 5860.00 0.2% cpumask_next_and /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 5618.00 0.2% kaf4reasrp1km /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 5482.00 0.2% kaf4reasrp0km /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 5314.00 0.2% kopp2upic /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 5129.00 0.2% find_next_bit /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux 4991.00 0.2% kdstf01001000000km /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 4842.00 0.2% ktrgcm /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 4762.00 0.2% evadcd /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle 4580.00 0.2% kdiss_mf_sc /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle «perf» : 0.36% ora_xxxx [kernel.kallsyms] [k] __ticket_spin_lock | --- __ticket_spin_lock | |--99.98%-- _raw_spin_lock | | | |--100.00%-- ipc_lock | | ipc_lock_check | | | | | |--99.83%-- semctl_main | | | sys_semctl | | | system_call | | | __semctl | | | | | | | --100.00%-- skgpwpost | | | kslpsprns | | | kskpthr | | | ksl_post_proc | | | kxfprienq | | | kxfpqrenq | | | | | | | |--98.41%-- kxfqeqb | | | | kxfqfprFastPackRow | | | | kxfqenq | | | | qertqoRop | | | | kdstf01001010000100km | | | | kdsttgr | | | | qertbFetch | | | | qergiFetch | | | | rwsfcd | | | | qertqoFetch | | | | qerpxSlaveFetch | | | | qerpxFetch | | | | opiexe | | | | kpoal8
これらの並列スレーブでstraceを実行すると、以下が生成されました。
. . . semctl(1347842, 397, SETVAL, 0x1) = 0 semctl(1347842, 388, SETVAL, 0x1) = 0 semctl(1347842, 347, SETVAL, 0x1) = 0 semctl(1347842, 394, SETVAL, 0x1) = 0 semctl(1347842, 393, SETVAL, 0x1) = 0 semctl(1347842, 392, SETVAL, 0x1) = 0 semctl(1347842, 383, SETVAL, 0x1) = 0 semctl(1347842, 406, SETVAL, 0x1) = 0 semctl(1347842, 389, SETVAL, 0x1) = 0 semctl(1347842, 380, SETVAL, 0x1) = 0 semctl(1347842, 395, SETVAL, 0x1) = 0 semctl(1347842, 386, SETVAL, 0x1) = 0 semctl(1347842, 385, SETVAL, 0x1) = 0 semctl(1347842, 384, SETVAL, 0x1) = 0 semctl(1347842, 375, SETVAL, 0x1) = 0 semctl(1347842, 398, SETVAL, 0x1) = 0 semctl(1347842, 381, SETVAL, 0x1) = 0 semctl(1347842, 372, SETVAL, 0x1) = 0 semctl(1347842, 387, SETVAL, 0x1) = 0 semctl(1347842, 378, SETVAL, 0x1) = 0 semctl(1347842, 377, SETVAL, 0x1) = 0 semctl(1347842, 376, SETVAL, 0x1) = 0 semctl(1347842, 367, SETVAL, 0x1) = 0 semctl(1347842, 390, SETVAL, 0x1) = 0 semctl(1347842, 373, SETVAL, 0x1) = 0 semctl(1347842, 332, SETVAL, 0x1) = 0 semctl(1347842, 379, SETVAL, 0x1) = 0 semctl(1347842, 346, SETVAL, 0x1) = 0 semctl(1347842, 369, SETVAL, 0x1) = 0 semctl(1347842, 368, SETVAL, 0x1) = 0 semctl(1347842, 359, SETVAL, 0x1) = 0 . . .
