
この出版物は、記事「Intelエンジニアのステンシル計算に適用される特性評価と最適化の方法論 」の最初の部分を翻訳したものです。 このパートでは、かなり一般的なコンピューティングカーネルの例を使用してパフォーマンスの分析とルーフラインモデルの構築に専念します。これにより、このプラットフォームでアプリケーションを最適化する見通しを評価できます。
次のパートでは、期待されるパフォーマンス値に近づけるためにどの最適化が適用されたかを説明します。 この記事で説明する最適化手法には、たとえば次のものがあります。
- スケーラブルな並列化(共同スレッドブロッキング)
- メモリ帯域幅の増加(キャッシュブロッキング、レジスタの再利用)
- プロセッサパフォーマンスの向上(ベクトル化、サイクルの再分割)。
記事の第3部では、アプリケーションの起動とビルドに最適なパラメーターを自動的に選択するアルゴリズムについて説明します。 これらのパラメーターは通常、プログラムのソースコードの変更(ループブロッキング値など)、コンパイラーのパラメーター(サイクルスイープファクター)、コンピューターシステムの特性(キャッシュサイズなど)に関連付けられています。 結果のアルゴリズムは、従来のヘビーウェイト検索手法よりも高速であることが判明しました。 最も単純な実装から最も最適化された実装まで、Intel XeonプロセッサE5-2697v2でパフォーマンスが6倍、第1世代Intel Xeon Phiコプロセッサで約3倍のパフォーマンスが得られました。 これに加えて、上記の自動チューニングの方法では、入力データのセットに最適な開始パラメーターが選択されます。
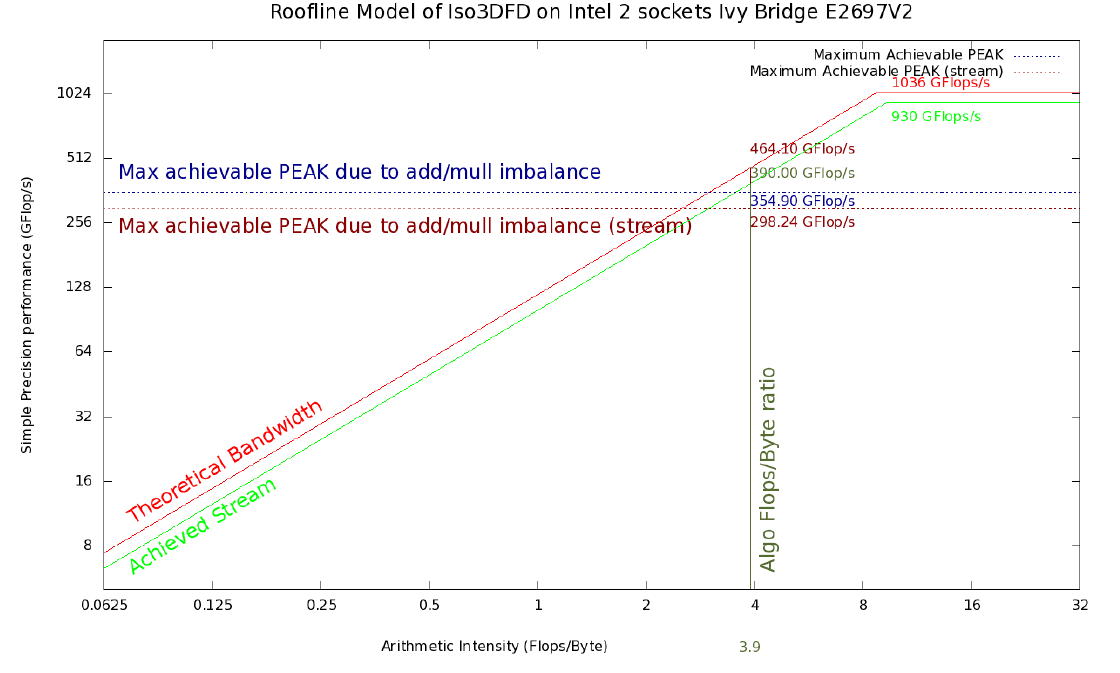
図1. Ivy Bridge 2S E5-2697 v2のルーフラインIso3DFDモデル。 赤と明るい緑の線は、それぞれ現在のプラットフォームの理論上の上限と達成可能な上限を示しています。 水平の青い線は、加算と乗算の特定の不均衡(#ADD; #MUL)を考慮し、ストリームトライアドベンチマークを使用して平均化されたメモリ帯域幅の最大値を反映しています(茶色の横線)。 濃い緑色の縦線は、Iso3DFDアルゴリズムのコアの算術強度に対応しています。 残りの線との交点は、対応する達成可能な制限を与えます。
短いレビュー
この記事では、等方性媒体(Iso3DFD)の一定または可変密度で音響方程式を解くために使用される3D有限差分アルゴリズム(3DFD)の特性評価(翻訳者のメモ-特性評価-特性の識別)および最適化方法について説明します。 3DFDの最も単純な実装から始めて、特定のコンピューティングシステム上で特定のアルゴリズムを特徴付けることによって、特定のアルゴリズムで得られる最高のパフォーマンスを評価する方法を説明します。
はじめに
時間領域での有限差分法は、たとえば、波の現象や地震探査の解析など、広く使用されている波のモデリング手法です。 この方法は、逆時間マイグレーションや完全な波形反転などの耐震解析技術を使用する場合によく使用されます。 この方法の種類には、波を音響または弾性とみなすことが含まれ、伝播媒体は異方性であり、密度も変化します。
ご存じのように、偏導関数の近似のための特定の数値スキームの選択は、実装のパフォーマンスに大きな影響を及ぼします[1]。 特に、これは3DFDアルゴリズムの演算強度(送信された各マシンワードの浮動小数点演算の数)に影響します。 この算術強度は、ルーフラインモデリング手法[2]を使用して、予想されるパフォーマンスにさらに関連付けることができます。 この方法により、特定のコンピューティングシステムで達成可能な最大値と比較して、実装のパフォーマンスレベルを評価できます。 つまり、ルーフラインモデルは、プログラムのソースコードを最適化することで達成できる生産性向上のフレームワークを設定します。 実装パフォーマンスが特定のレベルに達した後、アルゴリズム自体を変更することによってのみ、生産性をさらに向上させることができます。
