多くの研究者や開発者の間では、機械学習の分野でビッグデータを処理するためのツールはしばしば冗長であるという意見があります-いつでもサンプルを作成し、メモリに格納して、お気に入りのR、Python、Matlabを使用できます。 しかし実際には、このスタイルで数ギガバイトの比較的少量のデータでさえ処理するのが難しい場合に問題があります-そしてそれは非常に「ビッグデータ」技術が役立つことができるところです。
このようなタスクの良い例は、 SNA Hakathon 2016コンテストのタスクです。100万人のユーザーとその人口統計のソーシャルグラフが与えられます。 タスクは、この列で非表示の接続を見つけることです。 提供されるグラフのサイズはGZipで2ギガバイトのみであり、ビッグデータテクノロジーの使用はここでは正当化されないようですが、これは一見しただけです。
ソーシャルグラフで隠れたつながりを見つけるタスクで最も重要な「機能」の1つは、共通の友人の数です。 設計の観点から見ると、これは非常に難しい機能です。長さ2のパスがあるノードの数は、グラフ内の直接リンクの数よりも数桁大きくなります。 その結果、計算中にグラフが「爆発」し、スパースマトリックスから2ギガバイトに変換され、 高密度のテラバイトマトリックスに変換されます。
この問題を解決するためには小さなクラスターを上げるのが正しいように見えますが、急いではいけません。ビッグデータと対応するテクノロジーの処理の原則を採用したので、問題は通常のラップトップで解決できます。 原則から、「分割して征服する」と「すぐに尻尾を切る」、およびツールとしてApache Sparkを使用します。
問題は何ですか?
分析のために開かれたグラフは、隣接リスト(各頂点に隣接リストが与えられる)と非対称(すべての発信頂点が発信アークを知っているわけではない)の形式で表示されます。 このグラフの頂点間の相互の友人の数を計算する明白な方法は次のとおりです。

- グラフをペアのリストに変換します。
- 「共通の友人」によって、彼ら自身のためにカップルのリストに参加してください。
- 各ペアの出現回数を要約します。
もちろん、このアプローチの利点にはシンプルさが含まれます。Sparkでは、このソリューションに5行かかります。 しかし、彼にはもっと多くのマイナスがある。 すでに2番目のステップでjoin-aを実装すると、 シャッフル (処理の異なる段階間でのデータの転送)が発生し、ローカルストレージのリソースがすぐに使い果たされます。 そして、突然あなたのラップトップ上にまだそれのための十分なスペースがあるなら、それは間違いなく第三段階でシャッフルするのに十分ではありません。
タスクに対処するには、それを断片に分割し(「分割して征服する」)、少数の一般的な友人で結果をフィルタリングする必要があります(「すぐに切り刻む」)。 しかし、両方の条件を満たすことはすぐに問題です-グラフの一部でのみ相互の友人の数を計算すると、不完全な画像が得られ、フィルタを適切に適用できません...
ソリューションはどこにありますか?
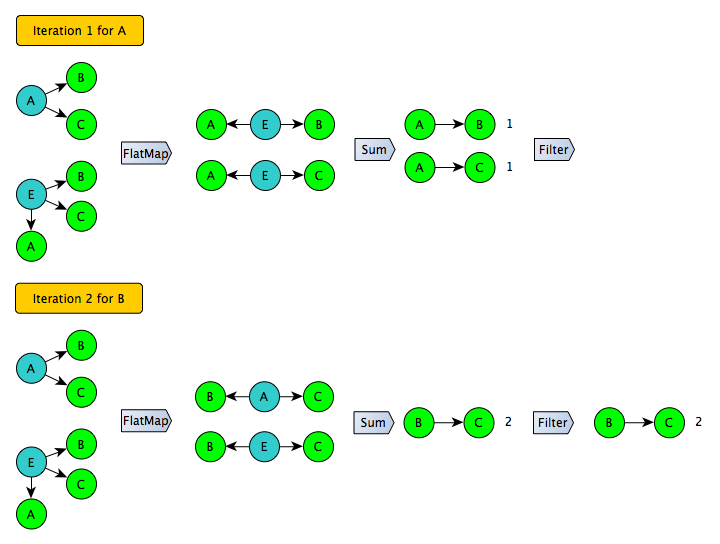
反対側から問題を見てみましょう。 最も問題となるのは、第2段階でペアのリストを結合することです。ペアのリスト自体の形式はサイズの点で非効率的であり、結合aサイドの1つは結果を歪めずに除外できません。 ペアとjoin-aのリストに変換せずに行うことは可能ですか? はい、「私は2人の友人の共通の友人です」という原則を使用する場合。 この場合、各フレンドリストの隣接リストを反復処理してすべてのペアを生成し、各ペアがシステム全体に出現した回数をカウントします。その結果、1つのシャッフルを使用して問題が解決します。
このアイデアを発展させるために、次のステップを踏むことは難しくありません:可能なすべてのペアを生成する代わりに、左側の特定のサブセットのユーザー(たとえば、偶数の識別子)のペアのみを生成する必要があります。 さらに、この手順を数回繰り返して、完全なカバレッジを取得できます。 同時に、各反復で、フィルターを安全に適用して「ロングテール」を遮断できます。このサブセットのユーザーの場合、数値は正確に取得されます。
このアプローチは対称グラフでうまく機能しますが、 SNA Hakathon 2016で提示されたグラフは非対称です-一部のユーザーにとって、入ってくるアークのみが知られています。 このトリックを使用するには、グラフを最初に展開する必要があります。

変換結果は既に保存され、反復アルゴリズムの入力として使用できます。
ゲームはろうそくの価値がありますか?
このグラフでは、100台のサーバーのクラスターで、一般的な友人の数を「正面から」数えるのに1時間かかりました。 最適化された反復オプションは、1台のデュアルコアラップトップで4時間半作動しました。 これらの数値から、「額」オプションは十分に大きな企業および/または研究チームにのみ受け入れられる一方、最適化されたオプションはほとんど誰でも起動できると結論付けることができます。 さらに、必要なコードと手順はすべてGitHubで公開されています 。
これらの「ビッグデータテクノロジー」は、このスキームで本当に必要ですか? 同じことをRまたはPythonで繰り返すことはできますか? 理論的には、不可能はありません。 しかし実際には、実装は多数の問題を解決し、非常に具体的な多くのパッケージと機能に精通する必要があります。 結果のコードは大きくなり、開発と保守に明らかに費用がかかります。
実際、この例を無視しても、多くの場合、Apache Sparkの使用はRおよびPythonよりも望ましい場合があります。データの並列処理はSparkにとって自然であり、高速化を実現し、実質的に変更なしでコードをGoogle Cloudのクラスターに転送できます( ケーススタディ )、はるかに大量のデータに適用されます。 さて、サポートされている機械学習アルゴリズムのコレクションは、「祖父母」よりは劣っていますが、すでに非常に印象的であり、絶えず更新されています( MLLib )。
Scalaを学ぶ時間:)