
そして、今日は楽しいものと有用なものを組み合わせます:興味深い(実用的な)分析問題を分析すると同時に、ニューラルネットワークの分析問題への(非)適用性を決定する多くの要因を分析します。
あなたがHabréへの登場を気にかけている会社でアナリストとして働いていると想像してください(Mail.comと呼びます)。 そして、PR部門の女の子があなたのところにやって来て、こう言います。「マネージャーと私は、会社のHabra格付けをブランドの重要なKPIであると特定しました。それに影響を与える重要な要因を特定し、最も合理的な戦略を導き出すために、そこでニューラルネットワークを試してください。」
このスピーチの最中に、目は痙攣し始めますが、数分後に分析のための質問のリストを作成します。
- Q 1 :会社のHabraインデックスに影響を与える重要な要因は何ですか?
- Q 2 :データはどこにありますか?
- Q 3 :復元された経験的依存度に応じた最適な戦略は何ですか?
記事の構造
黄色のオフトピック:Habra社のブログに関する真剣な情熱
たとえば、このような古い議論のように、企業ブログを取得する方法についての議論が展開される場合があります。
元のコメント:
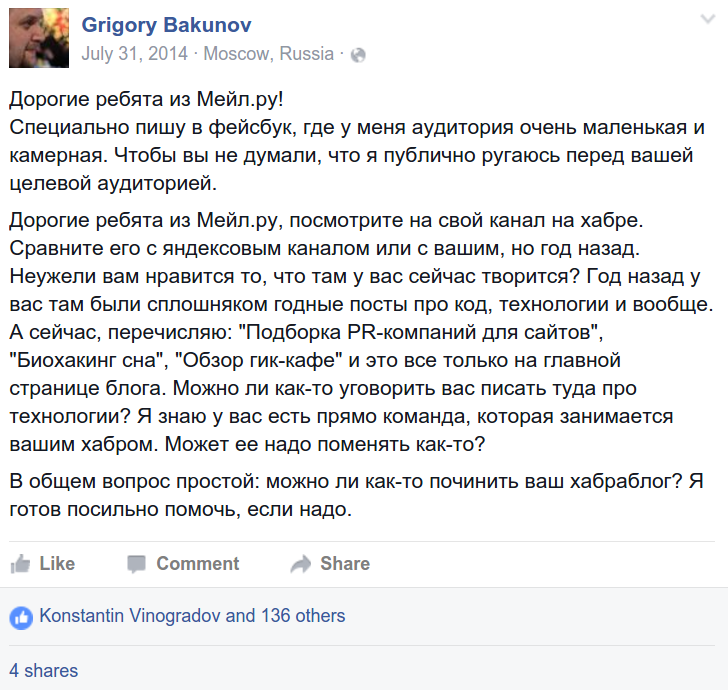
そして答え( ここから ):

一般に、このアプローチの深刻さは、このトピックに関する会社のプレゼンテーションですでに明らかになっています。

元のコメント:
そして答え( ここから ):
一般に、このアプローチの深刻さは、このトピックに関する会社のプレゼンテーションですでに明らかになっています。
潜在的な要因を特定します
会社のプロフィールを見ると、次の候補が印象的です。

さらに、パラメータは、カルマと従業員の評価、視聴回数、お気に入り、記事のプラス、およびその数など、変数のグループ全体で構成されます。
そして、ここで最も興味深い瞬間:機能の構築、そして実際にHabraインデックスを決定する要因は何ですか? そしてなぜこれがそんなに重要なのでしょうか? たとえば、機械学習アルゴリズムが実際のソース関数を「学習」するには、ソース関数を正しいスペースで定義する必要がありますが、これはありません!