結論:並行して実行された場合の「semctl」(セマフォ)の呼び出しが原因で、「スピン」スピンロック(コードの重要なセクション)に多くのCPU時間が費やされます。 Straceは、semctlへのすべての呼び出しが同じセマフォのセット(最初のパラメーター)を使用することを示しています。これは、この特定のセマフォのセットの競合を説明します(ブロッキング領域はセマフォではなくセマフォのセットです)。
解決策
Oracleのエンジニアは、「perf」の結果に基づいて、バージョン12.1.0.2の適切な、しかし残念ながら未公開の2013年バグを発見しました。 彼女にとって、問題を解決する方法は3つあります。
1. 「cluster_database」= trueから開始します。この場合、Oracleはクエリを異なる方法で実行し、セマフォ呼び出しの数を2桁減らします。 このアプローチをテストしたところ、カーネルのランタイムの即時オフロードが示されました。これは、この特定の問題がRAC環境で再現されない理由の説明です。
2. 他のkernel.sem設定で起動します。Exadataマシンには、次の定義済みセマフォ構成が付属しています。
kernel.sem = 2048 262144 256 256
「Ipcs」は、Oracleインスタンスの起動時に、この構成で次のセマフォ配列を示しました。
------ Semaphore Arrays -------- key semid owner perms nsems . . . 0xd87a8934 12941057 oracle 640 1502 0xd87a8935 12973826 oracle 640 1502 0xd87a8936 12006595 oracle 640 1502 , , : kernel.sem = 100 262144 256 4096 «ipcs»: ------ Semaphore Arrays -------- key semid owner perms nsems . . . 0xd87a8934 13137665 oracle 640 93 0xd87a8935 13170434 oracle 640 93 0xd87a8936 13203203 oracle 640 93 0xd87a8937 13235972 oracle 640 93 0xd87a8938 13268741 oracle 640 93 0xd87a8939 13301510 oracle 640 93 0xd87a893a 13334279 oracle 640 93 0xd87a893b 13367048 oracle 640 93 0xd87a893c 13399817 oracle 640 93 0xd87a893d 13432586 oracle 640 93 0xd87a893e 13465355 oracle 640 93 0xd87a893f 13498124 oracle 640 93 0xd87a8940 13530893 oracle 640 93 0xd87a8941 13563662 oracle 640 93 0xd87a8942 13596431 oracle 640 93 0xd87a8943 13629200 oracle 640 93 0xd87a8944 13661969 oracle 640 93 0xd87a8945 13694738 oracle 640 93 0xd87a8946 13727507 oracle 640 93 0xd87a8947 13760276 oracle 640 93 0xd87a8948 13793045 oracle 640 93 0xd87a8949 13825814 oracle 640 93 0xd87a894a 13858583 oracle 640 93 0xd87a894b 13891352 oracle 640 93 0xd87a894c 13924121 oracle 640 93 0xd87a894d 13956890 oracle 640 93 0xd87a894e 13989659 oracle 640 93 0xd87a894f 14022428 oracle 640 93 0xd87a8950 14055197 oracle 640 93 0xd87a8951 14087966 oracle 640 93 0xd87a8952 14120735 oracle 640 93 0xd87a8953 14153504 oracle 640 93 0xd87a8954 14186273 oracle 640 93 0xd87a8955 14219042 oracle 640 93
言い換えると、Oracleは、セット内のセマフォがより少なく、より多くのセットを割り当てました。 「cluster_database = TRUE」の代わりにこの構成をテストし、同じ低プロセッサコアランタイムを取得しました。
3.問題に対する3番目の解決策があります。 その利点:ホスト構成を変更する必要がなく、インスタンスごとに構成を行うことができます。セットごとに割り当てられるセマフォの数の上限を定義する文書化されていないパラメーター「_sem_per_sem_id」があります。 このパラメーターに適切な値(100や128など)を設定すると、最終結果は同じになります。 Oracleは、セット内のより少ないセマフォでより多くのセットを割り当てますが、このオプションはテストしていません。
おわりに
Oracleインスタンスを使用するいくつかの方法では、Linuxオペレーティングシステムレベルでスピンロックコンテストが行われ(Oracleがシングルインスタンスモードで実行されている場合)、推奨されるセマフォ設定が使用されます。 これにより、すべてのセマフォ呼び出しが同じセマフォセットに送られます。 Oracleにより多くのセマフォのセットを割り当てさせると、呼び出しはより多くのセットに分散されます。 したがって、一致は大幅に減少します。
大規模なノードに推奨されるデフォルトのセマフォパラメータは、特定の状況下ではシングルインスタンスモードに最適ではないというOracleの内部使用の兆候がおそらくあります。 しかし、包括的な公式ガイドがあるかどうかはわかりません。
これは、変更されたkernel.sem設定を使用して、以前とまったく同じテスト負荷を持つCPUプロファイルです。
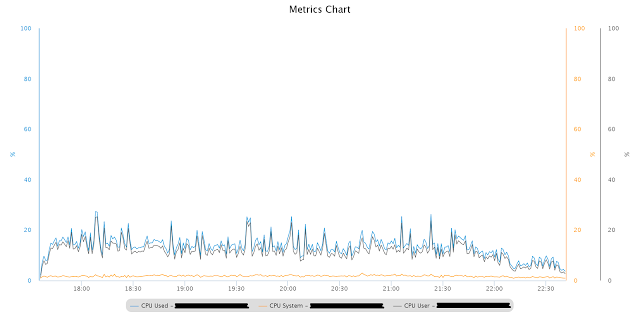
すべきではないPX関連の待機イベントもAWRレポートから消えました。 上記の複雑なクエリでも、パフォーマンスが大幅に向上しました。
ランドルフの素材が気に入ったら、3月24日にモスクワでマスタークラスを開催します。