どのコンピューターでも、その仕様は、浮動小数点演算の数(FLOP / s)およびメモリーとのデータ転送(メモリー帯域幅)のピーク値を定義します。 LINPACK [3]やSTREAM triad [4]などの標準ベンチマークを起動することで、対応する最大達成可能インジケーターを取得できます。
この記事の最初の部分は、デュアルソケットサーバーとコプロセッサーでのIso3DFDアルゴリズムのコアの達成可能な最大パフォーマンスを評価することを目的としています。 次に、パフォーマンスに重要な影響を与える可能性のあるいくつかの手法について説明します。 いつものように、このような最適化にはソースコードの多少の努力と修正が必要になる場合があります。 その後、最適ではないにしても、アプリケーションをコンパイルして実行するための最適なパラメーターセットをある程度見つけるための補助ツールを示します。
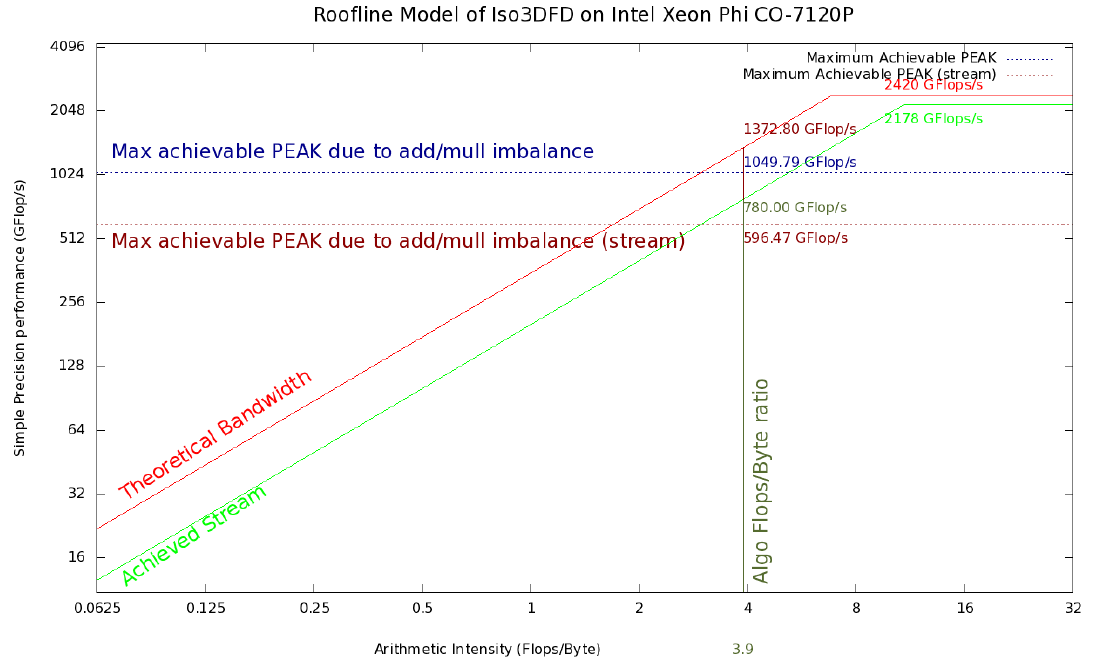
図2. Xeon Phi 7120PコプロセッサーのルーフラインIso3DFDモデル。 赤と明るい緑の線は、それぞれ現在のプラットフォームの理論上の上限と達成可能な上限を示しています。 水平の青い線は、加算と乗算の特定の不均衡(#ADD; #MUL)を考慮し、ストリームトライアドベンチマークを使用して平均化されたメモリ帯域幅の最大値を反映しています(茶色の横線)。 濃い緑色の縦線は、Iso3DFDアルゴリズムのコアの算術強度に対応しています。 残りの線との交点は、対応する達成可能な制限を与えます。
性能評価
コアIso3DFDアルゴリズムは、16空間サンプリングと2時間サンプリングの音響等方性波動方程式を解きます。 この3DFDカーネルの標準実装は、通常、1秒あたりの浮動小数点演算(FLOP / s)でピークコンピューティングシステムのパフォーマンスの10%未満を達成します。 CPUおよびXeon Phiコプロセッサー上のIso3DFDコンピューティングコアのルーフラインモデル[2]を取得する方法を検討します。 このアプリケーションの最大パフォーマンスを見つけるには、以下を見つける必要があります。
- ピークパフォーマンスとメモリ帯域幅(理論):単精度で2420 GFLOP / s、Intel Xeon Phi 7120Aで352 GB / s。 単精度で1036 GFLOP / s、1866 MHz DDR3メモリを搭載した2つのIntel XeonプロセッサーE5-2697v2で119 GB / s。
- Linpack(またはGEMM)およびSTREAMトライアドベンチマークで得られた値は、プラットフォーム上の対応する最大パフォーマンスインジケーターを提供します。IntelXeon Phi 7120Aの場合は2178 GFLOP / sおよび200 GB / s。 1866 MHz DDR3メモリを搭載した2つのIntel Xeon E5-2697v2プロセッサの場合、930 GFLOP / sおよび100 GB / s
- アプリケーションの演算強度は、浮動小数点数の加算と乗算(ADD、MUL)の数、メモリから送信されたバイト数、およびメモリへの特定のダウンロードと書き込み(LOAD、STORE)に基づいて計算されます。