ある意味、これは悪循環です。依存性を回復するための重要な要素がスペース(またはサブスペース)に含まれていることを知っておく必要があります。 しかし、この状況では、重要な要素(またはそのスーパーセット)がわかっていれば、問題は実際に解決されます。
特徴空間の真の表現
もう少し形式的には、次のように説明できます。データ表現にはローカルパターンが存在します。つまり、学習したい関数のすべてのパラメーターの「正しい表現」があります。 実関数がf(X、Y、Z)で、表現にXとYしかない場合、Zを考慮に入れない明らかに誤ったクラスF(X、Y)の関数を探します。この場合、実際の問題はKaggleとは大きく異なります。何も与えられません。
科学的な突く方法
どの要因が重要かを判断する方法は? 依存性は決定論的であることがわかります。つまり、TMがインデックスを明確に考慮する分析関数があります。 インデックス関数をfで表すと、 fは因子x iに依存します。 ただし 、任意のx iに対して以下のことが当てはまる場合に限ります。

そして、効果の大きさを呼び出します。
この定義は、変数間の独立性を意味するものではありません。 変数が依存している場合、 i番目の因子のcは他の変数に応じて異なる可能性があることを意味します。
また、経験から、関数は境界条件を満たさなければならないこともわかっています。
重要なポイント:ニューラルネットワークで関数がどうあるべきかについての先験的な強力なアイデアの統合は、完全に重要なタスクです。
したがって、質問Q 1の重要な観察結果:企業プロファイル(たとえば、上記のもの)からデータを適切に変換し、影響を測定して、交絡変数を1つずつ削除する必要があります。 また、分解条件をチェックする必要があります。つまり、変数は互いに独立しています。

データ収集
最後のページのアドレスhttps://habrahabr.ru/companies/にアクセスして、最も価値のある資料をご覧ください。
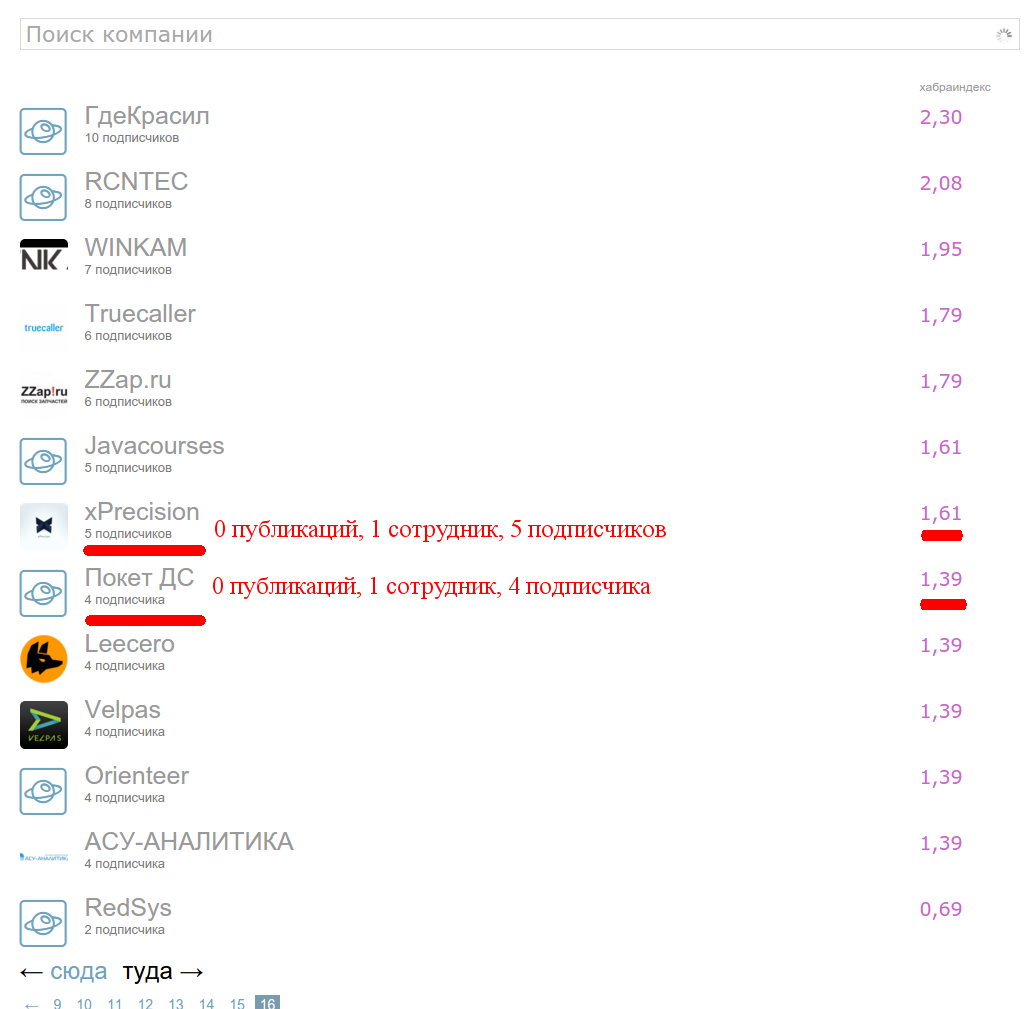
フォロワー
これは、出版物がなく、少数の従業員(1人または2人)と少数の加入者を持つ企業のセットです。 xPrecisionとPocket DSの 2つの会社を選択しましたが、従業員数が同じで加入者が1人違いであるため、Habraインデックスにゼロ以外の違いが見つかりました。
ビンゴ:Habraインデックスを決定する最初の要因は、 サブスクライバーの数です ! 成長は明らかに直線的ではないことに注意してください。リストの最初、中、最後の会社を見てください。 関数が十分な数のサブスクライバーで飽和し、マークアップがなく、一般にサブスクライバー要因が記事自体を支配しないようにするのが論理的です。 したがって、関数はゆっくりと成長し、ある時点でほぼ一定になります。 うーん、対数!
log(2)= 0.69
log(4)= 1.39
log(5)= 1.61
.....
合計、関数が次の形式であることを確認します。
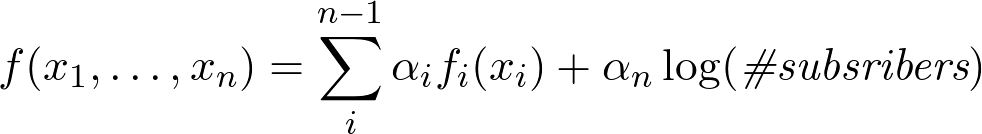
log(8)= 2.08であるため、関数はサブスクライバーのカルマに依存しないことに注意してください。
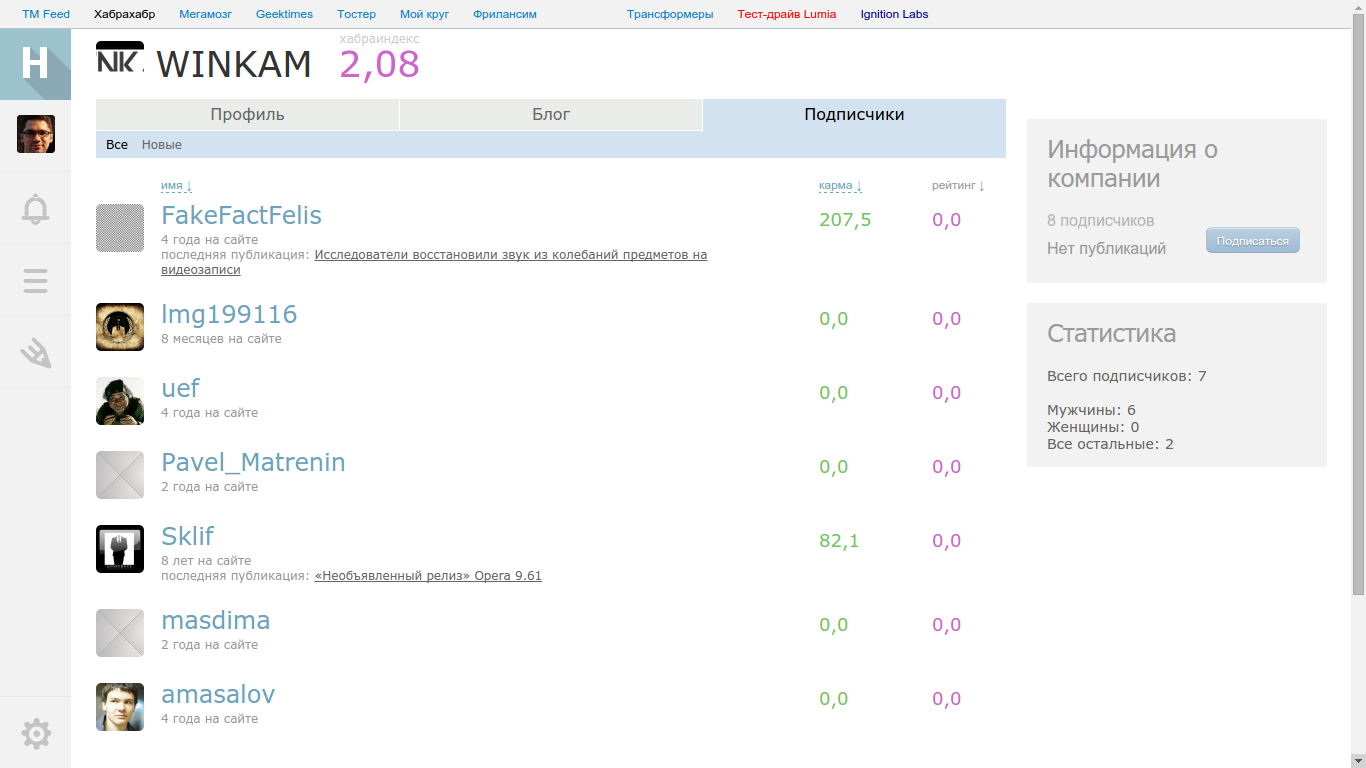
さらに、会社に出版物がない場合、係数は1であり、出版物がある場合は3です(詳細な分析で示されているように)。
従業員
15ページを検討し、加入者数と従業員数が異なる2つの会社を取り上げます。
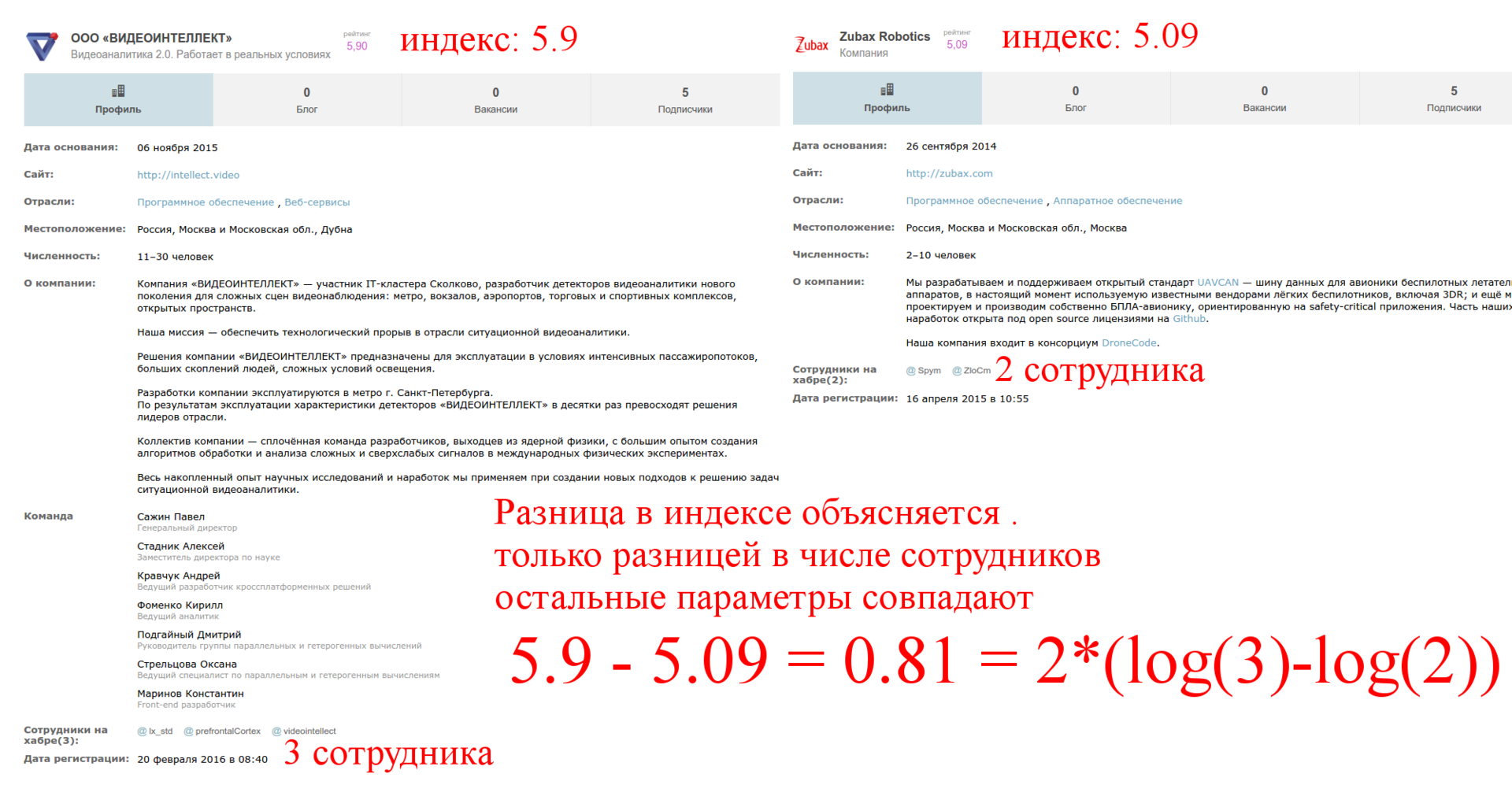
2番目の要因: 従業員数の対数 。 繰り返しますが、これは論理的であり、従業員の存在が記事を支配することは不可能です。 さらに、対数の前の係数は他のパラメーターにも依存します。
式は次の形式を取ります。
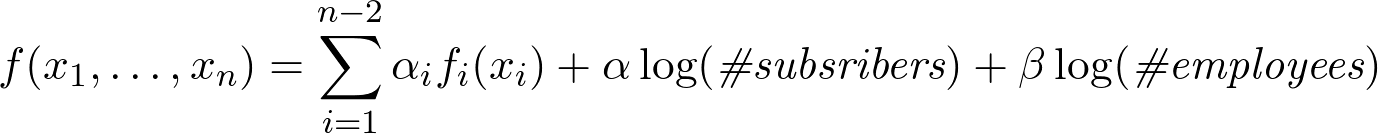
古いメリットの影響(記事ごと)
古い記事のプラス(〜1か月以上)は評価に影響しません:
古い記事を見ると、大きなプラスであっても効果はありません。
データ不足
ニューラルネットワークを使用するための最も重要な条件は、「信号がノイズよりも強い」大量のデータの存在であり、特徴空間が適切でなければなりません。 つまり、多くのノイズポイントがあったとしても、既存のパターンはノイズによって決定されます。 ご覧のとおり、実際にはデータはまったくなく、パターンをより明確に示しています。 また、フィーチャのスペースは小さく、いくつかの単純な構造を持っています(ほとんど因数分解されています)。 したがって、 Q 2は、適切にラベル付けされた大量のデータがない場合は、ニューラルネットワークを使用しないことを示しています。
結論:データはどこかから取得する必要があります。 非常に少量でも、仮説の正確な形成に必要です。
高品質の履歴データがない場合、どこで入手できますか? インターネットタイムマシン !