最後のポイントは、コンピューティングシステムに無限のメモリ帯域幅とサイズのキャッシュがあり、データアクセスのレイテンシ(レイテンシ)がゼロであるという仮定から得られます。 これにより、1つの要素のみが必要な場合でも任意の配列が完全にロードされる、一種の完璧なメモリサブシステムが定義されます。
他のいくつかの要因も、3DFDコアを使用するアプリケーション全体のパフォーマンスに影響を与える可能性があります-境界条件の選択、時間を逆転させたときのIOスキーム、および並列プログラミングのテクノロジーまたはモデル。 ただし、ここで紹介する分析では、境界条件とIOを考慮していません。 この問題に対するソリューションの並列実装では、OpenMPを使用するコンピューティングノードでのスレッド並列処理とともに、MPI標準を使用する分散システムのドメイン分解方法を使用します。 このペーパーでは、コンピューティングシステムの1つのノード上のサブドメインでの計算を検討します。
プラットフォームの演算強度
テストシステムは、CPUあたり12コアの2つのXeon E5-2697 CPU(2S-E5)で構成され、それぞれがターボモードなしで2.7 GHzの周波数で実行されます。 これらのプロセッサは、256ビット幅のベクトルレジスタによるAVX命令セット拡張をサポートしています。 これらの命令は、同時に(CPUクロックサイクルごとに)単精度(32ビット)で8つの浮動小数点数を使用して計算を実行できます。 したがって、理論上のピークパフォーマンスは、2.7(GHz)x 8(SP FP)x 2(ADD / MULL)x 12(コア)x 2(CPU)= 1036.8 GFLOP / sとして計算できます。 ピーク帯域幅は、メモリ周波数(1866 GHz)、メモリチャネル数[4]、クロックサイクルごとに送信されるバイト数(8)を使用して計算され、デュアルプロセッサノードの場合は1866 x 4 x 8 x 2(CPU)= 119 GB / sになります2S-E5。 また、アプリケーションの動作を特徴付けるために、スループットとパフォーマンスの現実的に達成可能な値を評価する必要があります。 最初の近似として、実際のアプリケーションのパフォーマンスは、ストリームトライアドまたはプロセッサ速度(合計FLOP / sバウンドまたはコンピューティングバウンドまたはCPUバウンド)を使用して推定されるメモリ帯域幅(合計帯域幅制限)によって制限されると仮定します。 Linpackベンチマークを示します。 これら2つのベンチマークの選択は純粋に仮説にすぎませんが、理想的な推定値から大きく外れている場合は、コンピューティングシステムの理論的なピーク値よりも近似として確かに適していると言えます。
2S-E5システムでは、Linpackは930 GFLOP / sおよびStream triad 100 GB / sを提供します。 さらに、理論的および実際の最大指標の算術強度(AI)は、それぞれ次のように計算できます。
AI(理論、CPU)= 1036.8 / 119 = 8.7 FLOP /バイト
AI(達成可能、CPU)= 930/100 = 9.3 FLOP /バイト
これらの値を使用して、任意のコンピューティングコアを次のように特徴付けることができます:コアの算術強度が9.3 FLOP /バイトよりも大きい(小さい)場合、このコアはプロセッサ速度-CPUバウンド(メモリ帯域幅)によって制限されていると言えます。