たとえば、企業ブログのランキングの時定数は約1か月であると判断し、会社の歴史を調べます。
http://web.archive.org/web/20151220201116/http://habrahabr.ru/company/oda/
また、記事の利点がどのように影響するかを理解したいと思います。 これを行うには、記事のプラスが考慮されなくなった直後に会社の格付けを知る必要があります-記事へのプラスを除き、ほとんどすべてのパラメーターが一致するはずなので、リスト内の企業間でそのようなデータを見つけることは事実上不可能です。
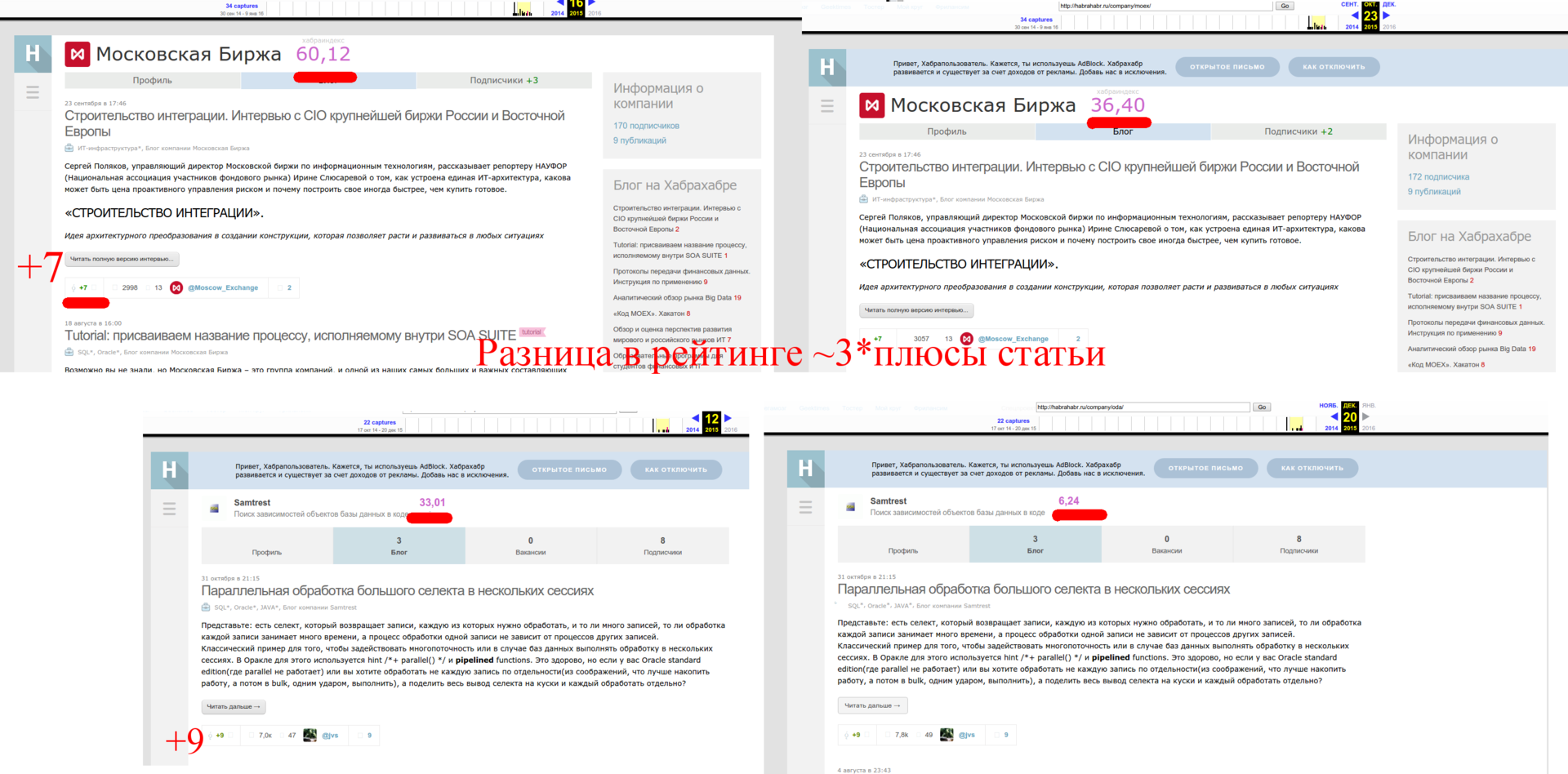
したがって、式は次の形式を取ります。
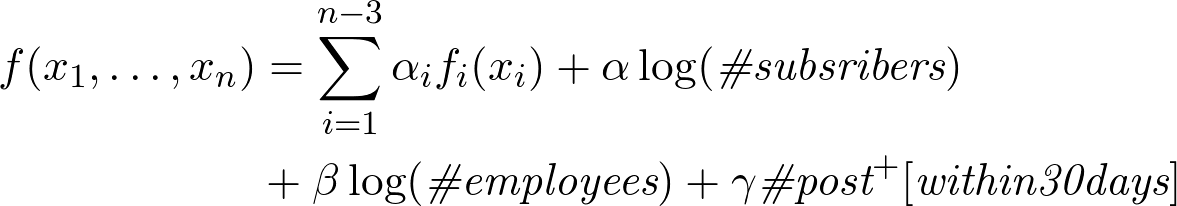
さらに、投稿が表示される前と後に評価を分析すると、会社に少なくとも1つの投稿がある場合、購読者と従業員からの評価は3倍になり、係数は次のようになることがわかります。

線形項の係数の推定値は概算ですが、絶対的に正確な係数の値よりも依存関係の性質が重要です。
カルマの効果と加入者と従業員の評価を決定します
従業員の評価
この効果を分析するには、ここではインターネットタイムマシンでさえも無力であるような重要なデータを収集する必要があります。 しかし、絶望することはできません。私はある会社のコントロールパネルにアクセスしただけで、評価をすぐに見ることができます。
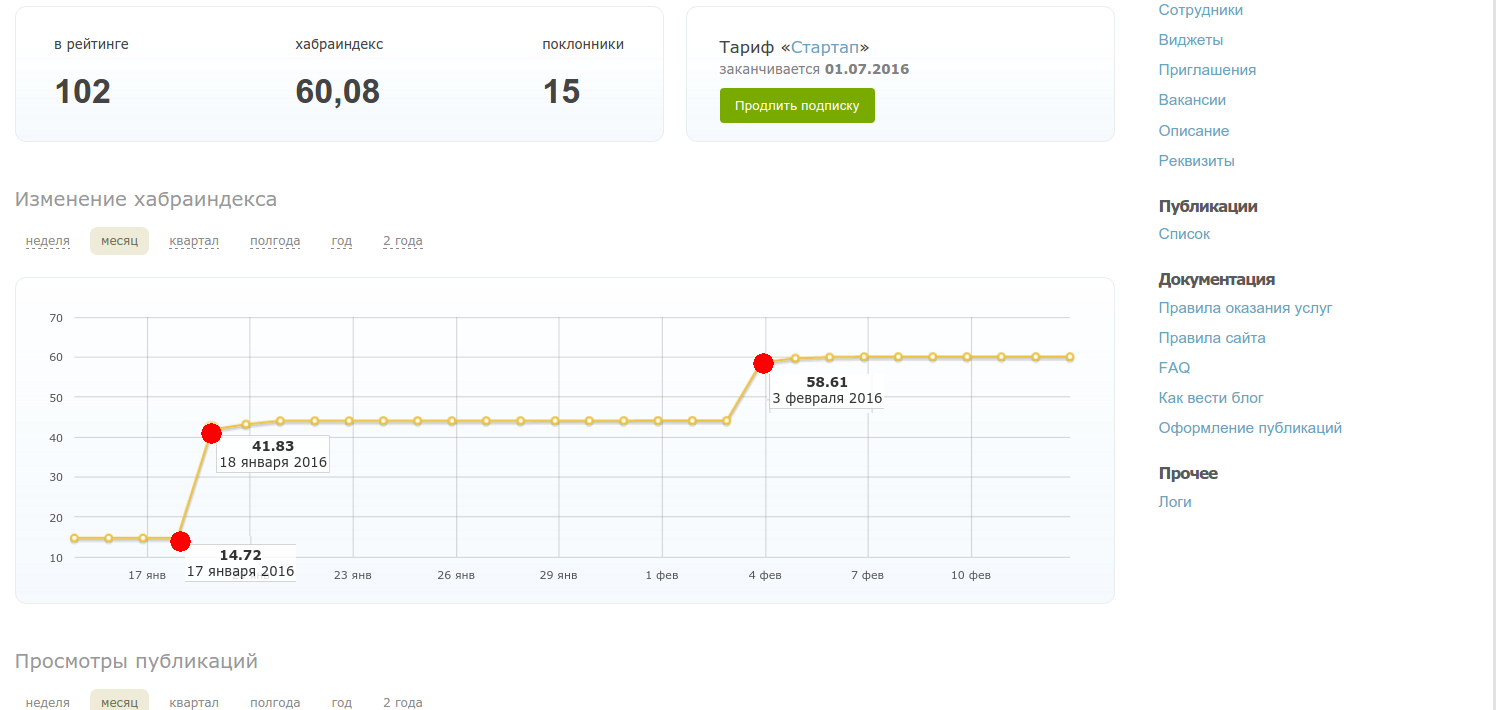
これらのポイントは、他の記事から評価を得た瞬間に対応しています。 そのため、労働者の格付けはHabra指数に影響します。分析では、係数が約9の対数であることが示されています。
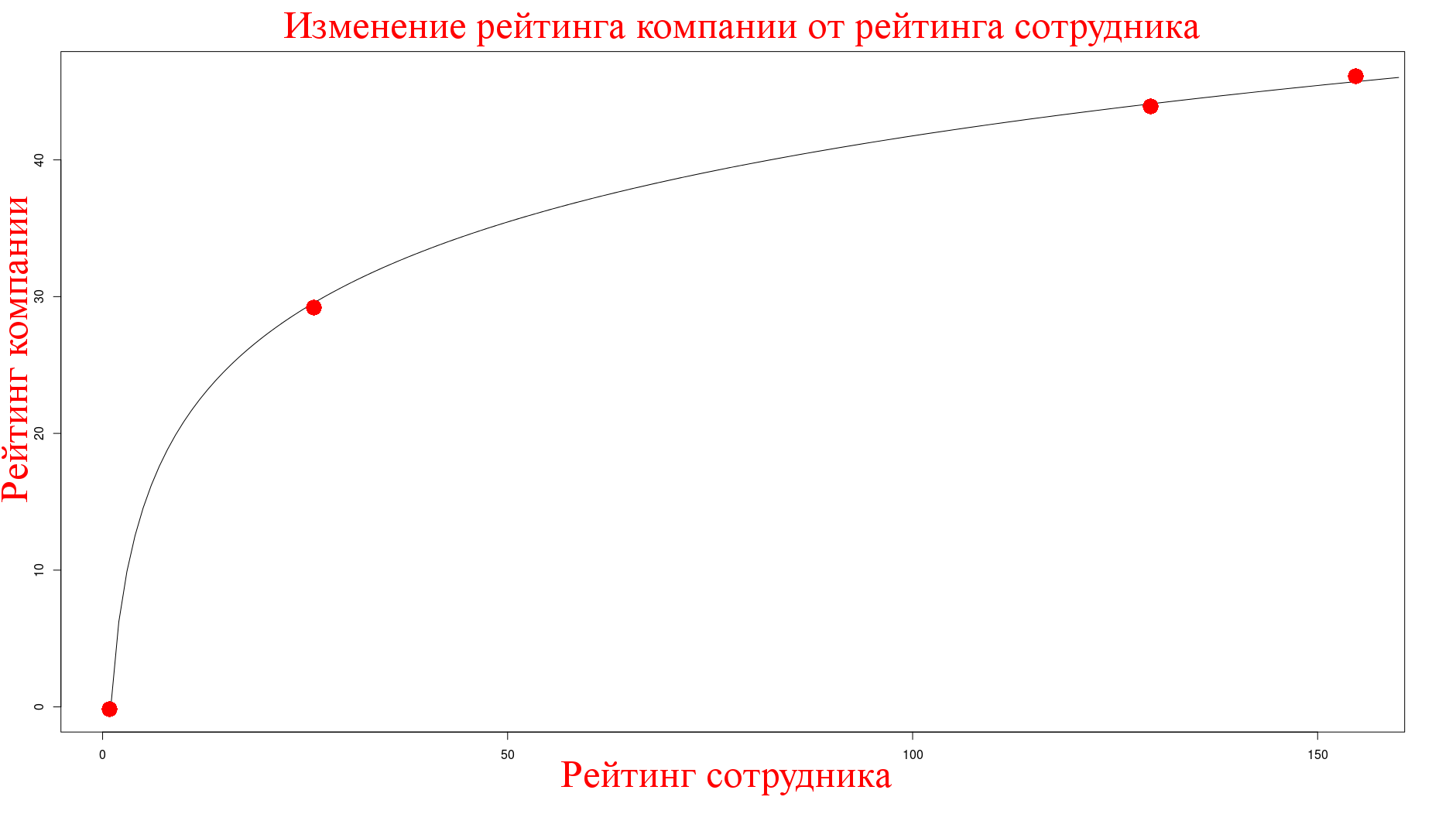
企業のポストで受け取った従業員のカルマ
従業員のカルマの効果を次のように測定します。Mosigraの投稿は1人によって作成され、これらの投稿でカルマを受け取っていることがわかっているため、アクティブな記事がない(まったく些細ではない)時点でインジケーターを測定しました。次のものを得ました:
name,blog,employees,subscribers,rating,size ..... mos_igra,115,10,4877,59.48,101_200
著者のカルマは〜850程度であったため、これらの投稿で得られたカルマへの依存性も対数であり、係数は〜3にほぼ等しくなります。
ご覧のとおり、会社の規模に関する情報も収集されました。 企業規模がインデックスに与える影響はゼロでした。
サブスクライバーの評価

このことから、成長は加入者の評価の観点からも対数的であり、記事の存在下で以前に観察された係数3がここにも現れることがわかります。

最終式
したがって、公開ケースの式は次のとおりです。
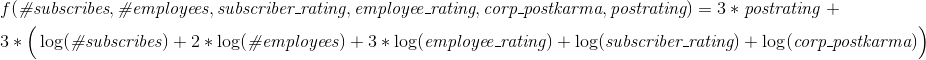
さらに、大きな括弧の前の係数(すべての対数の合計)は、会社に出版物がある場合は3、出版物がない場合は1です。 投稿へのプラスは、ユーザー投稿へのプラスと同じと見なされます(つまり、30日間保持されます)。
品質データを収集することの重要性
この記事を簡単に見ると、データの収集は非常に二次的なステップであるように思えるかもしれません。 実際、これは実際に問題を解決するための重要なステップです。これにより、仮説のスペースを大幅に狭め、インデックスに影響を与えない二次的な要因を取り除くことができました。
主要な要因を導き出すためにHabrインデックスの依存性を分析する最初の試み(2015年8月)を行ったときに十分ではなかったのは、Internet Time Machineと会社の時系列パネルからのデータでした。 たとえば、パラメーターの相互作用:記事の可用性に依存する係数は、パラメーターのグループにすぐに影響します。