Xeon PhiのLinpackおよびStreamトライアドで同様の計算を行うと、それぞれ2178 GFLOP / sおよび200 GB / sになります。 理論上のピーク推定値は2420 GFLOP / sおよび352 GB / sです。 したがって、算術強度は次のようになります。
AI(理論的、ファイ)= 2420.5 / 352 = 6.87 FLOP /バイト
AI(達成可能、ファイ)= 2178/200 = 10.89 FLOP /バイト
コンピューティングコアの演算強度
Rooflineモデルでは、特定のアプリケーションの算術強度の計算も必要です。 コードの目視検査または計算システムのカウンターにアクセスできる特別な手段により、算術演算とメモリーアクセスの数をカウントすることで取得できます。 差分スキーム[5]の標準的な計算カーネル内では、4つのダウンロード(coeff、prev、next、vel)、1つのレコード(next)、51の加算(インデックス計算は考慮されません)、27の乗算(図3)を見つけることができます。
for(int bz=HALF_LENGTH; bz<n3; bz+=n3_Tblock) for(int by=HALF_LENGTH; by<n2; by+=n2_Tblock) for(int bx=HALF_LENGTH; bx<n1; bx+=n1_Tblock) { int izEnd = MIN(bz+n3_Tblock, n3); int iyEnd = MIN(by+n2_Tblock, n2); int ixEnd = MIN(n1_Tblock, n1-bx); int ix; for(int iz=bz; iz<izEnd; iz++) { for(int iy=by; iy<iyEnd; iy++) { float* next = ptr_next_base + iz*n1n2 + iy*n1 + bx; float* prev = ptr_prev_base + iz*n1n2 + iy*n1 + bx; float* vel = ptr_vel_base + iz*n1n2 + iy*n1 + bx; for(int ix=0; ix<ixEnd; ix++) { float value = 0.0; value += prev[ix]*coeff[0]; for(int ir=1; ir<=HALF_LENGTH; ir++) { value += coeff[ir] * (prev[ix + ir] + prev[ix - ir]) ; value += coeff[ir] * (prev[ix + ir*n1] + prev[ix - ir*n1]); value += coeff[ir] * (prev[ix + ir*n1n2] + prev[ix - ir*n1n2]); } next[ix] = 2.0f* prev[ix] - next[ix] + value*vel[ix]; } }}}
図3.キャッシュブロッキングを使用したカーネルソースコードの計算
算術強度は次の式で計算できます。
AI =(#ADD + #MUL)/((#LOAD + #STORE)xワードサイズ)(1)
これにより、3.9 FLOP /バイトの算術強度が得られます。これに各プラットフォームの理論スループットを掛けて、このアルゴリズムで達成可能な最大パフォーマンスの最初の推定値を取得します。 Xeon Phiでは1372.8 GFLOP / s、2S-E5では461.1 GFLOP / sになります。 ただし、理論上のピークパフォーマンス値は、2つのパイプライン(1つはADD、もう1つはMUL)の並列使用を意味しますが、加算と乗算の不均衡によりこの計算コアでは不可能であるため、このコードはこの推定最大値を達成できません。 そして、これは達成可能な最大値が次のもので平均されるべきであることを意味します:
(#ADD + #MUL)/(2 x最大(追加、mul))、(2)
1つの256ビットAVX SIMDコンピューティングユニットの使用を想定して、サイクルあたり16の浮動小数点演算で可能な演算の合計数(ops /サイクル)と8 ops /サイクルで実行される加算と乗算の最大数の比率を反映します。 これにより、加算と乗算の不均衡を考慮して、ピークパフォーマンスの理論的な推定値が得られます。
図1および2は、2S-E5およびXeon Phiの上限がそれぞれ354.9 GFLOP / sおよび1049.8 GFLOP / sのルーフラインモデルを示しています。
より現実的なルーフラインモデルは、Streamトライアドベンチマークの帯域幅にコンピューティングコアの演算強度(それぞれ390 GFLOP / sおよび780 GFLOP / s)を掛けて取得できます。 赤い点線で示されているように、加算と乗算の不均衡を考慮すると((2)を使用して)さらに現実的なモデルを取得できます。 新しい上限は、2S-E5では約298 GFLOP / s、Xeon Phiでは596 GFLOP / sです。 このモデルは完璧なキャッシュモデルに基づいているため、結果の値は依然として達成可能な最大パフォーマンス値の大まかな推定値であると想定しています。 [2]に示されているように、メモリキャッシュの効果や制限など、コンピューティングシステムの特性に新しいエンティティを追加することで、結果として生じるルーフラインを改善できます。
続行するには...
参照資料
- D. Imbert、K。Immadouedine、P。Thierry、H。Chauris、L。Borges、「Expanded Abstracts」の「有限差分とi / o-less fwiのヒントとコツ」。 Soc。 説明 Geophys。、2011、pp。 3174-3178。
- S.ウィリアムズ、A。ウォーターマン、D。パターソン、「ルーフライン:マルチコアアーキテクチャの洞察力に富んだ視覚パフォーマンスモデル」、Communications of the ACM-A Direct Path to Dependable Software、vol。 52、pp。 65〜76、2009年4月。
- J. Dongarra、P。Luszczek、およびA. Petitet、「linpackベンチマーク:過去、現在、未来」、並行性と計算:実践と経験、vol。 15、いいえ。 9、pp。 803–820、2003、doi:10.1002 / cpe.728。
- JD McCalpin、「ストリーム:高性能コンピューターの持続可能メモリ帯域幅」、バージニア大学、バージニア州シャーロッツビル、Tech。 Rep。、1991-2007、継続的に更新される技術報告書。 www.cs.virginia.edu/stream
- L. Borges、「Intel Xeon Phiコプロセッサ向けの地震イメージングコードの開発経験」、2012年。software.intel.com/en-us/blogs/2012/10/26/experiences-in-developing-seismic-imaging-code -for-intel-xeon-phi-coprocessor
- JH Holland、「遺伝的アルゴリズムと試行の最適な割り当て」、SIAM Journal of Computing、vol。 2、いいえ。 2、pp。 88-105、1973。