ニューラルネットワークの適用性分析
問題がニューラルネットワークによって潜在的に解決できることを認識できる重要なポイントの短いリスト:
- 組み立てられた(マークアウトされた)データセットがあり、かなりのサイズ(明らかに「信号はノイズよりも強い*」である)
- かなりのサイズのフィーチャのスペース(画像内の色に沿った各ピクセルが1つの入力フィーチャであり、組み合わせと重ね合わせであると想像してください。まとめて1M +モデルパラメータについて話します)
- 特徴とパターンには階層構造があります-数字の分析を想像してください:点は直線で集められ、線は波状に、数字は波状に集められます(ネットワークを一種の圧縮マッピングと考えるのは簡単です)
- 依存関係が線形(2次関数、季節関数、一般的にあまり変化しない関数)であることがわかっている場合、依存関係の性質について重要な先験的なアイデアはありません。おそらく、このクラスのソリューションをすぐに探す必要があります。
- 結果の依存関係の分析は必要ありません。 アクションを予測するブラックボックスを取得する場合-これはかなり良い決定です-「GOでのこの動きは直感的には良いです」が、依存関係を分析する必要がある場合、ニューラルネットワークの場合は完全に重要なタスクになります(たとえば、 この記事を参照してください) )
私たちが分析した問題では、これらの条件はいずれも満たされていません 。
それでも、ダイエットピルはそれと何の関係がありますか?
これは救助に来て問題を解決する「魔法の薬」のほのめかしにすぎません。 重要なのは、実生活ではタスクは多面的であり、1つの汎用ハンマーで解決されるのではなく、分析と適切なツールの選択が必要であるということです。 2つのケースで症状が一致した場合でも、因果関係が異なる場合があり、2つの完全に異なる解決策が必要になる場合があります。
そうでなければ、これはすべてパンツノームのアプローチに似始めます

そうでなければ、これはすべてパンツノームのアプローチに似始めます
最適戦略分析
Habraインデックスを決定する主な要因を含む式があれば、質問3-さまざまなブログ戦略の有効性を評価するための質問に答えることができます。
重要な観察: 線形項は、+ 10程度の小さな値であっても、残りの対数項を簡単にメジャー化します。 10プラスの1つの記事に似た効果を得る(または150人の従業員を登録する)には、25,000人のサブスクライバーが必要です。 購読者だけで記事の効果を+20から得ることは事実上不可能です。
戦略1:毎週など、多くの小さな記事を定期的に〜+ 10で書く。 次に、会社の格付けはプラス3〜5 * 10〜= 150になり、他のパラメーターに少なくともある程度の現実的な値(たとえば、5人の従業員と100人の加入者)がある場合、最初のページに簡単に移動します。この戦略は非常に効果的です。ランキングの1位になったMicrosoftの戦略をご覧ください。 あなたが大企業であり、多くの情報ラインがある場合、戦略は合理的に見えます。
戦略1:いくつかの小さな記事 
2番目の戦略:月に1つか2つの思慮深い記事を50〜100プラスで書く。 企業のトップページと最初のページにいることが保証されています。 戦略の欠点は、このような数の記事を非常に難しい数で書くことです。 これは、たとえば、Mosigreで処理されます。以下の視覚化を参照してください。
戦略2:1つまたは2つの拡張記事 
加入者を獲得しようとする試みは、対数がすぐに一定に達するため(合理的な数の加入者に対して)、特に効果的な戦略ではありません。 すべての従業員をブログに登録するのは理にかなっていますが、非常に限られた効果しかありません。ここに577人の従業員がいるYandexでも、その効果は+ 12〜13の「常設」記事に匹敵します。